

一文解析NVIDIA AI-RAN部署平台
描述
生成式 AI 和 AI 智能体推理将推动 AI 计算基础设施从边缘云向中心云分布的需求。IDC 预测“到 2030 年,商业 AI(不包括消费者)将为全球经济贡献 19.9 万亿美元,并且占到 GDP 的 3.5%。”
5G 网络也必须不断发展,才能满足这些新的 AI 流量的需求。与此同时,电信公司将有机会成为托管企业 AI 工作负载的本地 AI 计算基础设施,这种基础设施不依赖网络连接,同时满足了数据隐私和主权要求。加速计算基础设施由于能够同时加速无线电信号处理和 AI 工作负载,因此能够在这个领域大放异彩。最重要的是,可以使用同一个计算基础设施处理 AI 和无线接入网络(RAN)服务。这一组合被电信行业称为 AI-RAN。
NVIDIA 推出了全球首个 AI-RAN 部署平台Aerial RAN Computer-1,该平台可在通用加速基础设施上同时服务于 AI 和 RAN 工作负载。
继 T-Mobile 推出 AI-RAN 创新中心之后,Aerial RAN Computer-1 将 AI-RAN 变成了现实,为电信公司提供了一个可在全球使用的可部署平台。它可以用于各种大、中、小型配置,部署在基站、分布式站点或集中式站点,有效地将网络转变为服务于语音、视频、数据和 AI 流量的多用途基础设施。
这项变革性的解决方案用 AI 重构了面向 AI 的无线网络。它给电信公司带来了一个推动 AI 飞轮的绝佳机遇,使电信公司能够充分利用其分布式网络基础设施、低延迟、有保证的服务质量、巨大的规模以及保护数据隐私、安全和本地化的能力,而这些都是实现 AI 推理和代理式 AI 应用的关键前提。
AI-RAN、AI Aerial 和 Aerial RAN Computer-1
AI-RAN 是构建 AI 原生多用途网络的技术框架。通过采用 AI-RAN 并从用途单一的传统 ASIC RAN 计算网络过渡到同时服务于 RAN 和 AI 的新型多用途加速计算网络,电信运营商现在可以参与新的 AI 经济,并利用 AI 提高网络效率。
NVIDIA AI Aerial包含三个计算机系统,可用于设计、仿真、训练和部署基于 AI-RAN 的 5G 和 6G 无线网络。Aerial RAN Computer-1 是 NVIDIA AI Aerial 的基础,并提供了适用于 AI-RAN 的商用级部署平台。
Aerial RAN Computer-1(图 1)提供了一个通用可扩展硬件基础,可运行各种 RAN 和 AI 工作负载,包括软件定义 5G、NVIDIA 或其他 RAN 软件提供商的 5G 专网 RAN、容器化网络功能、NVIDIA 或合作伙伴的 AI 微服务等。它还可托管内部和第三方生成式 AI 应用。Aerial RAN Computer-1 采用模块化设计,因此能够从 D-RAN 扩展到 C-RAN 架构,覆盖从农村到高密度的城市用例。
NVIDIA CUDA-X库是加速计算的核心。除提高效率外,该库还提供了速度、准确性和可靠性。这意味着在相同的功率范围内可以完成更多的工作。最重要的是,包括电信专用适配库在内的特定领域库是使 Aerial RAN Computer-1 适用于电信部署的关键。
