

什么是大模型、大模型是怎么训练出来的及大模型作用
描述
本文通俗简单地介绍了什么是大模型、大模型是怎么训练出来的和大模型的作用。
什么是大模型
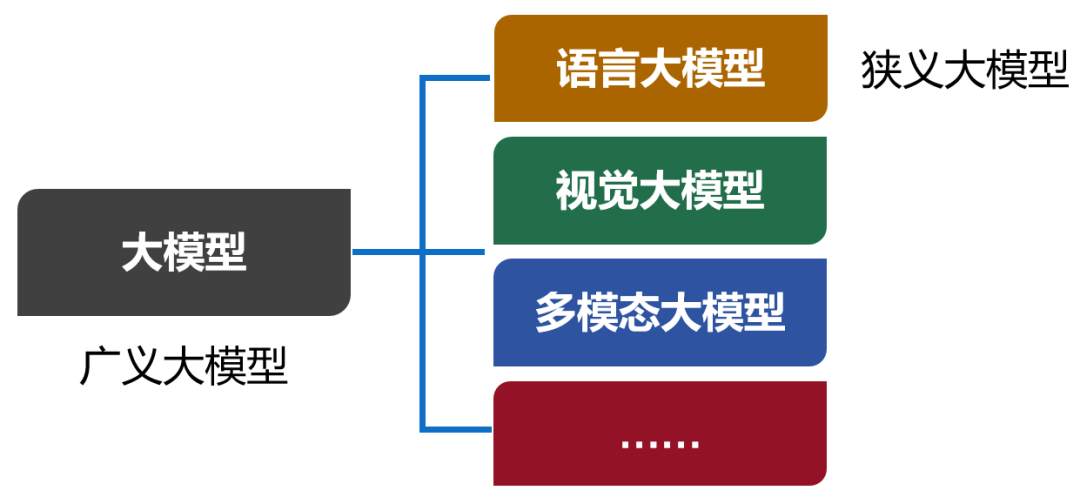
大模型,英文名叫Large Model,大型模型。早期的时候,也叫Foundation Model,基础模型。 大模型是一个简称,完整的叫法,应该是“人工智能预训练大模型”。预训练,是一项技术,我们后面再解释。 我们现在口头上常说的大模型,实际上特指大模型的其中一类,也是用得最多的一类——语言大模型(Large Language Model,也叫大语言模型,简称LLM)。 除了语言大模型之外,还有视觉大模型、多模态大模型等。现在,包括所有类别在内的大模型合集,被称为广义的大模型。而语言大模型,被称为狭义的大模型。
从本质来说,大模型,是包含超大规模参数(通常在十亿个以上)的神经网络模型。 神经网络是人工智能领域目前最基础的计算模型。它通过模拟大脑中神经元的连接方式,能够从输入数据中学习并生成有用的输出。
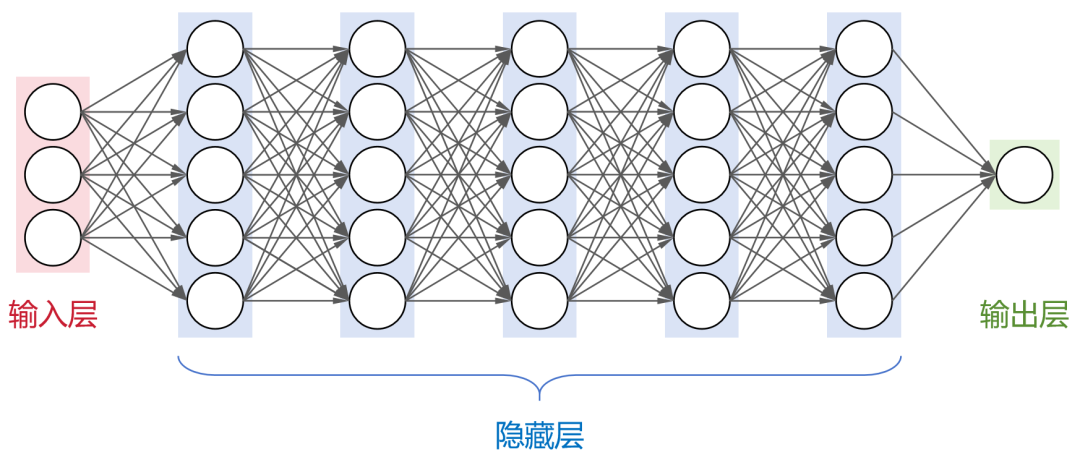
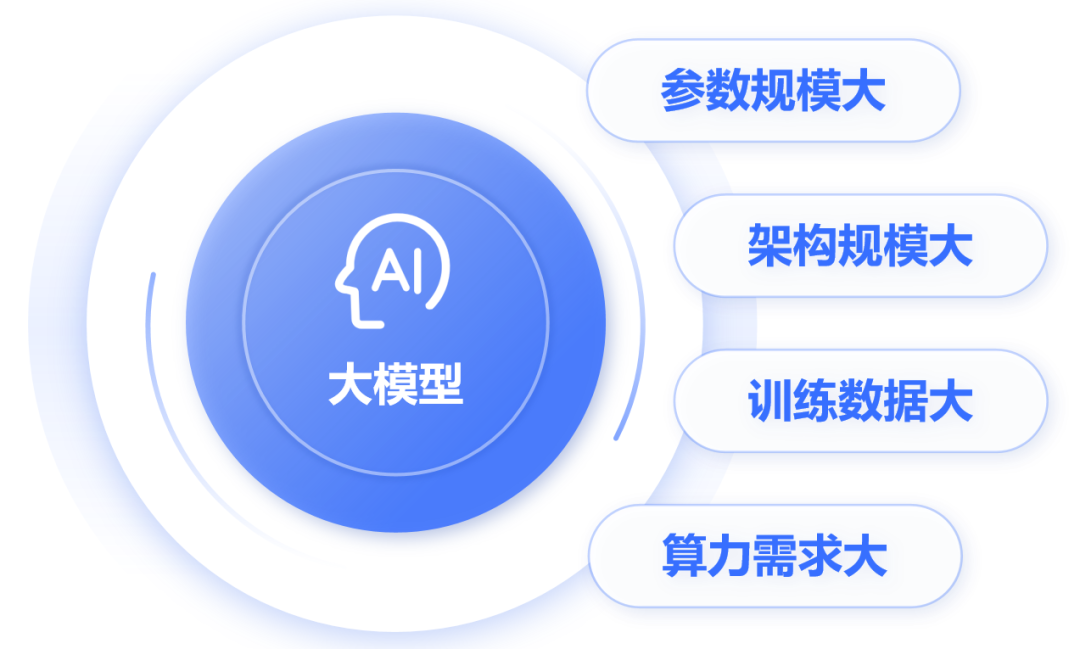
这是一个全连接神经网络(每层神经元与下一层的所有神经元都有连接),包括1个输入层,N个隐藏层,1个输出层。 大名鼎鼎的卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)以及transformer架构,都属于神经网络模型。 