

NVIDIA Spectrum X如何推动英伟达网络业务实现31亿美元收入
描述
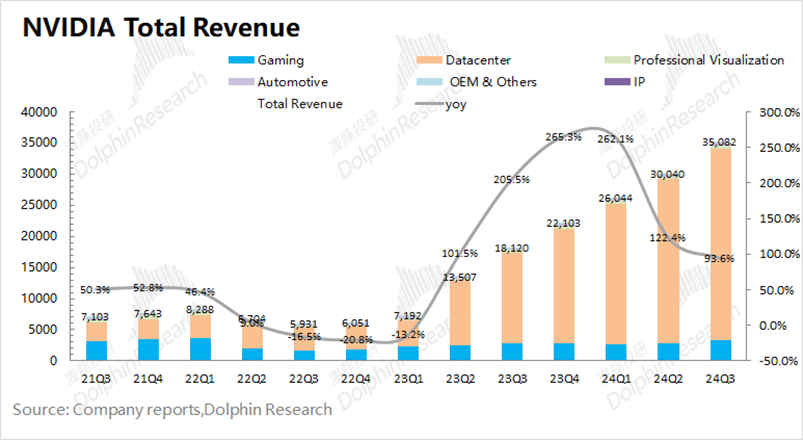
英伟达数据中心收入继续扩大
北京时间11月21日凌晨,英伟达发布本季度财报,公司实现营收350.8亿美元,同比增长93.6%,好于彭博一致预期(332亿美元)。公司收入增长,主要受数据中心业务需求增长的带动。在AI等需求的带动下,2025财年第三季度英伟达的数据中心业务在公司收入中的份额继续扩大,本季度达到了87.7%。
(Source:海豚投研)
细分来看,数据中心业务中计算收入为276亿美元,同比增长132%;网络收入为31亿美元,同比增长20%,这得益于益于Ethernet for AI,其中包括Spectrum X端到端以太网平台。据统计,AI网络NVIDIA Spectrum-X以太网AI收入同比增长超过3倍。
就在不久前,AI网络产业刚爆出了一项大新闻。马斯克仅用了122天就塑造了xAI 位于田纳西州孟菲斯市的 Colossus 超级计算机集群,该集群使用10万张NVIDIA Hopper GPU加速卡,超过1500个GPU机架,堪称全球最大AI超级计算机集群。
实际上,该集群使用了 NVIDIA Spectrum-X 以太网网络平台,该平台是专为多租户、超大规模的 AI 工厂提供卓越性能而设计的 RDMA网络而并不是InfiniBand网络。
NVIDIA声称专门面向 AI 的 Spectrum-X 以太网网络具有先进的功能,可在提供高效、可扩展的带宽的同时,实现低延迟和短尾延迟,而这些功能之前是 InfiniBand 网络所独有的。
NVIDIA基于 AI 的 Spectrum-X 以太网系统是一整套AI Networking的全家桶组合包括需要购买Spectrum-X交换机、Bluefield SuperNIC以及相关光模块及线缆组件。
基于以太网的Spectrum-X特性
我们根据超大以太网集群所面临的通信挑战来了解下基于以太网的Spectrum-X方案如何优化基于以太网的RDMA功能。
部分内容结合Nvidia AI Networking Whitepaper 编译
基于以太网的NVIDIA Spectrum-X:专为生成式AI时代设计
AI云作为支持生成式AI工作负载的新型数据中心类别,正日益受到业界的关注。这类数据中心不仅继承了传统云的核心功能,如多租户支持、安全性保障和多样化的工作负载支撑,更在支持更大规模的生成式AI应用方面展现出卓越能力。生成式AI是一类基于训练数据生成新输出的人工智能算法,其以图像、文本、音频等多种形式创造全新内容,与旨在识别模式和进行预测的传统人工智能系统形成鲜明对比。 NVIDIA Spectrum-X构建了以太网多租户、超大规模AI云而精心设计的革命性解决方案,它完美契合了生成式AI时代的发展需求。
