

CPU寄存器详解
嵌入式技术
描述
组件
计算机是一种数据处理设备,它由CPU和内存以及外部设备组成。CPU负责数据处理,内存负责存储,外部设备负责数据的输入和输出,它们之间通过总线连接在一起。CPU内部主要由控制器、运算器和寄存器组成。控制器负责指令的读取和调度,运算器负责指令的运算执行,寄存器负责数据的存储,它们之间通过CPU内的总线连接在一起。每个外部设备(例如:显示器、硬盘、键盘、鼠标、网卡等等)则是由外设控制器、I/O端口、和输入输出硬件组成。外设控制器负责设备的控制和操作,I/O端口负责数据的临时存储,输入输出硬件则负责具体的输入输出,它们间也通过外部设备内的总线连接在一起。
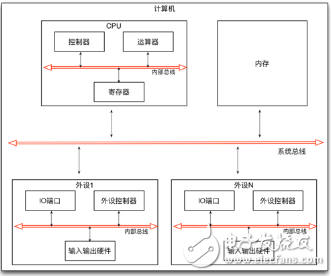
组件化的硬件体系
上面的计算机系统结构图中我们可以看出 硬件系统的这种组件化的设计思路总是贯彻到各个环节。在这套设计思想(冯。诺依曼体系架构)里面,总是有一部分负责控制、一部分负责执行、一部分则负责存储,它之间进行交互以及接口通信则总是通过总线来完成。这种设计思路一样的可以应用在我们的软件设计体系里面:组件和组件之间通信通过事件的方式来进行解耦处理,而一个组件内部同样也需要明确好各个部分的职责(一部分负责调度控制、一部分负责执行实现、一部分负责数据存储)。
缓存
一个完整的CPU系统里面有控制部件、运算部件还有寄存器部件。中寄存器部件的作用就是进行数据的临时存储。既然有内存作为数据存储的场所,那么为什么还要有寄存器呢?答案就是速度和成本。我们知道CPU的运算速度是非常快的,如果把运算的数据都放到内存里面的话那将大大降低整个系统的性能。解决的办法是在CPU内部开辟一小块临时存储区域,并在进行运算时先将数据从内存复制到这一小块临时存储区域中,运算时就在这一小快临时存储区域内进行。我们称这一小块临时存储区域为寄存器。因为寄存器和运算器以及控制器是非常紧密的联系在一起的,它们的频率一致,所以运算时就不会因为数据的来回传输以及各设备之间的频率差异导致系统性能的整体下降。你可能又会问为什么不把整个内存都集成进CPU中去呢?答案其实还是成本问题!
因为CPU速度很快,相应的寄存器也需要存取很快,二者速度上要匹配,所以这些寄存器的制作难度大,选材精,而且是集成到芯片内部,所价格高。而内存的成本则相对低廉,而且从工艺上来说,我们不可能在CPU内部集成大量的存储单元。
运算的问题通过寄存器解决了,但是还存在一个问题:我们知道程序在运行时是要将所有可执行的二进制指令代码都装载到内存里面去,CPU每执行一条指令前都需要从内存中将指令读取到CPU内并执行。如果按这样每次都从内存读取一条指令来依次执行的话,那还是存在着CPU和内存之间的处理瓶颈问题,从而造成整体性能的下降。这个问题怎么解决呢?答案就是高速缓存。其实在CPU内部不仅有为解决运算问题而设计的寄存器,还集成了一个部分高速缓存存储区域。高度缓存的制造成本要比寄存器低,但是比内存的制造成本高,容量要比寄存器大,但是比内存的容量小很多。虽然没有寄存器和运算器之间的距离那么紧密,但是要比内存到运算器之间的距离要近很多。一般情况下CPU内的高速缓存可能只有几KB或者几十KB那么大。正是通过高速缓存的引入,当程序在运行时,就可以预先将部分在内存中要执行的指令代码以及数据复制到高速缓存中去,而CPU则不再每次都从内存中读取指令而是直接从高速缓存依次读取指令来执行,从而加快了整体的速度。当然要预读取哪块内存区域的指令和数据到缓存上以及怎么去读取这些工作都交给操作系统去调度完成,这里面的算法和逻辑也非常的复杂,大家可以通过学习操作系统相关的课程去了解,这里就不再展开了。可以看出高速缓存的作用解决了不同速度设备之间的数据传递问题。在实际中CPU内部可能不止设有一级高速缓存,有可能会配备两级到三级的高速缓存,越高级的高速缓存速度越快,容量越低,而越低级的高度缓存则速度越慢,但是容量越大。比如iPhoneX上的搭载的arm处理器A11里面除了固有的37个通用寄存器外,L1级缓存的容量是64KB, L2级缓存的容量达到了8M(这么大的二级缓存,都有可能在你的程序代码少时可以一次性将代码读到缓存中去运行), 没有配备三级缓存。