目前,业界大部分的大模型,都采用了transformer架构。 刚才提到,大模型包含了超大规模参数。实际上,大模型的“大”,不仅是参数规模大,还包括:架构规模大、训练数据大、算力需求大。
以GPT-3为例。这个大模型的隐藏层一共有96层,每层的神经元数量达到2048个。 大模型的参数数量和神经元节点数有一定的关系。简单来说,神经元节点数越多,参数也就越多。例如,GPT-3的参数数量,大约是1750亿。 大模型的训练数据,也是非常庞大的。 同样以GPT-3为例,采用了45TB的文本数据进行训练。即便是清洗之后,也有570GB。具体来说,包括CC数据集(4千亿词)+WebText2(190亿词)+BookCorpus(670亿词)+维基百科(30亿词),绝对堪称海量。 最后是算力需求。 这个大家应该都听说过,训练大模型,需要大量的GPU算力资源。而且,每次训练,都需要很长的时间。
GPU算卡 根据公开的数据显示,训练GPT-3大约需要3640PFLOP·天(PetaFLOP·Days)。如果采用512张A100 GPU(单卡算力195 TFLOPS),大约需要1个月的时间。训练过程中,有时候还会出现中断,实际时间会更长。 总而言之,大模型就是一个虚拟的庞然大物,架构复杂、参数庞大、依赖海量数据,且非常烧钱。 相比之下,参数较少(百万级以下)、层数较浅的模型,是小模型。小模型具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的垂直领域场景。
大模型是如何训练出来的?
