

用英特尔CPU及GPU运行OpenAI-whisper模型语音识别
描述
作者:金立彦
介绍
Whisper 作为一款卓越的自动语音识别(ASR)系统,依托海量且多元的监督数据完成训练,其数据规模高达 680,000 小时,涵盖多种语言及丰富多样的任务类型,广泛采撷自网络资源,以此铸就了坚实的性能根基。
从技术架构层面剖析,Whisper 构建于先进的 Transformer 框架之上,采用经典的编码器 - 解码器模型设计,也就是广为人知的序列到序列模型范式。运作流程上,先是由特征提取器对原始音频输入展开精细处理,将其转换为对数梅尔频谱图,以此完成音频数据的初次 “编码”,提炼关键特征信息。紧接着,Transformer 编码器发挥强大的编码效能,深度解析频谱图蕴含的信息,进而凝练形成一系列编码器隐藏状态,为后续文本生成筑牢信息基石。最终环节,解码器粉墨登场,以前续已生成的文本标记以及编码器隐藏状态作为关键参照条件,遵循自回归原理,按顺序逐次预测文本标记,精准高效地实现从音频到文本的转换输出,展现出高水准的语音识别能力。
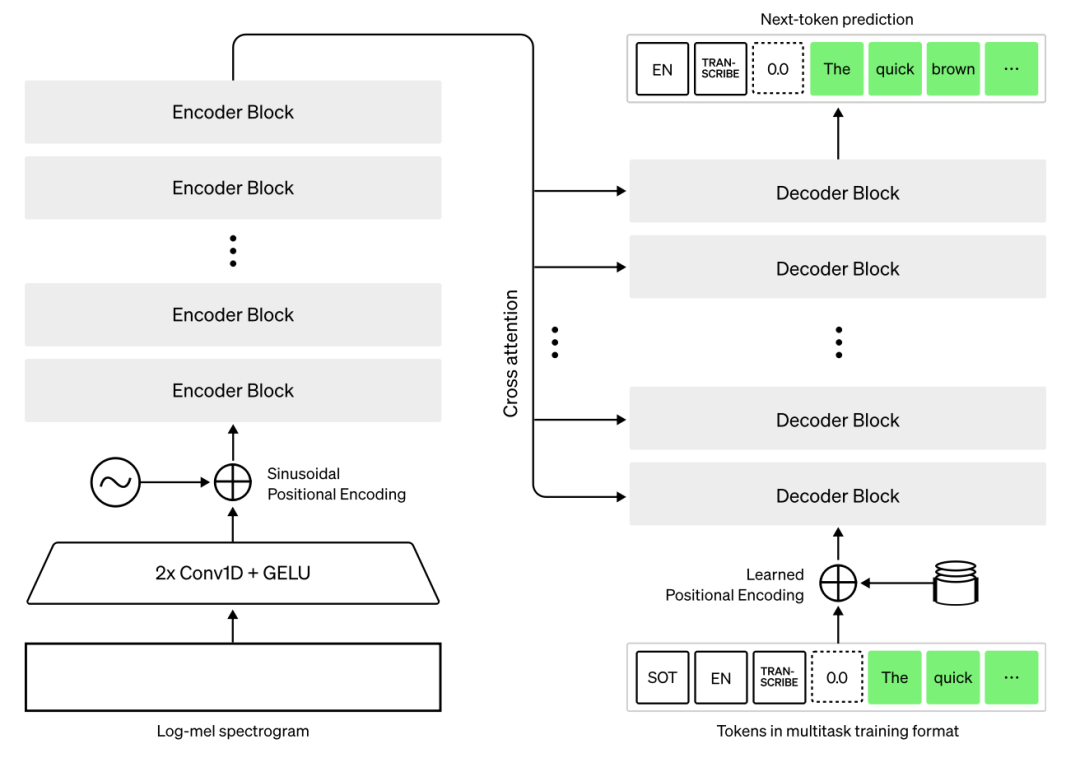
在本次教程里,我们将聚焦于如何借助 OpenVINO 高效运行 Whisper,解锁其强大的语音识别功能。为了快速上手、搭建应用,我们选用 Hugging Face Transformers 库中经过精心预训练的 Whisper 模型,充分利用其丰富且优质的参数设定与知识沉淀,作为项目开展的有力基石。紧接着,借助 Hugging Face Optimum Intel 库,能够轻松达成模型格式的无缝转换,将原本的模型精准转化为 OpenVINO IR 格式,这种格式专为 OpenVINO 生态量身定制,在推理速度、资源利用效率等诸多方面优势尽显,为后续流畅运行筑牢根基。
尤为值得一提的是,为了全方位简化用户在操作过程中的使用体验,我们引入便捷且高效的 OpenVINO Generate API,依托这一得力工具,去逐一落实 Whisper 自动语音识别的各场景应用,无论是实时语音转录,还是音频文件批量处理等,都能游刃有余,助力开发者以更低门槛、更高效率,驾驭 Whisper 与 OpenVINO 协同带来的卓越语音识别能力。
准备工作
依赖库安装
鉴于教程依托 OpenVINO - GenAI API 来开展各项验证,相应依赖环境的妥善搭建就成了至关重要的前置环节。为确保整个运行体系的稳定性、独立性与纯净性,强烈推荐借助 Python 的虚拟环境来执行安装操作。Python 虚拟环境能够有效隔离不同项目所需的依赖包及配置信息,避免因版本冲突、库依赖混淆等常见问题干扰项目推进,让 OpenVINO - GenAI API 所需的各类依赖组件得以精准、有序且互不干扰地完成部署,为后续流畅、高效运用该 API 筑牢坚实根基,从而保障整个语音识别功能开发与实践过程顺遂无忧。
pip install -q "torch>=2.3" "torchvision>=0.18.1" --extra-index-url https://download.pytorch.org/whl/cpu pip install -q "transformers>=4.45" "git+https://github.com/huggingface/optimum-intel.git" --extra-index-url https://download.pytorch.org/whl/cpu