无损网络与RDMA
在有损网络环境中,数据传输过程中面临着丢失或质量下降的风险。这种网络倾向于优先考虑数据传输的速度而非准确性。然而,对于AI应用而言,丢包导致的后果可能是灾难性的,包括性能下降、GPU资源的空闲浪费以及功耗的额外开销。
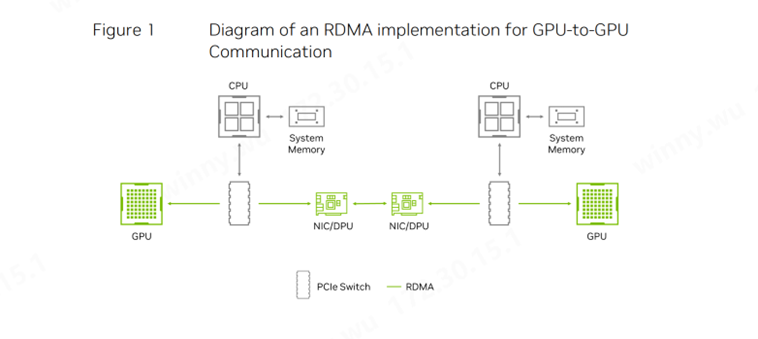
图1:GPU-GPU的RDMA通信实现示意图
无损网络则完全改变了这一局面。在这种网络中,数据传输的完整性得到严格保障,所有数据包都能够准确无误地到达目的地。尽管以太网最初的设计确实允许一定的丢包率,但在InfiniBand网络中,无损是基本要求。
随着GPU计算和大规模AI应用场景在云环境中的广泛应用,以太网也通过采用RoCE(RDMA over Converged Ethernet)和基于优先级的流量控制(PFC,Priority Flow Control)等技术,结合无损网络的实现,使用NVIDIA Spectrum-X,为AI应用提供了更加可靠和高效的解决方案。 远程直接内存访问(RDMA,Remote Direct Memory Access)技术的出现,进一步提升了网络传输的效率。它允许数据在远程系统、GPU和存储器之间直接传输,无需经过CPU的干预。传统的网络传输方式涉及多个复杂的步骤,包括数据的复制、网络发送以及接收方的多步骤处理。而RDMA则直接跨越了这些繁琐的中间环节,实现了数据的高效传输。我们在之前的Kiwi Talks有叙述过目前RDMA面对大规模集群存在的问题及建议。
挑战与方案1:自适应路由、多路径与数据包喷洒
传统数据中心的应用程序通常会产生大量的小数据流,这使得网络流量的统计平均值能够反映整体情况。在这种背景下,基于简单静态哈希的路由算法,如等价多路径(ECMP,Equal Cost Multi-Path),足以应对常见的网络流量问题。
然而,人工智能工作负载的特性却截然不同。它们通常会产生少量的大数据流,被称为“大象流”(elephant flows)。这些大象流会占用大量的链路带宽,如果多个大象流被路由到同一链路,就会导致严重的拥塞和高延迟。在人工智能应用中,即使是在非阻塞拓扑中使用ECMP,大象流之间的碰撞几率也非常高。由于AI作业的性能高度依赖于最坏情况下的表现,这些碰撞会导致模型训练时间既超出预期又变得极为不稳定。
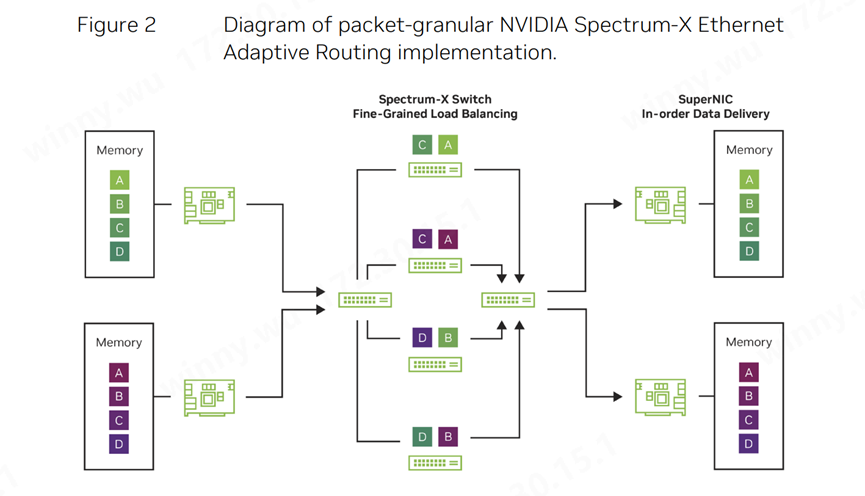
