

基于Arm Neoverse N2实现自动语音识别技术
描述
作者:安谋科技 (Arm China) 高级软件产品经理 杨喜乐
自动语音识别 (Automatic Speech Recognition) 技术已经深入到现代生活的方方面面,广泛应用于从语音助手、转录服务,到呼叫中心分析和语音转文本翻译等方面,为各行各业提供了创新解决方案,显著提升了用户体验。
随着机器学习 (ML) 和深度学习的最新进展,自动语音识别技术的精密性已经达到一个新的高度。现在,自动语音识别软件可以非常准确地理解各种口音、方言和说话风格。FunASR 是阿里巴巴达摩院开发的一款先进的开源自动语音识别工具包。它为开发和部署自动语音识别系统提供了一套全面的工具和模型。
FunASR 兼容 CPU 和 GPU 计算。虽然 GPU 为训练深度学习模型提供了出色的性能,但 CPU 在边缘侧和数据中心服务器中更为普遍,并且更适合模型推理。因此,FunASR 可以在 CPU 上进行高效的自动语音识别推理,并能在 GPU 加速不可用的情况下(如成本限制、功耗限制或缺乏可用性等),依然能够顺利部署。
Arm Neoverse N2 是一款专为云和边缘计算设计的高性能 CPU 处理器。它可以支持包括人工智能 (AI) 和 ML 在内的多种云工作负载,并增加了 SVE2、Bfloat16 (BF16) 数据格式和 MMLA 等 AI 功能。
SVE2 使开发者能够操作更大的数据向量,提升并行处理能力和执行效率,这对于 AI 模型训练和推理阶段涉及的大量数学计算尤为重要。
BF16 是一种较新的浮点格式,专为 AI 和 ML 应用而设计。它提供与 32 位浮点数相同的动态范围,但仅占用 16 位存储空间,有效缩小了模型尺寸,并显著提升了计算效率。
MMLA 是 Armv8.6 中的一个架构特性。它为 GEMM 运算提供了显著加速。GEMM 是 ML 中的一种基本算法,对两个输入矩阵进行复杂的乘法运算,得到一个输出。
Arm 此前推出了 Arm Kleidi 技术,这是一套专为开发者设计的赋能技术,旨在增强 Arm Neoverse、Arm Cortex 等 Arm 平台上的 AI 性能。Kleidi 技术广泛涉及从框架到高度优化的算子库,再到充满活力的独立软件供应商 (ISV) 生态系统,全面覆盖了 AI 开发的关键环节。
在本文中,我们将分享在基于 Neoverse N2 的阿里巴巴倚天 710 平台上部署 FunASR 推理过程及基准测试方法。同时,我们将通过启用 Arm Kleidi 技术进行对比分析,重点介绍与其他基于 CPU 和 GPU 的平台相比,在倚天 710 CPU 上运行 FunASR 推理在性价比方面的主要优势。
基准测试设置
软件版本:
Ubuntu 22.04(64 位)
PyTorch v2.3.0
pip install funasr==0.8.8
pip install modelscope==1.10.0
