

OpenAI o1 思维链模型的笔记
描述
“ 对于复杂推理任务来说,这是一个重要的进展,代表了人工智能能力的新水平。鉴于此,我们将计数器重置为 1,并将这一系列命名为 OpenAI o1。 ”
OpenAI 上周发布了两个新的预览模型:o1-preview 和 o1-mini(mini 不是预览版)--之前传言的代号为 “草莓”。关于这些模型有很多需要了解的地方--它们并不像 GPT-4o 那样简单,而是在成本和性能方面做了一些重大权衡,以换取 “推理 ”能力的提高。 新模型的能力用以下两张图表述的很清楚了(主要是数学和代码能力的提升):
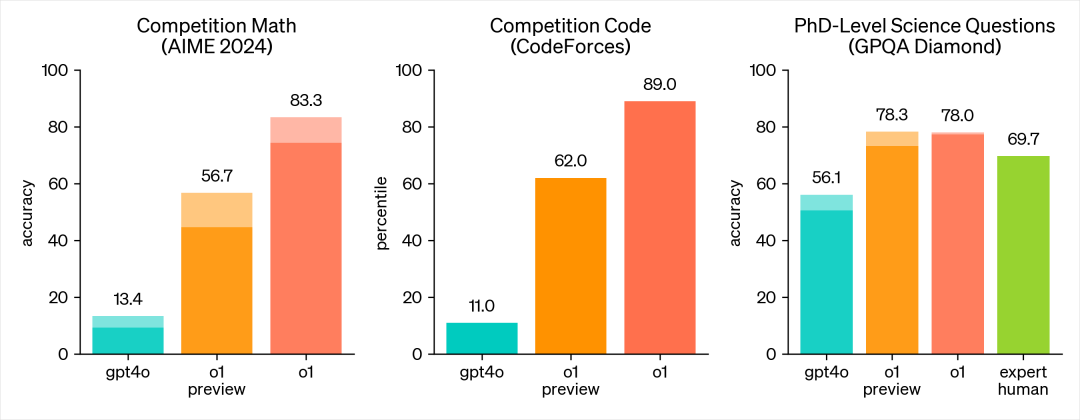
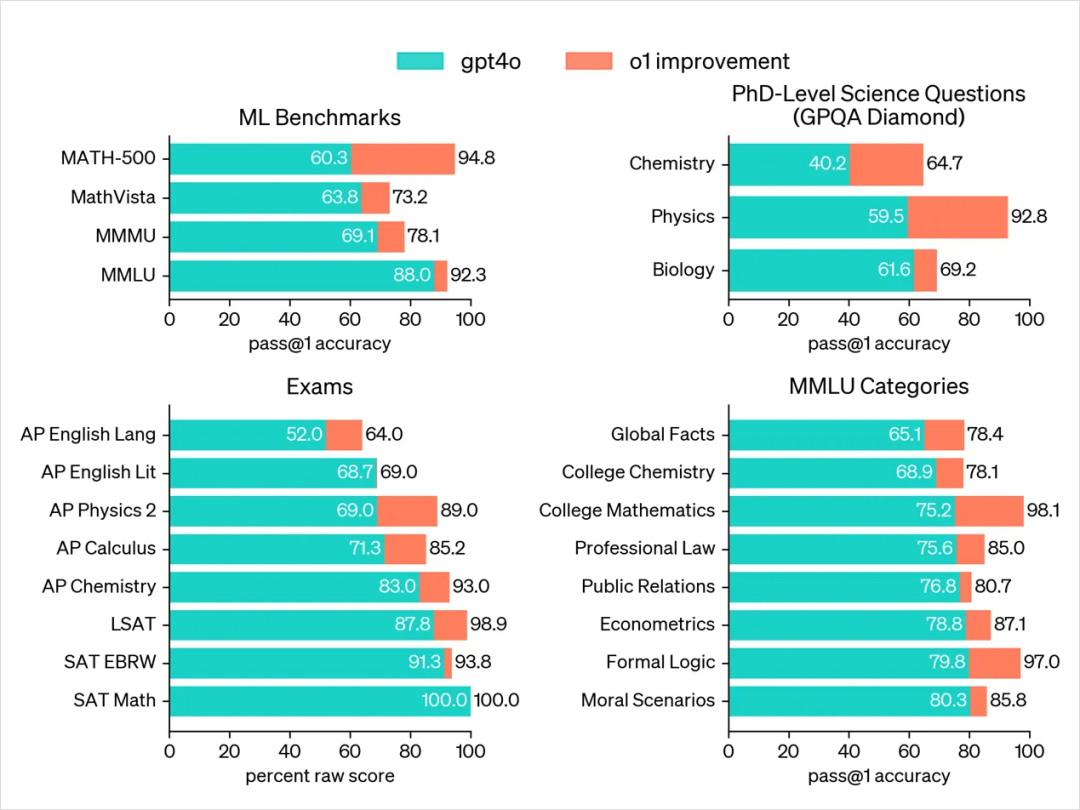
o1 详细的介绍很多公众号都有,这里就不再赘述了。本文只从思维链的角度,做一些分享,主要分为以下几方面:
为思维链训练
API 文档中的细节
隐藏的推理 token
示例
未来的创新
为思维链训练
我们开发了一系列新的人工智能模型,旨在花更多时间思考后再做出反应。
理解新模型的一种方式是将其视为思维链提示模式(Promopt)的扩展,即 “一步一步思考” 的技巧。 OpenAI 的文章 Learning to Reason with LLMs (https://openai.com/index/learning-to-reason-with-llms/)解释了新模型的训练方法:
我们的大规模强化学习算法在一个数据效率极高的训练过程中,教会模型如何利用其思维链进行富有成效的思考。我们发现,随着强化学习(训练时间计算)和思考时间(测试时间计算)的增加,o1 的性能也在不断提高。这种方法的扩展限制与 LLM 预训练的限制有很大不同,我们正在继续研究。
[...]
