

OpenVINO™ C++ 在哪吒开发板上推理 Transformer 模型|开发者实战
描述
使用 OpenVINO 定制你的 AI 助手丨开发者实战
作者:
王国强 苏州嘉树医疗科技有限公司 算法工程师
指导:
颜国进 英特尔边缘计算创新大使
研扬科技针对边缘 AI 行业开发者推出的『哪吒』(Nezha)开发套件,以信用卡大小(85 x 56mm)的开发板-『哪吒』(Nezha)为核心,『哪吒』采用 Intel N97 处理器(Alder Lake-N),最大睿频 3.6GHz,Intel UHD Graphics 内核GPU,可实现高分辨率显示;板载 LPDDR5 内存、eMMC 存储及 TPM 2.0,配备 GPIO 接口,支持 Windows 和 Linux 操作系统,这些功能和无风扇散热方式相结合,为各种应用程序构建高效的解决方案,专为入门级人工智能应用和边缘智能设备而设计。英特尔开发套件能完美胜人工智能学习、开发、实训、应用等不同应用场景。适用于如自动化、物联网网关、数字标牌和机器人等应用。
1.1
OpenVINO 介绍
OpenVINO 是一个开源工具套件,用于对深度学习模型进行优化并在云端、边缘进行部署。它能在诸如生成式人工智能、视频、音频以及语言等各类应用场景中加快深度学习推理的速度,且支持来自 PyTorch、TensorFlow、ONNX 等热门框架的模型。实现模型的转换与优化,并在包括 Intel硬件及各种环境(本地、设备端、浏览器或者云端)中进行部署。
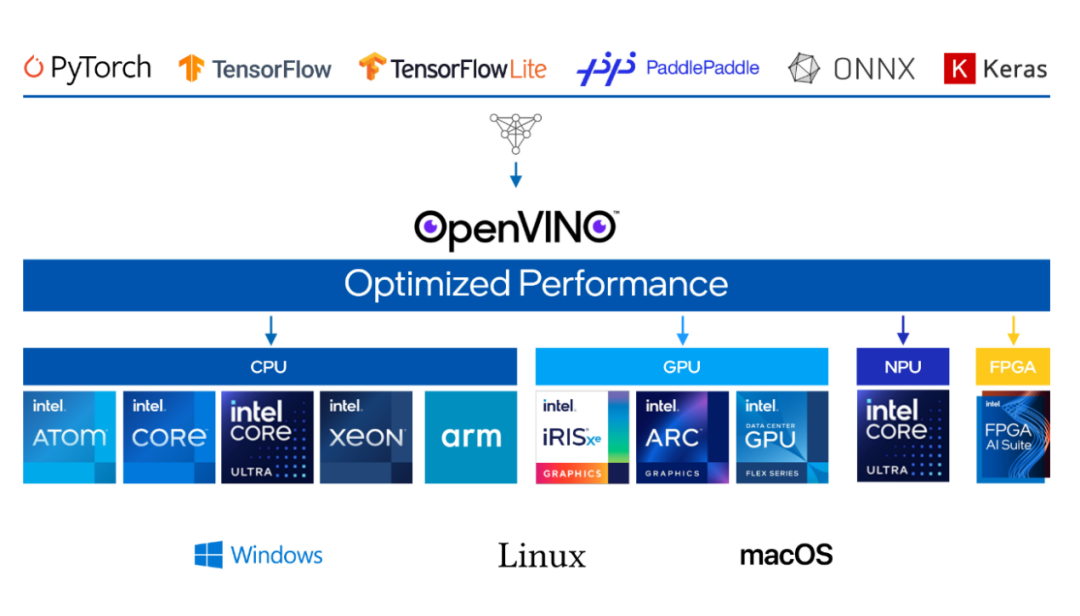
图1-2 以深度学习为基础的AI技术在各行各业应用广泛
1.2
Ubuntu22.04 上的
OpenVINO 环境配置
OpenVINO 官方文档 https://docs.openvino.ai 有最新版本的安装教程,这里使用压缩包的方式安装,选择对应的 Ubuntu22 的版本:
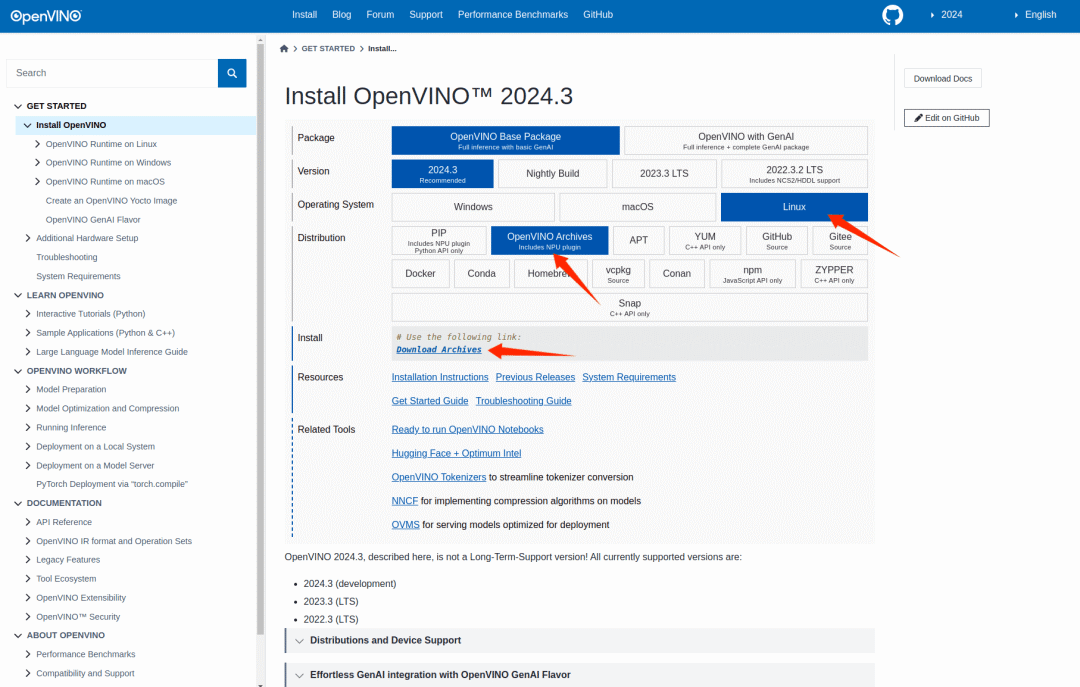
下载到哪吒开发板上后将压缩包解压:
1 tar -zxvf l_openvino_toolkit_ubuntu22_2024.3.0.16041.1e3b88e4e3f_x86_64.tgz
进入解压目录,安装依赖:
1 cd l_openvino_toolkit_ubuntu22_2024.3.0.16041.1e3b88e4e3f_x86_64/ 2 sudo -E ./install_dependencies/install_openvino_dependencies.sh
然后配置环境变量:
1 source ./setupvars.sh