模型:speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
请确保系统上安装了 PyTorch 和相关的 python 库[1],如果在 Arm 平台上运行,可使用 Arm 在 docker 仓库中提供的 PyTorch docker 镜像[2],以便进行快速评估。
1对环境进行初始化并导入所需的依赖项
export OMP_NUM_THREADS=16
export DNNL_VERBOSE=1
import torch
import torch.autograd.profiler as profiler
import os
import random
import numpy as np
from funasr.tasks.asr import ASRTaskParaformer as ASRTask
from funasr.export.models import get_model
from modelscope.hub.snapshot_download import snapshot_download
<< 滑动查看 >>
2下载并配置模型
Paraformer 是阿里巴巴达摩院在 FunASR 开源项目中开发的一款高效自动语音识别模型,旨在提高端到端语音识别系统的鲁棒性和效率。该模型基于 Transformer 架构,并融入了多项创新,以提升其在语音识别中的性能。为了进行基准测试,我们将使用魔搭社区中的 FunASR paraformer 模型[3]。
model_dir = snapshot_download('damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch', cache_dir='./',revision=None)
#set the radom seed 0
random.seed(0)
np.random.seed(0)
torch.random.manual_seed(0)
model, asr_train_args = ASRTask.build_model_from_file(
'damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/config.yaml','damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/model.pb' ,'damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/am.mvn' , 'cpu')
model = get_model(model, dict(feats_dim=560, onnx=False, model_name="model"))
<< 滑动查看 >>
3使用性能分析器运行以获取模型推理结果
