

国产大模型发展的经验与教训
描述
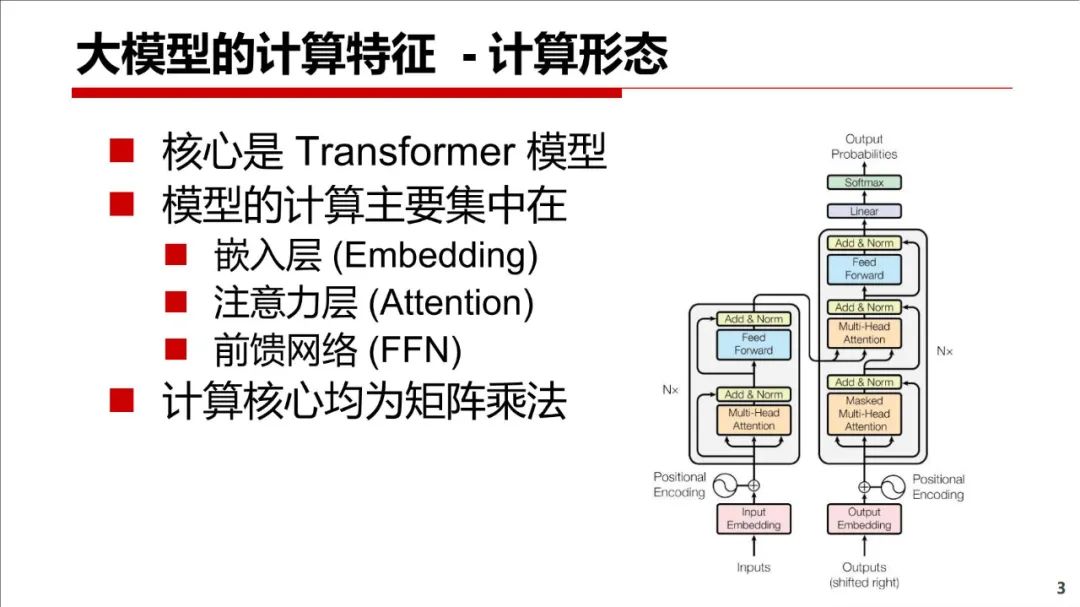
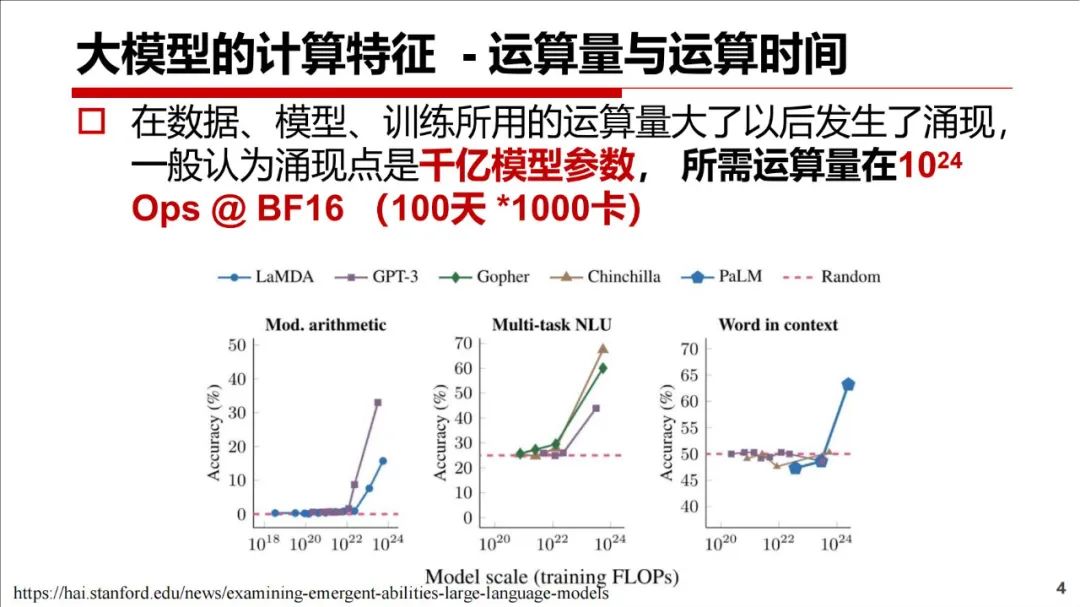
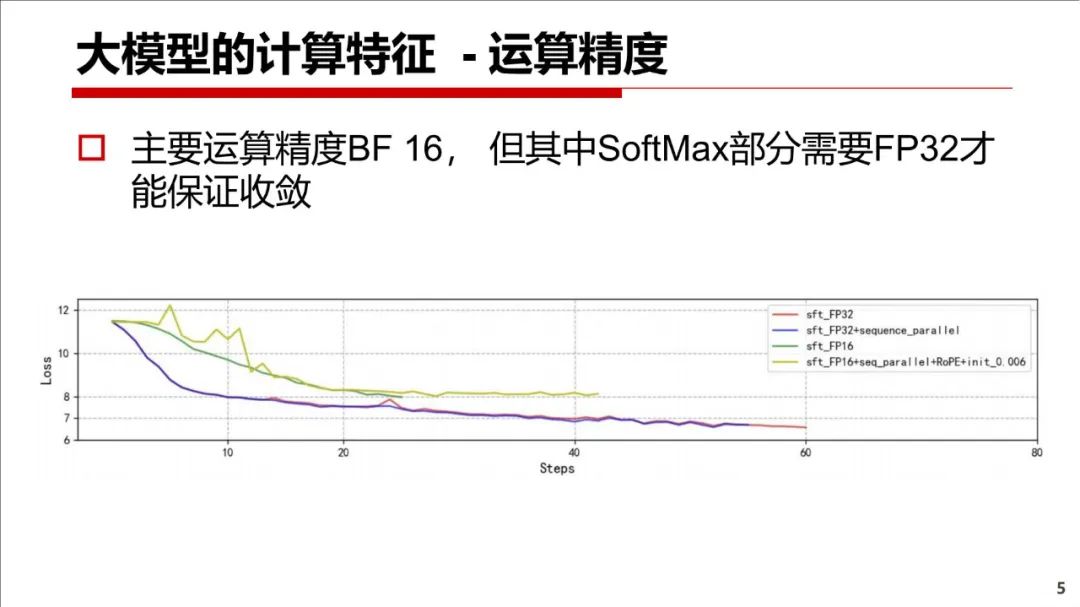
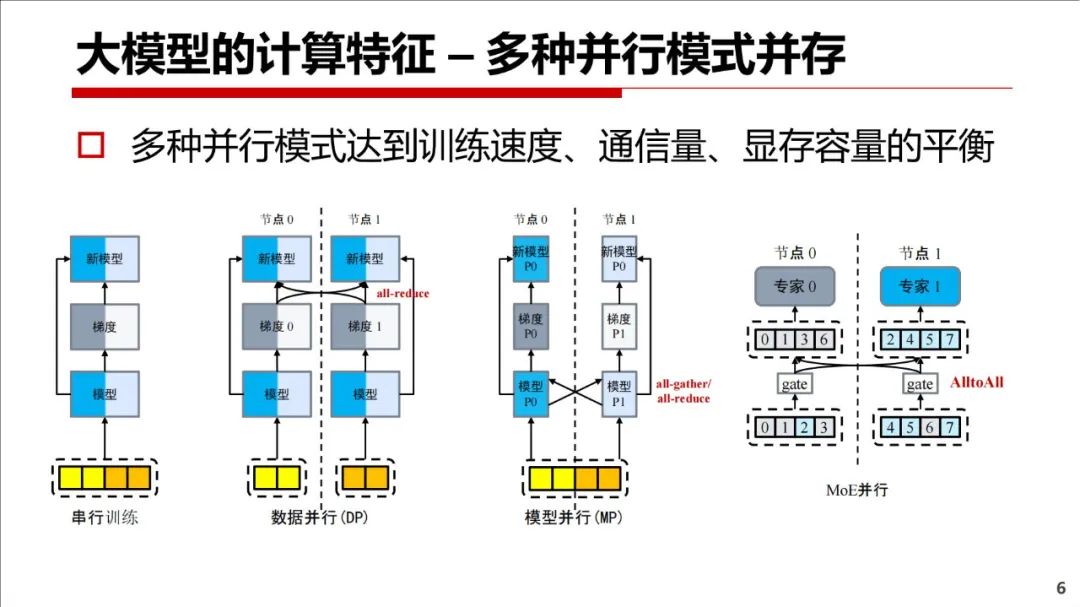
本文介绍大模型的计算特征(国产平台介绍、系统挑战、算子实现、容错)、框架的并行性支持、未来算法等。
随着ChatGPT的横空出世,人工智能大模型成为各行各业热议的焦点,国内外各种大模型如雨后春笋般涌现,引发了新一轮人工智能热潮。但在看到大模型取得巨大进步的同时,也要看到当前国内大模型的研发推广仍然面临不小的挑战和压力。
面对上述挑战,需从战略层面统筹考虑大模型研发运营等相关问题,充分发挥“集中力量办大事”的制度优势,强化顶层设计,加大统一规划,加大政策支持和资源投入力度,推动中国人工智能从“跟跑”迈向“领跑”。