接下来,我们了解一下大模型的训练过程。 大家都知道,大模型可以通过对海量数据的学习,吸收数据里面的“知识”。然后,再对知识进行运用,例如回答问题、创造内容等。 学习的过程,我们称之为训练。运用的过程,则称之为推理。
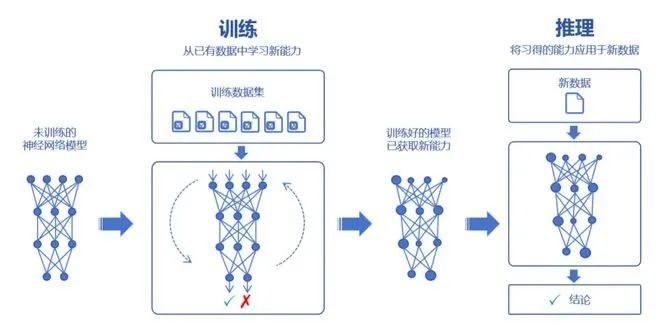
训练,又分为预训练(Pre-trained)和微调(Fine tuning)两个环节。
预训练
在预训练时,我们首先要选择一个大模型框架,例如transformer。然后,通过“投喂”前面说的海量数据,让大模型学习到通用的特征表示。 那么,为什么大模型能够具有这么强大的学习能力?为什么说它的参数越多,学习能力就越强? 我们可以参考MIT(麻省理工)公开课的一张图:
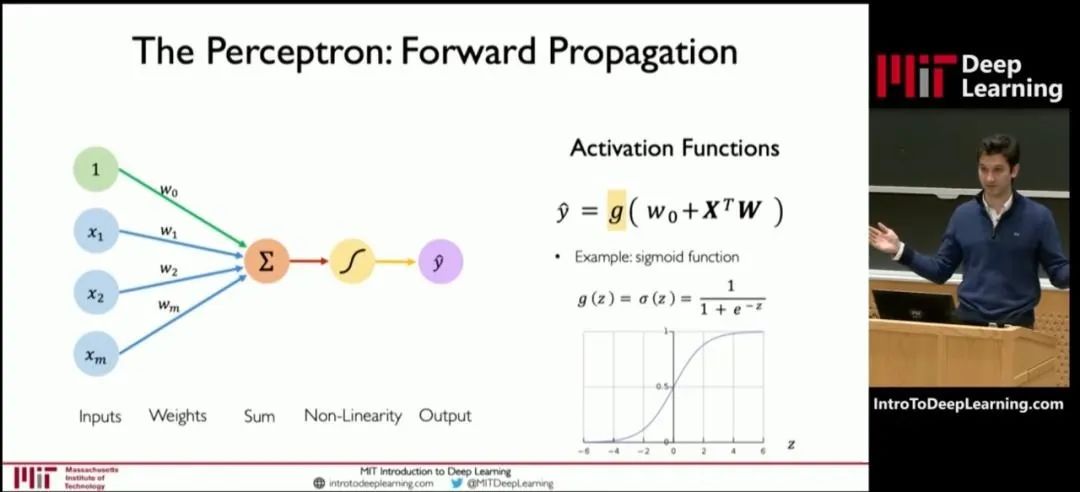
这张图是深度学习模型中一个神经元的结构图。 神经元的处理过程,其实就是一个函数计算过程。算式中,x是输入,y是输出。预训练,就是通过x和y,求解W。W是算式中的“权重(weights)”。 权重决定了输入特征对模型输出的影响程度。通过反复训练来获得权重,这就是训练的意义。 权重是最主要的参数类别之一。除了权重之外,还有另一个重要的参数类别——偏置(biases)。
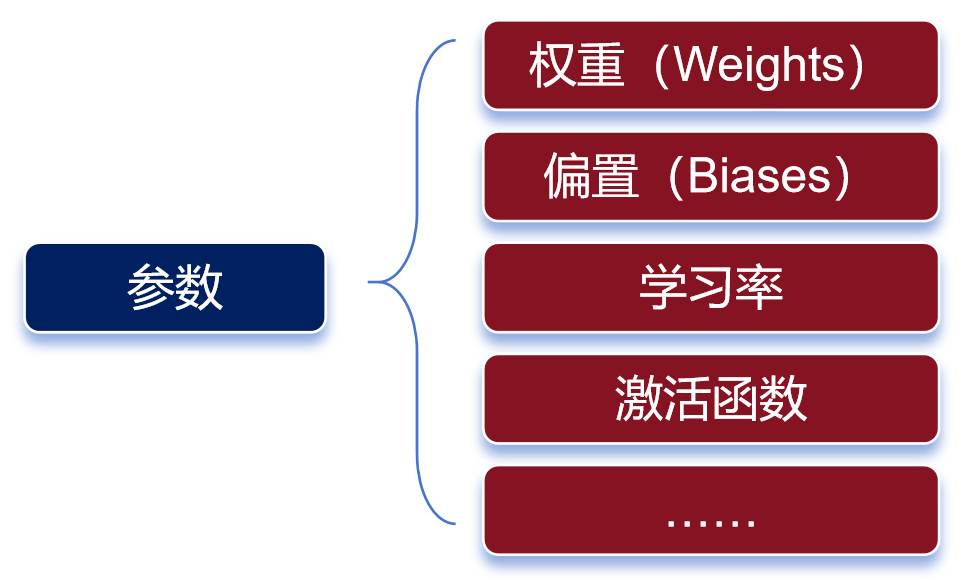
参数有很多种类 权重决定了输入信号对神经元的影响程度,而偏置则可以理解为神经元的“容忍度”,即神经元对输入信号的敏感程度。 简单来说,预训练的过程,就是通过对数据的输入和输出,去反复“推算”最合理的权重和偏置(也就是参数)。训练完成后,这些参数会被保存,以便模型的后续使用或部署。 参数越多,模型通常能够学习到更复杂的模式和特征,从而在各种任务上表现出更强的性能。 我们通常会说大模型具有两个特征能力——涌现能力和泛化能力。 当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,会表现出一些未能预测的、更复杂的能力和特性。模型能够从原始训练数据中,自动学习并发现新的、更高层次的特征和模式。这种能力,被称为“涌现能力”。 “涌现能力”,可以理解为大模型的脑子突然“开窍”了,不再仅仅是复述知识,而是能够理解知识,并且能够发散思维。 泛化能力,是指大模型通过“投喂”海量数据,可以学习复杂的模式和特征,可以对未见过的数据做出准确的预测。 参数规模越来越大,虽然能让大模型变得更强,但是也会带来更庞大的资源消耗,甚至可能增加“过拟合”的风险。 过拟合,是指模型对训练数据学习得过于精确,以至于它开始捕捉并反映训练数据中的噪声和细节,而不是数据的总体趋势或规律。