图2:NVIDIA:Spectrum-X以太网自适应路由的细粒度数据包示意图
因此,NVIDIA引入自适应路由算法来动态平衡网络中的数据传输。此外,路由的精细度也至关重要,以避免大象流之间的碰撞。即使按流量进行路由,仍然存在拥塞的可能性。然而,当采用数据包喷洒(Packet Spraying)技术,即按每个数据包进行路由时,数据包可能会以无序的方式到达目的地。为了实现数据包粒度的自适应路由,我们需要建立灵活的重新排序机制,确保自适应路由对应用程序来说是透明的。
挑战与方案2:拥塞控制
在繁忙的多租户AI云环境中,不同AI作业并行运行时,网络拥塞问题往往难以避免。尤其是当大量发送方试图向单一目的地或不同目的地(这些目的地可能已受到其它应用背景流量的影响)传输数据时,网络拥塞现象尤为显著。这种拥塞不仅会导致延迟飙升和有效带宽急剧缩减,还可能引发网络“热点”的扩散,造成相邻租户的相互干扰,即受害者效应。
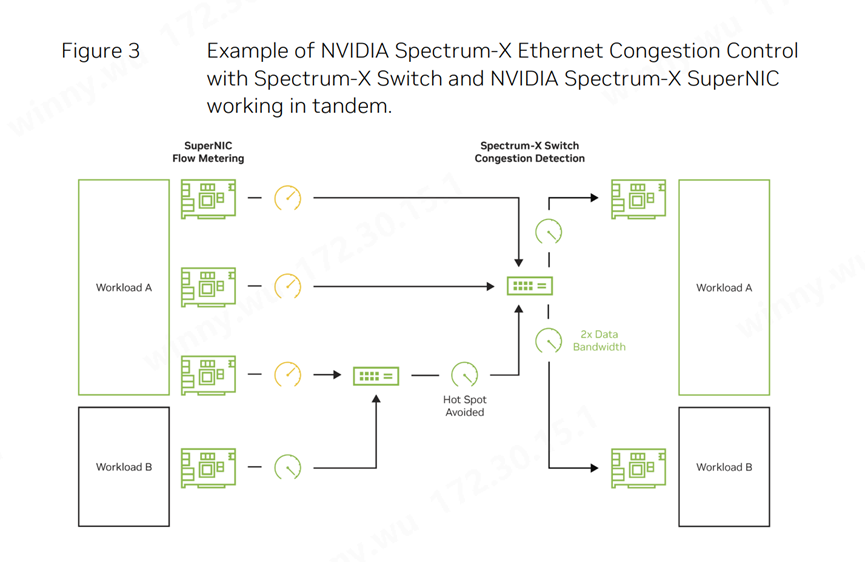
图3:NVIDIA:Spectrum-X以太网拥塞控制与交换机和NVIDIA BlueField SuperNIC协同工作
传统的拥塞控制方法,如显式拥塞通知(ECN,Explicit Congestion Notification),在支持生成式AI的以太网环境中显得捉襟见肘。为了有效缓解拥塞,负责数据传输的网络设备(如NIC或DPU)必须进行精确的流量控制。然而,ECN机制在交换机缓冲区接近满载时才开始发挥作用,此时接收方会通知发送方限制其发送速率。但在大规模AI模型常见的突发流量场景下,这种延迟的拥塞反馈可能导致缓冲区迅速填满,进而引发丢包问题。尽管深度缓冲交换机能够降低缓冲区溢出的风险,但它们引入的额外延迟却削弱了拥塞控制的初衷。
实现高效的拥塞控制需要交换机与网卡NIC之间的紧密协作。NVIDIA Spectrum-X通过利用Spectrum-4交换机的带内、硬件加速的遥测数据,为BlueField-3 SuperNIC提供实时的流量计量信息。
挑战与方案3:性能隔离与安全性多租户环境如AI云,必须确保各个作业之间的性能隔离,以免受到其它作业的网络流量干扰。遗憾的是,许多以太网ASIC设计在性能隔离方面考虑不足。这导致某些作业在面临“近邻干扰”(noisy neighbor)(即向同一端口发送流量的相邻作业)时,其有效带宽可能会急剧下降。 以太网网络在设计时还需考虑网络公平性。AI云应支持多种异构应用程序的混合运行。由于不同应用程序可能使用不同大小的数据帧,如果没有适当的隔离优化措施,大数据帧可能会占用过多的带宽资源,导致小数据帧传输受阻。