NVIDIA DOCA提供了一整套工具和库,能够显著提升电信工作负载的性能,包括 RDMA、PTP/ 定时同步和基于以太网的前端线路(eCPRI)以及对现代网络基础设施至关重要的 AI 工作负载。
总之,该全栈支持可扩展硬件、通用软件和开放式架构,使用户能够与生态合作伙伴一起提供高性能 AI-RAN。
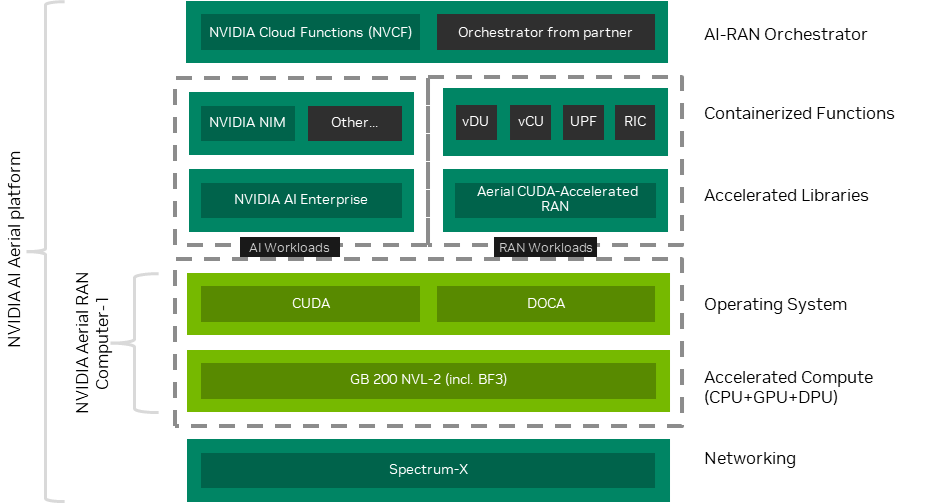
图 1. 作为 NVIDIA AI Aerial 平台一部分提供的NVIDIA Aerial RAN Computer-1
Aerial RAN Computer-1 的优势
借助 Aerial RAN Computer-1,无线网络可以变成一个由 AI 和 RAN 数据中心组成的大规模分布式网格,在为电信公司开辟新收入渠道的同时,通过软件升级为 6G 铺平道路。
Aerial RAN Computer-1 为电信运营商带来的优势如下:
通过 AI 和生成式 AI 应用、边缘 AI 推理或 GPU 即服务来获得收入。
将基础设施的利用率提高至单一用途基站的 2-3 倍,后者目前的利用率通常只有 30%。使用同一基础设施来托管内部生成式 AI 工作负载和其他容器化网络功能,例如 UPF 和 RIC 等。
通过针对特定站点的 AI 学习来提高无线网络性能,频谱效率最多可提高 2 倍,直接节省每 Mhz 获取频谱的成本。
为下一代应用提供高性能 RAN 和 AI 体验,将 AI 融入到每一次交互中。Aerial RAN Computer-1 在纯 RAN 模式下最多可提供 170 Gb/s 的吞吐量,在纯 AI 模式下最多可提供每秒 25,000 个 token 的吞吐量,即便在两种模式混合的情况下,也具有远超传统网络的性能。
Aerial RAN Computer-1 的组成
Aerial RAN Computer-1 的主要硬件组件如下:
NVIDIA GB200 NVL2
NVIDIA Blackwell GPU
NVIDIA Grace CPU
NVLink2 C2C
第五代 NVIDIA NVLink
键值缓存
MGX 参考架构
实时主流 LLM 推理
NVIDIA GB200 NVL2
Aerial RAN Computer-1 使用的NVIDIA GB200 NVL2平台(图 2)给数据中心和边缘计算带来了变革,为主流大语言模型(LLM)、vRAN、矢量数据库搜索和数据处理提供了空前的性能。
这一横向扩展型单节点架构搭载两个 NVIDIA Blackwell GPU 和两个 NVIDIA Grace CPU,可将加速计算无缝集成到现有基础设施中。
该多功能架构支持多种系统设计和网络选项,使 GB200 NVL2 平台成为了数据中心、边缘和蜂窝基站的理想选择,这些地点想要利用 AI 的强大性能以及无线 5G 连接。
例如在单个蜂窝基站中,GB200 服务器的一半可分配给 RAN 任务,另一半可通过多实例 GPU(MIG)技术用于 AI 处理。在聚合站点中,可以为 RAN 和 AI 各分配一整台专用的 GB200 服务器。在集中部署的情况下,RAN 和 AI 工作负载之间可共享 GB200 服务器集群。