说白了,就是大模型变成了“书呆子”,只会死记硬背,不愿意融会贯通。 预训练所使用的数据,我们也需要再说明一下。 预训练使用的数据,是海量的未标注数据(几十TB)。 之所以使用未标注数据,是因为互联网上存在大量的此类数据,很容易获取。而标注数据(基本上靠人肉标注)需要消耗大量的时间和金钱,成本太高。 预训练模型,可以通过无监督学习方法(如自编码器、生成对抗网络、掩码语言建模、对比学习等,大家可以另行了解),从未标注数据中,学习到数据的通用特征和表示。 这些数据,也不是随便网上下载得来的。整个数据需要经过收集、清洗、脱敏和分类等过程。这样可以去除异常数据和错误数据,还能删除隐私数据,让数据更加标准化,有利于后面的训练过程。 获取数据的方式,也是多样化的。 如果是个人和学术研究,可以通过一些官方论坛、开源数据库或者研究机构获取。如果是企业,既可以自行收集和处理,也可以直接通过外部渠道(市场上有专门的数据提供商)购买。
微调
预训练学习之后,我们就得到了一个通用大模型。这种模型一般不能直接拿来用,因为它在完成特定任务时往往表现不佳。 这时,我们需要对模型进行微调。 微调,是给大模型提供特定领域的标注数据集,对预训练的模型参数进行微小的调整,让模型更好地完成特定任务。

行业数据类别 微调之后的大模型,可以称之为行业大模型。例如,通过基于金融证券数据集的微调,可以得到一个金融证券大模型。 如果再基于更细分的专业领域进行微调,就是专业大模型(也叫垂直大模型)。 我们可以把通用大模型理解为中小学生,行业大模型是大学本科生,专业大模型是研究生。
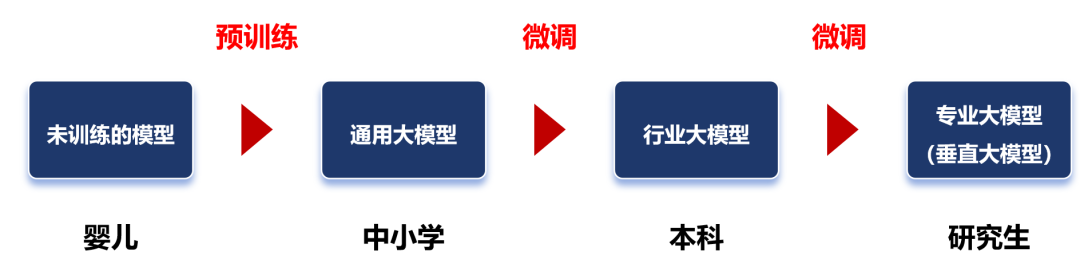
微调阶段,由于数据量远小于预训练阶段,所以对算力需求小很多。 大家注意,对于大部分大模型厂商来说,他们一般只做预训练,不做微调。而对于行业客户来说,他们一般只做微调,不做预训练。 “预训练+微调”这种分阶段的大模型训练方式,可以避免重复的投入,节省大量的计算资源,显著提升大模型的训练效率和效果。 预训练和微调都完成之后,需要对这个大模型进行评估。通过采用实际数据或模拟场景对大模型进行评估验证,确认大模型的性能、稳定性和准确性等是否符合设计要求。 等评估和验证也完成,大模型基本上算是打造成功了。接下来,我们可以部署这个大模型,将它用于推理任务。 换句话说,这时候的大模型已经“定型”,参数不再变化,可以真正开始干活了。 大模型的推理过程,就是我们使用它的过程。通过提问、提供提示词(Prompt),可以让大模型回答我们的问题,或者按要求进行内容生成。 最后,画一张完整的流程图:
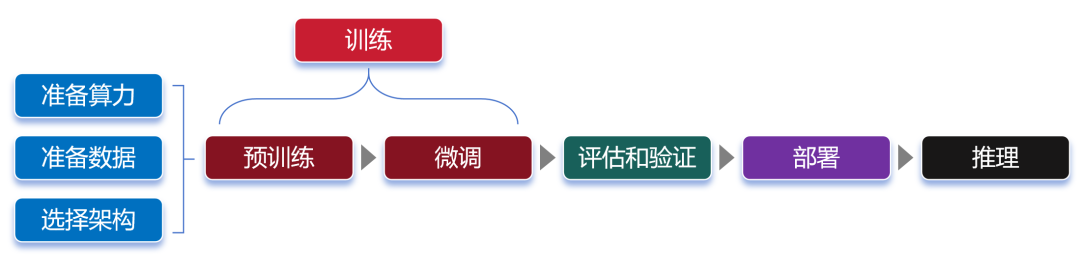
