

时空引导下的时间序列自监督学习框架
描述
【导读】最近,香港科技大学、上海AI Lab等多个组织联合发布了一篇时间序列无监督预训练的文章,相比原来的TS2Vec等时间序列表示学习工作,核心在于提出了将空间信息融入到预训练阶段,即在预训练阶段考虑各个序列之间的关系。因此,本文提出的方法更适合作为时空预测领域的预训练模型。下面为大家详细介绍一下这篇文章。

摘要
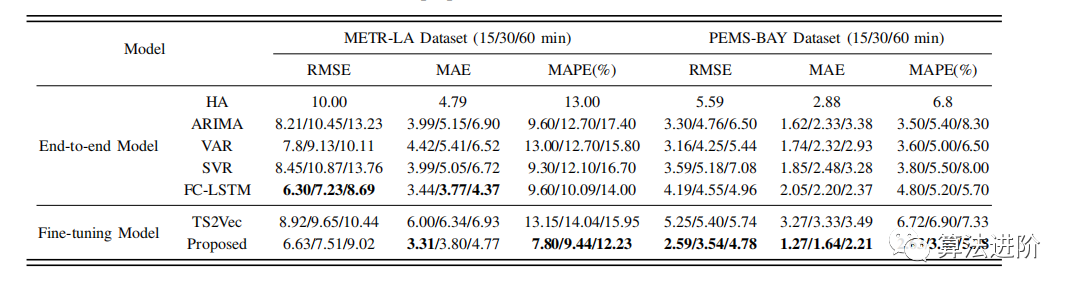
相关时间序列分析在许多现实行业中扮演着重要的角色。为进一步的下游任务学习这个大规模数据的有效表示是必要的,但也具有挑战性。在本文中,我们提出了一个通过时空引导表示预测的单个实例的时间步长级表示学习框架。我们评估了我们的表示学习框架在相关时间序列预测和将预测模型转移到有限数据的新实例。在学习到的表示之上训练的线性回归模型表明,我们的模型在大多数情况下表现最好。特别是与表示学习模型相比,我们在PeMS-BAY数据集上将RMSE、MAE和MAPE分别减少了37%、49%和48%。此外,在真实世界的地铁客流数据中,我们的框架展示了传输以推断新的冷启动实例的未来信息的能力,收益分别为15%、19%和18%。
1 背景
近年来,许多关于时间序列自监督学习方法的研究仍存在几个显著的缺点:
最近的研究[13, 14]只学实例级表示,不适合点级任务,如预测和异常检测。尽管它们在许多时间序列下游任务(如分类和聚类)上成功。
当前研究忽视不同实例间的相关性,学习相关时间序列的集成表示,难以转移到现实世界的下游任务,例如子实例预测。
所有基于对比的方法(如TS2Vec)都对数据分布或实例相关性做出假设,可能失去多样性,并可能出现假阴性样本。
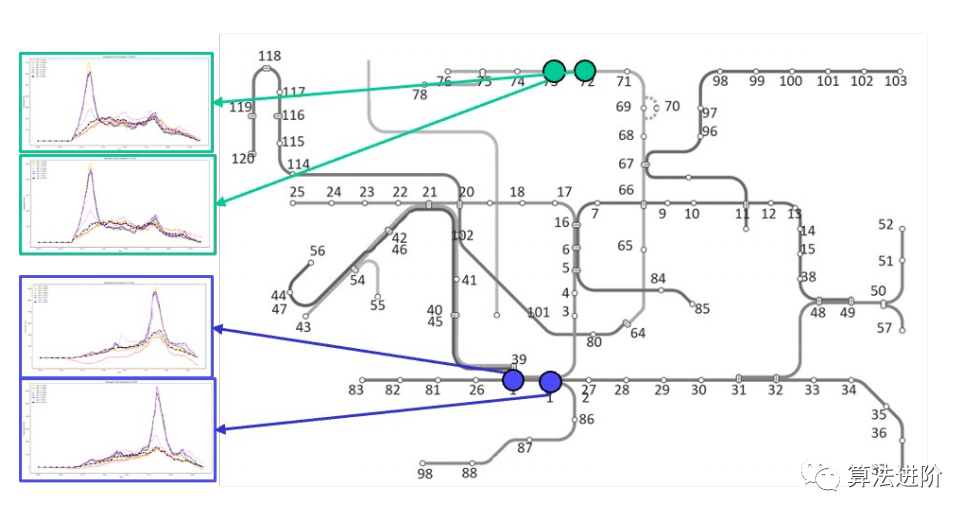
(a)空间相关性:一个车站的客流通常受到其图形邻居的影响。
(b)每周周期模式的时间相关性与缺失数据问题
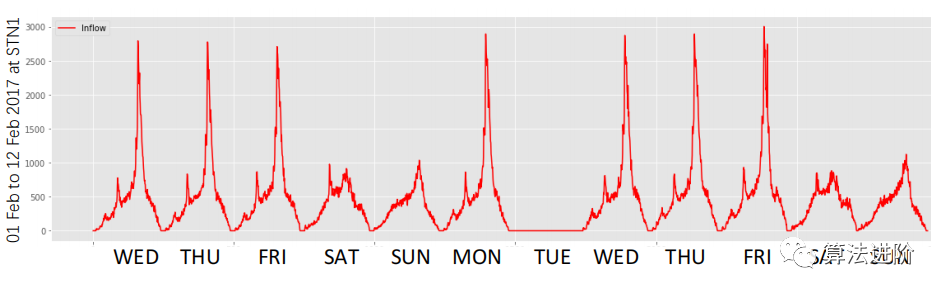
图1:相关时间序列的时空相关性的一个例子:[1]、[2]地铁站的乘客流入。(a)空间相关性:相邻车站的客流通常都很相似。(b)时间相关性:一个车站的客流通常具有历史时期的模式。此外,还观察到缺失的数据。
