

浪潮信息发布“源”Yuan-EB助力RAG检索精度新高
描述
近日,浪潮信息发布 “源”Yuan-EB(Yuan-embedding-1.0,嵌入模型),在C-MTEB榜单中斩获检索任务第一名,以78.41的平均精度刷新大模型RAG检索最高成绩,将基于元脑企智EPAI为构建企业知识库提供更高效、精准的知识向量化能力支撑,助力用户使用领先的RAG技术加速企业知识资产的价值释放。
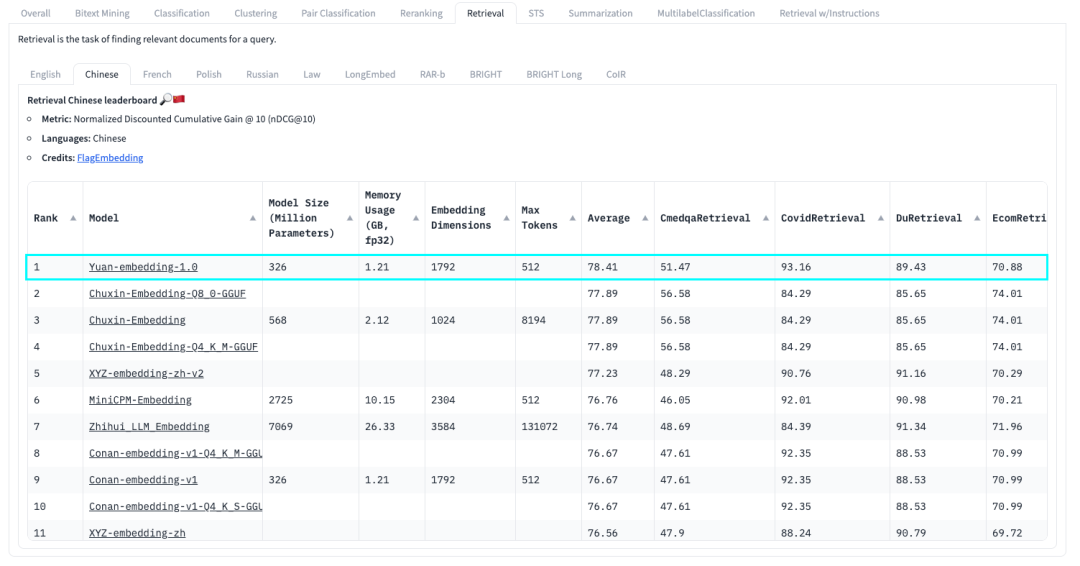
“源”Yuan-EB 在HuggingFace的C-MTEB榜单中排名第一
Yuan-EB(版本号Yuan-embedding-1.0) 是专为增强中文文本检索能力而设计的嵌入模型(也称Embedding模型),在 “源2.0” 大模型的工作基础上,创新性地采用了“源2.0-M32”大模型进行数据重写与合成,并通过索引技术、样本排序等系列方法完成高质量微调数据集构建,能够有效提升RAG系统的检索精度。
C-MTEB是目前业内最权威的嵌入模型测试榜单。其中,检索任务(Retrieval)是检索增强生成(RAG)场景下最为重要、应用最广泛的任务能力,考察的是Embedding模型从大量的数据集中找到并返回与给定查询最相关或最匹配的信息的过程。“源”Yuan-EB基于该任务提供的医疗、新闻、电商、娱乐等8个中文文本数据集,实现了业界领先的海量文本检索精度。
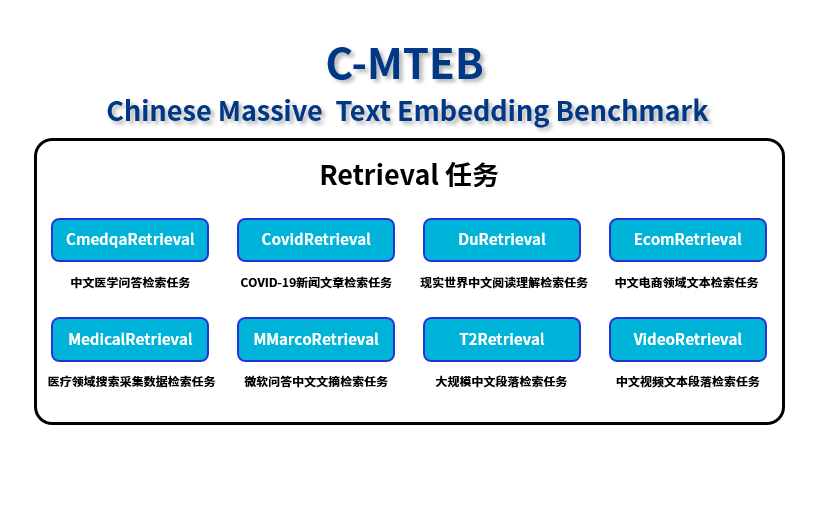
C-MTEB榜单Retrieval任务提供8个测试数据集
“源” Yuan-EB 助力RAG检索精度新高
嵌入模型在RAG流程中扮演着关键角色,它能够将复杂的高维数据(例如文本、图像或音频)转换为机器可理解的向量形式,直接决定了RAG检索的精准性和效率。
“源”Yuan-EB通过数据准备与模型微调两个方面的技术创新,实现了模型精度的大幅提升:
■ 在数据方面,基于“源2.0”微调阶段的问答数据进行清洗与筛选,构建问题(query)与文本(corpus)数据集;使用“源2.0-M32”对C-MTEB 训练数据进行重写与合成,通过索引技术与排序模型进行高效的难负样本提取,完成大规模难负例样本挖掘,形成高质量微调数据集;
■ 在微调方面,通过两个阶段的领先微调方法实现模型能力提升。第一阶段,使用各个领域(医疗、新闻、长文本、娱乐等方向)的大规模数据进行对比学习训练;第二阶段,采用“源2.0-M32”生成的合成数据进一步微调,并使用MRL方法完成“源”Yuan-EB训练;