大模型究竟有什么作用?
根据训练的数据类型和应用方向,我们通常会将大模型分为语言大模型(以文本数据进行训练)、音频大模型(以音频数据进行训练)、视觉大模型(以图像数据进行训练),以及多模态大模型(文本和图像都有)。 语言大模型,擅长自然语言处理(NLP)领域,能够理解、生成和处理人类语言,常用于文本内容创作(生成文章、诗歌、代码)、文献分析、摘要汇总、机器翻译等场景。大家熟悉的ChatGPT,就属于此类模型。 音频大模型,可以识别和生产语音内容,常用于语音助手、语音客服、智能家居语音控制等场景。 视觉大模型,擅长计算机视觉(CV)领域,可以识别、生成甚至修复图像,常用于安防监控、自动驾驶、医学以及天文图像分析等场景。 多模态大模型,结合了NLP和CV的能力,通过整合并处理来自不同模态的信息(文本、图像、音频和视频等),可以处理跨领域的任务,例如文生图,文生视频、跨媒体搜索(通过上传图,搜索和图有关的文字描述)等。 今年以来,多模态大模型的崛起势头非常明显,已经成为行业关注的焦点。 如果按照应用场景进行分类,那么类别就更多了,例如金融大模型、医疗大模型、法律大模型、教育大模型、代码大模型、能源大模型、政务大模型、通信大模型,等等。 例如金融大模型,可以用于风险管理、信用评估、交易监控、市场预测、合同审查、客户服务等。功能和作用很多很多,不再赘述。
-
深层神经网络模型的训练:过拟合优化2020-12-02 3887
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
请问有没有不在linux上对.pt模型向.kmodel转换的教程呢?2025-02-08 544
-
Pytorch模型训练实用PDF教程【中文】2018-12-21 5207
-
深度融合模型的特点2021-07-16 2247
-
pytorch训练出来的模型参数保存为嵌入式C语言能够调用形式的方法2021-12-15 1565
-
在Ubuntu上使用Nvidia GPU训练模型2022-01-03 2535
-
海思AI芯片学习(十)将yolov3 darknet模型转换为caffemodel2022-01-26 802
-
AI模型如何将它导入工程里2022-07-14 2288
-
深度学习如何训练出好的模型2023-12-07 2319
-
人脸识别模型训练是什么意思2024-07-04 2373
-
python训练出的模型怎么调用2024-07-11 4642
-
瑞芯微(EASY EAI)RV1126B 模型转换教程示例2026-04-30 298
全部0条评论

快来发表一下你的评论吧 !