NVIDIA Blackwell GPU
NVIDIA Blackwell 是一个变革性的架构,它能够提高性能、效率和规模。NVIDIA Blackwell GPU包含 2080 亿个晶体管,并采用专门定制的 TSMC 4NP 节点制造而成。所有 NVIDIA Blackwell 产品均搭载两个接近光罩极限的裸片,并通过 10-TB/s 片间互联技术连接成一个统一的 GPU。
NVIDIA Grace CPU
NVIDIA Grace CPU是一款突破性的处理器,它专为运行 AI、vRAN、云计算和高性能计算(HPC)应用的现代数据中心设计。该处理器具有出色的性能和内存带宽,能耗却只有当今领先服务器处理器的一半。
NVLink2 C2C
GB200 NVL2 平台使用NVLink-C2C为每个 NVIDIA Grace CPU 和 NVIDIA Blackwell GPU 之间提供突破性的 900 GB/s 互联速度。结合第五代 NVLink,该平台提供了 1.4TB 的超大连贯内存模型,推动了加速 AI 和 vRAN 性能的提升。
第五代 NVIDIA NVLink
为了充分发挥超大规模计算和万亿参数 AI 模型的强大性能,服务器集群中的每个 GPU 都必须进行无缝而快速的通信。
第五代NVLink是一种高性能互联技术,能够提高 GB200 NVL2 平台的性能。
键值缓存
键值(KV)缓存通过存储对话上下文和历史记录来提高 LLM 的响应速度。
GB200 NVL2 通过其完全连贯的 NVIDIA Grace GPU 和 NVIDIA Blackwell GPU 内存来优化键值缓存,该内存通过 NVLink-C2C 连接,NVLink-C2C 的速度是 PCIe 的 7 倍。
这使得 LLM 预测单词的速度比基于 x86 的 GPU 更快。
MGX 参考架构
MGX GB200 NVL2 是一种将 CPU C-Link 和 GPU NVLink 相连的 2:2 配置。
HPM 包含以下组件:
NVIDIA Grace CPU(2 个)
用于 GPU puck 和 I/O 卡的连接器
安装在 2U AC 服务器中的 GPU 模块(2 个)
每个可插拔 GPU 模块包含 GPU、B2B 连接和 NVLink 连接器。
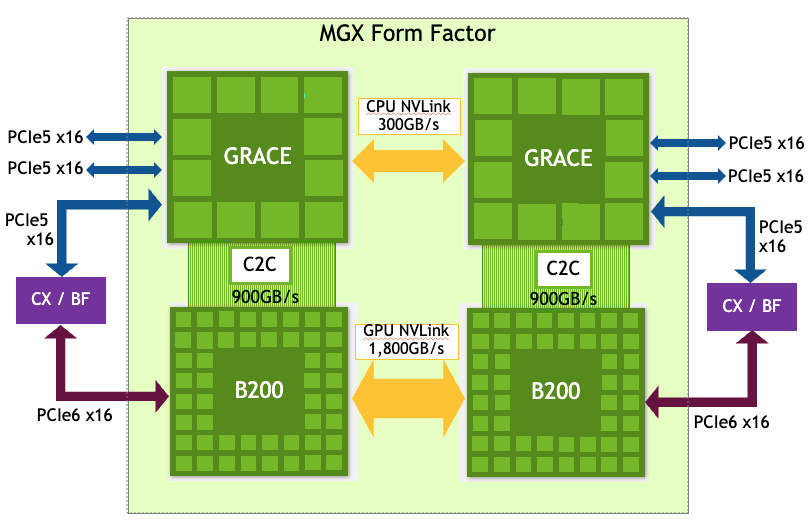
图 2. NVIDIA GB200 NVL2 平台布局
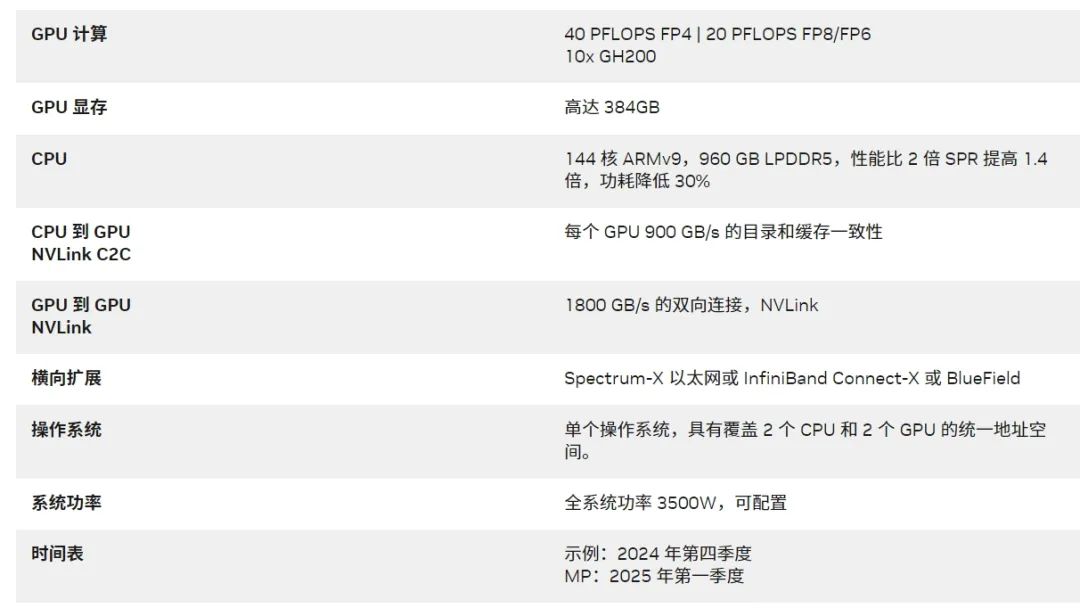
表 1. GB200 NVL2 平台特性
实时主流 LLM 推理
GB200 NVL2 平台引入了高达 1.3TB 的超大连贯内存,该内存由两个 NVIDIA Grace CPU 和两个 NVIDIA Blackwell GPU 共享。结合第五代 NVIDIA NVLink 和高速片间(C2C)连接技术,该共享内存将主流语言模型(如 Llama3-70B)的实时 LLM 推理性能提高了 5 倍。