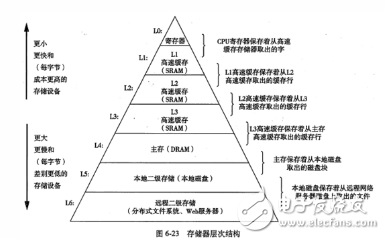
存储的层次结构
我们知道在软件设计上有一个所谓的空间换时间的概念,就是当两个对象之间进行交互时因为二者处理速度并不一致时,我们就需要引入缓存来解决读写不一致的问题。比如文件读写或者socket通信时,因为IO设备的处理速度很慢,所以在进行文件读写以及socket通信时总是要将读出或者写入的部分数据先保存到一个缓存中,然后再统一的执行读出和写入操作。
可以看出无论是在硬件层面上还是在软件层面上,当两个组件之间因为速度问题不能进行同步交互时,就可以借助缓存技术来弥补这种不平衡的状况
指令中的寄存器
CPU执行的每条指令都由操作码和操作数组成,简单理解就是要对谁(操作数)做什么(操作码)。在CPU内部要运算的数据总是放在寄存器中,而实际的数据则有可能是放在内存或者是IO端口中。因此我们的程序其实大部分时间就是做了如下三件事情:
把内存或者I/O端口的数据读取到寄存器中
将寄存器中的数据进行运算(运算只能在寄存器中进行)
将寄存器的内容回写到内存或者I/O端口中
这三件事情都是跟寄存器有关,寄存器就是数据存储的中转站,非常的关键,因此在CPU所提供的指令中,如果操作数有两个时至少要有一个是寄存器。
;下面部分是arm64指令示例:
mov x0, #0x100 ;将常数0x100赋值给寄存器x0
mov x1, x0 ;将寄存器x0的值赋值给寄存器x1
ldr x3, [sp, #0x8] ;将栈顶加0x8处的内存值赋值给x3寄存器
add x0, x1, x2 ;x0 = x1 + x2 可以看出运算的指令必须放在寄存器中
sub x0, x1, x2 ;r0 = x1 - x2
str x1, [sp, #0x08] ;将寄存器x1中的值保存到栈顶加0x8处的内存处。
;下面部分是x64指令示例(AT&T汇编):
mov $0x100, %rax ;将常数0x100赋值给寄存器rax
mov %rax, %rbx ;将寄存器rax的值赋值给rbx寄存器
movq 8(%rax), %rbx ;将寄存器rax中的值+8并将所指向内存中的数据赋值给rbx寄存器
所以不要将机器语言或者汇编语言当成是很复杂或者难以理解的语言,如果你仔细观察一段汇编语言代码时,你就会发现几乎大部分代码都是做的上面的三件事情。我们在高级语言里面看到的只是变量,但是在低级语言里面看到的就是内存地址和寄存器,你可以将内存地址和寄存器也理解为定义的变量,带着这样的思路去阅读汇编代码时你就会发现其实汇编语言也不是那么的困难。在高级语言中我们可以根据自身的需要定义出很多有特殊意义的变量,但是低级语言中因为寄存器就那么几个,它必须要被复用和重复使用,因此汇编语言中就会出现大量的将寄存器的内容保存到内存中的指令代码以及从内存中读取到寄存器中的指令代码。这些代码中有很多都有共性,只要在你实践中多去阅读,然后适应一下就很快能够很高兴的去看汇编代码了,熟能生巧吗。
-
解析CPU中的寄存器2022-09-19 5017
-
基于DWC2的USB驱动开发-发送相关的寄存器DMA寄存器详解2023-07-16 2909
-
编程寄存器相关位详解2021-08-12 1029
-
ARM寄存器详解2010-07-10 3241
-
DSP2812寄存器详解2016-01-08 1097
-
51寄存器的所有寄存器名称,(包括寄存器每一位的作用及用法)资源详解2017-10-16 1459
-
移位寄存器怎么用_如何使用移位寄存器_移位寄存器的用途2017-12-22 21053
-
寄存器操作方法_对寄存器操作的通用方法总结2018-05-22 24540
-
寄存器变量2019-06-03 2830
-
CPU、寄存器和内存单元的物理结构2022-09-05 5547
-
ARM通用寄存器及状态寄存器详解2023-01-06 9459
-
cpu寄存器和存储器的区别2023-03-21 2257
-
工程监测无线中继采集仪的寄存器(参数)汇总详解2023-05-19 1250
-
CPU的6个主要寄存器2024-02-03 7102
-
寄存器分为基本寄存器和什么两种2024-07-12 2779
全部0条评论

快来发表一下你的评论吧 !