为了解决这些挑战,我们提出了一个通过时空引导的相关时间序列表示学习框架。本文的主要贡献总结如下:
我们构建了一个学习框架,用于学习任意实例在任何时间步长内的点级表示。这具有灵活性,所学习到的表示法可以被微调用于1) 相关的时间序列预测,以及 2) 用于新实例的转移任务,而无需重新训练预测模型。为了捕捉空间和时间上的相关性,我们在自监督学习框架中利用了来自预定义相邻矩阵的历史数据和相邻信息。
为了避免在时间序列数据的对比学习范式中经常出现的假阴性,我们在模型中加入了一个没有负样本的自监督学习框架。我们定义了空间和时间目标,并使用蒙版视图来预测目标的表示,以学习相关性。
我们根据实际数据不同下游任务的结果和分析,展示了表示学习框架的有效性和灵活性。我们对预测任务的评估显示了具有可比性能的端到端解决方案,但我们的方法更灵活,可以转移到进入数据集的新实例,而无需重新训练模型。
2 相关工作
2.1 预文本任务时间序列学习
通过设计各种预文本任务来提取有用的信息,以帮助模型在下游任务中表现良好。这些预文本任务包括遮盖序列的重构、相对定位、时间洗牌和对比预测编码任务等。这些任务的目的是学习时间序列的有效表示,以便在下游任务中获得更好的性能。此外,还有其他的预文本任务,如引导空间时间表示预测等。
2.2 基于对比的时间序列学习
基于对比的时间序列学习是一种时间序列表示学习的方法,其中大多数方法都采用对比学习框架。这些方法通过构建正负样本对来进行自监督学习,其中对比损失试图最大化正样本对之间的相似性,同时最小化负样本对之间的相似性。先前的研究提出了许多方法来选择正负样本对,以提高所学习表示的质量。这些方法包括使用三元组损失随机选择时间段、使用对比预测编码(CPC)等。这些方法的目的是学习时间序列的有效表示,以便在下游任务中获得更好的性能。
3 方法
