

后摩尔时代的创新:在米尔FPGA上实现Tiny YOLO V4,助力AIoT应用
描述
学习如何在 MYIR 的 ZU3EG FPGA 开发板上部署 Tiny YOLO v4,对比 FPGA、GPU、CPU 的性能,助力 AIoT 边缘计算应用。
一、 为什么选择 FPGA:应对 7nm 制程与 AI 限制
在全球半导体制程限制和高端 GPU 受限的大环境下,FPGA 成为了中国企业发展的重要路径之一。它可支持灵活的 AIoT 应用,其灵活性与可编程性使其可以在国内成熟的 28nm 工艺甚至更低节点的制程下实现高效的硬件加速。
米尔的 ZU3EG 开发板凭借其可重构架构为 AI 和计算密集型任务提供了支持,同时避免了 7nm 工艺对国产芯片设计的制约。通过在 ZU3EG 上部署 Tiny YOLO V4,我们可以为智能家居、智慧城市等 AIoT 应用提供高效的解决方案。
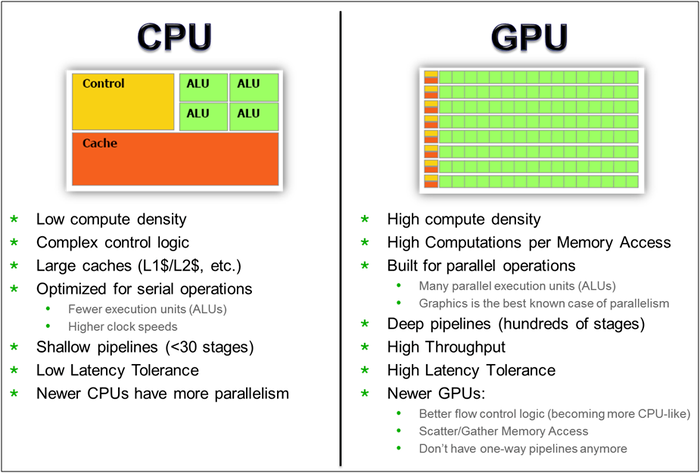
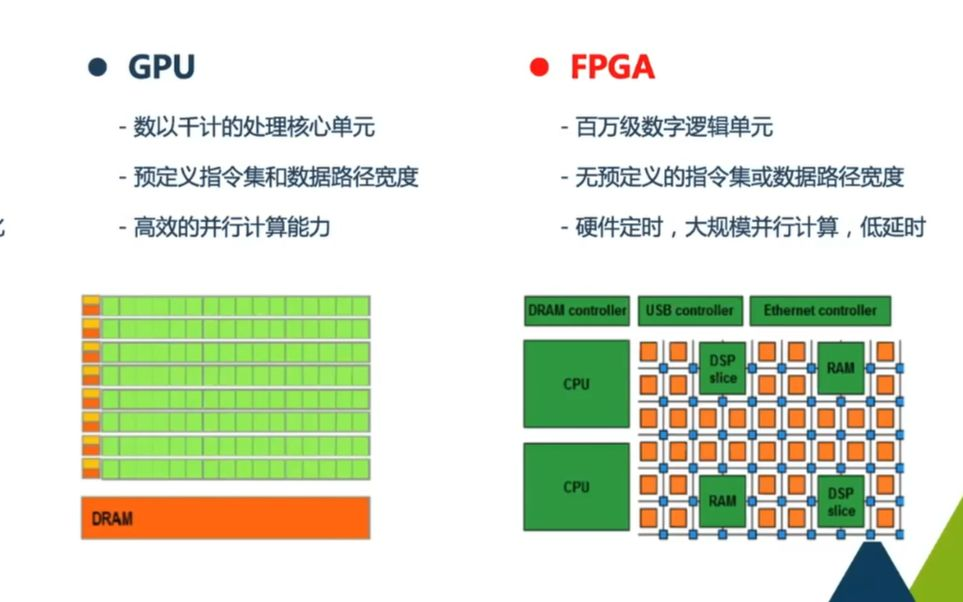
CPU GPU FPGA 架构对比
二、 了解 Tiny YOLO 模型及其适用性
YOLO(You Only Look Once)是一种实时物体检测模型,它通过一次性扫描整个图像,实现高效的对象识别。
