

飞龙入海:ANSYS官方的大模型应用
描述
写在前面的话
大模型差不多是一项发明,其重要性不亚于电的发现和电灯的发明。
大模型的基础是使用Transformer算法识别了人类语言(大致等同于人类的思维逻辑)的内在关系和特征,学习了海量知识的内在关联规律,并以人们需要的形式进行输出。
大模型在通用代码编制方面已经展现了强大的能力,那么对于细分行业的代码编程是否具有辅助价值?
ANSYS官方发表了以下这篇大模型辅助Redhawk MapReduce建模的方法。
大模型与工程仿真代码
大型语言模型 (LLM) 在自然语言处理 (NLP) 的发展中发挥着重要作用,在各种应用中展示了非凡的多功能性,包括特定领域的问答和代码生成 。显着的进步导致了最先进的模型,如 GPT-4 、Claude 和 Mistral,后者集成了 “Mixture-Experts” (MoE)。
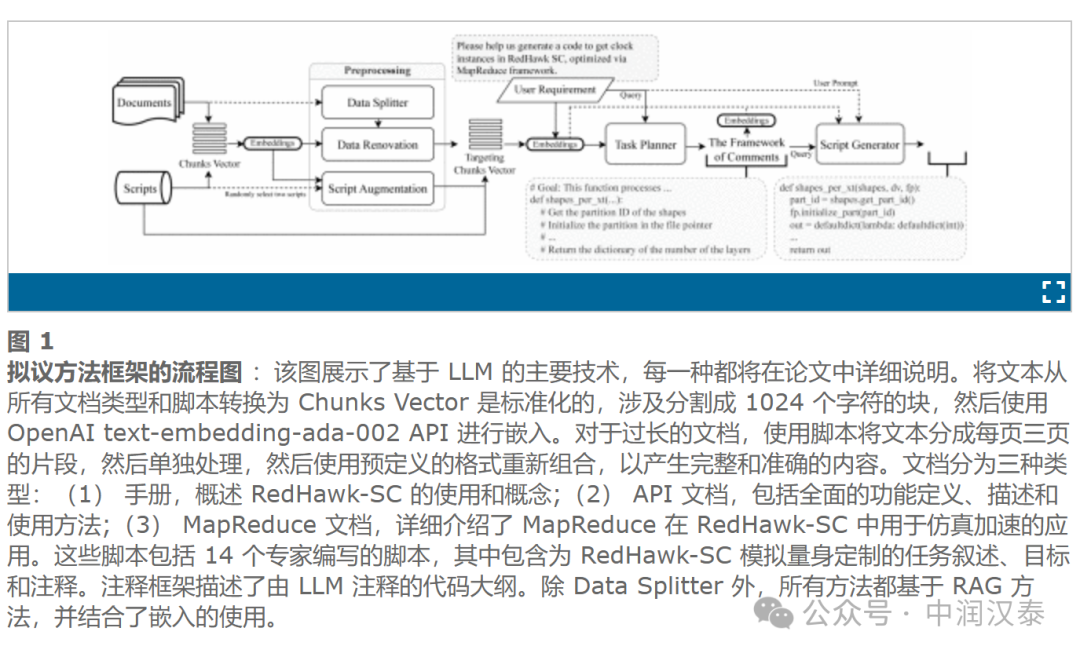
检索增强生成 (RAG) 框架被广泛用于通过从外部数据库中检索事实内容来增强专业领域的 LLM,从而减轻幻觉并提高性能。这种方法涉及将数据解析为字符有限的重叠片段,并将它们转换为基于向量的检索的嵌入,从而赋予 LLM 精确的特定领域知识。
代码生成是 LLM 的一个关键应用,但它在特定领域的工程任务中提出了各种挑战,例如在 Ansys RedHawk-SC (RH-SC) 平台上的任务。在这里,由于任务的复杂性和缺乏编码专业知识,用户经常难以创建 MapReduce (注)Python 脚本。通过自然语言指令自动生成此脚本可以显著提高工作效率并增强用户体验。
MapReducePython 代码不仅需要对 RH-SC 架构有深入的了解,还需要复杂电路设计方面的专业知识。缺乏全面的技术文档和稀缺的电子设计自动化 (EDA) 在线资源使 LLM 难以获得必要的领域知识。
虽然 ChatEDA 试图通过微调 Llama2和在开源 EDA 工具上实现自规划代码生成来解决这些问题,但这种方法成本高昂。其他方法,如 TestPilot和 Veri-Gen已经显示出在我们的专业上下文中生成代码的局限性。
为了克服这些挑战,ANSYS提出了基于 RAG 的新方法,而无需对 LLM 进行任何形式的预训练或微调。其中的Data Splitter 和 Data Renovation 技术改进了语义文本分割并丰富了段落内容,从而避免了直接文档提取的典型混乱。这些方法显著提高了 RAG 的嵌入准确性,从而更有效地检索信息,从而提高了超越传统字符计数分割技术的整体性能。同时引入一种新颖的提示技术 Implicit Knowledge Expansion and Contemplation (IKEC),将 IKEC 与思维链 (CoT) 方法相结合,以探索潜在的性能改进。
通过实现这些数据预处理和自规划代码生成提示策略,可以生成符合用户需求的脚本。经过 180 多位ANSYS专家的投票,结果证实了Splitter 和 Renovation 方法显著提高了代码生成的质量。
框架
Splitter
RAG 方法的有效性取决于文本的相关性,由嵌入计算确定。传统的 RAG 技术通常按字符数对文本进行分段,可能会产生缺乏主题焦点的块。因此,这些块生成的嵌入不能充分表示目标主题,从而降低了检索高质量文本内容的可能性。
Data Splitter 通过对文本进行语义分割来解决此问题,专注于有意义的单元,例如 API 函数和概念,同时保留原始文本格式并纠正格式问题。我们将文本分割成固定的页面单位,让 LLM 确定段落的完整性。不完整的句段将保持未闭合状态,从而促进无缝后处理以组合完整的段落。
如下图所示,数据拆分器将提取的文档内容精确划分为不同的、集中的片段,从而有效地解决可能出现的格式问题。确定在何处拆分文本的任务类似于“二元分类问题”,这对于 LLM 来说相对简单。因此,使用 LLM 来完成这项任务,在这种情况下放弃使用 RAG 技术。

