

k-means算法原理解析
电子说
描述
K-MEANS算法
K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法。k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体方法。包括初始化优化K-Means++, 距离计算优化elkan K-Means算法和大数据情况下的优化Mini Batch K-Means算法。
1. K-Means原理初探
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
如果用数据表达式表示,假设簇划分之间的随机数为(C1,C2,。。.Ck),则我们的目标是最小化平方误差E:
E=∑i=1k∑x∈Ci||x−μi||22E=∑i=1k∑x∈Ci||x−μi||22
其中μi是簇Ci的均值向量,有时也称为质心,表达式为:
μi=1|Ci|∑x∈Cixμi=1|Ci|∑x∈Cix
如果我们想直接求上式的最小值并不容易,这是一个NP难的问题,因此只能采用启发式的迭代方法。K-Means采用的启发式方式很简单,用下面一组图就可以形象的描述。
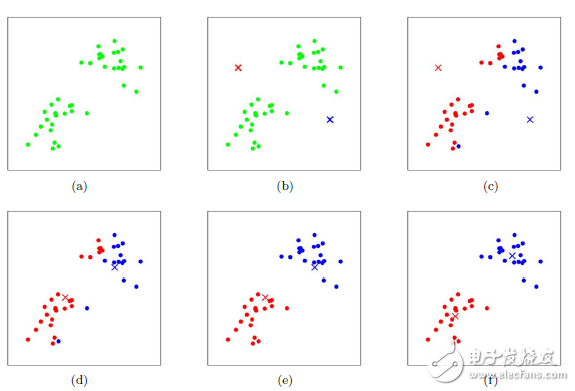
上图a表达了初始的数据集,假设k=2。在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别,如图c所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如图4所示,新的红色质心和蓝色质心的位置已经发生了变动。图e和图f重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图f。当然在实际K-Mean算法中,我们一般会多次运行图c和图d,才能达到最终的比较优的类别。
读者可以通过下面这个动态图来形象的了解算法的实现过程
在上一节我们对K-Means的原理做了初步的探讨,这里我们对K-Means的算法做一个总结。
首先我们看看K-Means算法的一些要点。
1)对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的k值。
2)在确定了k的个数后,我们需要选择k个初始化的质心,就像上图b中的随机质心。由于我们是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心,最好这些质心不能太近。
好了,现在我们来总结下传统的K-Means算法流程。
输入是样本集D={x1,x2,。..xm}D={x1,x2,。..xm},聚类的簇树k,最大迭代次数N
输出是簇划分C={C1,C2,。..Ck}C={C1,C2,。..Ck}
1) 从数据集D中随机选择k个样本作为初始的k个质心向量: {μ1,μ2,。..,μk}{μ1,μ2,。..,μk}
2)对于n=1,2,。..,N
a) 将簇划分C初始化为Ct=∅t=1,2.。.kCt=∅t=1,2.。.k
b) 对于i=1,2.。.m,计算样本xixi和各个质心向量μj(j=1,2,。..k)μj(j=1,2,。..k)的距离:dij=||xi−μj||22dij=||xi−μj||22,将xixi标记最小的为dijdij所对应的类别λiλi。此时更新Cλi=Cλi∪{xi}Cλi=Cλi∪{xi}
c) 对于j=1,2,。..,k,对CjCj中所有的样本点重新计算新的质心μj=1|Cj|∑x∈Cjxμj=1|Cj|∑x∈Cjx
e) 如果所有的k个质心向量都没有发生变化,则转到步骤3)
3) 输出簇划分C={C1,C2,。..Ck}C={C1,C2,。..Ck}
3. K-Means初始化优化K-Means++
在上节我们提到,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心。如果仅仅是完全随机的选择,有可能导致算法收敛很慢。K-Means++算法就是对K-Means随机初始化质心的方法的优化。
关于这里,原作者博客写的有点儿含糊,网上有几篇博客写的不是很清楚,这里把他们总结在一起,特别对有问题的地方用红色字体解释和说明:
