

一文了解AI网络互联的市场潜力
描述
AI网络多层次的互联彰显市场潜力
NVIDIA作为全球领先的视觉计算和人工智能公司,其市值突破万亿元的背后,除了强大的GPU产品线,互联技术扮演了不可或缺的支柱角色。NVIDIA于2019年收购以色列公司Mellanox,自此成就了它的暴力美学。通过高性能的单个GPU加速卡,NVLink及NVSwitch打造Scale-up护城河,同时还配备用于后端网络Scale-out的ConnectX系列智能网卡等全栈AI网络互联产品线打造AI工厂。据悉,2023年NVIDIA 在Networking领域的销售额为130亿美金。
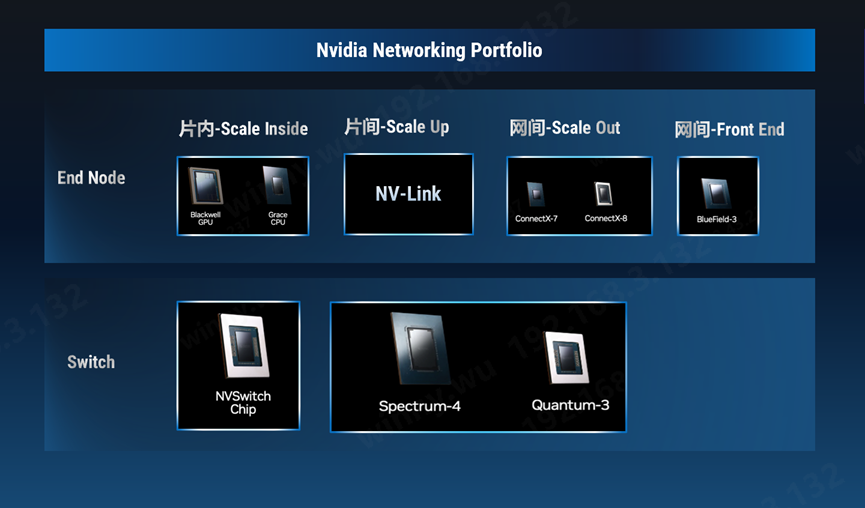
(来源:整理自NVIDIA)
01
网间互联:
高速以太网的新纪元
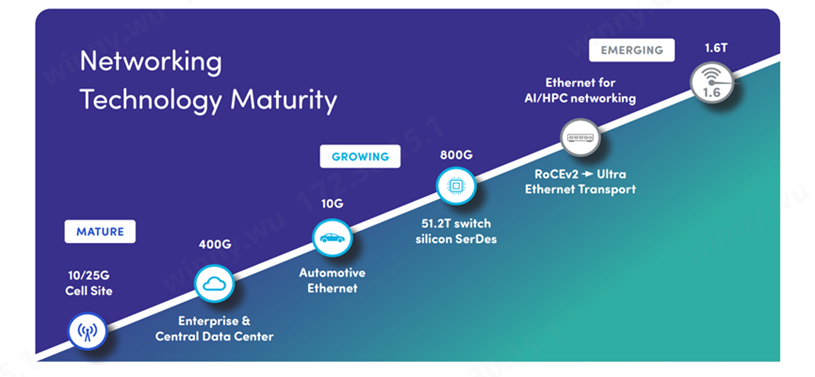
根据Spirent HSE Market Impact Report的高速以太网市场动态更新,随着端口速度持续演进,各速度级别的采纳率都保持强劲,即便是10G和25G在中小企业和5G基站部署中仍享有稳定的需求。超越传统需求曲线,基于51.2T的交换机Serdes以及AI网络Scale-out从RDMA RoCE2向UEC(超以太联盟)规范演进的趋势已经明朗。目前市场已经开始展望1.6T以太网,以期在明年迅速把握AI驱动的市场机遇。
1.6T以太网
数据中心流量的预期指数级增长正在推动1.6T以太网的研究。尽管IEEE 802.3dj标准预计在2026年内完成,但2024年已经明确的基础功能将支持硅芯片、光学元件和光模块的早期开发。
面向AI和HPC的以太网
随着AI和高性能计算(HPC)的需求日益增长,基于融合以太网的远程直接内存访问RDMA(RoCEv2),预计将演进至新的超以太网传输(UET)标准(隶属于UEC)。
800G
最初的部署将由全球主要云厂商企业引领,以支持数据中心内的AI应用,并伴随着51.2Tbps交换机的应用。800G提供了更高的带宽、更低的延迟、提升的能效以及更多的连接,为数据中心的互联提供了未来几年的保障。
以太网逐步替代Infiniband
Scale-out 层面,用于AI训练的高速网络InfiniBand的远程直接内存访问(RDMA)被普遍应用,但现在越来越多的关注点转向了将开放标准、广泛采用的以太网用于这一用途。与InfiniBand相比,以太网降低了成本和复杂性,并且没有可扩展性的限制。