pip install -q -U "openvino>=2024.5.0" "openvino-tokenizers>=2024.5.0" "openvino-genai>=2024.5.0" --extra-index-url https://download.pytorch.org/whl/cpu pip install -q datasets "gradio>=4.0" "soundfile>=0.12" "librosa" "python-ffmpeg<=1.0.16" pip install -q "nncf>=2.14.0" "jiwer" "typing_extensions>=4.9" pip install -q "numpy<2.0"
在安装 openvino-genai 时需特别留意,务必添加 “--extra-index-url https://download.pytorch.org/whl/cpu” 这一参数,若不添加,后续调用 ov_genai.WhisperPipeline 方法时会出现找不到该方法的问题。此外,若使用的是 Windows 平台,还需关注 numpy 版本情况。鉴于可能存在的版本兼容性问题,建议将 numpy 版本降至 2.0 以下;要是遇到因版本不兼容而弹出提示的状况,可直接注释掉源文件,以此确保 openvino-genai 能够顺利安装与运行。
模型下载
模型下载具备两种可选方式。其一,借助 Hugging Face Optimum Intel 平台执行下载操作。倘若在此过程中遭遇下载受阻的情形,可灵活通过配置国内镜像站来完成下载路径的转换,顺利达成下载任务。不过需要注意的是,鉴于相关模型的数据体量颇为庞大,在模型转换阶段对内存容量有着较高要求,一旦设备内存过小,极有可能致使系统运行异常,甚至出现崩溃状况。
其二,可选择直接从 Hugging Face 下载由 intel 预先转换好的模型,这种方式更为便捷直接,免去了自行转换可能面临的内存等诸多困扰,可按需择优选用。
以下为目前所有支持的模型清单,供参考使用。
model_ids = {
"Multilingual models": [
"openai/whisper-large-v3-turbo",
"openai/whisper-large-v3",
"openai/whisper-large-v2",
"openai/whisper-large",
"openai/whisper-medium",
"openai/whisper-small",
"openai/whisper-base",
"openai/whisper-tiny",
],
"English-only models": [
"distil-whisper/distil-large-v2",
"distil-whisper/distil-large-v3",
"distil-whisper/distil-medium.en",
"distil-whisper/distil-small.en",
"openai/whisper-medium.en",
"openai/whisper-small.en",
"openai/whisper-base.en",
"openai/whisper-tiny.en",
],}
Hugging Face Optimum Intel
若计划通过 Hugging Face Optimum Intel 途径来获取所需内容,有两种便捷方式可供选择。