通过强化学习,o1 学会了训练自己的思维链和完善自己使用的策略。它学会识别和纠正错误。它学会把棘手的步骤分解成更简单的步骤。它学会在当前方法无效时尝试不同的方法。这一过程极大地提高了模型的推理能力。
实际上,这意味着模型可以更好地处理更为复杂的提示,在这种情况下,要想取得好的结果,除了预测下一个 token 外,还需要回溯和 “思考”。API 文档中的细节关于新模型及其权衡的一些最有趣的细节可以在它们的 API 文档中找到:
对于需要图像输入、函数调用或持续快速响应时间的应用程序,GPT-4o 和 GPT-4o mini 仍将是正确的选择。但是,如果您的目标是开发需要深度推理并能适应较长响应时间的应用程序,那么 o1 型号可能是一个极佳的选择。
从文档中可以归纳出一些要点:
API 访问限制:新的 o1-preview 和 o1-mini 模型的 API 访问权限目前仅限于 tier 5 级账户--你需要至少花费 1000 美元购买 API 点数。
不支持系统提示(system prompt):模型使用现有的聊天完成 API,但只能发送用户和助手消息。
不支持的功能:不支持流式传输(streaming)、工具使用(tool usage)、批量调用或图片输入。
响应时间:根据模型解决问题所需的推理量,请求可能需要几秒到几分钟不等。
最有趣的是 “推理令牌”(reasoning tokens)的引入:这些 token 在 API 响应中不可见,但仍作为输出令牌(output token)计费和计算。所以您将支付比 API 响应结果 token 数量更多的费用。
鉴于推理令牌的重要性,OpenAI 建议为受益于新模型的提示分配约 25000 个推理令牌。输出令牌的数量限制将大幅增加,o1-preview 增加到 32768 个,规模较小的 o1-mini 增加到 65536 个!与 gpt-4o 和 gpt-4o-mini 模型相比,这两个模型目前的输出令牌限制都增加到了 16,384 个。
API 文档中还有最后一个有趣的提示:
限制检索增强生成(RAG)中的附加上下文:在提供附加上下文或文档时,只包含最相关的信息,以防止模型的响应过于复杂。
这与通常的 RAG 实现方式有很大不同,通常的建议是在提示中塞入尽可能多的潜在相关文档。
隐藏的推理 Token
一个让人感觉很不爽的点:这些推理令牌在应用程序接口(API)中是不可见的,但还是要收费(花了钱看不到买了什么东西)。OpenAI 在博客中解释了其中的原因:
假设它是忠实和可读的,那么隐藏的思维链就能让我们 “读懂” 模型的思想,了解它的思维过程。例如,将来我们可能希望监控思维链,以发现操纵用户的迹象。但是,要做到这一点,模型必须能够以不改变的形式自由表达自己的想法,因此我们不能在思维链上训练任何政策遵从或用户偏好。我们也不想让用户直接看到不一致的思维链。
因此,在权衡了用户体验、竞争优势以及对思维链进行监控的选项等多重因素后,我们决定不向用户展示原始的思维链。
因此,这里有两个关键原因:
安全性和政策合规性:OpenAI希望模型能够在不暴露可能违反政策规则的情况下,自由地表达其思想。这意味着模型需要有能力在不受到政策合规性或用户偏好影响的情况下,进行自由的思考。
竞争优势:OpenAI不希望其他模型能够通过训练来模仿他们投入资源开发的推理工作。隐藏推理令牌可以作为一种保护措施,防止其他公司或模型复制他们的推理技术。
这一做法显然无法让用户满意。作为一个希望使用 LLMs 进行开发的人,可解释性和透明度对我来说非常重要:如果我输入了一个复杂的提示,而提示评估的关键细节却被隐藏起来,而只能看到最后的结论,这让我觉得是一大倒退。
示例OpenAI 在其公告的 “思维链” 部分提供了一些简单的示例,包括生成 Bash 脚本、解决填字游戏和计算中等复杂的化学溶液的 pH 值。 这些示例表明,新的 CHatGPT 网页版本确实展示了思维链的细节,但并没有显示原始的推理令牌,而是使用了一个单独的机制来将步骤总结为更易于人类了解的形式。
OpenAI 还有两本新的 cookbook,其中包含更复杂的示例,但我觉得有点难以理解:
使用推理进行数据验证展示了一个多步骤的过程,用于生成一个包含11列的CSV格式的示例数据,然后以各种不同的方式进行验证。https://cookbook.openai.com/examples/o1/using_reasoning_for_data_validation
使用推理进行例程生成(routine generation)展示了o1-preview代码,将知识库文章转换成大型语言模型可以理解和遵循的一系列例程。https://cookbook.openai.com/examples/o1/using_reasoning_for_routine_generation
Twitter上还有些在 GPT-4o 上失败但在 o1-preview 上有效的提示例子。其中有几个是我最喜欢的:
由 Matthew Berman 提出的 “你的回应中有多少个单词?” 这个问题,模型在五个可见的回合中思考了十秒钟,然后回答说“这个句子中有七个单词。”(There are seven words in this sentence)。正好7个!
由 Fabian Stelzer 提出的“解释这个笑话:‘两头牛站在田野里,一头牛问另一头:‘你觉得现在流行的疯牛病怎么样?’另一头说:‘谁在乎,我是直升机!’” 真正的疯牛 其他模型对这个无能为力。
不过,好的例子还是有点少。以下是参与创建这些新模型的 OpenAI 研究员 Jason Wei 的相关说明:
AIME 和 GPQA 的结果确实很强,但这并不一定能转化为用户能感受到的东西。即使是从事科学工作的人,要找到 GPT-4o 失败、o1 做得很好、而我能给答案打分的提示词也并不容易。但是,当你找到这样的提示词时,o1 就会给人一种完全神奇的感觉。我们都需要找到更难的提示。
Ethan Mollick已经预览了这些模型几周,并发表了他的初步印象。他对填字游戏的示例特别有趣,因为其中包含了可见的推理步骤,包括这样的注释:
我注意到1 Across和1 Down的首字母不匹配。考虑将1 Across的“LIES”改为“CONS”,以确保对齐。
未来的创新
社区需要一段时间来摸索出这些新模型的最佳实践和应用场景。估计大部分人仍会会继续主要使用 GPT-4o 和 Claude 3.5 Sonnet 模型,但新的思维链模型对扩展对大型语言模型(LLMs)能解决的任务类型会有相当大的启发。
希望我们能看到其他人工智能实验室,包括开源模型社区,开始用他们自己的模型版本复制其中的一些结果,这些模型经过专门训练,可以应用这种思维链推理方式。
注意:如果想第一时间收到 KiCad 内容推送,请点击下方的名片,按关注,再设为星标。
常用合集汇总:
和 Dr Peter 一起学 KiCad
KiCad 8 探秘合集
KiCad 使用经验分享
KiCad 设计项目(Made with KiCad)
常见问题与解决方法
KiCad 开发笔记
插件应用
发布记录
审核编辑 黄宇
-
雷军:小米玄戒O1已开始大规模量产2025-05-20 1438
-
OpenAI:DeepSeek与Kimi揭秘o1,长思维链提升模型表现2025-02-18 1057
-
OpenAI o3-mini模型思维链遭质疑2025-02-08 1237
-
对标OpenAI o1,DeepSeek-R1发布2025-01-22 3565
-
OpenAI发布o1模型API,成本大幅下降60%2024-12-19 1232
-
ChatGPT新模型o1被曝具备“欺骗”能力2024-12-12 1294
-
OpenAI发布满血版ChatGPT Pro2024-12-06 1559
-
昆仑万维推出“天工大模型4.0”o1版(Skywork o1)邀请测试2024-11-28 1480
-
昆仑万维天工大模型4.0 O1版即将邀测2024-11-19 1653
-
天工大模型4.0 O1版即将启动邀测2024-11-18 1869
-
Orion模型即将面世,OpenAI采用新发布模式2024-10-25 1314
全部0条评论

快来发表一下你的评论吧 !