实现性能隔离和防止“近邻干扰”的关键在于采用共享数据包缓冲区。通过为所有作业提供平等的缓存访问权限,共享缓冲区能够确保混合AI云工作负载的稳定性和低延迟。
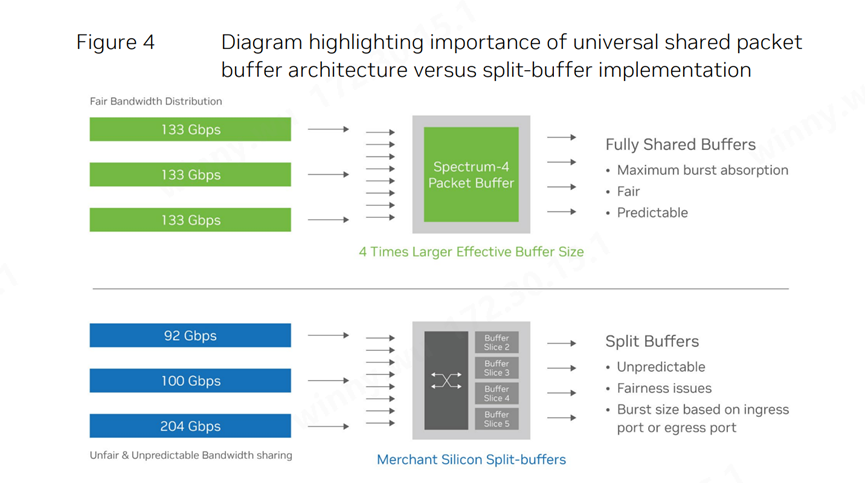
图4:强调通用共享数据包缓冲区架构与分割缓冲区实现之间重要性
除了从带宽角度考虑性能隔离外,我们还应认识到性能隔离与零信任架构对于多租户环境网络安全的重要性。数据无论是在静止状态还是传输过程中,都需要得到严格的保护。高效的加密和认证工具能够在不牺牲性能的前提下提供强大的安全保障。BlueField-3 DPU集成了安全引导功能,为基于硬件的信任根提供了坚实基础,并支持MACsec和IPsec等协议用于数据加密,以及AES-XTS 256/512等加密算法用于静态数据的保护。
以上是英伟达对基于以太网Spectrum-X解决方案的部分优势特性总结;
UEC 超以太联盟对标 NVIDIA Spectrum
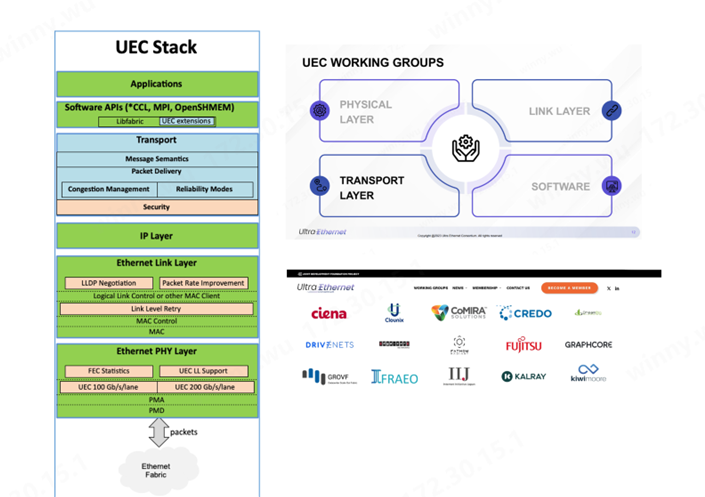
我们已经了解UEC是专门为AI网络Scale -out互联成立的国际联盟,目的是全面优化RDMA的功能,从而实现更大规模的AI网络集群的高效运作。
UEC 主要在Transport Layer传输层做了全面的优化,不限于消息语义优化、数据包传输、拥塞控制及可靠性安全性等目前大规模集群扩展需要优化的功能。
UEC支持自适应路由及数据包喷洒
超以太联盟下一代的Modernized RDMA将支持多路径传输的数据包喷洒技术,从而优化自适应路由。UEC支持了RUD,UET就可以将同一个流的不同包分散到多个路径上同时传输,实现包喷洒功能。这让交换机可以充分发挥ECMP甚至WCMP(Weighted Cost Multi- Pathing)路由能力,将去往同一目的地的数据包通过多条路径发送,大幅度提高网络利用率。
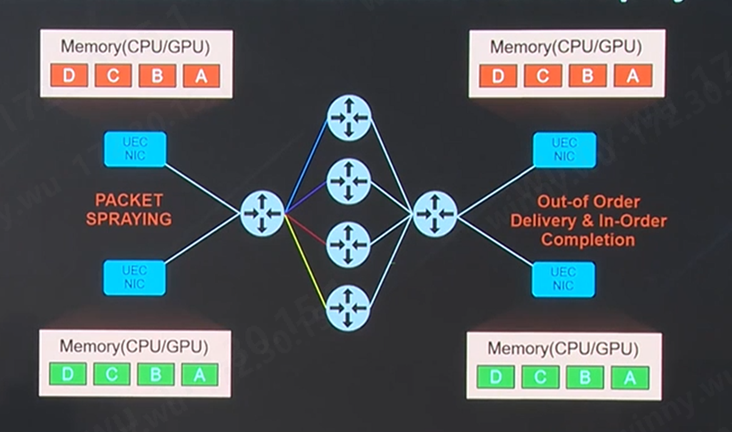
(来源:AMD)
UEC将支持端到端遥测Telemetry
新的UEC对于拥塞做出了优化机制:来自网络的拥塞信息可以向参与者提供拥塞的位置和原因。缩短拥塞信号路径并向端点提供更多信息,能够实现更快速的拥塞控制。无论是发送方还是接收方安排传输,现代交换机都可以通过快速传递准确的拥塞信息给调度器或起搏器pacer,促进响应式的拥塞控制,从而提高拥塞控制算法的响应速度和准确性。结果是减少了拥塞、降低了丢包率和缩短了队列长度——所有这些为改善尾部延迟提供了服务。
UEC支持安全性与加密