这样 OpenVINO 的环境就配置好了,可以直接在 Intel CPU 上推理模型,如果需要在 Intel iGPU 上推理,还需要另外安装 OpenCL runtime packages,参考官方文档:
https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-gpu.html
这里使用 deb 包的方式安装,按照 Github
https://github.com/intel/compute-runtime
的说明下载7个 deb 包,然后 dpkg 安装
1 sudo dpkg -i *.deb
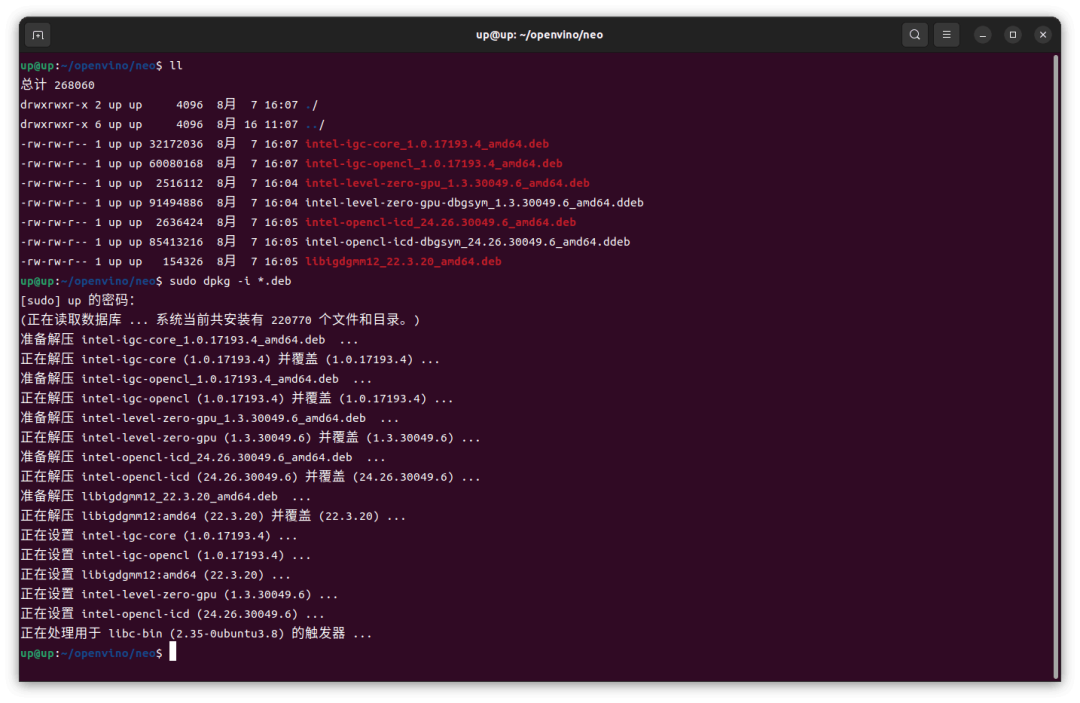
如果 dpkg 安装出现依赖报错,就需要先 apt 安装依赖,然后再 dpkg 安装7个 deb 包
1 sudo apt install ocl-icd-libopencl1
这样在哪吒开发板 Ubuntu22.04 上使用 Intel iGPU 进行 OpenVINO 推理的环境就配置完成了。
1.3
Transformer模型推理
模型是一个基于 Transformer 结构的模型,训练后生成 ONNX 中间表示,OpenVINO 可以直接使用 ONNX 模型进行推理,也可以转为 OpenVINO IR格式,转换命令如下:
1 ovc model.onnx
默认会生成 FP16 的模型,如果精度有较大损失,可指定 compress_to_fp16 为 False 就不会进行 FP16 量化了:
1 ovc model.onnx --compress_to_fp16=False
转换后将生成.xml和.bin两个文件,.xml文件描述了模型的结构,.bin文件包含了模型各层的参数。
推理代码如下:
1 #include 2 #include 3 #include 4 #include 5 #include 6 #include 7 #include 8 const int length = 300; 9 void read_csv(const char* filepath, float* input) 10 { 11 std::ifstream file(filepath); 12 std::string line; 13 if (file.is_open()) 14 { 15 std::getline(file, line); 16 for (int i = 0; i < 300; i++) 17 { 18 std::getline(file, line); 19 std::stringstream ss(line); 20 std::string field; 21 if (std::getline(ss, field, ',')) 22 { 23 if (std::getline(ss, field, ',')) 24 { 25 input[i] = std::stof(field); 26 } 27 } 28 } 29 file.close(); 30 } 31 float maxVal = *std::max_element(input, input + 300); 32 for (int i = 0; i < 300; i++) 33 { 34 input[i] /= maxVal; 35 } 36 } 37 std::vector softmax(std::vector input) 38 { 39 std::vector output(input.size()); 40 float sum = 0; 41 for (int i = 0; i < input.size(); i++) 42 { 43 output[i] = exp(input[i]); 44 sum += output[i]; 45 } 46 for (int i = 0; i < input.size(); i++) 47 { 48 output[i] /= sum; 49 } 50 return output; 51 } 52 void warmup(ov::InferRequest request) 53 { 54 std::vector inputData(length); 55 memcpy(request.get_input_tensor().data(), inputData.data(), length * sizeof(float)); 56 request.infer(); 57 } 58 int main() 59 { 60 const char* modelFile = "/home/up/openvino/AutoInjector_Transformer/AutoInjector_Transformer/2024-07-17-17-28-00_best_model.xml"; 61 const char* dirpath = "/home/up/openvino/AutoInjector_Transformer/AutoInjector_Transformer/data"; 62 const char* device = "GPU"; 63 std::vector inputs(length); 64 std::vector outputs(length * 4); 65 ov::Core core; 66 // Load Model 67 std::cout << "Loading Model" << std::endl; 68 auto start_load_model = std::chrono::high_resolution_clock::now(); 69 auto model = core.read_model(modelFile); 70 auto compiled_model = core.compile_model(model, device); 71 ov::InferRequest request = compiled_model.create_infer_request(); 72 std::cout << "Model Loaded, " << "time: " << std::chrono::duration_cast(std::chrono::high_resolution_clock::now() - start_load_model).count() << "ms" << std::endl; 73 request.get_input_tensor().set_shape(std::vector{1, length}); 74 // Warmup 75 warmup(request); 76 for (auto& filename : std::filesystem::directory_iterator(dirpath)) 77 { 78 std::string pathObj = filename.path().string(); 79 const char* filepath = pathObj.c_str(); 80 std::cout << "Current File: " << filepath << std::endl; 81 // Read CSV 82 auto start = std::chrono::high_resolution_clock::now(); 83 read_csv(filepath, inputs.data()); 84 memcpy(request.get_input_tensor().data(), inputs.data(), length * sizeof(float)); 85 // Infer 86 request.infer(); 87 // Get Output Data 88 memcpy(outputs.data(), request.get_output_tensor().data(), length * sizeof(float) * 4); 89 // Softmax 90 std::vector softmax_results(length); 91 std::vector temp(4); 92 std::vector softmax_tmp(4); 93 for (int i = 0; i < length; i++) 94 { 95 for (int j = 0; j < 4; j++) 96 { 97 temp[j] = outputs[j * length + i]; 98 } 99 softmax_tmp = softmax(temp); 100 auto maxVal = std::max_element(softmax_tmp.begin(), softmax_tmp.end()); 101 auto maxIndex = std::distance(softmax_tmp.begin(), maxVal); 102 softmax_results[i] = maxIndex; 103 } 104 std::cout << "Infer time: " << std::chrono::duration_cast(std::chrono::high_resolution_clock::now() - start).count() << "ms" << std::endl; 105 106 // Print outputs 107 for (int i = 0; i < length; i++) 108 { 109 std::cout << softmax_results[i] << " "; 110 } 111 } 112 return 0; 113 }
使用 cmake 进行构建,在 CMakeLists.txt 中指定变量 ${OpenVino_ROOT} 为前面解压的 OpenVINO 压缩包路径:
1 cmake_minimum_required(VERSION 3.10.0) 2 3 project(AutoInjector_Transformer) 4 5 set(CMAKE_CXX_STANDARD 20) 6 set(CMAKE_CXX_STANDARD_REQUIRED ON) 7 set(OpenVino_ROOT /home/up/openvino/l_openvino_toolkit_ubuntu22_2024.3.0.16041.1e3b88e4e3f_x86_64/runtime) 8 set(OpenVINO_DIR ${OpenVino_ROOT}/cmake) 9 10 find_package(OpenVINO REQUIRED) 11 12 include_directories( 13 ${OpenVino_ROOT}/include 14 ${OpenVino_ROOT}/include/openvino 15 ) 16 17 link_directories( 18 ${OpenVino_ROOT}/lib 19 ${OpenVino_ROOT}/lib/intel64 20 ) 21 22 add_executable(AutoInjector_Transformer AutoInjector_Transformer.cpp) 23 target_link_libraries(AutoInjector_Transformer openvino)