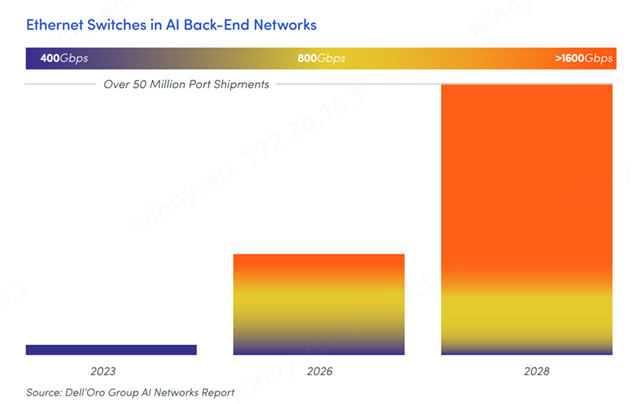
智能网卡和以太网交换机的前景可期
Dell’Oro预测,到2028年,部署在AI后端网络中的以太网交换机端口出货量将超过5000万台。到2025年,AI后端网络中的以太网交换机端口出货量有一半将是800Gb/s,到2028年将达到1600Gb/s。 其Ethernet Adapter and Smart NIC 5-Year July 2024 Forecast Report报告称:预计以太网智能网卡市场到 2028 年将超过 160 亿美元,大幅提高的市场展望主要源于支持AI服务器集群Scale-out的后端网络对以太网连接有强烈需求。 Dell'Oro集团高级研究总监 Baron Fung 表示:“AGI应用的出现推动了将加速服务器与后端以太网网络相互连接的需求,这对于大型语言模型的训练来讲是必然的一步。对于以太网网卡来说,这是一个新的市场机会,与传统的前端以太网适配器市场相比,增长显著更高。” 到 2028 年,整个以太网智能 NIC 市场(包括前端和后端网络的服务器连接)预计将以 27% 的复合年增长率增长。后端网络的服务器访问速度将至少比前端网络领先一代,以跟上 GPU 加速器密集路线图的发布步伐。
智能网卡Chiplet芯粒化提上日程
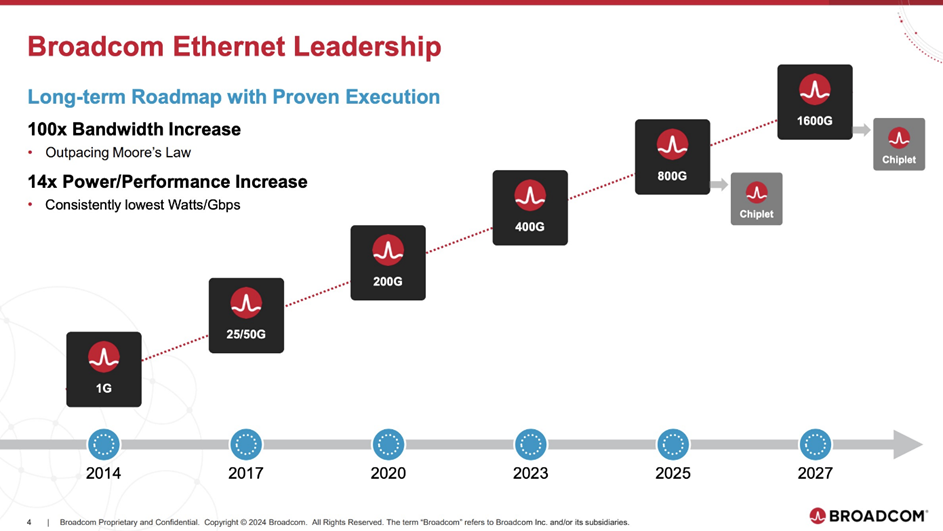
(来源:Broadcom)
“
Broadcom在今年上半年推出了面向AI网络的400G智能网卡,并公布了基于以太网的SmartNIC Roadmap。随着800G的步伐进一步加快,Broadcom预计将在2025-2026年间推出下一代带宽为800G,基于Chiplet架构的网卡芯片。采用Chiplet技术的超高带宽智能网卡,正成为推动下一代网卡技术发展的新动力。这正与奇异摩尔在网间互联侧的产品路线理念不谋而和。下一代产品将全面支持超级以太网联盟(UEC)的NIC标准。
02
片间互联:加速卡需求旺盛,
国产GPU潜力突围
全球GPU加速卡需求剧增
大模型的规模扩大需要大量的训练基础设施,并显著推动数据中心 AI 芯片市场。未来更多十万卡加速器集群会进入我们的眼帘。例如,xAI 最近建立了一个拥有 100,000 个NVIDIA H100 的液冷数据中心,而 Meta 报告称它购买了 500,000 个 GPU,其数量翻了一番,达到 100 万个。