而其简化版 Tiny YOLO V4 更适合嵌入式设备,具有较少的层数和参数。其轻量化特性更适合在资源受限的设备上运行,尤其在低功耗、实时检测的边缘计算设备中表现出色。
相比传统 GPU,FPGA 能在小面积和低功耗下实现类似的推理性能,非常契合 AIoT 应用。像米尔 ZU3EG 这样的 FPGA 开发板,通过底板和丰富接口的载板设计,非常适合高效的嵌入式低功耗数据处理。
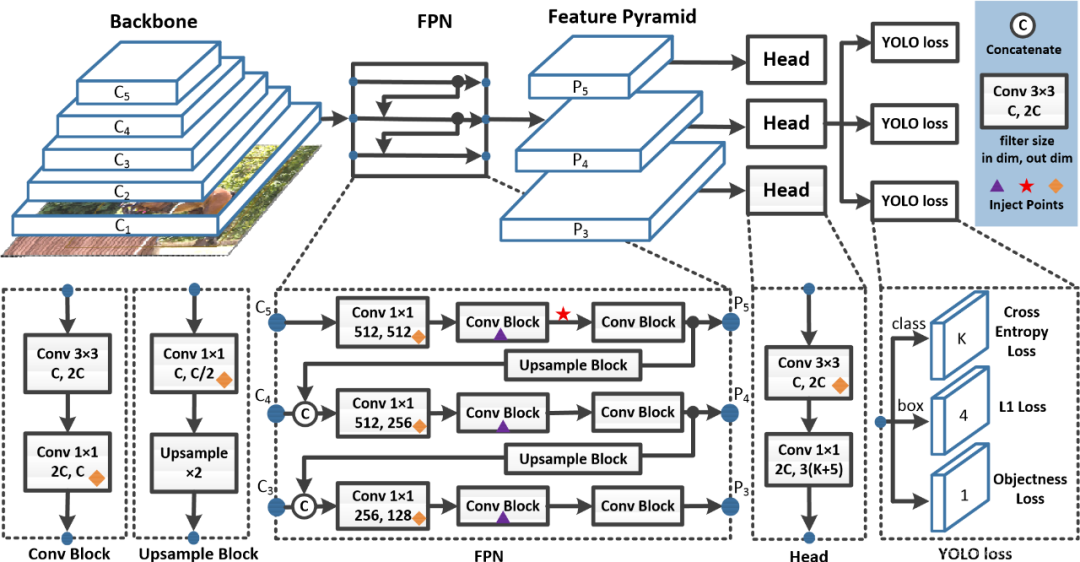
Yolo V4 网络结构图
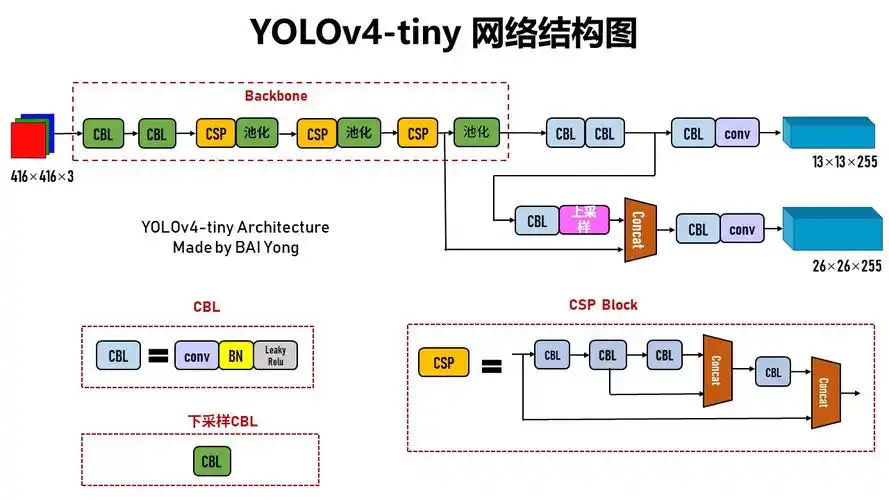
Tiny Yolo V4 网络结构图
(通过优化网络结构和参数,保持较高检测精度的同时,降低模型的计算量和内存占用)
三、 获取数据集和模型
可下载开源训练集或预训练模型。为了确保兼容性,建议将模型转换为 ONNX 格式,以便后续能在 FPGA 上完成优化。
1.下载 Tiny YOLO V4 模型:从Darknet 的 GitHub 仓库 获取 Tiny YOLO 的预训练权重,或者在 COCO 等数据集上自行训练模型。自定义的模型适用于特定应用场景(如车辆检测、人脸检测等)。
2.数据准备:若要自定义模型,可使用 LabelImg 等工具对数据集进行标注,将数据转为 YOLO 格式。之后,可将 YOLO 格式转换为 ONNX 格式,以便兼容 FPGA 优化工具链。