k-means++算法选择初始seeds的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。wiki上对该算法的描述是如下:
1,从输入的数据点集合中随机选择一个点作为第一个聚类中心
2,对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3,选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4,重复2和3直到k个聚类中心被选出来
5,利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述上可以看到,算法的关键是第3步,如何将D(x)反映到点被选择的概率上,一种算法如下:
1,先从我们的数据库随机挑个随机点当“种子点”
2,对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
3,然后,再取一个随机值,用权重的方式来取下一个“种子点”。
这个算法的实现是:先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到,Random《=0(注意,这个式子的意思是:在刚才保存的那个数组里,我们从头开始遍历每一个元素的D(x),直到减掉的Random小于0,此时停止),此时的点就是下一个“种子点”。
4,重复2和3直到k个聚类中心被选出来
5,利用这k个初始的聚类中心来运行标准的k-means算法
可以看到算法的第三步选取新中心的方法,这样就能保证距离D(x)较大的点,会被选出来作为聚类中心了。至于为什么原因很简单,如下图 所示:

假设A、B、C、D的D(x)如上图所示,当算法取值Sum(D(x))*random(原作者博客里这样写是因为在编程语言中,random函数产生的是0-1之间的 随机数,所以他用Sum(D(x))*random来表示随机生成一个位于[0-Sum(D(x))]之间的随机数),该值会以较大的概率落入D(x)较大的区间内,所以对应的点会以较大的概率被选中作为新的聚类中心。
4. K-Means距离计算优化elkan K-Means
在传统的K-Means算法中,我们在每轮迭代时,要计算所有的样本点到所有的质心的距离,这样会比较的耗时。那么,对于距离的计算有没有能够简化的地方呢?elkan K-Means算法就是从这块入手加以改进。它的目标是减少不必要的距离的计算。那么哪些距离不需要计算呢?elkan K-Means利用了两边之和大于等于第三边,以及两边之差小于第三边的三角形性质,来减少距离的计算。
第一种规律是对于一个样本点x和两个质心μj1,μj2。如果我们预先计算出了这两个质心之间的距离D(j1,j2),则如果计算发现2D(x,j1)≤D(j1,j2),我们立即就可以知道
D(x,j1)≤D(x,j2)。此时我们不需要再计算D(x,j2),也就是说省了一步距离计算。
第二种规律是对于一个样本点xx和两个质心μj1,μj2。我们可以得到D(x,j2)≥max{0,D(x,j1)−D(j1,j2)}这个从三角形的性质也很容易得到。
利用上边的两个规律,elkan K-Means比起传统的K-Means迭代速度有很大的提高。但是如果我们的样本的特征是稀疏的,有缺失值的话,这个方法就不使用了,此时某些距离无法计算,则不能使用该算法。
5. 大样本优化Mini Batch K-Means
在传统的K-Means算法中,要计算所有的样本点到所有的质心的距离。如果样本量非常大,比如达到10万以上,特征有100以上,此时用传统的K-Means算法非常的耗时,就算加上elkan K-Means优化也依旧。在大数据时代,这样的场景越来越多。此时Mini Batch K-Means应运而生。
顾名思义,Mini Batch,也就是用样本集中的一部分的样本来做传统的K-Means,这样可以避免样本量太大时的计算难题,算法收敛速度大大加快。当然此时的代价就是我们的聚类的精确度也会有一些降低。一般来说这个降低的幅度在可以接受的范围之内。
在Mini Batch K-Means中,我们会选择一个合适的批样本大小batch size,我们仅仅用batch size个样本来做K-Means聚类。那么这batch size个样本怎么来的?一般是通过无放回的随机采样得到的。
