

智能无处不在:安谋科技“周易”NPU开启端侧AI新时代
制造/封装
描述
在科技之光的照耀下,大模型从云端的殿堂飘然而至终端的舞台。这一历史性的跨越,不仅赋予了数据处理以迅捷之翼,更将智能体验推向了前所未有的高度。终端上的大模型以灵动的姿态,即时捕捉并回应着每一个细微的需求,将AI的触角延伸至世界的每一个角落。

近日,在EEVIA主办的第12届中国硬科技产业链创新趋势峰会暨百家媒体论坛上,安谋科技产品总监鲍敏祺发表了精彩的主题演讲《端侧AI应用芯机遇,NPU加速终端算力升级》。他深入剖析了端侧AI发展的广阔前景,并详细介绍了安谋科技自研NPU的最新进展。
端侧AI正在崛起

AIGC大模型带来的算力提升是端侧AI迎来的最大机遇。鲍敏祺表示,从近期头部大厂的发布中都可以看出,端侧AI的应用已经得到了业界的一致认可。

当前,国际和国内实际部署的主流端侧大模型体量主要集中在100亿参数以下。这一限制主要是由于端侧设备的内存带宽范围通常在50-100GB/s之间。为了满足用户对应用实时性的需求,10-30亿参数的大模型最适合部署在现有的带宽条件下。这些模型能够在保持高效性能的同时,提供快速响应和高质量的服务。
头部终端厂商如OPPO、vivo、小米、荣耀和华为等,都在积极推动端侧AI的发展。他们不仅自研了适合端侧部署的大模型,还将其与具体业务场景紧密结合。芯片厂商也达成了共识,认为AI NPU(神经网络处理单元)将是未来消费类电子产品发展的重点。NPU通过专门优化的硬件架构,能够大幅提升端侧设备的AI计算能力,同时降低功耗。