推理运行十次迭代以获得平均结果。
batch = 64
seq_len = 93
dim = 560
speech = torch.randn((batch, seq_len, dim))
speech_lengths = torch.tensor([seq_len for _ in range(batch)], dtype=torch.int32)
with torch.no_grad():
with profiler.profile(with_stack=True, profile_memory=False, record_shapes=True) as prof:
for _ in range(10):
model(speech, speech_lengths)
print(prof.key_averages(group_by_input_shape=True).table(sort_by='self_cpu_time_total', row_limit=200))
<< 滑动查看 >>
使用 BF16 Fast Math 内核加速推理
作为 Arm Kleidi 技术的一部分,Arm Compute Library (ACL) 通过利用 BF16 MMLA 指令,提供了优化的 BF16 通用矩阵乘法 (GEMM) 内核。这些指令在 Neoverse N2 CPU 中得到支持,并且从 PyTorch 2.0 版本开始便通过 oneDNN 后端集成到了 PyTorch 中。ACL 中的 Fast Math GEMM 内核可以高度优化 CPU 上的推理性能。
要启用 Fast Math GEMM 内核,请在运行推理之前设置以下环境变量:
$ export DNNL_DEFAULT_FPMATH_MODE=BF16
我们发现,在基于 Neoverse N2 的倚天 710 平台上启用 BF16 Fast Math 内核后,与默认的 FP32 内核相比,性能提高了约 2.3 倍。
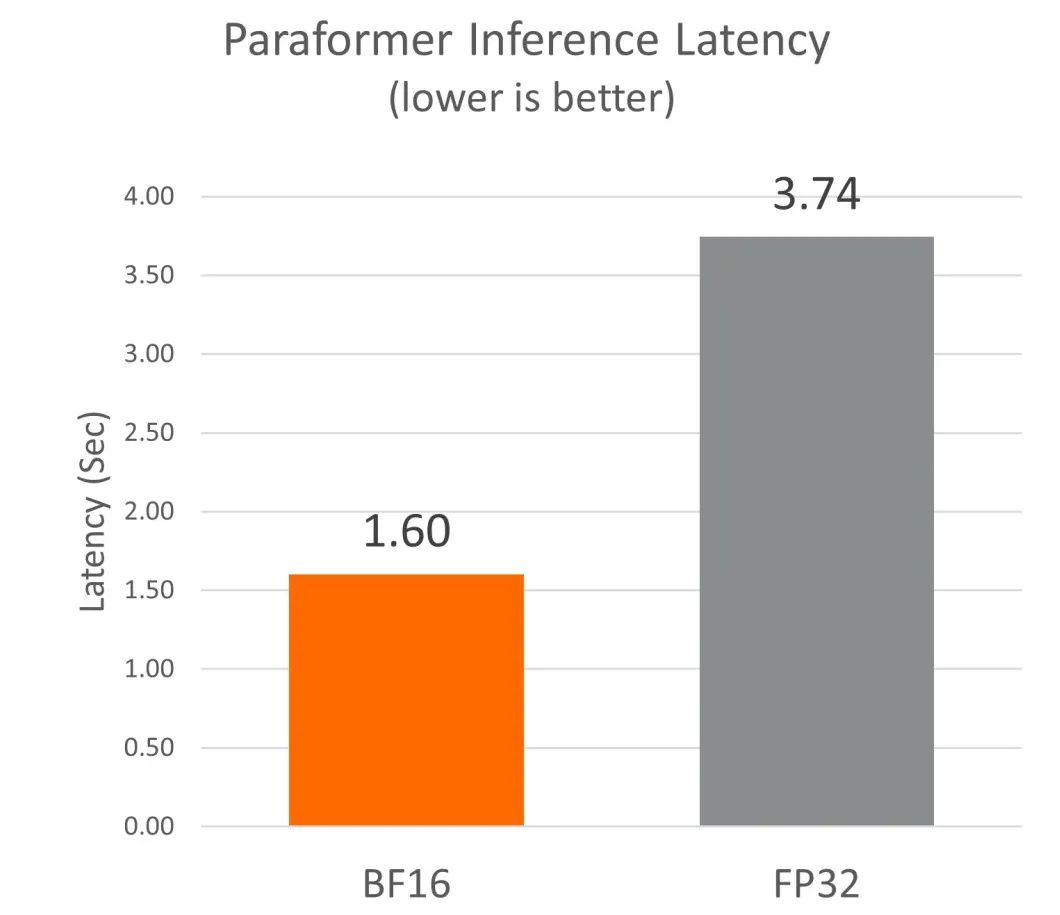
性能比较
我们还比较了 FunASR paraformer 模型在倚天 710 和阿里云其他同等级别云实例上的性能*。
Arm Neoverse N2(倚天 710):
ecs.c8y.4xlarge (16 vCPU + 32GB)
第 4 代英特尔至强“Sapphire Rapids”:
ecs.c8i.4xlarge (16 vCPU + 32GB)
第 4 代 AMD EPYC“Genoa”:
ecs.c8a.4xlarge (16 vCPU + 32GB)
*使用 armswdev/pytorch-arm-neoverse:r24.07-torch-2.3.0-onednn-acl docker 镜像的倚天 710[2],适用于英特尔 Sapphire-Rapids 和 AMD Genoa 的官方 PyTorch v2.3.0