其一,可前往官方代码仓库
https://github.com/huggingface/optimum-intel.git
手动进行下载操作,按照页面指引与常规代码拉取流程,便能顺利将相关资源保存至本地。其二,更为高效的方式则是借助 pip 工具,在命令行输入 “pip install optimum-intel”,系统便会自动连接网络资源,开启下载与安装进程,轻松将 optimum-intel 模块部署到位。
然而,在实际操作过程中,可能会遇到因网络限制、服务器拥堵等因素导致的下载不畅甚至失败的状况。此时,巧妙配置国内镜像站就能有效破解难题,确保下载顺利推进。具体而言,配置国内镜像站后,下载命令如下(示例以常用的国内知名镜像站为例,实际可按需灵活选用适配镜像):在命令行输入 “pip install -i [镜像站地址] optimum-intel”,比如使用清华镜像站时,命令便是 “pip install -i https://pypi.tuna.tsinghua.edu.cn/simple optimum-intel”,以此借力国内优质镜像资源,快速、稳定地完成下载任务。
optimum-cli export openvino --model [模型] --library transformers --task automatic-speech-recognition-with-past --framework pt [保存路径]
如:
optimum-cli export openvino --model openai/whisper-large-v3-turbo --library transformers --task automatic-speech-recognition-with-past --framework pt models/whisper-large-v3-turbo
Hugging Face API下载
在模型应用场景中,若设备性能与存储条件理想,达到转换要求,那我们可自行将模型转换为 OpenVINO 格式,转换完成后便能顺畅投入使用,尽享 OpenVINO 带来的高效推理优势。然而,现实情况复杂多变,部分设备受限于硬件规格,诸如内存容量捉襟见肘、处理器性能差强人意,难以满足模型转换所需条件。但这并不意味着与 OpenVINO 格式模型的便捷体验失之交臂,借助 Hugging Face 的 API,我们得以另辟蹊径。只需简单操作,就能直接从 Intel 的资源库中获取已完美转换好的 OpenVINO 格式模型,跳过繁琐复杂的转换流程,即便设备性能欠佳,也能初步体验其魅力,虽说推理速度或许稍慢一些,可也为更多设备、更多使用者推开了一扇通往高效模型应用的大门。
安装Hugging Face api
pip install huggingface_hub
下载模型
import huggingface_hub as hf_hub # 模型id model_id = "Intel/whisper-large-v2-onnx-int4-inc" # 模型保存的位置 model_path = "whisper-large-v2-onnx-int4-inc" hf_hub.snapshot_download(model_id, local_dir=model_path)
具体所支持模型可以查看:
https://huggingface.co/Intel
设置国内镜像