一是提高算力规模。进一步完善信息基础设施,加快推进“东数西算”步伐,加大算力网络建设力度,为大模型研发运营提供足够算力,同时进一步提高网络速度,降低网络时延,为更多大模型走向应用创造条件。
二是加强数据管理。国家层面加强对数据的管控,明确行业标准,建立数据使用规则,确保大模型训练数据的质量。同时,针对行业数据,破除不同厂家之间数据互相不能查询的壁垒,确保大模型训练有充足、准确的专业数据。
三是建立大模型研发“国家队”。集中全国顶尖人才和优质资源,举全国之力进行攻坚突破,同时解决大模型研发中存在的“小而散”问题,减少无效或低效大模型开发对算力和能源的浪费。
四是加大资金投入。建立国家大模型基金,专门用于大模型的研发、训练等。
五是加大政策支持。面向大模型研发,制订更加优惠的税收政策。针对国有企业在大模型研发上投入的资金,允许以两倍规模计为企业净利润。
六是加大科技投入。解决核心技术“卡脖子”问题,特别是加大人工智能芯片研发制造力度。









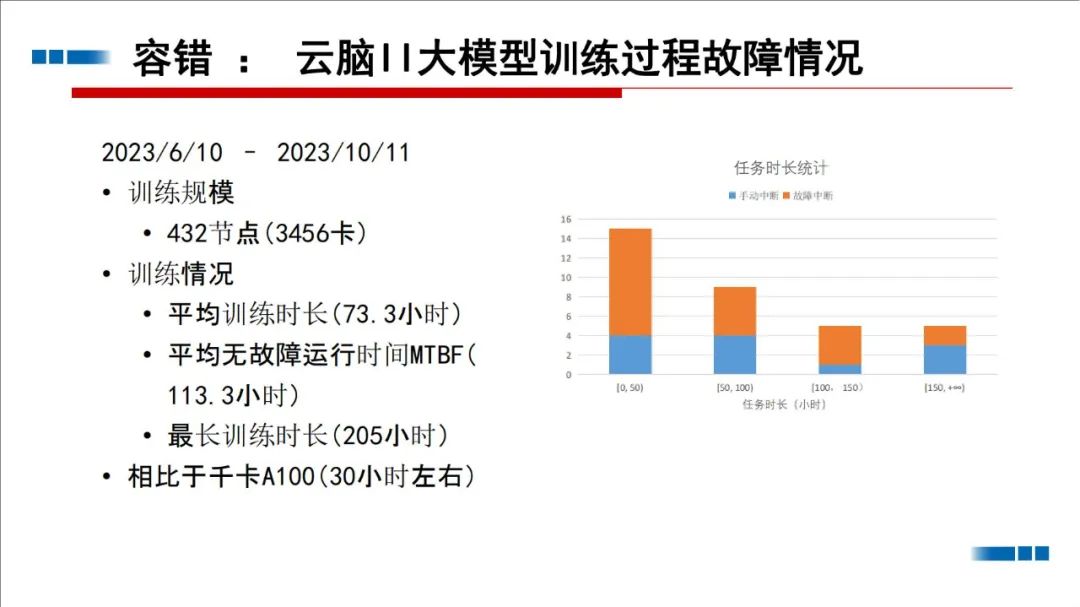
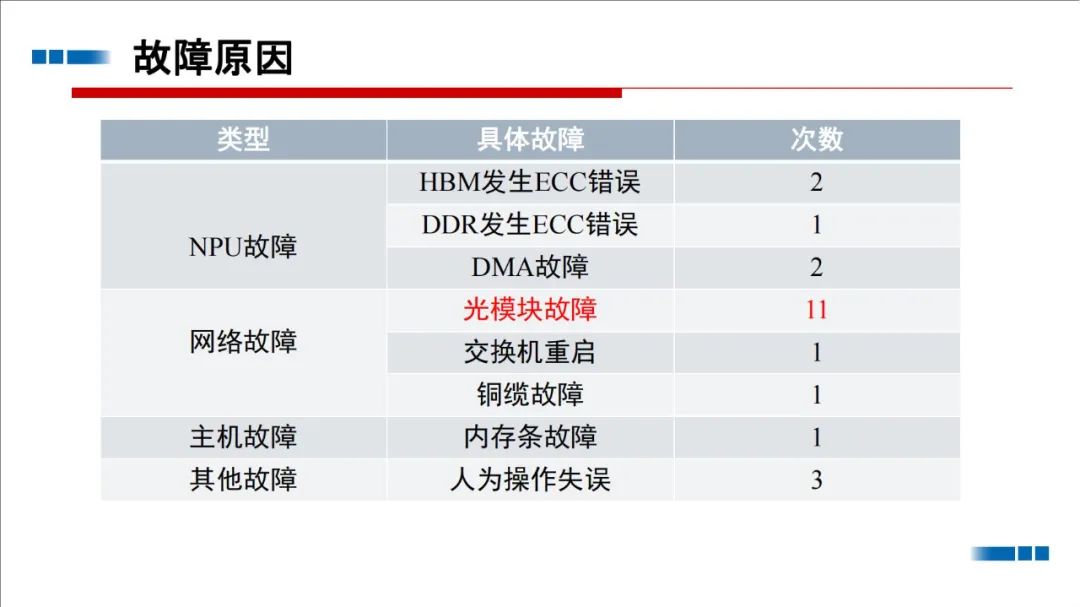


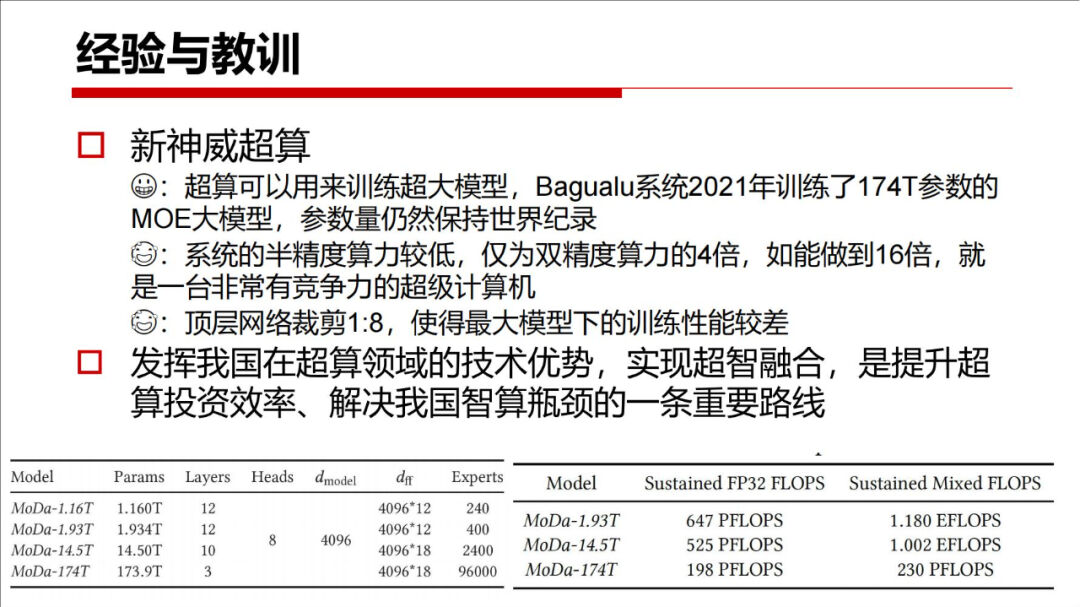

-
目前国产fpga的发展有哪些趋势2024-06-30 7016
-
国产FPGA的发展前景是什么?2024-07-29 8123
-
轮胎稳态侧向半经验模型的研究2009-12-02 2578
-
求大神分享单片机从业的经验教训和学习历程?2021-09-18 1192
-
珠海炬力与SigmaTel达成和解的经验教训2009-12-24 1171
-
摩托罗拉联席CEO布朗总结经验教训2009-05-21 658
-
工程师跨度13年、回顾194个bug总结的18条编码、测试和调试经验教训2018-02-27 1425
-
物联网行业的8条经验教训盘点2018-03-17 3665
-
探讨华为国际化之路的经验和教训2018-09-18 33640
-
企业如何从智能家居中吸取经验教训2018-11-19 3383
-
写在最前:单片机从业的经验教训和历程。2021-11-15 624
-
NASA的经验教训文件中的一些电气工程事故2022-10-20 1720
-
从50多个生物识别可穿戴产品开发周期得到的十大经验教训2022-11-01 553
-
嵌入式微控制器应用中的无线(OTA)更新:设计权衡与经验教训2023-11-23 598
-
大模型发展下,国产GPU的机会和挑战2024-07-18 981
全部0条评论

快来发表一下你的评论吧 !