我们发现,基于 Neoverse N2 的倚天 710,搭配 BF16 Fast Math 内核,使得 paraformer 自动语音识别模型的推理性能较同等级别的 x86 云实例有高达 2.4 倍的优势。
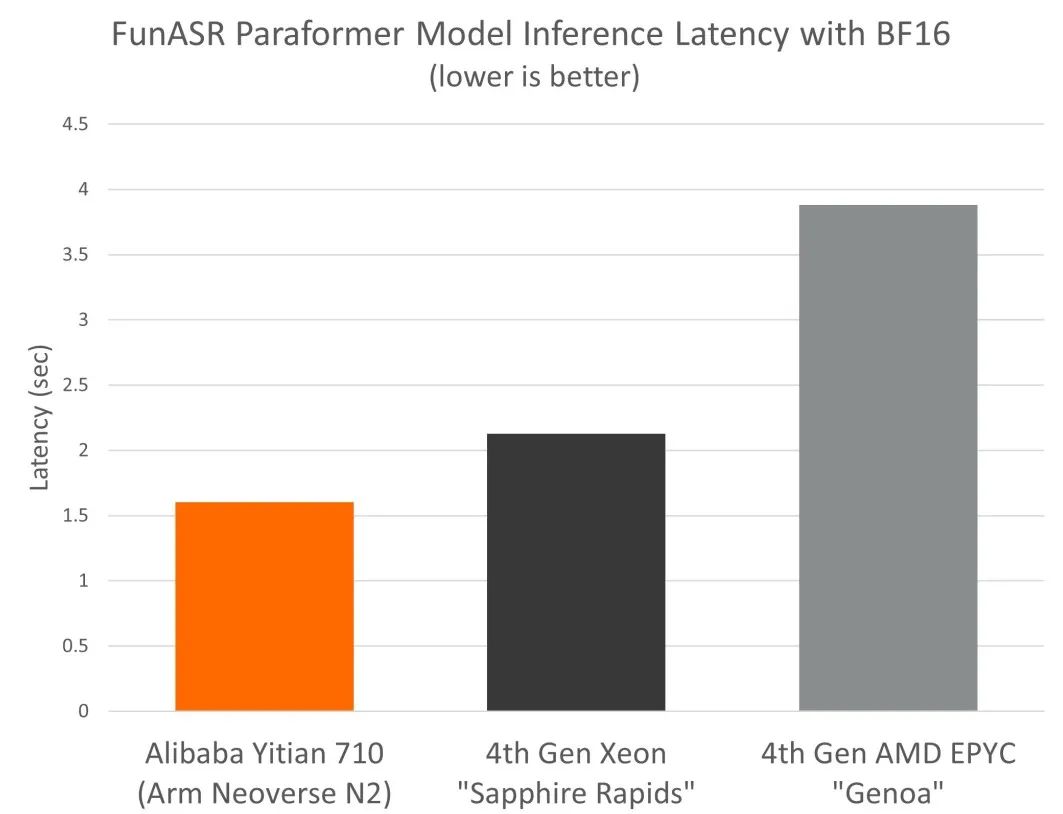
在实际推理部署中,成本是 AI 部署的主要考虑因素之一,对技术的实现和采用有很大的影响。为全面了解 CPU 和 GPU 平台上自动语音识别推理部署的总体拥有成本 (TCO),我们将 NVIDIA A10 GPU 也纳入对比分析中。得益于 Neoverse N2 出色的性能和能效,倚天 710 平台相较于同等级别 x86 实例和 GPU 平台,展现出更高的成本效益,这一点也体现在了阿里云倚天 710 实例更普惠的定价上。

从基准测试结果来看,倚天 710 在自动语音识别推理部署的 TCO 方面具有显著优势,其性价比较同等级别 x86 和 GPU 平台高出 3.5 倍。
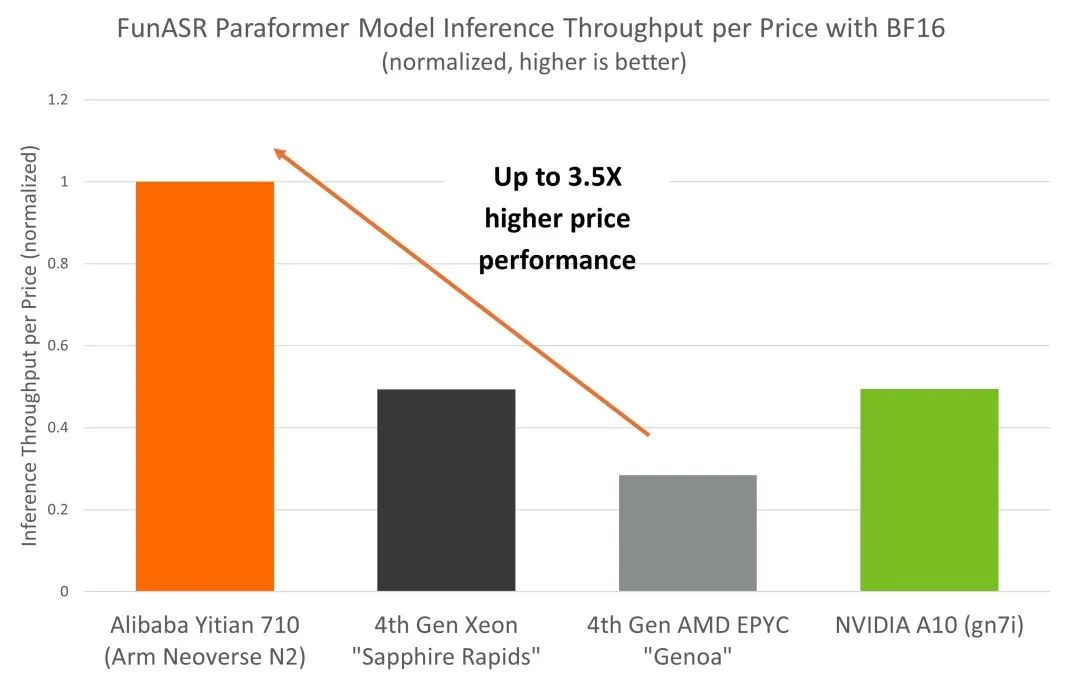
结论
基于 Arm Neoverse N2 的阿里巴巴倚天 710 具有 BF16 MMLA 扩展等特定 ML 功能,为采用 Arm Kleidi 技术的 FunASR paraformer 模型提供了出色的推理性能。开发者在倚天 710 上构建自动语音识别应用可实现更高性价比。
-
如何在Arm Neoverse N2平台上提升llama.cpp扩展性能2026-02-11 474
-
Arm Neoverse N2平台实现DeepSeek-R1满血版部署2025-07-03 1541
-
Arm新Arm Neoverse计算子系统(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N32024-04-24 3393
-
Arm 更新 Neoverse 产品路线图,实现基于 Arm 平台的人工智能基础设施2024-02-22 1043
-
ARM Neoverse™N2参考设计技术概述2023-08-29 611
-
Arm Neoverse™ N2核心加密扩展技术参考手册2023-08-17 845
-
Arm Neoverse™ N1 PMU指南2023-08-12 918
-
ARM Neoverse™N2软件优化指南2023-08-11 622
-
Arm Neoverse N2汽车硬件技术概述2023-08-10 742
-
ARM Neoverse N2 PMU指南2023-08-09 765
-
Arm Neoverse家族新增V1和N2两大平台,突破高性能计算瓶颈2021-04-30 11458
-
互联网巨头纷纷启用Arm CPU架构,Arm最新Neoverse V1和N2平台加速云服务器芯片自研2020-09-30 1819
全部0条评论

快来发表一下你的评论吧 !