尽管端侧AI的发展势头强劲,但鲍敏祺强调,这并不意味着要彻底放弃云端AI。相反,他认为两者应该实现互补,才能产生最大的收益。端侧AI的优势在于其时效性和数据本地化带来的安全性。由于数据处理发生在设备本地,用户的隐私得到更好的保护,同时也能实现实时响应。而云端AI则具备更强的推理能力和大规模数据处理能力,可以进行更复杂的任务。因此,结合端侧和云端的优势,将为用户提供更加全面和高效的AI体验。
从人机交互界面的发展历史来看,从最初的物理按键到触摸屏和语音交互,再到当前的Agent智能体,每一次变革都极大地提升了用户体验。未来的趋势将是多模态场景,即结合图像、音频、视频等多种输入方式,使设备能够更全面地理解用户的需求。通过观察和学习,未来的AI系统将能够更好地预测和满足用户的期望,从而实现真正的智能化。
以三重升级应对三重挑战
端侧AI的快速发展给硬件设备带来了三重挑战:成本、功耗和生态系统。
成本的挑战主要来自于设备的存储容量、带宽和芯片计算资源。功耗则源自对数据的大量搬运,而且大模型无法像CNN一样实现高度复用,也会大幅提升功耗。最后,开发工具的不断优化和支持也是挑战所在。
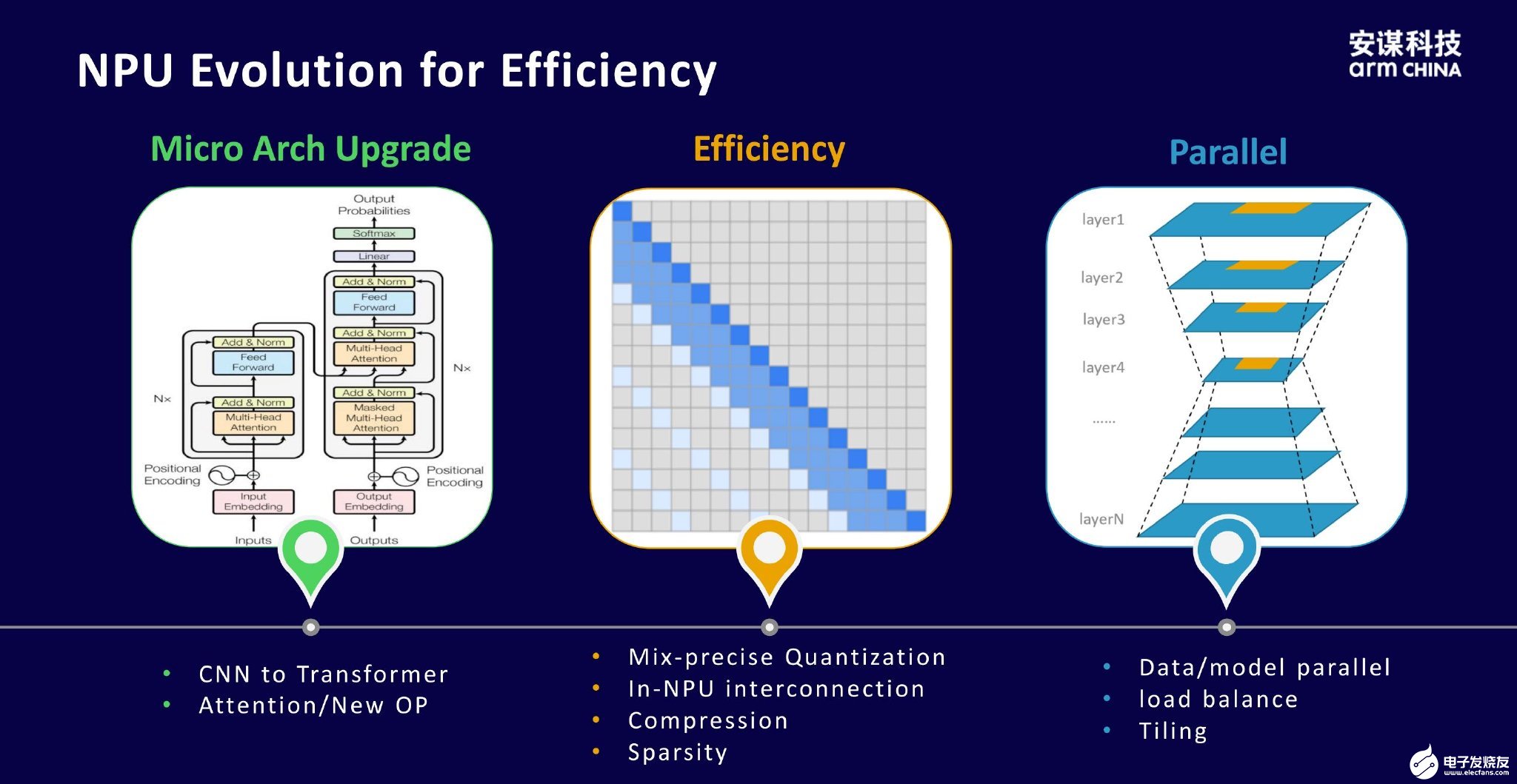
针对这些挑战,安谋科技自研的“周易”NPU围绕微架构、能效和并行处理等方面进行了升级。
● 微架构:鉴于CNN与Transformer的差异性,“周易”NPU在保留CNN能力的基础上,又针对Transformer进行了优化,克服了实际计算中的瓶颈。
● 效率:进行混合精度的量化,比如int4和fp16,在算法和工具链层面上实现低精度量化。同时,对数据进行无损压缩和改变稀疏度,从而增加有效带宽。另外,采用In-NPU interconnection技术,实现了对总线带宽的扩展。
● 并行处理:采用数据并行或模型并行,使用负载均衡和Tiling,减少了数据的搬运。