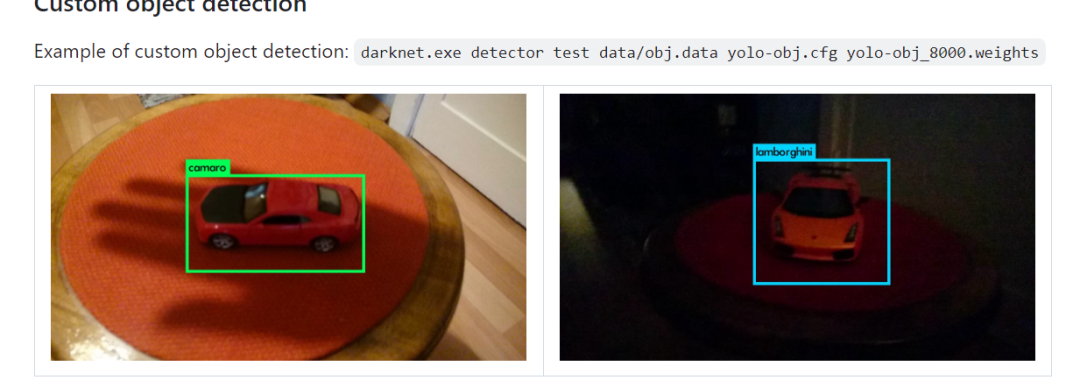
Tiny YOLO 在 Darknet 上训练的截图
四、 通过 Vivado HLS 为 FPGA 准备模型
要将模型部署到 FPGA,需要将神经网络操作转换为硬件级描述。使用 Xilinx 的 Vitis HLS(高级综合)可以将 Tiny YOLO v4 的 C++ 模型代码的转化为 Verilog RTL(寄存器传输级)代码,从而将模型从软件世界带入硬件实现。
详细步骤:
1.模型层映射和优化:
- 将 YOLO 的每一层(如卷积层、池化层)映射为硬件友好的 C/C++ 结构。例如,将卷积映射为乘累加(MAC)数组,通过流水线实现并行化。
2.算子加速与指令优化:
- 流水线(Pipelining):利用流水线来处理多项操作并行,减少延迟。
- 循环展开(Loop Unrolling):展开循环,以每周期处理更多数据,尤其在卷积操作中有效。
- 设置 DATAFLOW 指令,使层间独立处理。
3.量化与位宽调整:
- 将激活值和权重量化为定点精度(例如 INT8),而非浮点数。这在维持准确度的同时显著降低计算量,尤其适合 FPGA 的固定点运算支持。
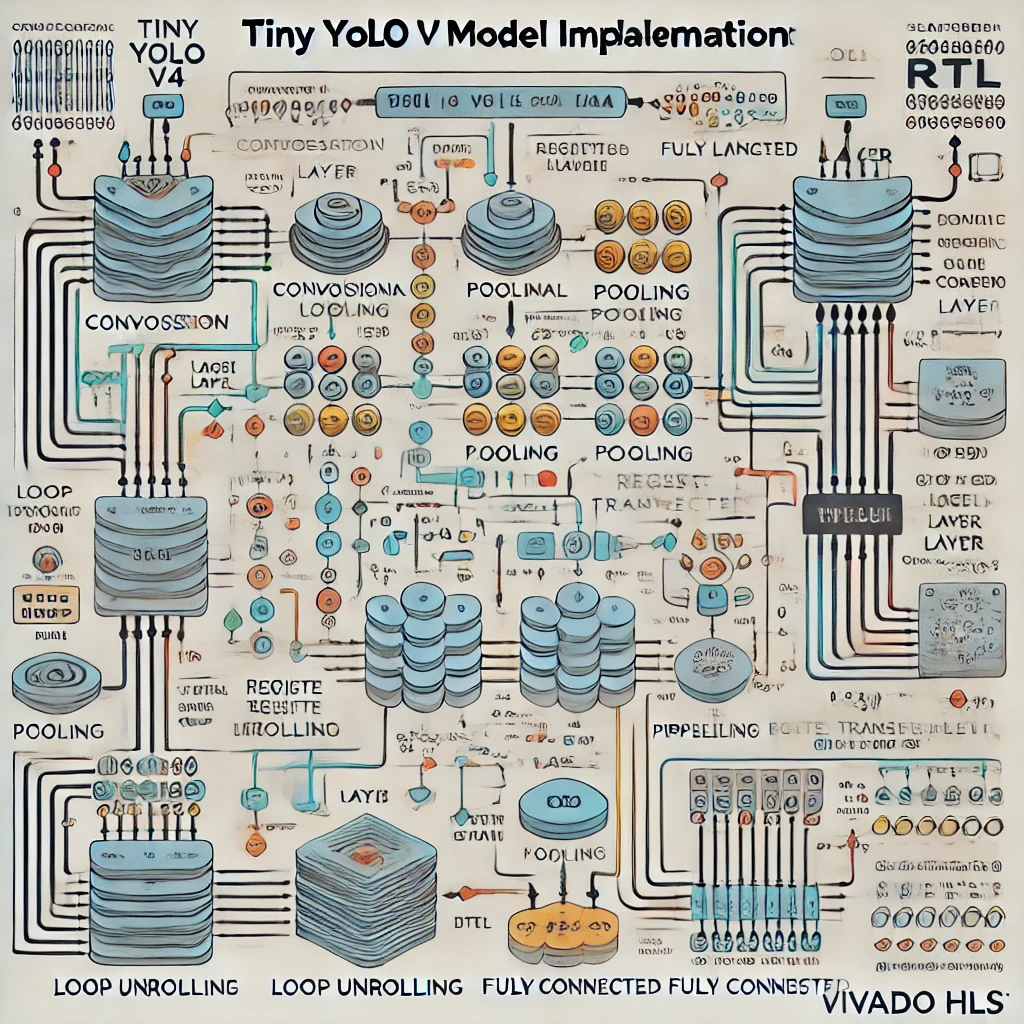
Tiny YOLO 模型在 Vivado HLS 中的层层转化流程图