这边主要介绍提出的模型框架。该模型的编码器由三个组件组成:输入投影层、扩张卷积神经网络模块和MLP预测器。对于每个输入w,输入投影层是一个全连接层,将时间戳t的观测值xi,t映射到高维潜在向量z。然后,应用具有十个残差块的扩张卷积神经网络模块来提取每个时间戳的上下文表示。每个扩张卷积块包含两个1-D卷积层,具有扩张参数(对于第l个块为2的l次方)。扩张卷积使不同领域具有大的感受野。在BYOL的思想下,通过预测视图的不同目标而不是对比来学习表示。在视图和目标通过全连接层f映射到高维潜在向量之后,使用两个扩张卷积神经网络预测器来预测从遮盖视图嵌入的潜在向量中的时空表示。
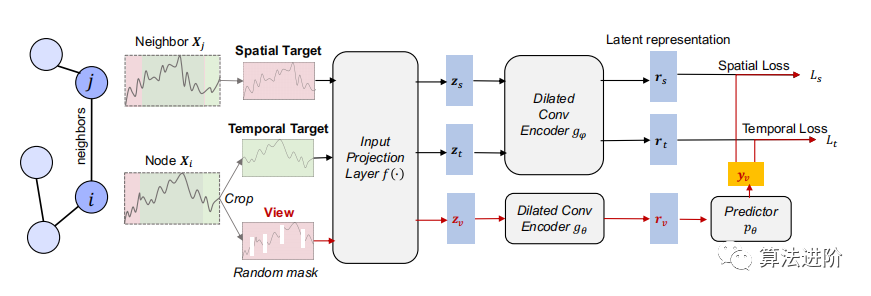
图2:提出的一种相关时间序列的表示学习框架:主干由一个投影到高维空间的线性层,两个具有不同参数的扩张卷积编码器和一个用于根据蒙版视图嵌入的潜在向量来预测时空表示的预测器组成。
4 实验结果
4.1 相关的时间序列预测
下图为本文提出的表示学习方法在时空预测数据集上的预测效果,可以看到相比TS2Vec,我们的方法有比较明显的效果提升。这足以说明我们提出的引入空间信息的对比学习,对于时空预测类型的问题效果更好。
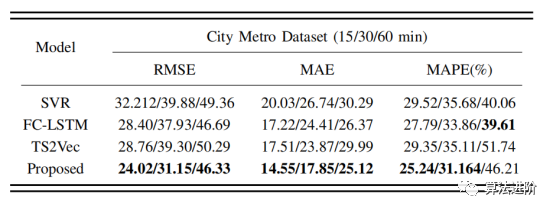
表1:所提方法和基线MAE、MAPE和RMSE(最好的加粗表示,下同)
我们在PEMS-BAY数据集上的性能优于基于时空图的神经网络对PEMS-BAY数据集的短期预测。我们可以看到,与TS2Vec相比,我们的模型有更好的预测趋势。
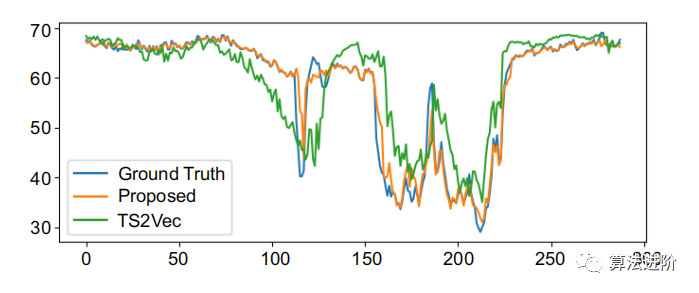
图3.我们的模型和TS2Vec的一个典型预测切片可视化。
4.2 冷启动——将模型转移到数据有限的新实例
如图4所示,由于新的地铁站的建设,地铁网络图结构会发生变化,同时这些新的地铁站通常只有很少的历史数据可用,因此预测它们的未来客流量会变得更加困难,这就是时间序列预测的"cold-start"问题。我们提出的方法在大多数情况下都取得了最好的预测性能(表2)。
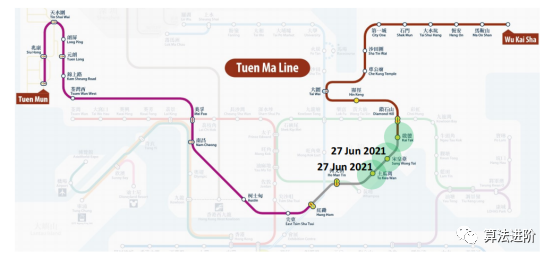
图4 新建地铁站数据有限,也改变地铁网络图(绿色突出显示) 表2:新车站的城市地铁:拟建方法的MAE、MAPE、RMSE及基线。
4.3 消融研究