鲍敏祺还详细介绍了下一代的周易“NPU”架构,不仅包含了能够适应多任务场景的Task Schedule Manager,而且整个架构具备可扩展能力,并增加DRAM以实现高带宽的匹配,还增加了OCM(Optional on Chip SRAM),以支持有特殊要求的算法。

鲍敏祺在演讲中特别强调了“周易”NPU对异构计算的支持,并指出无论是从能效还是整个SoC(系统级芯片)的面积角度来看,异构计算都是端侧AI芯片的最佳选择。他解释道,面对不同的应用场景,异构计算能够实现算力的灵活裁剪,并将不必要的功耗降到最低。
跨领域的应用专家
周易“NPU”已经在多个关键领域展示了其强大的性能和灵活性,特别是在汽车应用、AI加速卡以及AIoT场景中。
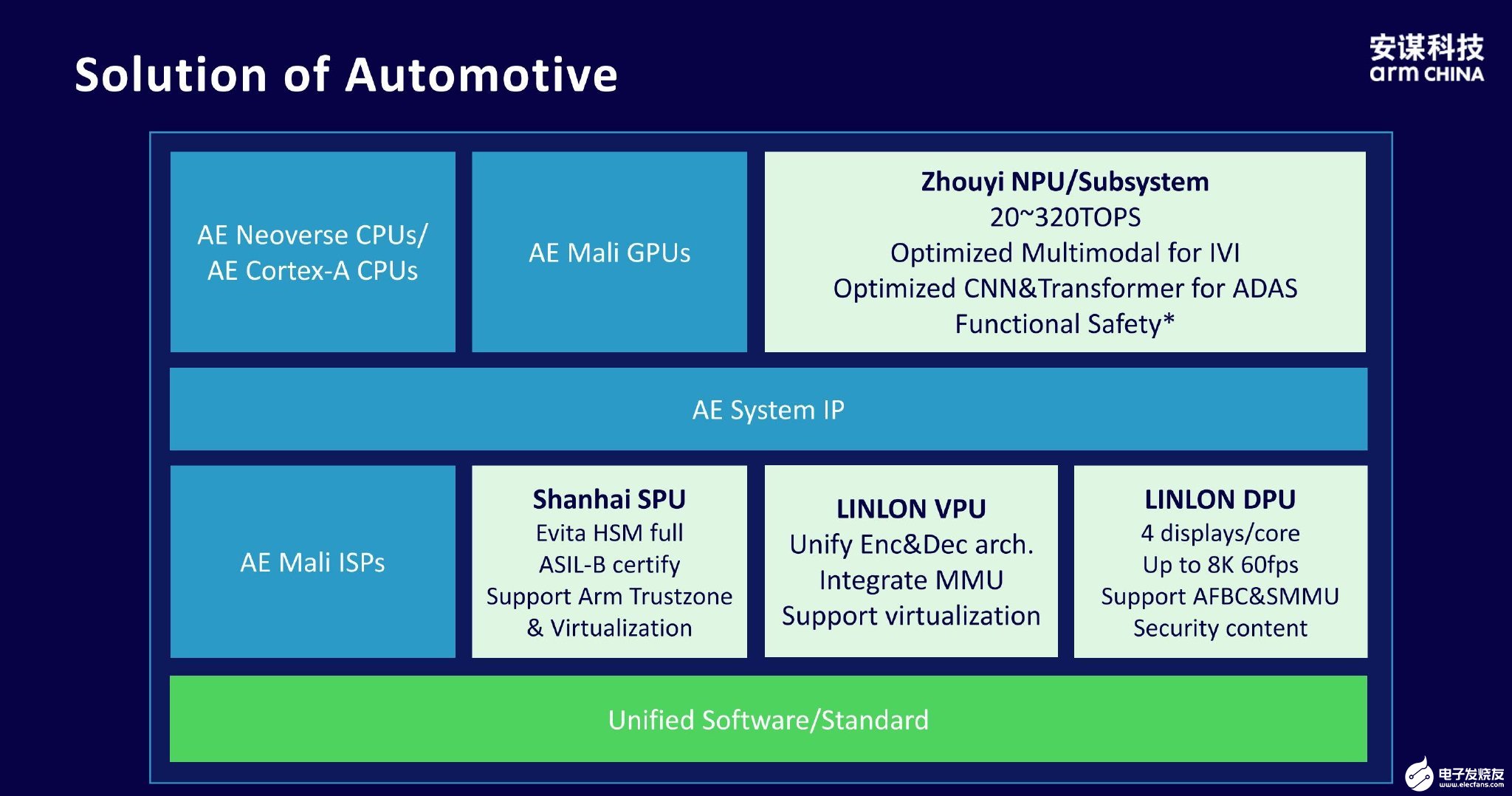
在汽车应用中,不同的场景会对应不同的算力需求。如果是车载信息娱乐系统,对算力的要求不会太高,但是在ADAS应用中,很多情况下要执行多任务,对算力的要求就会大幅提升。而“周易”NPU的算力范围是20~320TOPS,可以根据需求裁剪出所需的算力。鲍敏祺表示,搭载了“周易”NPU的芯擎科技“龍鷹一号”已累计出货超过40万片,并成功定点应用于吉利旗下的领克、银河系列以及一汽红旗等20余款主力车型中。
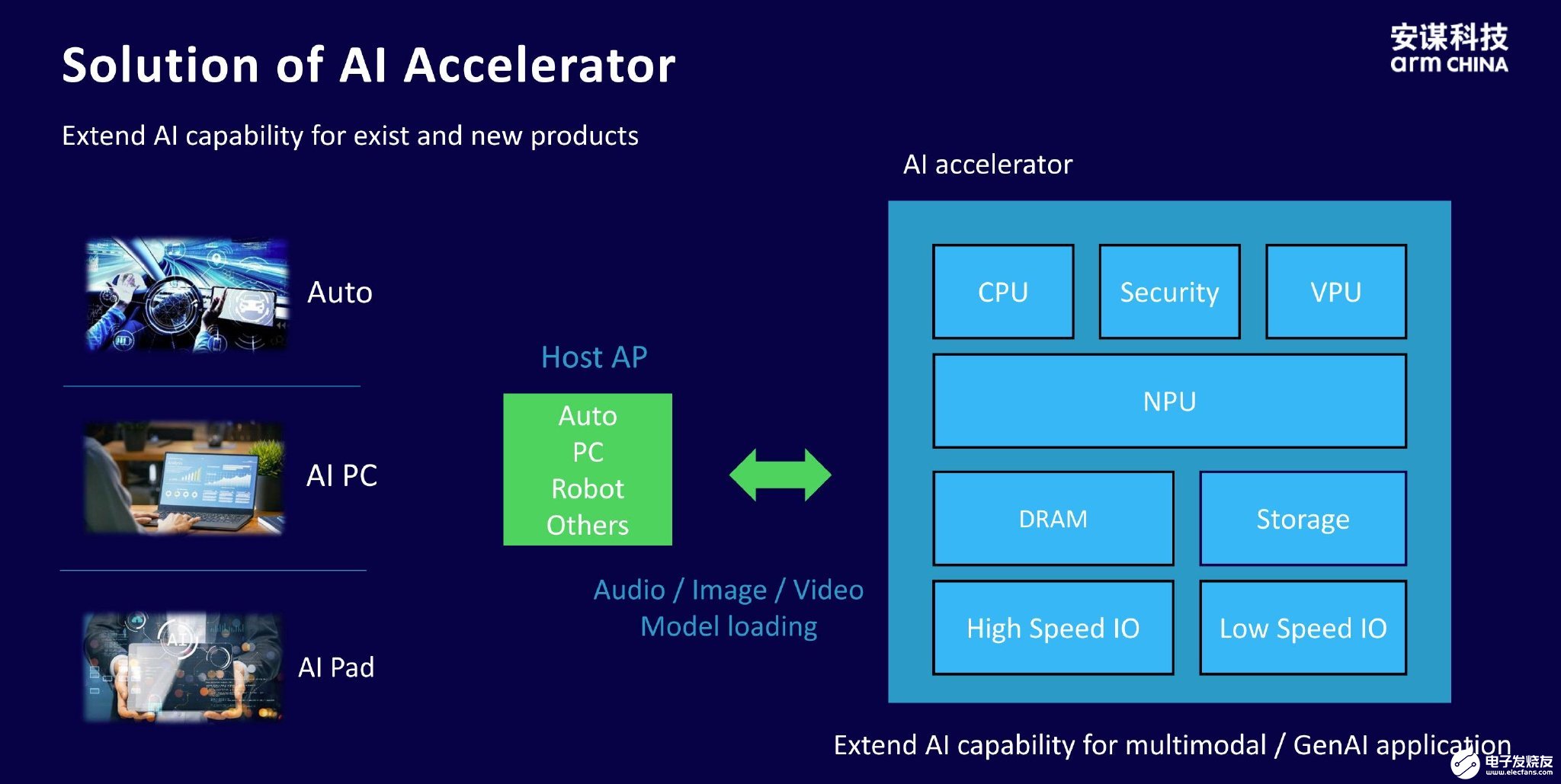
在AI加速卡的应用中,周易“NPU”能够与智能汽车、PC、机器人等不同类型的主机处理器(Host AP)进行高效交互,处理音频、图像、视频等多种数据形式。这种多模态模型的支持能力使得周易“NPU”能够在复杂的数据环境中保持高性能和灵活性。在AIoT场景中,设备通常受到面积和功耗的严格限制。尽管如此,周易“NPU”仍能提供高效的算力支持,同时保证高度的安全性。这使得它成为多个应用场景的理想选择。