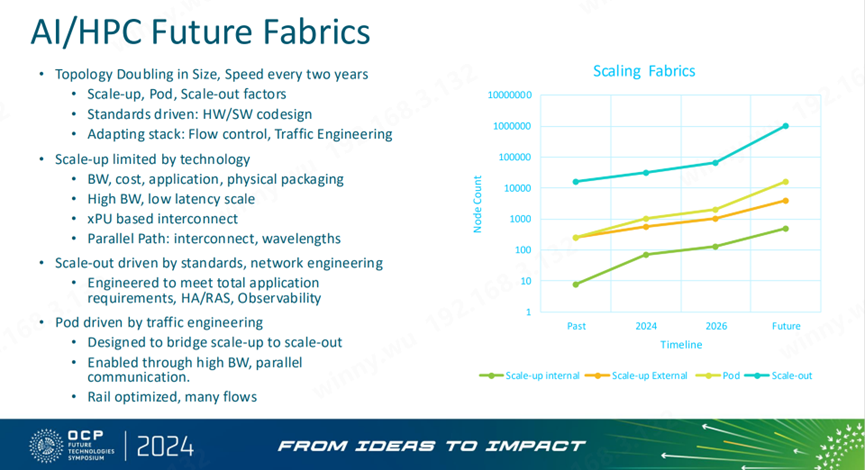
(来源:OCP Global Summit 2024)
“
Scale-up网络演进趋势已经超出单个服务器机架范围;在今年的OCP Summit上又出现了新定义(如上图):Scale-up Internal和Scale-up External 两个部分共同构成Scale-up网络。Internal部分具体指的以单个机架为节点的GPU数量,从过去传统的8卡到百卡甚至几百卡演进(小于1000 卡);External部分是以突破单个服务器机架为节点,也就是超节点所构建的超带宽域的Node数量,节点间加速卡数量预计2026年后将突破1000卡。
(更多阅读:Kiwi Talks | Scale-up 军备赛愈演愈烈,集体对抗英伟达的暴力美学)
根据Tech Insight机构公布的报告表示数据中心 AI 芯片/加速器市场继续主导全球半导体市场。该市场将以 37% 的复合年增长率增长,到 2029 年将达到 3550 亿美元。其中生成式 AI 应用是芯片的最大驱动力,到 2029 年预计有望达到 2500 亿美元。GPU 在整个细分市场中占据主导地位,到 2023 年的总收入将达到 370 亿美元,该机构预计这一趋势不会放缓。然而在过去五年中,我们看到 AI 加速器的平均售价 (ASP) 增长了四倍。目前正上市的 NVIDIA 的 H100 在零售市场上的价格可能高达 40,000 美元,而两代前的 V100 价格为 10,000 美元。这样的价格上涨在半导体市场上是闻所未闻的。随着越来越多的 AI 应用程序进入生产状态,机构预计重点将转移到定价而不是性能上。长期来看,这种溢价和垄断的市场发展态势需要被打破。
国产GPU市场份额逐步提升
国际数据公司(IDC)发布了最新的《中国半年度加速计算市场(2024上半年)跟踪》报告。IDC数据显示,2024上半年中国加速服务器市场规模达到50亿美元,同比2023上半年增长63%。其中GPU服务器依然占主导地位,达到43亿美元。同时NPU、ASIC 和 FPGA等非GPU加速服务器以同比182%的增速达到近7亿美元市场规模。
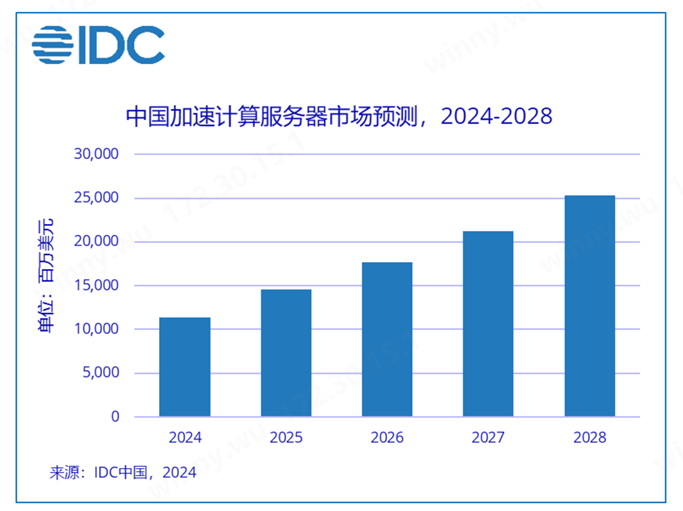
行业大模型的深入研发对于AI软硬件与生态部署有着明显带动作用。人工智能在诸如智慧城市、智能家居等综合复杂性场景,在金融、医疗、教育等行业的细分功能层面提供更细化更多元的方案。