如果无法下载,可以设置镜像下载为https://hf-mirror.com,只需要设置环境变量即可。
Linux
export HF_ENDPOINT=https://hf-mirror.comCopy
Windows Powershell
$env:HF_ENDPOINT = "https://hf-mirror.com"
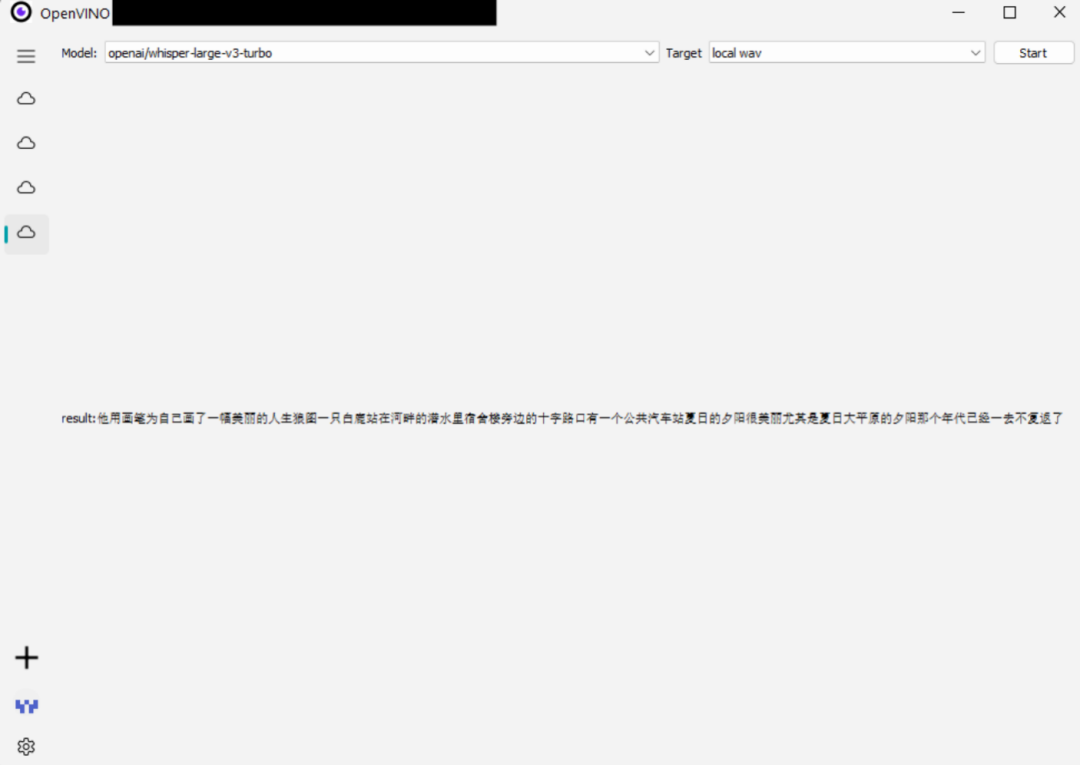
推理
mport librosa
# 推理设备,可以是CPU,GPU,NPU
device = “”
en_raw_speech, samplerate = librosa.load(音频文件, sr=16000)
import openvino_genai
ov_pipe = openvino_genai.WhisperPipeline(str(model_path), device=device.value)
start = time.time()
genai_result = ov_pipe.generate(en_raw_speech)
print('generate:%.2f seconds' % (time.time() - start)) # 输出推理时间
print(f"result:{genai_result}")
总结
通过本文,您将学习如何利用OpenVINO框架结合Intel的CPU和GPU硬件,快速高效地实现OpenAI Whisper模型的语音识别。OpenVINO作为一个强大的深度学习推理优化工具,可以显著提升模型推理的速度和性能,尤其是在Intel的硬件平台上。在本教程中,我们将详细介绍如何配置OpenVINO环境,如何将OpenAI Whisper模型转换为OpenVINO支持的格式,以及如何在Intel的CPU和GPU上运行该模型进行语音识别。
未来,借助OpenVINO框架,您将能够轻松实现更多语音识别相关的应用案例,例如多语种语音转文本、语音命令识别以及智能助手等。OpenVINO的跨平台能力和对多种硬件的支持,使其成为AI开发者进行高效推理加速的理想选择。
-
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程2025-07-17 2177
-
为什么无法检测到OpenVINO™工具套件中的英特尔®集成图形处理单元?2025-03-05 662
-
英特尔助力京东云用CPU加速AI推理,以大模型构建数智化供应链2024-05-27 1312
-
重塑翻译与识别技术:开源语音识别模型Whisper的编译优化与部署2024-01-06 5776
-
英特尔媒体加速器参考软件Linux版用户指南2023-08-04 731
-
英特尔放弃同时封装 CPU、GPU、内存计划2023-05-26 2474
-
釜底抽薪,英特尔挖了AMD的GPU墙角2022-02-22 5729
-
英特尔重点发布oneAPI v1.0,异构编程器到底是什么2020-10-26 2172
-
解读英特尔GPU架构2020-09-04 7622
-
英特尔未来的芯片都将集成语音识别技术2019-12-20 1166
-
黄仁勋欢迎英特尔进入GPU市场2019-03-26 997
-
如何才能在英特尔CPU第8代的主板上运行Windows Vista2018-10-17 3590
-
英特尔cpu命名规则_英特尔cpu分类有哪些_英特尔cpu性能排行榜2018-01-04 41250
全部0条评论

快来发表一下你的评论吧 !
