

Google Cloud如何守护大模型安全
描述
以下文章来源于谷歌云服务,作者 Google Cloud
杨鹏
Google Cloud 安全专家
大模型就像神通广大的 "哪吒",能写文章、画画、编程,无所不能。但如果哪吒被恶意操控,后果不堪设想!而且,培养这样的大模型需要大量投入,如果被 "黑化",损失也是巨大的。
这样看,大模型的安全关系到每个人,Google Cloud 提供了安全工具和服务,能保护大模型不被坏人利用,避免 "黑化"。
想了解更多关于大模型安全和 Google Cloud 的相关知识?请继续关注我们的系列文章!
大模型安全概要
生成式 AI 发展迅速,但也面临安全风险。MITRE ATLAS、NIST AI RMF 和 OWASP AI Top 10 等安全标准组织,总结了生成式 AI 的主要安全威胁,主要包括:
●对抗性攻击:攻击者扰乱模型输入或窃取模型信息,导致错误输出或信息泄露。
● 数据投毒:攻击者污染训练数据,使模型产生偏差或后门。
● 模型窃取:攻击者窃取模型结构和参数,用于复制或攻击。
● 滥用和恶意使用:模型被用于生成虚假信息、垃圾邮件等。
● 隐私和安全:模型可能泄露用户隐私或存在安全漏洞。
● 模型篡改:攻击者修改模型参数、逻辑或数据,改变模型行为。
此外,公众还关注生成式 AI 的法律合规、治理、偏差、透明度、环境影响等问题。解决这些问题,才能确保生成式 AI 安全、可靠、负责任地发展。
在这当中,模型篡改 (Model Tampering,也可称为模型投毒-Model Poisoning) 这类的威胁涵盖了对模型的任何未经授权的修改,包括但不限于对模型训练或者微调注入后门或降低性能,修改模型参数或代码导致模型无法正常工作或产生错误结果。这类威胁对应的漏洞一般被认为利用难度比较高,因为攻击者不仅要突破层层基础安全纵深防御,还需要熟悉大模型训练和优化,了解如何绕过代码审计和各类监控且可以有效地影响到模型训练工作。
但是,近期发生的一些模型投毒事故证明,熟悉流程和相关大模型技术的内部攻击者可以放大这类风险,甚至可以使得投入数千万美元的训练工作毁于一旦。同时,随着黑产灰产的不断演进,未来这类威胁带来的影响可能还会增大,上面说的让模型 "黑化" 的风险并不是危言耸听。
理解大模型训练的安全风险
下图是在 Google Cloud 上进行生成式 AI 训练,部署和推理的典型架构。图中画红框的部分是大模型训练的范畴。
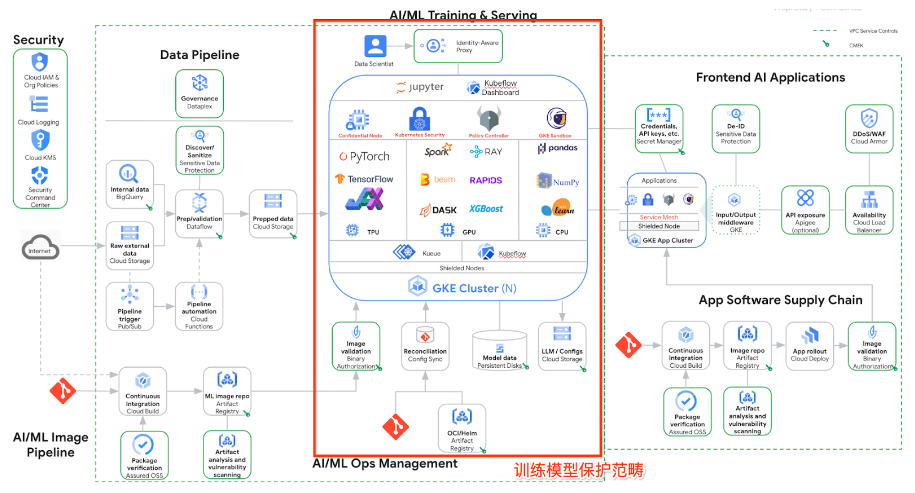
首先让我们从基础设施、工具链、供应链、模型代码和配置等方面,拆解一下模型篡改可能面临的风险类别:
基础设施
● 未经授权的访问:攻击者可能入侵模型训练或部署的服务器、云平台等基础设施,直接篡改模型文件或运行环境。这包括利用系统漏洞、弱口令、社会工程学等手段获取访问权限。
● 恶意代码注入:攻击者可能在基础设施中植入恶意代码,例如后门程序、rootkit 等,用于监控模型行为、窃取数据或篡改模型输出。
● 拒绝服务攻击:攻击者可能对基础设施发起 DDoS 攻击,导致模型无法正常提供服务,影响用户体验和业务运营。
模型训练工具链
● 投毒的训练框架:攻击者可能篡改模型训练所使用的框架或库,例如 TensorFlow、PyTorch 等,注入恶意代码或后门,影响模型训练过程和结果。
● 恶意的模型评估工具:攻击者可能篡改模型评估工具,例如指标计算脚本、可视化工具等,导致模型评估结果失真,掩盖模型存在的安全问题。
● 不安全的模型部署工具:攻击者可能利用模型部署工具中的漏洞,例如未经身份验证的 API 接口、不安全的配置文件等,篡改模型参数或逻辑。
模型供应链
● 预训练模型的风险:使用来自不可信来源的预训练模型,可能存在被篡改的风险,例如模型中可能被植入后门或恶意代码。
● 第三方数据的风险:使用来自不可信来源的第三方数据进行模型训练,可能存在数据投毒的风险,导致模型学习到错误的模式或产生偏差。
● 依赖库的风险:模型训练和部署过程中使用的各种依赖库,可能存在安全漏洞,攻击者可能利用这些漏洞篡改模型或窃取数据。
模型代码和配置
● 代码注入:攻击者可能直接修改模型代码,注入恶意代码或后门,改变模型的行为。
● 配置错误:错误的模型配置可能导致安全漏洞,例如过低的访问权限、未加密的敏感信息等,攻击者可能利用这些漏洞篡改模型。
● 版本控制问题:缺乏有效的版本控制机制,可能导致模型被意外修改或回滚到存在安全问题的版本。
发挥云原生的力量一起应对风险
经过多年的积累,Google 既是一个 AI 专家,又是一个安全专家,在应对类似的风险方面有丰富的经验。在 Google Cloud 平台上,有多种云原生的手段来帮助大家应对上面提到的大模型投毒的威胁。