五、 使用 Vivado 综合与部署 Verilog 到 米尔的ZU3EG FPGA开发板
当 HLS 生成的 RTL 代码准备就绪后,可以使用 Vivado 将模型部署到 FPGA。
1.Vivado 中的设置:
将 HLS 输出的 RTL 文件导入 Vivado。
在 Vivado 中创建模块设计,包括连接AXI 接口与 ZU3EG 的 ARM 核连接。
2.I/O 约束与时序:
定义 FPGA 的 I/O 引脚约束,以匹配 ZU3EG 板的特定管脚配置。配置时钟约束以满足合适的数据速率(如视频数据 100-200 MHz)。
进行时序分析,确保延迟和响应速度达到实时要求。
3.生成比特流并下载到 ZU3EG:
生成的比特流可以直接通过 JTAG 或以太网接口下载到 ZU3EG。
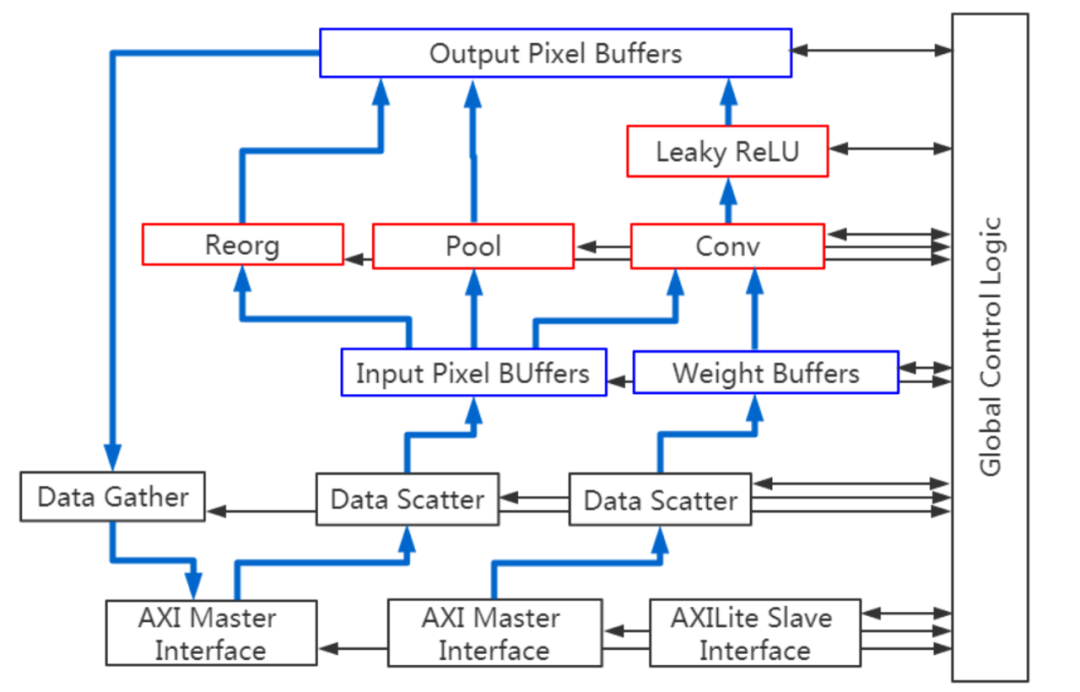
将 Tiny YOLO 处理模块连接到 米尔ZU3EG开发板 的外设和接口
六、 在 FPGA 上测试并运行推理
现在 Tiny YOLO 已部署,可以验证其实时对象检测性能。
1.数据采集:
- 通过连接的相机模块捕捉图像或视频帧,或者使用存储的测试视频。
- 使用 ZU3EG 的 ARM 核上的 OpenCV 对帧进行预处理,再将它们传入 FPGA 预处理后进行推理。
2.后处理与显示:
