

不懂就问AI:AI大模型embeding是什么
描述
背景和问题
osc推文看到一部分内容,关于AI的,虽然作者早期也做过AI的一部分工作,就是简单的训练和预测,也是用的GAN等类似的生成对抗网络,但是毕竟好多年没有用了,而且现在是大语言模型相关的概念还是没怎么了解过,这不OSC,也就是开源中国提到的这个图,里面有个embeddings引发了我的思考,借本文也分享一下这个概念。

解答
在人工智能领域,特别是在处理自然语言处理(NLP)和机器学习任务时,“embedding”一词通常指的是将高维的离散数据(如单词、句子或图像)转换成低维的连续向量表示的过程。这种转换使得机器能够更好地理解和处理这些数据,因为连续的向量空间可以进行数学运算,如加法和乘法,这有助于捕捉数据之间的复杂关系。
以下是一些关于embedding的关键点:
词嵌入(Word Embedding):这是最常见的embedding形式,它将词汇映射到向量空间,使得语义上相似的词在向量空间中彼此接近。
句子嵌入(Sentence Embedding):将整个句子或短语转换成单一的向量,以捕捉句子的整体含义。
文档嵌入(Document Embedding):类似于句子嵌入,但用于更长的文本,如文章或文档。
图像嵌入(Image Embedding):在计算机视觉中,将图像转换成向量形式,以便进行图像识别和分类。
上下文嵌入(Contextual Embedding):某些模型,如Transformer和BERT,生成的嵌入不仅考虑单个词的含义,还考虑它在句子中的上下文。
预训练嵌入(Pre-trained Embedding):使用大量数据预训练得到的嵌入,可以在特定任务上进行微调,提高模型性能。
定制嵌入(Custom Embedding):针对特定任务或数据集定制的嵌入,可能需要从头开始训练或根据预训练嵌入进行调整。
嵌入空间(Embedding Space):嵌入向量所在的多维空间,不同的数据点在这个空间中以向量形式表示。
嵌入维度(Embedding Dimension):嵌入向量的维数,决定了模型可以捕捉的数据复杂性。
嵌入技术(Embedding Techniques):生成嵌入的方法,包括Word2Vec、GloVe、BERT等。
在AI大模型中,embedding是模型理解和处理数据的基础,它们使得模型能够执行各种复杂的任务,如语言翻译、情感分析、图像识别等。
小结
经过查询,我大概理解了一些内容,也就是类似与编解码,只不过是维度级别的编解码。以前用做数字识别的例子里面有个one-hot编码,也大概这个含义吧。不过瘾,画个图。
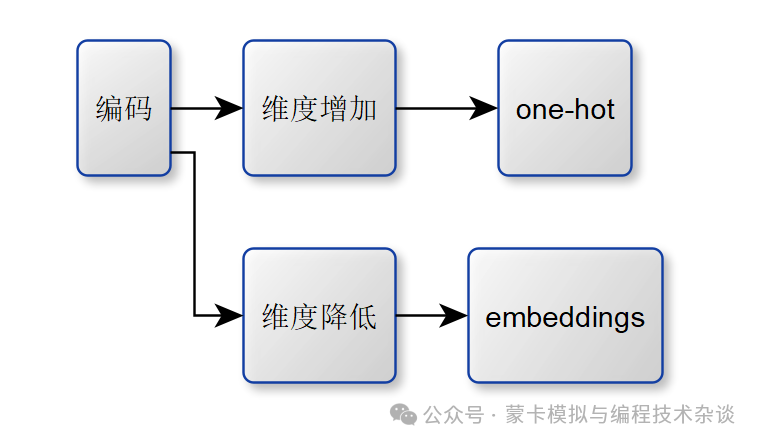
这里其实不是百分百这样的。很多时候embeddings,其实是嵌入的意思,很多时候是维度升高的。
我斗胆说一个想法,编码是训练的的基础,编码其实是数据预处理的一种手段。欢迎思想碰撞。
-
AI大模型之Python基础2026-07-18 30
-
Hollis【实战课程】大模型应用开发实战,AI大模型应用开发-模型训练-RAG-Agent-AI项目实战(已完结)2026-07-09 57
-
AI大模型应用开发实战训练营-第18期2026-07-04 23
-
博学谷ai大模型就业班第八期2026-06-30 50
-
使用NORDIC AI的好处2026-01-31 1812
-
AI模型的配置AI模型该怎么做?2025-10-14 446
-
首创开源架构,天玑AI开发套件让端侧AI模型接入得心应手2025-04-13 1141
-
STM CUBE AI错误导入onnx模型报错的原因?2024-05-27 1244
-
使用cube-AI分析模型时报错的原因有哪些?2024-03-14 1276
-
AI大模型可以设计电路吗?电子发烧友网官方 2024-01-02
-
AI算法中比较常用的模型都有什么?2022-08-27 3688
-
【AI专家讲座】不懂编程没关系,邀请您来学AI2019-04-18 3735
全部0条评论

快来发表一下你的评论吧 !