Data Renovation
Data Renovation 解决了技术文档通常简洁性所带来的挑战。它使 LLM 能够有条不紊地用易于理解的知识丰富每个段落,从而增强嵌入——即使 LLM 已经熟悉这些知识。我们利用 LlamaIndex 提供的 RAG 框架为原始文档和脚本提供深深植根于源材料上下文的补充内容,从而确保信息的可靠性。
Data Splitter 处理的每个段落随后按顺序更新。从图中值得注意的是,翻新一丝不苟地纳入了内容中提到的关键术语的额外细节。
Script Augmentation
获取带有详细注释的脚本通常是一项具有挑战性的工作。在只有有限数量的此类脚本可用的情况下,如果我们提示 LLM 基于参考脚本生成“全新”脚本,由于 LLM 的专业知识有限,结果通常是混乱的输出。如图 2 所示,随机选择了两个脚本,并采用 RAG 框架来鼓励在创建具有明确、特定于任务目的的新脚本时进行 “重大结构更改”(重建)。此方法可确保生成的脚本具有令人满意的质量。通过重复生成结构多样的脚本,可以丰富脚本增强的参考资料库。
隐性知识扩展与沉思 (IKEC)
IKEC技术是我们在工作中开发的一种新颖方法,旨在促使LLM利用自己的知识库在内部扩展和丰富它最有信心的内容。这个过程涉及 LLM 在得出最终结果之前进行深思熟虑和深入的思考。此外,我们还尝试将这项技术与 CoT 流程集成,这是出于对哪些内部提示可能有助于 LLM 性能的好奇心。
结论
本文介绍了在特定领域问题中提高 LLM 的 RAG 性能的四个显着贡献:数据拆分、数据更新、脚本增强和 IKEC。通过对文本进行语义分割和以高 LLM 置信度更新内容,这些技术有助于在 RAG 的数据检索过程中改进以主题为中心的嵌入。Data Splitter 和 Data Renovation 技术在数据源级别增强嵌入的新应用特别具有创新性。
这些贡献的有效性已通过涉及ANSYS 28 名领域专家的小组和 182 票分析的全面评估得到验证。结果表明,Data Splitter 和 Data Renovation 方法显著提高了专业领域内 MapReduce 应用程序中 RHSC 的代码生成质量。具体来说,归因于这些方法的改进可量化地大于 CoT,数据拆分器方法的改进是 CoT 提示的 1.43 倍,数据翻新方法的改进是 CoT 的 0.45 倍。
注:MapReduce 是一种编程模型和关联的实现,用于处理和生成适用于各种实际任务的大型数据集。用户根据 map 和 reduce 函数指定计算,底层运行时系统会自动在大规模机器集群之间并行计算,处理机器故障,并安排机器间通信以有效利用网络和磁盘。
-
使用ADI官方的Spice模型进行仿真时,如何对模型的引脚名称和原理图符号进行编辑?2023-11-14 1036
-
仿脑科技飞龙芯超越了现时主流的框架和思路2023-08-30 2219
-
Ansys云端平台实现通过AWS轻松访问和部署Ansys仿真2022-11-15 2949
-
Ansys HFSS 导体计算2022-01-06 26565
-
如何理解ANSYS软件 ANSYS软件对电脑配置的要求高吗2021-08-03 20250
-
什么是ANSYS 17.0?2019-08-26 4267
-
采用ANSYS HFSS软件实现WiFi天线设计2019-07-04 4543
-
Ansys HFSS和EMPro的兼容性?2019-03-21 2702
-
ansys2017-12-08 1943
-
ansys仿真教程2017-11-21 5694
-
基于ANSYS有限元的磁阀式可控电抗器的磁路模型研究_章宝歌2017-01-08 748
-
ANSYS基础应用2011-05-11 994
-
ANSYS中X对象的名称--ANSYS使用简介2009-06-18 1319
-
轿车参数化分析模型的构造研究及应用2009-04-16 3136
全部0条评论

快来发表一下你的评论吧 !
