

 案例验证:分析NCCL-Tests运行日志优化Scale-Out网络拓扑
案例验证:分析NCCL-Tests运行日志优化Scale-Out网络拓扑
电子说
描述
背景:All-reduce 和 Ring 算法
GPU[并行计算]中需要大规模地在计算节点之间同步参数梯度,产生了大量的集合通信流量。为了优化集合通信性能,业界开发了不同的集合通信库(xCCL),其核心都是实现 All-Reduce,这也是分布式训练最主要的通信方式。

LLM训练中的 All Reduce 操作一般分为三个步骤:
- 把每个节点的数据切分成N份;
- 通过reduce-scatter,让每个节点都得到1/N的完整数据块;
- 通过all-gather,让所有节点的每个1/N数据块都变得完整
基于这种流量模式,Ring算法是目前实现该操作最常见的基础算法之一。
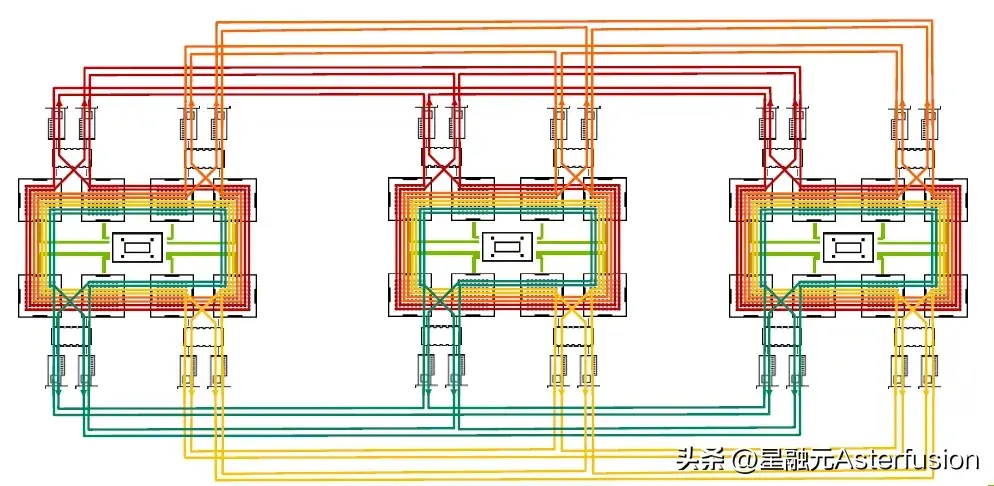
顾名思义,Ring算法构建了一个环形网络——每个节点的数据会被切分成N份数据在所有GPU之间移动,且每个GPU只和相邻的GPU通信。这种流水线模式能充分利用所有节点的发送和接收带宽,减少 GPU 等待数据的空闲时间,同时也改善了传输[大数据]块时的性能和时延抖动问题。(但对于小规模数据传输,Ring算法可能会表现出较高的延迟和低效。)
工具说明:NCCL-Tests
NVIDIA提供的NCCL是当前面向AI的集合通信事实标准,NCCL-Test 是 NVIDIA 开源的工具,我们可以在官方Github下载来进行不同算法的 性能测试 (例如:ring,trees…)。本次测试使用All reduce的ring算法来进行性能评估。
**代码语言:**javascript
复制
root@bm-2204kzq:~# /usr/local/openmpi/bin/mpirun #多机集群测试需要使用MPI方式执行
--allow-run-as-root
-bind-to none #不将进程绑定到特定的CPU核心
-H 172.17.0.215:8,172.17.0.81:8 # host列表,:后指定每台机器要用的GPU数量
-np 16 #指定要运行的进程数,等于总GPU数量
-x NCCL_SOCKET_NTHREADS=16
-mca btl_tcp_if_include bond0
-mca pml ^ucx -mca btl ^openib #指定BTL的value为'^openib'
-x NCCL_DEBUG=INFO #NCCL的调试级别为info
-x NCCL_IB_GID_INDEX=3
-x NCCL_IB_HCA=mlx5_0:1,mlx5_2:1,mlx5_3:1,mlx5_4:1
-x NCCL_SOCKET_IFNAME=bond0 #指定了 NCCL 使用的网络接口
-x UCX_TLS=sm,ud #调整MPI使用的传输模式
-x LD_LIBRARY_PATH -x PATH
-x NCCL_IBEXT_DISABLE=1 #如使用RoCE网络,此处应禁用
-x NCCL_ALGO=ring
/root/nccl-tests/build/all_reduce_perf -b 512 -e 18G -f 2 -g 1 #执行all reduce操作
NCCL-Tests常用参数及解释
- GPU 数量
- -t,--nthreads 每个进程的线程数量配置, 默认 1;