- 模型检测对象后,输出边框和类别标签。使用 OpenCV 将边框映射回原始帧,并在每个检测到的对象周围显示类别和置信度。
3.性能测试:
- 测量帧速率(FPS)和检测准确度。微调量化位宽或数据流参数,以优化实时需求。

Tiny YOLO 模型在 ZU3EG 上显示检测结果的实时输出,视频帧中标注了检测到的对象
七、 性能优化与调试技巧
为提高性能,可以进行以下调整:
- 内存访问:设计数据存储方式,最大限度利用缓存并减少数据传输,降低内存瓶颈。
- 降低延迟:重新评估关键路径延迟。若延迟过高,调整 Vitis HLS 中的流水线深度,并验证层间的数据依赖性。
- 量化改进:尝试 INT8 量化。Xilinx 的 Vitis AI 可帮助微调量化参数,以平衡准确性与速度。
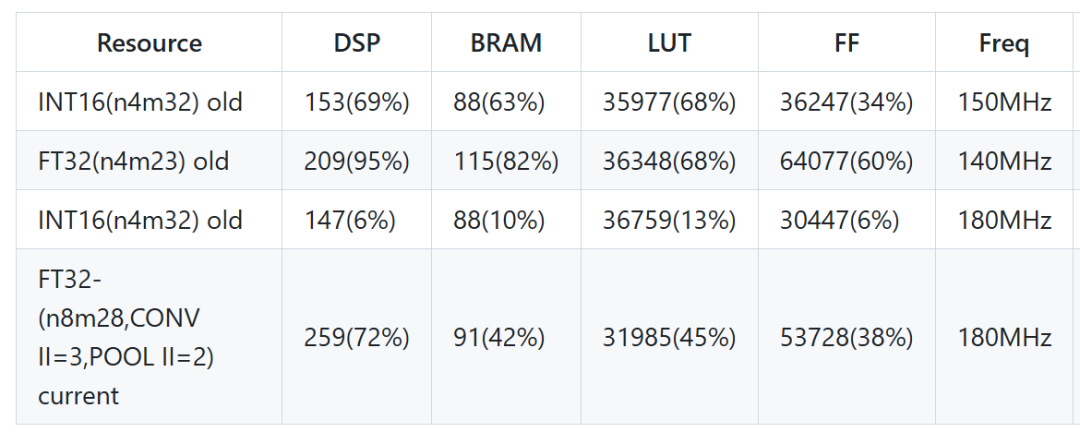
不同优化配置对资源使用的影响
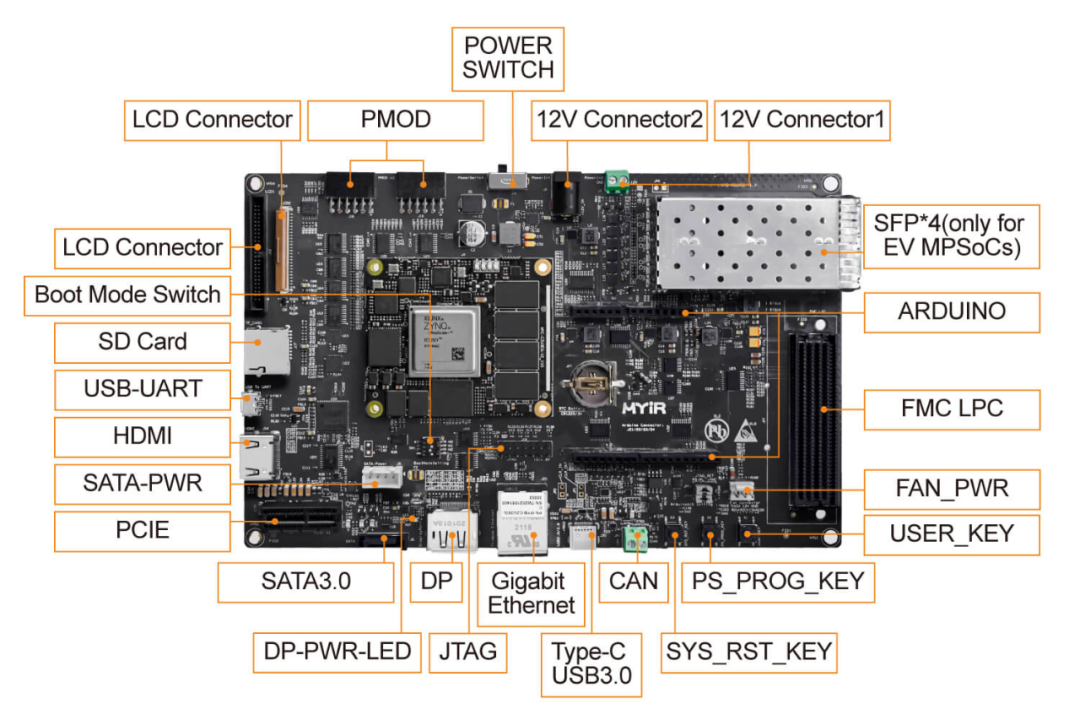
米尔MYC-CZU3EG/4EV/5EV-V2核心板及开发板
在MYIR 的 ZU3EG 开发平台上提供了一种高效的解决方案。利用 FPGA 独特的灵活性和低功耗优势,助力未来 AIoT 设备的普及和智能升级。
-
助力AIoT应用:在米尔FPGA开发板上实现Tiny YOLO V42024-12-06 2264
-
将Yolo V3-Tiny模型转换为IR格式遇到错误怎么解决?2025-03-05 519
-
韬定律:后摩尔时代走向“时间缩微”,光互联与SOA的新可能性2026-05-28 165
-
根据“后摩尔时代”芯片行业如何发展?2017-06-27 6002
-
介绍yolo v4版的安装与测试2022-02-17 1669
-
使用Yolo-v4-Tf-Tiny模型运行object_detection_demo.py时报错怎么解决?2023-08-15 1013
-
IC在后摩尔时代的挑战和机遇2010-02-21 1565
-
『 RJIBI 』-基于FPGA的YOLO-V3物体识别计算套件2020-05-19 16196
-
后摩尔时代集成电路产业特性及发展趋势2021-01-10 11501
-
重磅演讲:持续推进摩尔时代的IC设计艺术2021-11-16 5645
-
YOLO v4在jetson nano的安装及测试2021-12-22 822
-
聚焦后摩尔时代,后摩尔时代集成电路产业如何突破2022-04-08 2354
-
如何调节后摩尔时代的架构计算之争2022-06-13 1880
-
使用Tensil、TF-Lite和PYNQ在Ultra96板上运行YOLO v4 Tiny2023-06-25 839
-
后摩尔时代芯片互连新材料及工艺革新2023-08-25 1853
全部0条评论

快来发表一下你的评论吧 !