为了增加算法的准确性,我们一般会多跑几次Mini Batch K-Means算法,用得到不同的随机采样集来得到聚类簇,选择其中最优的聚类簇。
6. K-Means(K-近邻学习)与KNN(k-近邻估计)
初学者很容易把K-Means和KNN搞混,两者其实差别还是很大的。
K-Means是无监督学习的聚类算法,没有样本输出;而KNN是监督学习的分类算法,有对应的类别输出。KNN基本不需要训练,对测试集里面的点,只需要找到在训练集中最近的k个点,用这最近的k个点的类别来决定测试点的类别。而K-Means则有明显的训练过程,找到k个类别的最佳质心,从而决定样本的簇类别。
当然,两者也有一些相似点,两个算法都包含一个过程,即找出和某一个点最近的点。两者都利用了最近邻(nearest neighbors)的思想。
7. K-Means小结
K-Means是个简单实用的聚类算法,这里对K-Means的优缺点做一个总结。
K-Means的主要优点有:
1)原理比较简单,实现也是很容易,收敛速度快。
2)聚类效果较优。
3)算法的可解释度比较强。
4)主要需要调参的参数仅仅是簇数k。
K-Means的主要缺点有:
1)K值的选取不好把握
2)对于不是凸的数据集比较难收敛
3)如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4) 采用迭代方法,得到的结果只是局部最优。
5) 对噪音和异常点比较的敏感。
k-means聚类算法的应用
聚类就是按照一定的标准将事物进行区分和分类的过程,该过程是无监督的,即事先并不知道关于类分的任何知识。聚类分析又称为数据分割,它是指应用数学的方法研究和处理给定对象的分类,使得每个组内部对象之间的相关性比其他对象之间的相关性高,组间的相异性较高。
聚类算法被用于许多知识领域,这些领域通常要求找出特定数据中的“自然关联”。自然关联的定义取决于不同的领域和特定的应用,可以具有多种形式。典型的应用例如:
1. 商务上,帮助市场分析人员从客户基本资料库中发现不同的客户群,并用购买模式来刻画不同客户群的特征;
2. 聚类分析是细分市场的有效工具,同时也可用于研究消费者行为,寻找新的潜在市场、选择实验的市场,并作为多元分析的预处理。
3. 生物学上,用于推导植物和动物的分类,对基因进行分类,获得对种群固有结构的认识;
4. 地理信息方面,在地球观测数据库中相似区域的确定、汽车保险单持有者的分组,及根据房子的类型、价值和地理位置对一个城市中房屋的分组上可以发挥作用;
5. 聚类也能用于在网上进行文档归类来修复信息;
6. 在电子商务网站建设数据挖掘中的应用,通过分组聚类出具有相似浏览行为的客户,并分析客户的共同特征,可以更好的帮助电子商务的用户了解自己的客户,向客户提供更合适的服务。
7. 聚类分析可以作为其它数据挖掘算法的预处理步骤,便于这些算法在生成的簇上进行处理。
-
基于距离的聚类算法K-means的设计实现2022-07-18 3602
-
使用K-means压缩图像2019-08-28 1878
-
调用sklearn使用的k-means模型2020-06-12 1162
-
K-Means有什么优缺点?2021-06-10 1201
-
改进的k-means聚类算法在供电企业CRM中的应用2010-03-01 691
-
Web文档聚类中k-means算法的改进2009-09-19 1313
-
K-means+聚类算法研究综述2012-05-07 800
-
基于密度的K-means算法在聚类数目中应用2017-11-25 840
-
K-Means算法改进及优化2017-12-05 1027
-
基于布谷鸟搜索的K-means聚类算法2017-12-13 1263
-
熵加权多视角核K-means算法2017-12-17 928
-
K-Means算法的简单介绍2018-07-05 5570
-
K-MEANS聚类算法概述及工作原理2022-06-06 6060
-
K-means聚类算法指南2022-10-28 2592
-
大学课程 数据分析 实战之K-means算法(2)算法代码2023-02-11 1141
全部0条评论

快来发表一下你的评论吧 !