为了验证我们的模型中时间和空间成分的有效性,我们比较了在METRLA数据集上不同超参数α值的模型性能。我们将α的值从0→1,时间间隔为0.25,其中α = 1意味着我们只使用历史信息,而α = 0意味着我们只考虑空间依赖性。
表3:METR-LA对α不同值的消融结果
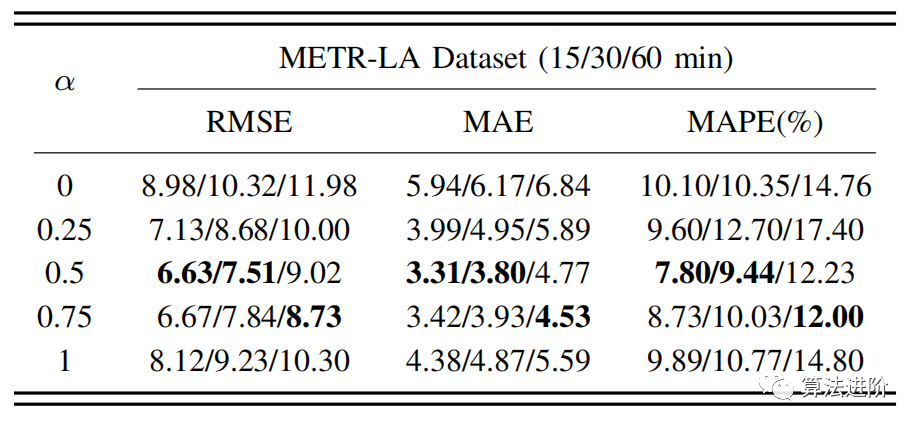
表3显示,当α=为0.5时,我们的模型在短期预测中表现最好。当时间目标的贡献大于空间目标时,或当α=值为0.75时,该模型的长期预测效果更好。
4.4 对丢失的数据具有鲁棒性
我们以METR-LA数据集为例,以三个缺失率、20%、40%和60%的随机缺失数据来评估预测性能。图5显示,在缺失率小于60%的情况下,我们的空间和时间目标都是非常稳健的。请注意,对于较小的α,如α = 0.25,预测性能比α = 0.75稳定。这表明空间目标的设计可以提高表示学习框架的鲁棒性。
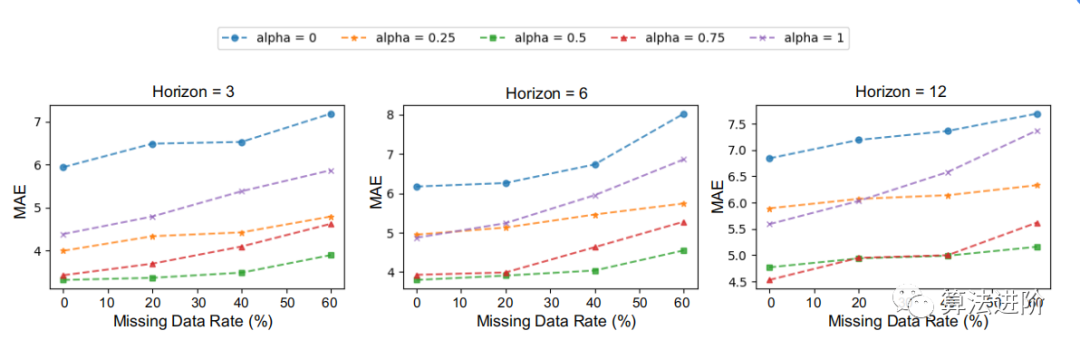
图5:METR-LA数据集对不同缺失数据率和α的MAE
-
使用MATLAB进行无监督学习2025-05-16 1754
-
基于transformer和自监督学习的路面异常检测方法分享2023-12-06 3271
-
适用于任意数据模态的自监督学习数据增强技术2023-09-04 2022
-
一个通用的时空预测学习框架2023-06-19 3036
-
设计时空自监督学习框架来学习3D点云表示2022-12-06 1782
-
自监督学习的一些思考2022-01-26 621
-
机器学习中的无监督学习应用在哪些领域2022-01-20 5657
-
华裔女博士提出:Facebook提出用于超参数调整的自我监督学习框架2021-04-26 2470
-
基于人工智能的自监督学习详解2021-03-30 7156
-
半监督学习:比监督学习做的更好2020-12-08 2316
-
自监督学习与Transformer相关论文2020-11-02 3475
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6830
-
基于半监督学习框架的识别算法2018-01-21 1085
全部0条评论

快来发表一下你的评论吧 !