- -g,--ngpus 每个线程的 GPU 数量,默认 1;
- 数据大小配置
- -b,--minbytes 开始的最小数据量,默认 32M;
- -e,--maxbytes 结束的最大数据量,默认 32M;
- 数据步长设置
- -i,--stepbytes 每次增加的数据量,默认: 1M;
- -f,--stepfactor 每次增加的倍数,默认禁用;
- NCCL 操作相关配置
- -o,--op 指定哪种操作为reduce,仅适用于Allreduce、Reduce或ReduceScatter等操作。默认值为:求和(Sum);
- -d,--datatype 指定使用哪种数据类型,默认 : Float;
- 性能相关配置
- -n,--iters 每次操作(一次发送)循环多少次,默认 : 20;
- -w,--warmup_iters 预热迭代次数(不计时),默认:5;
- -m,--agg_iters 每次迭代中要聚合在一起的操作数,默认:1;
- -a,--average <0/1/2/3> 在所有 ranks 计算均值作为最终结果 (MPI=1 only). <0=Rank0,1=Avg,2=Min,3=Max>,默认:1;
- 测试相关配置
- -p,--parallel_init <0/1> 使用线程并行初始化 NCCL,默认: 0;
- -c,--check <0/1> 检查结果的正确性。在大量GPU上可能会非常慢,默认:1;
- -z,--blocking <0/1> 使NCCL集合阻塞,即在每个集合之后让CPU等待和同步,默认:0;
- -G,--cudagraph 将迭代作为CUDA图形捕获,然后重复指定的次数,默认:0;
案例验证:优化GPU互连拓扑
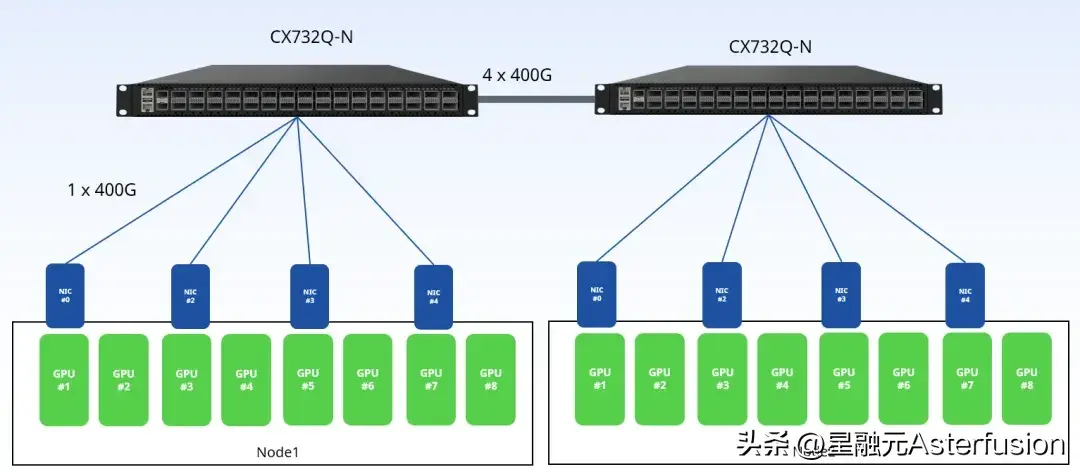
下图是一个未优化的双机8卡(H20)组网测试拓扑:
按照一般CPU云数据中心的连接方式,将同服务器的网卡连接到一台交换机上,两台交换机之间有4条400G链路相连。参与测试的为星融元(Asterfusion)交换机(CX732Q-N,32 x 400GE QSFP-DD, 2 x 10GE SFP+)。
NCCL-Test 性能测试结果
**代码语言:**javascript
复制
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
512 128 float sum -1 56.12 0.01 0.02 0 54.54 0.01 0.02 0
1024 256 float sum -1 55.09 0.02 0.03 0 53.85 0.02 0.04 0
2048 512 float sum -1 55.67 0.04 0.07 0 54.84 0.04 0.07 0
4096 1024 float sum -1 55.70 0.07 0.14 0 55.05 0.07 0.14 0
8192 2048 float sum -1 56.36 0.15 0.27 0 56.53 0.14 0.27 0
16384 4096 float sum -1 57.21 0.29 0.54 0 57.02 0.29 0.54 0
32768 8192 float sum -1 60.74 0.54 1.01 0 59.87 0.55 1.03 0
65536 16384 float sum -1 67.42 0.97 1.82 0 68.41 0.96 1.80 0
