

如何构建一个演示移动端应用
描述
作者:Arm 战略与生态部工程师 Ayaan Masood
作为通讯工具,视频会议几乎随处可见,尤其适用于远程办公和社交互动。但其使用体验并非总是简单直接、即开即用,可能需要进行调整,确保音频视频设置良好。其中,照明便是一个难以把握的因素。在会议中,光线充足的视频画面会显得得体大方,而糟糕的照明条件则会显得不够专业,还会分散其他与会者的注意力。有时,改变光照情况并不可行,特别是在光线昏暗的冬季或照明不足的地点。
在本文中,我们将探讨如何构建一个演示移动端应用,以解决弱光条件下的视频照明问题。我们将介绍支持该应用的神经网络模型及其机器学习 (ML) 管线、性能优化等。
找到合适的神经网络
我们采用基于神经网络的解决方案改善视频照明。因此,这项工作的核心在于找到适合当前任务的神经网络。目前,市面上有很多出色的开源模型可供使用,而为本项目找到合适的候选模型至关重要。我们在评估模型时主要关注以下三项要求:性能良好、照明质量出色、视频处理表现优异。
我们的目标是实现移动端实时推理,这意味着,每帧处理时间只有严格控制在 33 毫秒内,才能实现每秒 30 帧的流畅播放。其中包括预处理/后处理步骤以及神经网络运行所需的时间。视频画质增强是另一项重要标准。该模型可智能化增强暗像、还原细节,确保视频帧之间暂时保持连贯,避免画面闪烁。
模型架构
所选模型来自 2021 年研究论文《用于弱光图像/视频增强的语义引导零样本学习》[1]。在包含混合曝光和照明条件的复杂数据集上进行测试时,该模型的弱光增强质量非常出色。暗像中不清晰的细节和结构突然变得清晰起来。该模型的另一个优点是尺寸极小,仅有一万个网络参数,因此推理速度很快。在模型架构方面,输入的图像张量被缩小并传递到卷积层栈。这些层会预测逐像素增强因子,然后在模型后处理模块中,将增强因子以乘法方式应用到原始图像像素上,从而生成增强的图像。
值得一提的是,训练采用包含两千张合成图像的小型数据集,这就表明,如果数据集规模更大,模型就还有更大提升空间。我们增强了真实参照图像,生成一系列统一曝光值,从而调整图像明暗。该模型的训练不受监督,无需标签,而是通过一个指导训练的损失函数来学习如何增强弱光图像。这个损失函数是多个独立损失的组合,它们分别负责图像的各个方面,如颜色、亮度和语义信息。
ML 管线
该应用的 ML 管线从输入帧开始,根据模型输入张量要求加以处理,然后推理并向用户显示输出。拦截相机帧进行推理是 CameraX 库的内置功能,通过安卓的“图像分析”API 实现。
我们采用了两种不同的 ML 推理引擎:ONNX runtime和 TensorFlow Lite。将 Pytorch 模型导出为 ONNX 模型是 Pytorch 库自带的功能,而导出到 TensorFlow Lite 则困难得多。该模型的有效导出器为 Nobuco,其工作机制是先创建可转换为 TFLite 的 Keras 模型。
模型推理产生的输出格式取决于 ML 运行时。如果采用 ONNX,则为 NCHW(即数量、通道、高度、宽度);如果采用 TFLite,则为 NHWC,其中通道排在末尾。这影响了后处理步骤的完成方式,即将整数 RGB 值的输出缓冲区解包,以创建终末位图,并显示在屏幕上。
结果呈现
性能优化
在 Kotlin 中将 RGBA 位图转换为 RGB 的计算成本很高。当性能预算限制在 33 毫秒以内时,仅转换过程就需要花费几十毫秒。为了加快速度,我们使用了 C++ 语言,并对编译器进行了全面优化。但是,要从 Kotlin 代码调用 C++ 代码,就得用到 Java 原生接口 (JNI)。通过 JNI 传递一个 3x512x512 大小的浮点数缓冲区成本很高,因为必须复制两次,先从 Kotlin 复制到 C++,处理完后再复制回 Kotlin。为了解决这个问题,我们使用了 Java 直接缓冲区。传统缓冲区的内存由安卓运行时在堆上分配,C++ 不容易访问。而直接缓冲区必须按照系统的正确字节顺序分配,而一旦分配好了,内存就能以操作系统和 C++ 易于访问的方式分配。这样,我们就省去了复制到 JNI 的时间,并能够利用高度优化的 C++ 代码。
量化
该模型使用量化技术进行优化。量化就是使用较低精度表示神经网络的权重和激活值,从而在略微牺牲模型质量的情况下提高推理速度。量化用的数据类型通常比较小,例如 INT8,它占用的空间只有原来 32 位浮点数 (FP32) 的四分之一。模型量化有两种:动态量化和静态量化。动态量化仅量化模型权重,并在运行时,针对激活值确定量化参数。静态量化则事先使用代表性数据集量化权重和激活值,所以在推理方面更快。对于这个模型,静态量化提高了推理速度,而输出照明增强效果则略暗一些,这样的取舍是值得的。