UEC传输协议从设计之初就融入了网络安全概念,能够加密并验证AI训练或推理作业中计算端点间发送的所有网络流量。UEC传输协议借鉴了现代加密方法(如IPSec和PSP)中用于高效会话管理、认证和保密的核心技术。随着作业规模的扩大,必须在不使主机和网络接口的会话状态急剧膨胀的前提下支持加密。为此,UET(UEC传输)引入了新的密钥管理机制,允许成千上万个参与同一作业的计算节点之间高效共享密钥。它被设计成能在AI训练和推理所要求的高速和大规模下高效实现。托管在大型以太网网络上的高性能计算(HPC)作业具有类似的特征,同样需要相当的安全机制。这意味着UEC传输不仅能满足AI领域的需求,也能适应HPC环境中对于安全性和性能的严格要求,确保数据在大规模网络中的传输既高效又安全。

UEC成员Arista公司表示,“当PCI总线因主机CPU上的竞争工作负载或降速等原因出现拥塞时,通常需要使用ECN(显式拥塞通知)标记。Arista在实现ECN标记方面经验丰富,可以对经过拥塞队列的数据包进行标记。此外,该公司还支持即将推出的多种网络内遥测(In-Network Telemetry)技术,它们能提供更细粒度的网络拥塞队列深度信息,从而全面支持网络内遥测。这项新技术预计将与超以太网的网卡和未来的RDMA一起发挥更大作用。”
-
英伟达GPU惨遭专业矿机碾压,黄仁勋宣布砍掉加密货币业务!2018-08-24 4330
-
AMD正收购Xilinx,规模或超300亿美元2020-10-10 2472
-
英伟达DPU的过“芯”之处2022-03-29 5998
-
英伟达发布Q2财报,实现营收31.2亿美元2018-08-19 3931
-
游戏和数据中心芯片推动英伟达Q3收入30.1亿美元2019-11-15 4558
-
英伟达将以400亿美元收购Arm2020-09-14 3568
-
英伟达将从软银手中收购ARM_交易价值400亿美元2020-09-16 2658
-
英伟达发布第三季度财报:收入创下47.3亿美元纪录2020-12-20 2303
-
英伟达市值蒸发310亿美元 英伟达收跌约2.7%2023-12-05 2343
-
印度厂商Yotta采购10亿美元英伟达AI芯片2024-01-12 1648
-
英伟达市值蒸发近2000亿美元2024-08-30 1303
-
英伟达2026财年Q1营收公布 一季度营收441亿美元 英伟达Q1净利润187.8亿美元2025-05-29 1663
-
NVIDIA新闻:英伟达10亿美元入股诺基亚 英伟达推出全新量子设备2025-10-29 2779
-
英伟达Spectrum-X硅光技术全面量产2026-06-03 1811
-
英伟达Spectrum-X以太网硅光技术全面量产2026-06-04 1441
全部0条评论

快来发表一下你的评论吧 !