131072 32768 float sum -1 109.6 1.20 2.24 0 108.8 1.20 2.26 0
262144 65536 float sum -1 108.3 2.42 4.54 0 108.3 2.42 4.54 0
524288 131072 float sum -1 115.0 4.56 8.55 0 112.8 4.65 8.72 0
1048576 262144 float sum -1 135.0 7.77 14.57 0 129.4 8.10 15.19 0
2097152 524288 float sum -1 144.6 14.51 27.20 0 142.9 14.67 27.51 0
4194304 1048576 float sum -1 222.0 18.89 35.43 0 220.0 19.07 35.75 0
8388608 2097152 float sum -1 396.5 21.15 39.66 0 392.1 21.40 40.12 0
16777216 4194304 float sum -1 736.3 22.78 42.72 0 904.7 18.55 34.77 0
33554432 8388608 float sum -1 1405.5 23.87 44.76 0 1542.0 21.76 40.80 0
67108864 16777216 float sum -1 2679.0 25.05 46.97 0 2721.0 24.66 46.24 0
134217728 33554432 float sum -1 5490.1 24.45 45.84 0 5291.6 25.36 47.56 0
268435456 67108864 float sum -1 10436 25.72 48.23 0 11788 22.77 42.70 0
536870912 134217728 float sum -1 25853 20.77 38.94 0 23436 22.91 42.95 0
1073741824 268435456 float sum -1 47974 22.38 41.97 0 54979 19.53 36.62 0
2147483648 536870912 float sum -1 117645 18.25 34.23 0 117423 18.29 34.29 0
4294967296 1073741824 float sum -1 248208 17.30 32.44 0 229171 18.74 35.14 0
8589934592 2147483648 float sum -1 474132 18.12 33.97 0 476988 18.01 33.77 0
17179869184 4294967296 float sum -1 949191 18.10 33.94 0 965703 17.79 33.36 0
# Out of bounds values : 0 OK
- size (B):操作处理的数据的大小,以字节为单位;
- count (elements):操作处理的元素的数量;
- type:元素的数据类型;
- redo p:使用的归约操作;
- root:-1 表示这个操作没有根节点(all-reduce 操作涉及到所有的节点);