在输入序列长度为 256、输出序列长度为 8,000、精度为 FP4 的情况下,GB200 NVL2 平台的推理速度最高可达每秒 25,000 个 token,折合每天 21.6 亿个 token。
图 3 显示了 GB200 NVL2 在支持 AI 和 RAN 工作负载时的表现。
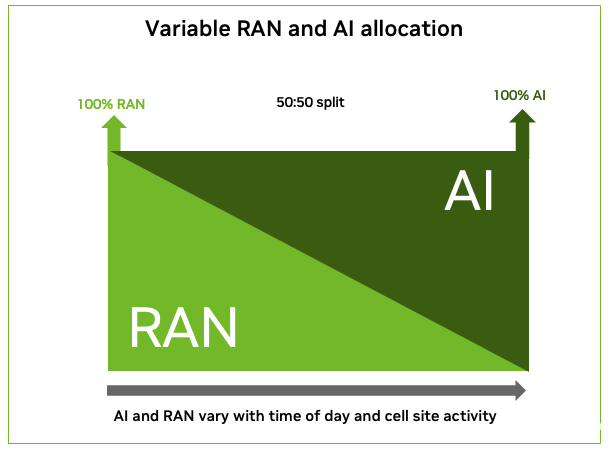
图 3. GB200 NVL2 中 RAN 和 AI 的计算利用率
以下是 GB200 NVL2 平台上 RAN 和 AI 的平台租用情况:
100% 利用率下的工作负载
RAN:约 36 个 100 MHz 64T64R
*token:25,000 token/秒
AI:约 10 美元/时,折合约 90,000 美元/年
50:50 利用率平分情况下的工作负载
RAN:约 18 个 100 MHz 64T64R
*token:12,500 token/秒
AI:约 5 美元/时,折合 45,000 美元/年
*token AI 工作负载:Llama-3-70B FP4 | 序列长度输入 256 /输出 8K
Aerial RAN Computer-1 的配套硬件
Aerial RAN Computer-1 的配套硬件是NVIDIA BlueField-3和NVIDIA Spectrum-X。
NVIDIA BlueField-3
NVIDIA BlueField-3 DPU 支持实时数据传输,提供前传 eCPRI 流量所需的精确 5G 时序。
NVIDIA 提供完整的 IEEE 1588v2 精确时间协议(PTP)软件解决方案。NVIDIA PTP软件解决方案专为满足最苛刻的 PTP 配置文件设计。NVIDIA BlueField-3 包含 1 个集成式 PTP 硬件时钟(PHC),使设备精度突破了 20 纳秒,同时还提供了计时相关功能,包括时间触发调度和基于时间的软件定义网络(SDN)加速等。
该技术还使软件应用能够以高带宽传输前传、兼容 RAN 数据。
NVIDIA Spectrum-X
边缘和数据中心网络在推动 AI 和无线技术进步及性能方面发挥着至关重要的作用,它们是支撑分布式 AI 模型推理、生成式 AI 和世界领先 vRAN 性能的支柱。
NVIDIA BlueField-3 DPU 支持成百上千个 NVIDIA Blackwell GPU 的高效伸缩,为应用提供了最佳的性能。
NVIDIA Spectrum-X 以太网平台专为提高基于以太网的 AI 云的性能和效率设计,并且包含了 5G 定时同步所需的所有功能。其 AI 网络性能较传统以太网提高了 1.6 倍,同时还能在多租户环境中保证性能的一致性和可预测性。
当在机架配置中部署 Aerial RAN Computer-1 时,Spectrum-X 以太网交换机可用作一种两用架构。它既可处理计算架构上的前传和 AI(东西向)流量,也可传输融合架构上的回传或中传以及 AI(南北向)流量。远程无线电设备按照 eCPRI 协议将该交换机作为终端。
Aerial RAN Computer-1
上的软件堆栈
Aerial RAN Computer-1 上的关键软件堆栈包括:
NVIDIA Aerial CUDA 加速 RAN