鲍敏祺最后表示,下一代周易“NPU”将会继承并显著增强前代产品的强算力、易部署以及可编程等特点和优势,并围绕精度、带宽、调度管理、算子支持等多个方面进行持续优化。同时,NPU不仅要考虑适配现在的存储介质,还要考虑到对未来各种存储介质的适配,使得NPU能够更好地满足当前及未来市场需求。
- 相关推荐
- 热点推荐
- 安谋科技
-
端侧AI需求大爆发!安谋科技发布新一代NPU IP,赋能AI终端应用2025-07-11 9124
-
无处不在的嵌入式如何改变生活?2014-09-01 3928
-
如何提高人工智能应用开发的生产效率2021-02-01 2201
-
能量收集应用无处不在2021-03-19 977
-
权力管理无处不在2021-04-22 629
-
安谋科技“周易”NPU软件开源项目上线2022-11-21 1590
-
自研矩阵再添新军!安谋科技发布新一代“周易”X2 NPU2023-03-28 906
-
影像无处不在,回忆如何“安”放2023-05-22 3052
-
广和通开启端侧AI新时代2024-12-12 1688
-
软硬协同优化,安谋科技新一代“周易”NPU实现DeepSeek-R1端侧高效部署2025-02-14 408
-
安谋科技“周易”NPU成功部署DeepSeek-R12025-02-19 1260
-
安谋发布“周易”X3 NPU,破局AI算力,智绘未来蓝图2025-11-17 448
-
安谋科技:端侧NPU技术创新,拉动AI算力落地引擎2025-12-09 6157
-
应对端侧AI算力、内存、功耗“三堵墙”困境,安谋科技Arm China “周易”X3给出技术锦囊2025-12-18 553
-
MWC 2026|展锐芯,让AI无处不在2026-03-02 1939
全部0条评论

快来发表一下你的评论吧 !