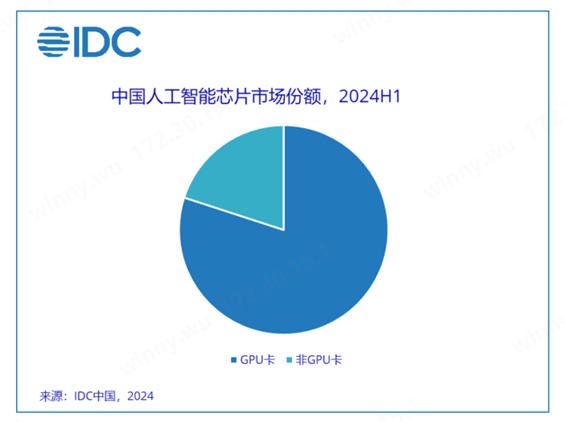
2024上半年,中国加速芯片的市场规模达超过90万张。从技术角度来看,GPU卡占据80%的市场份额;从品牌角度来看,中国本土人工智能芯片品牌的出货量已接近20万张,约占整个市场份额的20%。用于推理的人工智能芯片占据了61%的市场份额。在GPU加速卡入口受限之后,由于数质化转型大趋势对于算力的持续需求,中国本土品牌加速卡的市场份额逐步增长。
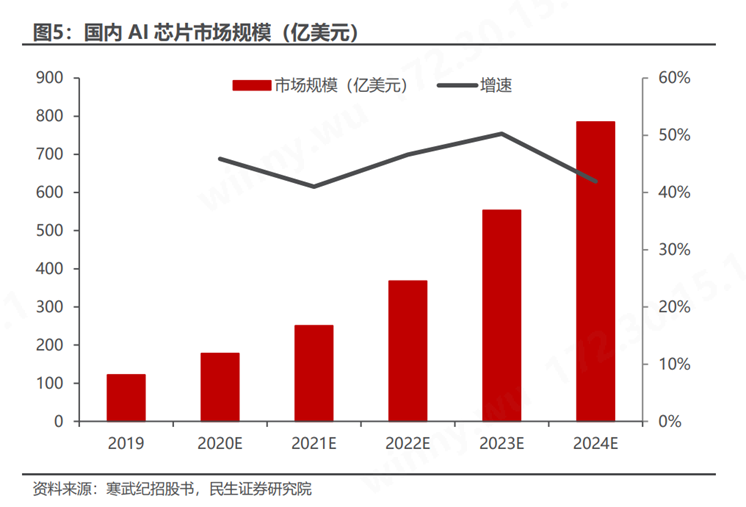
随着大数据的发展和计算能力的提升,根据寒武纪招股书,2022 年中国AI芯片市场规模预计达 368亿元,预计 2024 年市场规模将达到 785 亿元,复合增速有望达到 46%。 宏观来看,随着全球科技竞争的加剧,构建自主可控的国产万卡甚至十万卡的集群系统,不仅关乎技术主权,更是推动AI产业持续健康发展的关键,其中生态的构建尤为复杂且至关重要。今年三月,中国工程院院士郑纬民指出,尽管国产AI芯片与业界领先水平仍存在差距,但生态的完善能够有效弥补这一短板,确保大多数任务不会因芯片性能的微小差异而受显著影响。
03
片内互联:Chiplet在服务器
的应用迎来黄金期
为了提升单芯片算力,过往业内方案集中在增加单⼀芯片上的晶体管数量和扩大芯片⾯积。但随着先进制程发展接近物理极限,单芯片面积触及机台设计上限,性能持续发展受限。且传统冯诺依曼计算架构下芯片算力同时受存储墙、I/O墙制约,芯片算力利⽤率低。因此Chiplet芯粒化是后摩尔时代提升性能的共识。 Chiplet技术可以将不同类型的AI加速卡(如神经网络处理器、张量处理器、视觉处理器等)通过高速、低功耗的互联方式进行集成,实现高效的AI计算。这种模块化设计不仅提高了AI芯片的性能,还优化了功耗效率。 在智能计算集群的效能核心,GPU单卡的计算能力构成了集群整体算力的基石。Chiplet技术作为提升单个AI加速卡的快速更新和升级,具有关键意义,从而跟上不断发展的人工智能算法和应用需求。
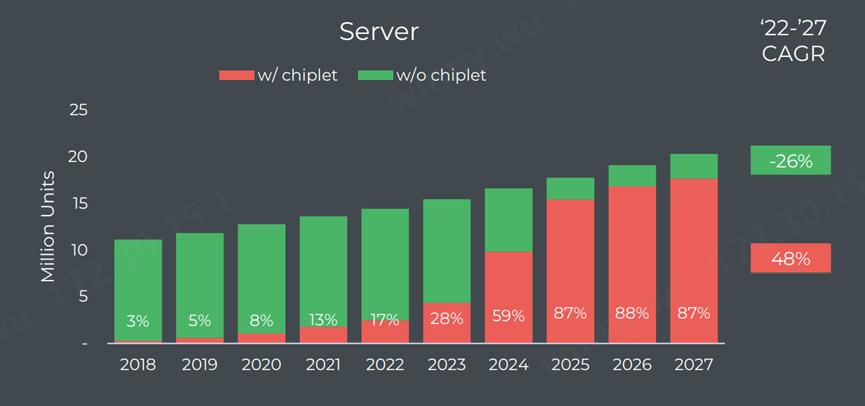
(来源:Yole Market Update 2023)
“
根据国际知名机构Yole发布的Chiplet Market Update 2023,预计到2025年,集成Chiplet的芯片在数据中心服务器市场比例预计可以达到87%,这一比例在2021年仅为13%。这意味着未来AI大算力芯片的芯粒化将是一个势不可挡的主流趋势。