NVIDIA AI Enterprise 和 NVIDIA NIM
NVIDIA 云功能
NVIDIA Aerial CUDA 加速 RAN
NVIDIA Aerial CUDA 加速 RAN是 NVIDIA 构建的主要 RAN 软件,该软件适用于在 Aerial RAN Computer-1 上运行的 5G 和 5G 专网。
它包含了由 NVIDIA GPU 加速的互通 PHY 和 MAC 层库,这些库可以通过 AI 组件轻松修改和无缝扩展。其他软件提供商、电信公司、云服务提供商(CSP)和企业也可以使用这些经过强化的 RAN 软件库,构建定制化商业级软件定义 5G RAN 和未来的 6G RAN。
Aerial CUDA 加速 RAN 与 NVIDIA Aerial AI 无线电框架集成,该框架提供了一套 AI 增强功能,支持在 RAN 中使用框架工具 pyAerial、NVIDIA Aerial 数据湖和NVIDIA Sionna进行训练和推理。
与其形成互补的是NVIDIA Aerial Omniverse数字孪生。NVIDIA Aerial Omniverse 数字孪生一个系统级网络数字孪生开发平台,它实现了对无线系统的物理级精度模拟。
NVIDIA AI Enterprise
和 NVIDIA NIM
NVIDIA AI Enterprise是一个企业级生成式 AI 软件平台。NVIDIA NIM是一个微服务集,可简化生成式 AI 应用基础模型的部署。
两者共同提供了易于使用的微服务和蓝图。这些微服务和蓝图加快了数据科学流程的速度,并且简化了企业生产级 co-pilot 和其他生成式 AI 应用的开发与部署。
企业和电信公司既可以订阅NVIDIA Elastic NIM托管服务,也可以自行部署和管理 NIM。Aerial RAN Computer-1 可以托管 NVIDIA AI Enterprise 和基于 NIM 的 AI 与生成式 AI 工作负载。
NVIDIA 云功能
NVIDIA 云功能为 GPU 加速的 AI 工作负载提供了一个无服务器平台,确保了安全性、可扩展性与可靠性。它支持多种通信协议,包括:
HTTP 轮询
流式传输
gRPC
NVIDIA 云功能主要适用于运行时间较短的抢占式工作负载,例如推理和微调等。由于 RAN 工作负载的资源利用率会随时间变化,因此该功能非常适合 Aerial RAN Computer-1 平台。
短暂的抢占式 AI 工作负载通常可以填满一天中利用率较低的时段,从而保持 Aerial RAN Computer-1 平台的高利用率。
部署选项和性能
Aerial RAN Computer-1 提供多种部署选项,包含了无线接入网络中的所有点:
无线基站蜂窝站点
接入点位置
移动交换中心
基带中心
如果用于 5G 专网,Aerial RAN Computer-1 可以位于企业经营场所内。
Aerial RAN Computer-1 可支持各种配置和位置,包括私有云、公有云或混合云环境,而且无论位置或接口标准如何,均可使用相同的软件。与传统的单一用途 RAN 计算机相比,该能力带来了空前的灵活性。