模型推理时间
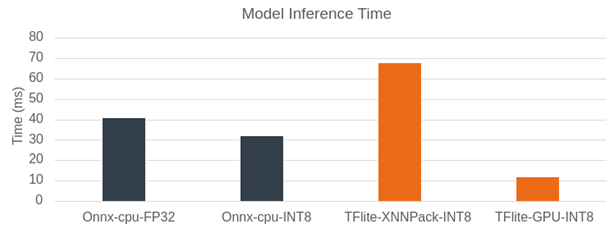
图:模型推理时间 Pixel 7
上图比较了使用 ONNX runtime 和 TensorFlow Lite 对弱光增强模型进行模型推理的时间。在 Pixel 7 上的分辨率为 512x512。我们先将 ONNX runtime 作为推理引擎。在 CPU 上运行时,FP32 的模型推理时间为 40 毫秒。当量化到 INT8 时,这一时间缩短到 32 毫秒。性能原本有望获得大幅提升,但使用可视化工具 Netron 分析模型文件后发现,模型图中增加了额外的量化/反量化算子,从而增加了计算开销。使用 XNNPack 和 INT8 模型的 TensorFlow Lite 在 CPU 上的表现稍慢于 ONNX runtime,推理时间接近 70 毫秒。不过,TensorFlow Lite 在使用 GPU 处理时,超越了之前所有推理引擎和模型类型的组合。对于 512x512 输入图像的推理,TensorFlow Lite 仅需 11 毫秒,因此我们选择它作为运行模型的后端,以实现实时照明增强。
安卓性能提示 API
想要重复对演示应用进行基准测试,就必须要用 ADB 命令来开启安卓固定性能模式。这是因为每次测试时,CPU 的频率可能会变来变去,ADB 命令可以固定 CPU 频率。我们发现,在使用这种固定性能模式后,帧时间减少了。但这也让应用开发者左右为难,因为他们没法控制 CPU 频率,但又不能指望终端用户会使用 ADB。不过,安卓性能提示 API 可以解决这个问题。该 API 主要用于游戏,其工作原理是设定目标帧时间并将该指标报告回安卓系统,由安卓系统调整时钟频率,尝试达到该目标。这使得帧时间得到了与固定性能模式相当的良好改善。
帧率
当弱光增强功能打开时,应用会显示帧时序。尽管帧率约为 37 FPS,但摄像头帧速率会根据硬件和照明情况受到限制(在极弱光条件下,安卓系统会降低相机 FPS 以提高亮度)。在 Pixel 7 上,向用户显示的帧速率(默认的安卓摄像头 API)上限为 30 FPS。更快的推理并不会带来更好的用户体验,因此保留了一个 7 FPS 的性能缓冲。
进一步的模型训练
尽管原始模型在暗场景下的照明增强效果相当不错,但图像有时会出现过度曝光的情况。为了解决这个问题,我们采用了一个包含两万张合成图像的大型数据集进行训练,此前的研究论文仅使用了两千张图像。
不过,基于大型数据集的训练时间会变长。经过调查,性能下降的原因是每批量八张图像超出了 GPU VRAM 容量,并溢出到系统内存中。为了在不增加 VRAM 使用量的情况下提高有效批次大小,我们采用了梯度累积技术,无需针对每个批量计算梯度,而是累积多个批量后再计算梯度。在我们的案例中,我们可以使用的批量上限是六张图像,而采用梯度累积技术后,我们能够使用的批量是 60 张图像。
结论
我们在本文中展示了一个可运行的演示移动端应用,用于实时改善移动端视频的照明效果。基于 Arm 平台优化并运行 ML 模型的过程非常顺畅,得益于量化和各种推理引擎等技术的运用,该模型能够在 33 毫秒的严苛性能限制下顺利运行。
-
如何构建一个简单的对讲电路2022-11-21 3591
-
AIROC™ CYW20829 HID鼠标演示代码无法构建怎么解决?2025-07-03 4725
-
如何构建一个具有同步复位端的CMOS四进制计数器?2016-12-10 3291
-
什么是投影机无PC移动演示2010-02-05 379
-
高通联合中国移动、中兴通讯进行端到端5G新空口系统的互通演示2017-11-28 6612
-
如何快速构建一个移动跨平台视频通话应用2019-02-24 3864
-
pc端是什么意思_PC端与移动端区别2020-05-08 75793
-
中兴联手广州移动实现构建端到端的5G地铁切片2020-06-03 3925
-
端到端的无人机导航模拟演示2022-04-06 7231
-
如何构建一个连接互联网的流量计2022-05-11 3074
-
如何使用ESP32构建一个BLE iBeacon2022-07-12 9013
-
构建一个移动RFID阅读器2022-12-05 697
-
构建一个移动端友好的SAM方案MobileSAM2023-06-30 2745
-
构建一个移动应用程序2023-07-04 598
-
一个Artist RoboHelper的构建2023-07-10 495
全部0条评论

快来发表一下你的评论吧 !