单个芯片的算力和性能高度依赖于Chiplet的设计以及先进封装工艺,这些因素共同推动了单个加速卡算力的提升。自成立以来,奇异摩尔始终专注于Chiplet技术与互联技术的研发,凭借深厚的Chiplet设计功底和量产经验,以及全面的片内互联(Scale Inside)产品线——包括UCIe D2D IP接口和IO Die互联芯粒,全力助推国产大算力芯片性能的不断提升。
据Yole预测,到2027年,基于Chiplet芯粒的处理器市场将超过1350亿美元。到2032年,预计芯粒的采用将在消费和汽车市场全面加速,并在国防、航空航天、工业和医疗领域站稳脚跟。
AI基础设施的转型正在引领我们进入一个全新的技术时代,其中极致的互联技术创新不仅是推动产业发展的关键,更是决定未来AI网络竞争力的核心因素。从片内互联、片间互联再到网间互联,成就多层次的高性能互联正是奇异摩尔所持续专注的。随着Scaling Law的延续,这场技术革命的新蓝图依赖于产业链的每一份子去谱写、去绘制。
-
潜力巨大 中国市场不容忽视2011-07-16 3238
-
智慧医疗的市场潜力巨大也存在诸多问题2016-06-30 3803
-
15分钟充满快充移动电源---未来的潜力有多大?2017-06-16 3549
-
带你宏观了解一下FPGA的市场,潜力?!2018-02-08 5937
-
智能音箱市场潜力巨大 谷歌、亚马逊各自为王2018-07-06 2696
-
射频开展优势明显 前端市场潜力巨大2019-12-20 4015
-
新能源车、光伏、风电驱动,薄膜电容市场潜力巨大2022-12-08 24553
-
车用锂电池市场潜力大2009-11-16 502
-
3G 商务手机市场潜力巨大 飞利浦 D908 引领新体验2010-02-08 738
-
黄学杰 :锂离子电池市场潜力巨大2010-02-11 641
-
浅谈LED室内照明市场潜力2010-04-19 1065
-
物联网市场潜力无限,却为何遭遇尴尬?2013-02-17 1097
-
图谋VR市场潜力 英伟达如何布置VR市场战略2017-01-05 696
-
线性马达带你了解国内电动牙刷的市场潜力2023-08-17 1255
-
氮化镓(GaN)技术的迅猛发展与市场潜力2024-07-24 1964
全部0条评论

快来发表一下你的评论吧 !