“源”Yuan-EB为用户提供了大模型企业知识库应用开发的最优模型选择,能够在 RAG流程的多个方面起到显著的精度提升,包括信息检索的准确性、处理大规模数据的效率、消除语义歧义、降低计算成本、增强对长文档的处理能力以及模型鲁棒性等,最大化提升RAG流程的整体性能和应用效果。
元脑企智EPAI集成“源”Yuan-EB,加速知识库构建与性能提升
目前,“源”Yuan-EB已经在开源社区和企业大模型开发平台元脑企智EPAI中全面开放下载。用户可以在元脑企智EPAI平台中快速使用“源”Yuan-EB,并结合EPAI自研的多阶段RAG技术,零代码、低成本地基于企业数据构建大模型知识库应用。
企业大模型开发平台“元脑企智”EPAI(Enterprise Platform of AI),是浪潮信息为企业AI大模型落地应用打造的高效、易用、安全的端到端开发平台,提供数据准备、模型训练、知识检索、应用框架等系列工具,支持调度多元算力和多模算法,帮助企业高效开发部署生成式AI应用、打造智能生产力。
元脑企智EPAI已经支持超过13种类型文档的信息识别与提取,结合创新的多级混合检索策略,有效提升元脑企智EPAI在管理、解析、检索知识库与生成内容方面的最终效果,帮助企业用户实现基于私有数据、行业数据下的精准检索、精准问答,确保专业场景下大模型生成内容的准确性和可靠性,加速大模型创新力释放。
-
RAG(检索增强生成)原理与实践2026-02-11 11030
-
浪潮信息与智源研究院携手共建大模型多元算力生态2024-12-31 1230
-
浪潮信息与智源研究院达成战略合作协议2024-12-26 1178
-
浪潮信息发布"源"Yuan-EB,刷新RAG检索最高成绩2024-12-25 1116
-
借助浪潮信息元脑企智EPAI高效创建大模型RAG2024-12-19 1481
-
浪潮信息源2.0大模型与百度PaddleNLP全面适配2024-10-17 1460
-
浪潮信息:元脑企智EPAI助力金融大模型快速落地2024-09-20 1166
-
浪潮信息重磅发布“源2.0-M32”开源大模型2024-06-05 1537
-
浪潮信息发布“源2.0-M32”开源大模型2024-05-29 1376
-
浪潮信息发布企业大模型开发平台“元脑企智”EPAI2024-04-18 1289
-
浪潮信息与英特尔合作推出一种大模型效率工具“YuanChat”2024-03-27 1664
-
仪电云云操作系统获得浪潮信息澎湃技术认证2023-12-27 1489
-
浪潮信息发布源2.0基础大模型,千亿参数全面开源2023-11-28 1536
-
NVIDIA携手浪潮信息助力虚拟人创作便捷化2022-07-27 2972
全部0条评论

快来发表一下你的评论吧 !