- time (us):操作的执行时间,以微秒为单位;
- algbw (GB/s):算法带宽,以 GB/s 为单位;
- busbw (GB/s):总线带宽,以 GB/s 为单位;
- wrong:错误的数量,如果这个值不是 0,那可能表示有一些错误发生。
查看结果时需要关注如下几点:
- 数据量增加时,带宽是否会下降(下降明显不符合预期);
- 带宽的峰值,每次算到的带宽峰值,可以只关注 in 或者 out;
- 平均值,在数据量递增的情况下,可能无法体现最终的结果;
- 请确保数据量足够大,可以压到带宽上限(通过调整 b、e 或者 n 选项)。
分析以上信息可以发现:平均总线带宽仅22GB/s,在达到47GB/s左右的峰值流量后,随着数据量越大带宽性能却在下降,与正常值相差甚远。
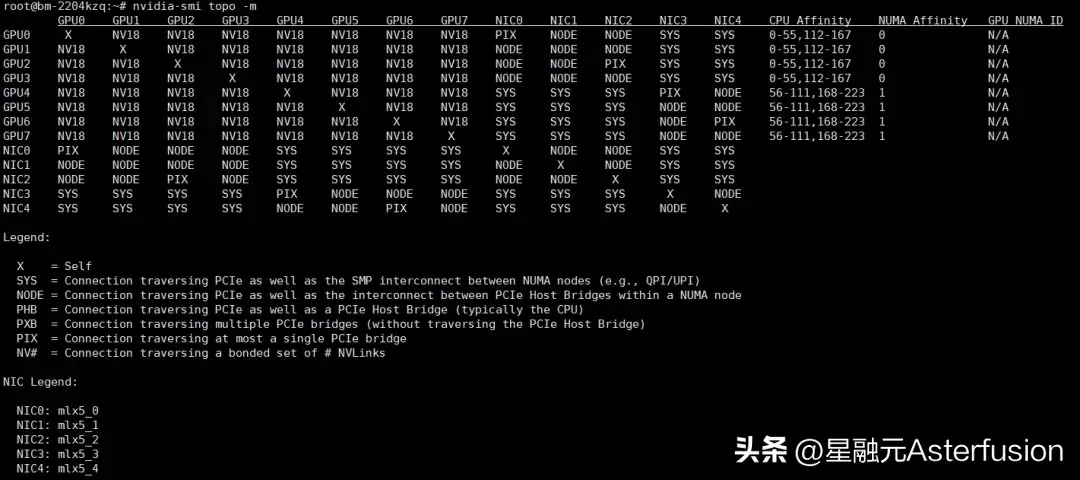
机内拓扑分析
通过 nvidia-smi topo -m 可以得知机内设备拓扑
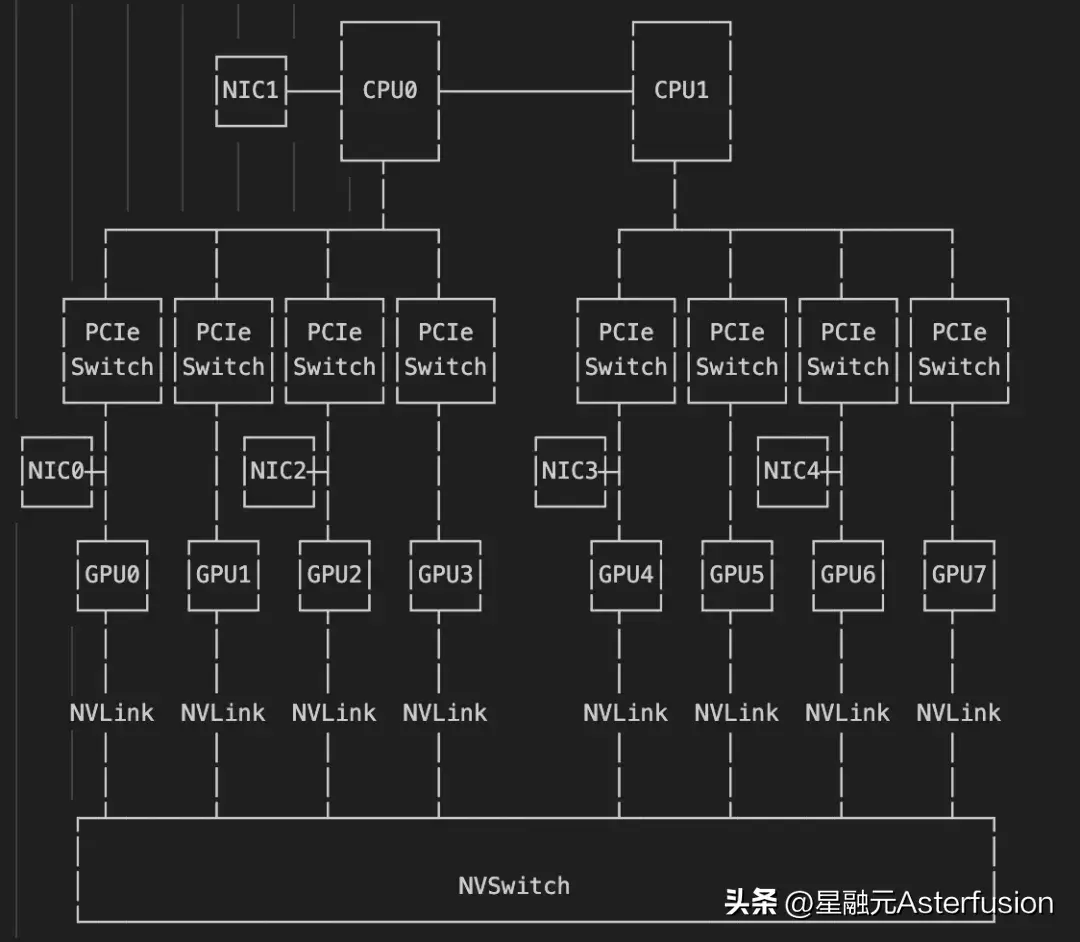
将上表转化为如下示意图:
NCCL通信路径分析
NCCL中用Channel的概念表示一个通信路径,在初始化的过程会自动感知拓扑并计算最佳的通信路径。为了更好的利用带宽和网卡实现并发通信,NCCL会使用多channel。NCCL-test运行日志里列出了16组channel如下:
**代码语言:**javascript
复制
### ChannelNum:16
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 00/16 : 0 7 5 6 4 3 1 2 8 15 13 14 12 11 9 10
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 01/16 : 0 7 5 6 4 3 1 10 8 15 13 14 12 11 9 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 02/16 : 0 7 5 6 12 11 9 10 8 15 13 14 4 3 1 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 03/16 : 0 7 5 14 12 11 9 10 8 15 13 6 4 3 1 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 04/16 : 0 7 5 6 4 3 1 2 8 15 13 14 12 11 9 10
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 05/16 : 0 7 5 6 4 3 1 10 8 15 13 14 12 11 9 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 06/16 : 0 7 5 6 12 11 9 10 8 15 13 14 4 3 1 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 07/16 : 0 7 5 14 12 11 9 10 8 15 13 6 4 3 1 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 08/16 : 0 7 5 6 4 3 1 2 8 15 13 14 12 11 9 10