要保护模型安全,需要多管齐下: 加强基础设施安全,例如做好访问控制和入侵检测;使用可信的工具链,并对预训练模型、数据和依赖库进行安全审查;同时,还要保护好模型代码和配置,并进行持续的监控和检测。
Ray on Vertex AI 提供了一个强大的平台,可以帮助您更好地进行 LLMOps,在提高模型训练的效率和有效性的同时,保护模型代码和配置:
安全的环境
Vertex AI 提供了安全可靠的运行环境,并与 Google Cloud 的安全工具集成,例如 IAM 和 VPC Service Controls,可以有效地控制访问权限和保护敏感数据。
可复现的流程
Ray 和 Vertex AI 的结合可以帮助您构建可复现的模型训练和部署流程,通过版本控制和跟踪实验参数,确保模型代码和配置的一致性。
持续监控和集成
您可以利用 Vertex AI 的监控工具和 Ray 的可扩展性,对模型进行持续监控和性能分析,及时发现异常情况并进行调整。
通过 Ray on Vertex AI,结合 Google Cloud 的权限管理、网络隔离、威胁监控等手段,可以将模型代码和配置纳入到一个安全、可控、可复现的环境中,从而更好地保护模型的安全性和完整性。
Jupyter Notebook、Kubeflow 和 Ray 之类的大模型训练工具也是需要保护的重点。需要从漏洞评估、用户访问控制、加密和网络隔离等多个方面入手,确保训练开发和测试工具的安全可靠。
漏洞评估
● 使用 Artifact Analysis 扫描镜像中的漏洞,并使用 Binary Authorization 根据扫描结果限制部署。
● 对于运行中的工作负载,考虑使用 Advanced Vulnerability Insights 进行更深入的漏洞分析。
用户访问控制
● 通过 Cloud Load Balancer 和 Identity-Aware Proxy 对 Cloud Console 环境访问进行代理、Kubeflow Central Dashboard 和 Ray dashboard UI 进行用户身份验证和授权。
加密
● 使用 CMEK 对启动磁盘和永久磁盘进行静态加密。
● 使用 HTTPS Load Balancing 对前端通信进行传输加密。
● 可选: 支持 Ray TLS,但会影响性能。
网络隔离
● 根据 Jupyter Notebook、Kubeflow 和 Ray 的要求配置网络策略和 Cloud Firewall 规则。
● Kubeflow 集成了 Istio 来控制集群内流量和用户交互,还可以使用 Cloud Service Mesh 补充 AI/ML 运营环境的网络安全。
Vertex AI Colab Enterprise 将 Colab 的易用性与 Google Cloud 的安全性和强大功能相结合,为数据科学家提供了一个理想的平台,在安全、可扩展的环境中运行 Jupyter Notebook,同时轻松访问 Google Cloud 的各种资源。
保障大模型训练安全,需审查预训练模型、第三方数据和依赖库。选择 Google Cloud 提供的预训练模型,并使用 Artifact Analysis 等工具进行漏洞扫描和依赖分析,确保模型来源可靠且安全。
在管理依赖库的安全风险方面,Google Cloud Assured OSS 可以发挥重要作用。它提供了一系列经过 Google 安全审查和维护的开源软件包,例如 TensorFlow、Pandas 和 Scikit-learn 等常用的大模型训练库。
● 可信来源:Assured OSS 的软件包来自 Google 管理的安全可靠的 Artifact Registry,确保来源可信。
● 漏洞修复:Google 会积极扫描和修复 Assured OSS 软件包中的漏洞,并及时提供安全更新。
● 软件物料清单 (SBOM):Assured OSS 提供了标准格式的 SBOM,帮助您了解软件包的组成成分和依赖关系,方便进行安全评估。
目前,业内大模型训练使用最多的基础设施平台是 Kubernetes。Google Cloud 托管的 Kubernetes 平台 GKE,提供高度安全、可扩展且易于管理的 Kubernetes 环境,让开发者专注于模型开发和部署,无需担心底层基础设施的运维。下面是一些面向大模型训练风险的 GKE 安全加固建议。
基础的云原生安全加固和管控在 Google Cloud 上可以非常方便地使用,可以利用其提供的 Identity and Access Management (IAM) 服务精细化地控制对模型和数据的访问权限,并使用 Security Command Center 进行入侵检测和安全监控,及时发现并应对潜在威胁。此外,Google Cloud 还提供了一系列安全加固工具和服务,例如虚拟机安全、网络安全、数据加密等,帮助您构建更加安全的生成式 AI 基础设施。