该解决方案还支持各种网络技术,包括:
开放式无线接入网络(Open-RAN)架构
AI-RAN
3GPP 标准
其他业界领先的规范
与早期的 NVIDIA GPU 相比,基于 GB200 的 Aerial RAN Computer-1 进一步提升了 RAN 和 AI 处理性能及能效(图 4)。
GB200 NVL2 平台为现有基础设施提供了易于部署和扩展的一站式 MGX 服务器。您可以通过先进的 RAN 计算技术获得主流 LLM 推理和数据处理功能。

图 4. GB200 NVL2 与前几代产品的性能比较
总结
AI-RAN 将给电信行业带来变革,使电信公司能够通过生成式 AI、机器人和自主技术来开辟新的收入来源,并提供更好的体验。NVIDIA AI Aerial 平台实现了 AI-RAN 的落地,使其与 NVIDIA 实现 AI 原生无线网络的广阔愿景相吻合。
借助 Aerial RAN Computer-1,电信公司现在可以在通用基础设施上部署 AI-RAN。您可以通过同时运行 RAN 和 AI 工作负载,最大程度地提高利用率,并利用 AI 算法提高 RAN 性能。
最重要的是,借助这台通用计算机,您可以把握新的机遇,成为需要本地计算和数据主权的企业首选的 AI 架构。您可以从以 AI 为中心的方法开始,然后采用 RAN 并进行软件升级,从第一天起就获得最大化投资回报。
T-Mobile 和软银已宣布,将与领先的 RAN 软件提供商一起使用 NVIDIA AI Aerial 的软硬件组件,实现 AI-RAN 的商业化落地。
在世界移动通信大会上,Vapor IO 和拉斯维加斯市共同宣布使用 NVIDIA AI Aerial 部署全球首个 5G 专网 AI-RAN。
-
AI-RAN重新定义下一代蜂窝网络的设计与部署方式2026-06-29 516
-
是德科技与三星携手英伟达展示端到端AI-RAN验证工作流程2026-03-05 1068
-
罗德与施瓦茨携手英伟达推进基于数字孪生技术的AI-RAN测试2026-03-03 859
-
如何借助NVIDIA ARC-Compact在基站部署AI-RAN2025-05-27 2276
-
爱立信与软银在AI-RAN集成领域的重要进展2025-03-17 13552
-
是德科技与东北大学合作展示AI-RAN协调测试方案2025-03-05 1558
-
利用NVIDIA AI Aerial推动电信行业发展2024-11-20 1627
-
诺基亚、英伟达与T-Mobile携手共建首个AI-RAN创新中心2024-09-26 1402
-
是德科技加入AI-RAN联盟,推动无线网络AI创新2024-08-28 2107
-
罗德与施瓦茨成为AI-RAN 联盟的新成员2024-06-27 1840
-
6G与AI强绑定,AI-RAN联盟成立,无中国厂商参与?2024-03-01 7019
-
英伟达牵手多巨头,发起AI-RAN联盟,涉足电信业百亿美元市场2024-02-28 1666
-
AI 和无线行业领导者共同成立 AI-RAN 联盟2024-02-27 895
全部0条评论

快来发表一下你的评论吧 !