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 09/16 : 0 7 5 6 4 3 1 10 8 15 13 14 12 11 9 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 10/16 : 0 7 5 6 12 11 9 10 8 15 13 14 4 3 1 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 11/16 : 0 7 5 14 12 11 9 10 8 15 13 6 4 3 1 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 12/16 : 0 7 5 6 4 3 1 2 8 15 13 14 12 11 9 10
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 13/16 : 0 7 5 6 4 3 1 10 8 15 13 14 12 11 9 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 14/16 : 0 7 5 6 12 11 9 10 8 15 13 14 4 3 1 2
bm-2204kzq:252978:253054 [0] NCCL INFO Channel 15/16 : 0 7 5 14 12 11 9 10 8 15 13 6 4 3 1 2
Device map 显示 Rank #0-7、#8-15在同一服务器
**代码语言:**javascript
复制
### Device maps
## GPU map
# Rank 0 Group 0 Pid 252978 on bm-2204kzq device 0 [0x0f] NVIDIA H20
# Rank 1 Group 0 Pid 252979 on bm-2204kzq device 1 [0x34] NVIDIA H20
# Rank 2 Group 0 Pid 252980 on bm-2204kzq device 2 [0x48] NVIDIA H20
# Rank 3 Group 0 Pid 252981 on bm-2204kzq device 3 [0x5a] NVIDIA H20
# Rank 4 Group 0 Pid 252982 on bm-2204kzq device 4 [0x87] NVIDIA H20
# Rank 5 Group 0 Pid 252983 on bm-2204kzq device 5 [0xae] NVIDIA H20
# Rank 6 Group 0 Pid 252984 on bm-2204kzq device 6 [0xc2] NVIDIA H20
# Rank 7 Group 0 Pid 252985 on bm-2204kzq device 7 [0xd7] NVIDIA H20
# Rank 8 Group 0 Pid 253834 on bm-2204qhn device 0 [0x0f] NVIDIA H20
# Rank 9 Group 0 Pid 253835 on bm-2204qhn