然后 cmake 构建项目:
1 mkdir build && cd build 2 cmake .. 3 make
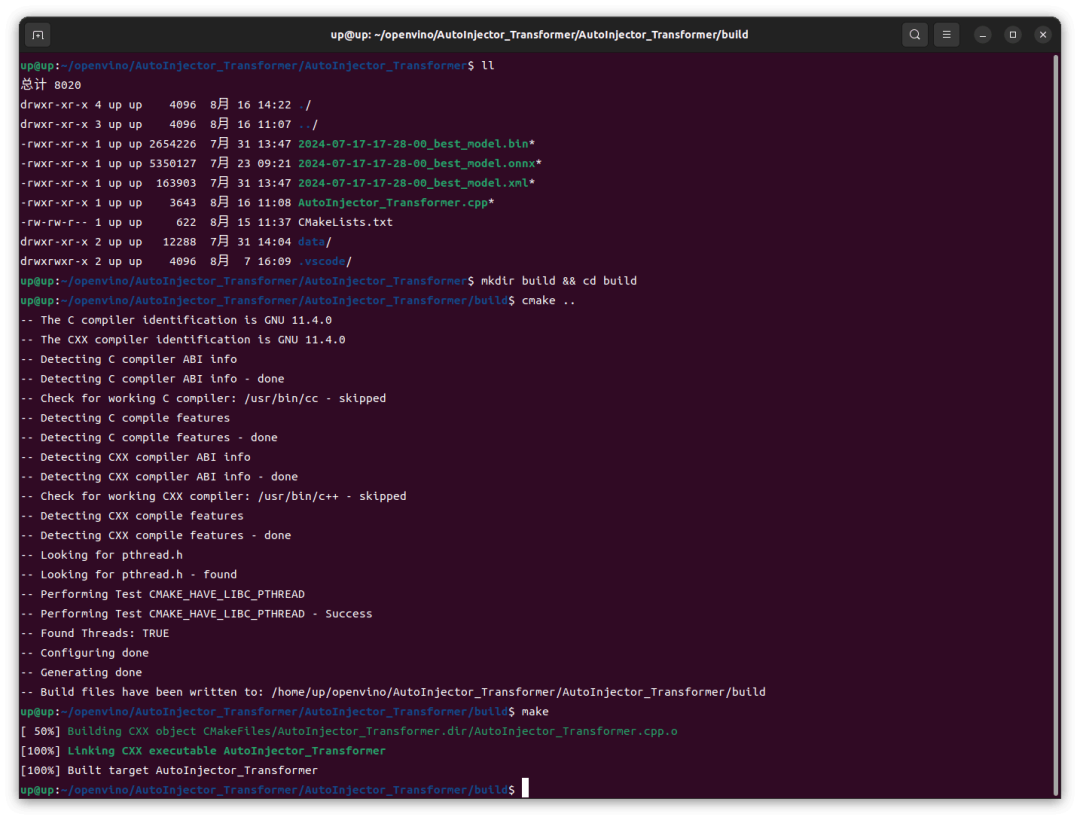
然后运行生成的可执行文件:
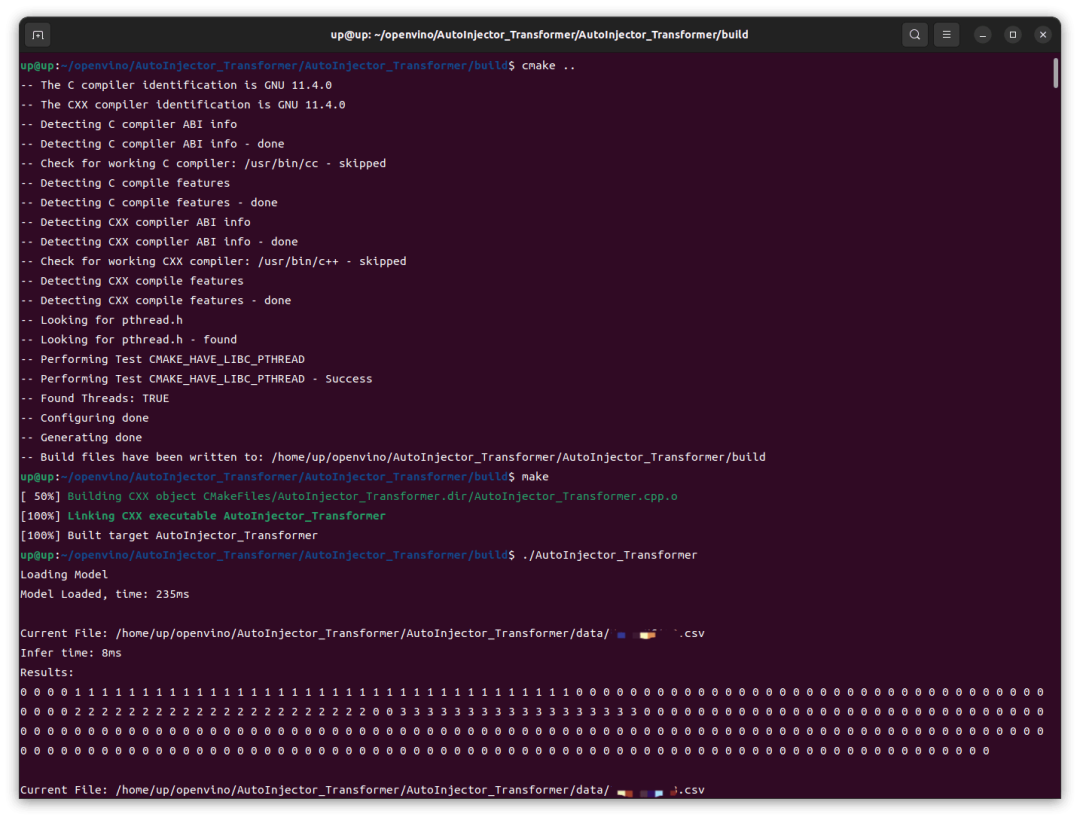
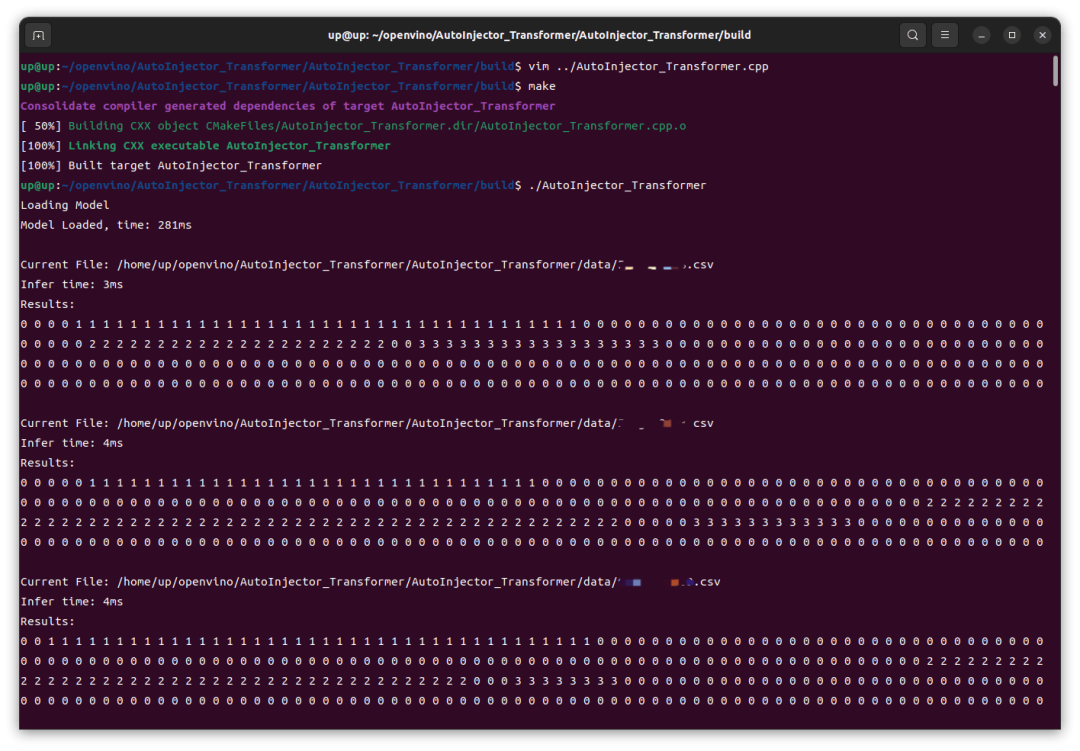
可以看到,在 Intel iGPU 上的推理速度还是很快的,前几次推理稍慢,8ms,后续基本稳定在 4ms,这跟我之前在 RTX4060 GPU 上用 TensorRT 推理并没有慢多少。然后我这里修改了代码改为 CPU 运行,重新编译、运行,结果在 Intel CPU 上的速度还要更快一点。
-
迅为RK3568开发板模型推理测试实战LPRNet 车牌识别2025-08-25 1784
-
基于哪吒开发板部署YOLOv8模型2024-11-15 2132
-
使用OpenVINO Model Server在哪吒开发板上部署模型2024-11-01 1496
-
使用OpenVINO C++在哪吒开发板上推理Transformer模型2024-10-12 1737
-
OpenVINO2024 C++推理使用技巧2024-07-26 2461
-
英特尔开发套件『哪吒』在Java环境实现ADAS道路识别演示 | 开发者实战2024-04-29 1798
-
如何使用OpenVINO C++ API部署FastSAM模型2023-11-17 2089
-
基于OpenVINO C# API部署RT-DETR模型2023-11-10 2143
-
在Ubuntu上搭建OpenVINO C++程序开发环境2023-08-09 2073
-
用OpenVINO™ C++ API编写YOLOv8-Seg实例分割模型推理程序2023-06-25 3430
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-05 2243
-
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型2023-05-26 2967
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 2857
-
基于OpenHarmony开发板上测试Native C++应用开发2022-10-08 6307
全部0条评论

快来发表一下你的评论吧 !