生成式 AI 的安全及合规治理
不容忽视
生成式 AI 技术日新月异,其安全风险也随之不断演变。长期的生成式 AI 安全治理能够帮助我们持续应对新的威胁,确保 AI 系统始终安全可靠,并适应不断变化的法律法规和社会伦理要求,最终促进生成式 AI 技术的健康发展和应用。Google Cloud SAIF (Security AI Framework) 是一个旨在保障 AI 系统安全的概念框架。它借鉴了软件开发中的安全最佳实践,并结合了 Google 对 AI 系统 specific 的安全趋势和风险的理解。
SAIF 的主要内容可以概括为以下四个方面:
安全开发 (Secure Development)
威胁建模:在 AI 系统的开发初期就进行威胁建模,识别潜在的安全风险。
安全编码:采用安全的编码实践,防止代码漏洞和安全缺陷。
供应链安全:确保 AI 系统的供应链安全,例如使用可信的第三方库和数据。
安全部署 (Secure Deployment)
访问控制:对 AI 系统进行访问控制,防止未经授权的访问和修改。
安全配置:对 AI 系统进行安全配置,例如配置防火墙规则和加密通信。
漏洞扫描:对 AI 系统进行漏洞扫描,及时发现和修复安全漏洞。
安全执行 (Secure Execution)
输入验证:对 AI 系统的输入进行验证,防止恶意输入和攻击。
异常检测:对 AI 系统的运行状态进行监控,及时发现异常行为。
模型保护:保护 AI 模型不被窃取或篡改。
安全监控 (Secure Monitoring)
日志记录:记录 AI 系统的运行日志,方便安全审计和事件调查。
安全评估:定期对 AI 系统进行安全评估,识别新的安全风险。
事件响应:建立事件响应机制,及时应对安全事件。
SAIF 的目标是帮助组织将安全措施融入到 AI 系统的整个生命周期中,确保 AI 系统的安全性和可靠性。它强调了以下几个关键原则:
● 默认安全:AI 系统应该默认安全,而不是事后补救。
●纵深防御:采用多层次的安全措施,防止单点故障。
● 持续监控:持续监控 AI 系统的运行状态,及时发现和应对安全威胁。
● 持续改进:不断改进 AI 系统的安全措施,以适应不断变化的威胁环境。
行动从今天开始
我们深入探讨了大模型安全的重要性、面临的风险以及 Google Cloud 提供的安全工具和服务,涵盖了基础设施安全、模型安全、数据安全和供应链安全等方面。未来,就像我们一起努力保护 "小哪吒" 一样,Google Cloud 会和大家一起,利用强大的安全工具和丰富的经验,把大模型训练的每个环节都保护好,让 AI 技术安全可靠地为我们服务!
-
NetApp与Google Cloud深化合作:重构分布式云数据基础设施的“安全主权”新范式2026-04-27 1371
-
Cadence与Google合作,利用ChipStack AI Super Agent在Google Cloud上扩展AI驱动的芯片设计2026-04-24 2536
-
Meta Llama 3.1系列模型可在Google Cloud上使用2024-08-02 1303
-
Flutter首次亮相Google Cloud Next大会2024-05-09 1403
-
Google Cloud 线上课堂 | Google Cloud 迁移最佳实践2023-11-28 1222
-
新知同享|Cloud 开发加速创新,更加安全2023-09-08 1167
-
使用 Renesas AE-CLOUD2 将 GPS 数据发送到 Google Cloud IoT2023-01-04 1475
-
Google Cloud 线上课堂 | 从 CI/CD 流程安全到 NAS - Google Cloud 加速企业创新2022-11-10 1338
-
恩智浦为 Google IoT Cloud 提供安全解决方案2022-08-15 957
-
基于Google Cloud运行的NVIDIA CloudXR2021-08-13 2307
-
如何使用Google Cloud评估板来连接到Google Cloud IoT平台?2021-06-15 1925
-
Google发布众多新品,为增强云安全性2020-03-20 891
-
DXC Technology宣布与Google Cloud缔结全球合作关系2019-08-23 1495
-
物联网从业者最想关心的——Google Cloud IoT放出了哪些“大招”?2018-07-27 6863
全部0条评论

快来发表一下你的评论吧 !