device 1 [0x34] NVIDIA H20
# Rank 10 Group 0 Pid 253836 on bm-2204qhn device 2 [0x48] NVIDIA H20
# Rank 11 Group 0 Pid 253837 on bm-2204qhn device 3 [0x5a] NVIDIA H20
# Rank 12 Group 0 Pid 253838 on bm-2204qhn device 4 [0x87] NVIDIA H20
# Rank 13 Group 0 Pid 253839 on bm-2204qhn device 5 [0xae] NVIDIA H20
# Rank 14 Group 0 Pid 253840 on bm-2204qhn device 6 [0xc2] NVIDIA H20
# Rank 15 Group 0 Pid 253841 on bm-2204qhn device 7 [0xd7] NVIDIA H20
结合每个channel的具体路径信息(详见文末),在所有16条channel下的机间流量仅有以下8种固定的rank组合:10-0、2-8、1-10、9-2、6-12、14-4、5-14、13-6,对应的,产生通信的网卡有且仅有:
**代码语言:**javascript
复制
优化前性能不佳的原因是: 所有跨节点的并行流量都需跨交换机在四条互联链路上[负载均衡],而现有的ECMP负载均衡对大流不够友好,形成了性能瓶颈。
所以在设计Scale-out网络拓扑的时候,我们应让集群内所有同轨道的网卡连接在一台交换机上,使集群性能达到最优。
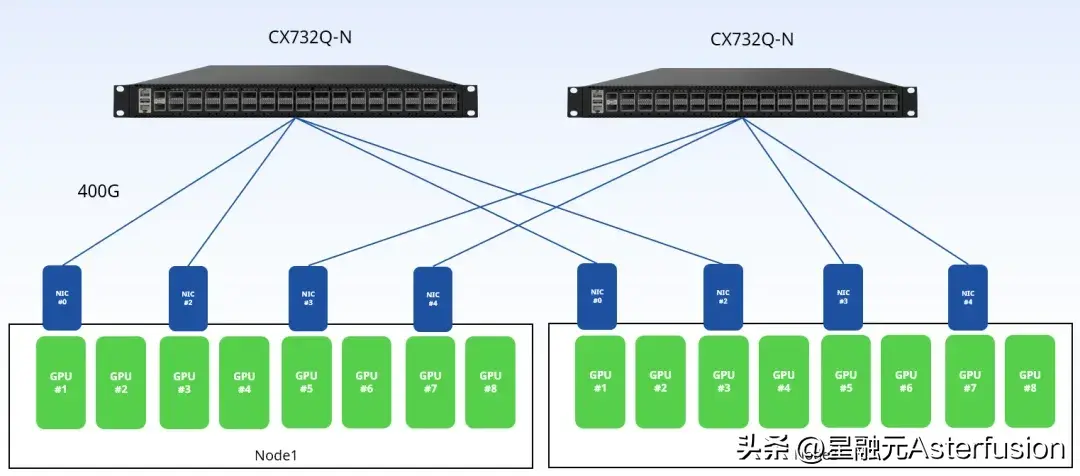
按此方式调整后,测得单机四卡模式跨RoCE交换机(CX732Q-N)的总线带宽与网卡直连数值相近,约195GB/s。
更多内容请参考:
https://asterfusion.com/
https://mp.weixin.qq.com/s/HHCxpaidUfAZwH6G6PwmKg
审核编辑 黄宇
-
运行230-yolov8优化笔记本示例时遇到ops.scale_segments问题怎么解决?2025-03-06 401
-
请问,多个while循环该怎么做运行日志呢?2021-09-18 3495
-
如何去实现嵌入式linux设备中应用运行日志呢2021-11-04 1049
-
车载网络FlexRay拓扑结构的优化2008-10-24 1109
-
对于大规模系统日志的日志模式提炼算法的优化2017-11-21 864
-
基于互惠能力的对等网络拓扑优化算法2017-11-29 653
-
基于Hadoop与聚类分析的网络日志分析模型2017-12-07 917
-
人类互作网络拓扑模块分析2017-12-13 999
-
局部拓扑控制的网络路由方法2018-02-11 1032
-
无线传感器网络簇级拓扑模型的演化分析研究资料2018-11-29 1261
-
嵌入式linux设备中应用运行日志的实现2021-11-01 900
-
针对大量log日志快速定位错误地方2023-03-20 1520
-
如何确保电能质量在线监测装置运行日志的准确性?2025-12-17 860
-
NVIDIA Spectrum-X以太网硅光技术助力AI工厂网络创新2026-01-14 1134
全部0条评论

快来发表一下你的评论吧 !
