

Kaggle知识点:使用大模型进行特征筛选
描述
本文转自:Coggle数据科学
数据挖掘的核心是是对海量数据进行有效的筛选和分析。传统上数据筛选依赖于数据驱动的方法,如包裹式、过滤式和嵌入式筛选。随着大模型的发展,本文将探讨如何利用大模型进行特征筛选。
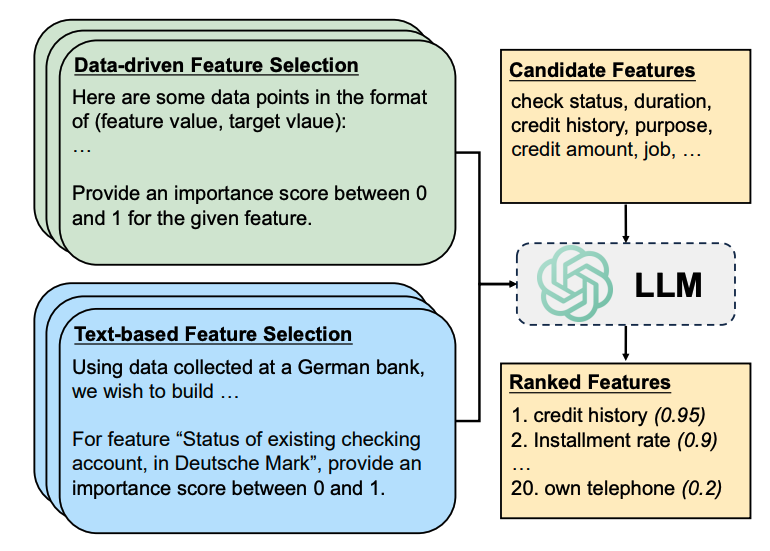
筛选思路
数据驱动方法依赖于数据集中的样本点进行统计推断,而基于文本的方法需要描述性的上下文以更好地在特征和目标变量之间建立语义关联。
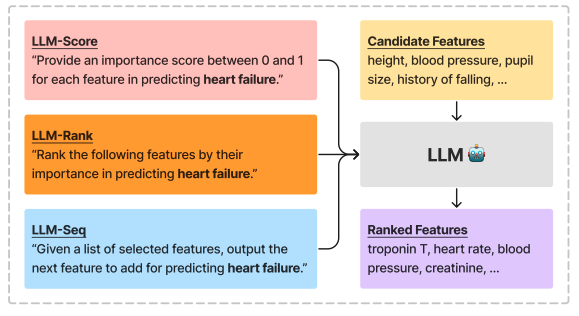
这种方法利用了大型语言模型(LLMs)中丰富的语义知识来执行特征选择。大模型将利用数据集描述(desd)和特征描述(desf),描述特征的重要性。
- LLM生成的特征重要性得分(LLM-Score)
- LLM生成的特征排名(LLM-Rank)
- 基于LLM的交叉验证筛选(LLM-Seq)
实验设置
- 模型:实验中使用了不同参数规模的LLMs,包括LLaMA-2(7B和13B参数)、ChatGPT(约175B参数)和GPT-4(约1.7T参数)。
- 比较方法:将基于LLM的特征选择方法与传统的特征选择基线方法进行比较,包括互信息过滤(MI)、递归特征消除(RFE)、最小冗余最大相关性选择(MRMR)和随机特征选择。
- 数据集:使用了多个数据集进行分类和回归任务的评估,包括Adult、Bank、Communities等。
实现细节:对于每个数据集,固定特征选择比例为30%,并在16-shot、32-shot、64-shot和128-shot的不同数据可用性配置下进行评估。使用下游L2惩罚的逻辑/线性回归模型来衡量测试性能,并使用AUROC和MAE作为评估指标。
实验结果
将LLM-based特征选择方法与传统的特征选择基线方法进行比较,包括LassoNet、LASSO、前向序贯选择、后向序贯选择、递归特征消除(RFE)、最小冗余最大相关性选择(MRMR)、基于互信息(MI)的过滤和随机特征选择。
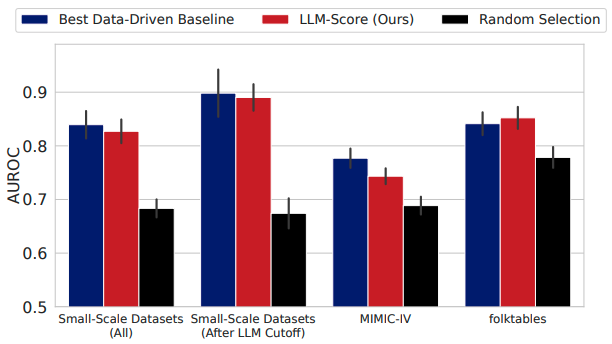
- 发现1:在小规模数据集上,基于文本的特征选择方法比数据驱动的方法更有效。在几乎所有的LLM和任务中,基于文本的特征选择方法的性能都超过了数据驱动方法。
- 发现2:使用最先进的LLMs进行基于文本的特征选择,在每种数据可用性设置下都能与传统特征选择方法相媲美。
- 发现3:当样本数量增加时,使用LLMs的数据驱动特征选择会遇到困难。特别是当样本大小从64增加到128时,分类任务的性能显著下降。
- 发现4:与数据驱动特征选择相比,基于文本的特征选择显示出更强的模型规模扩展性。
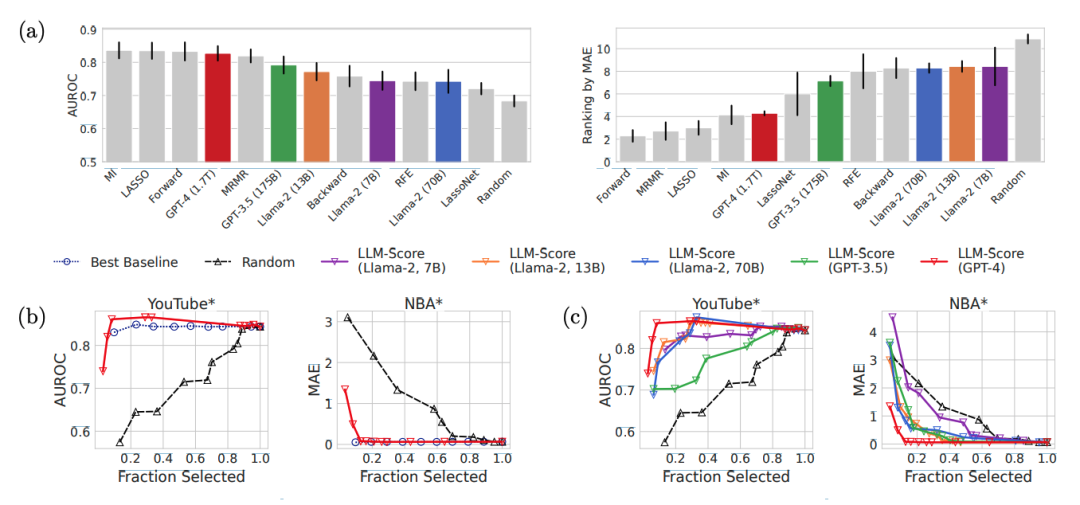
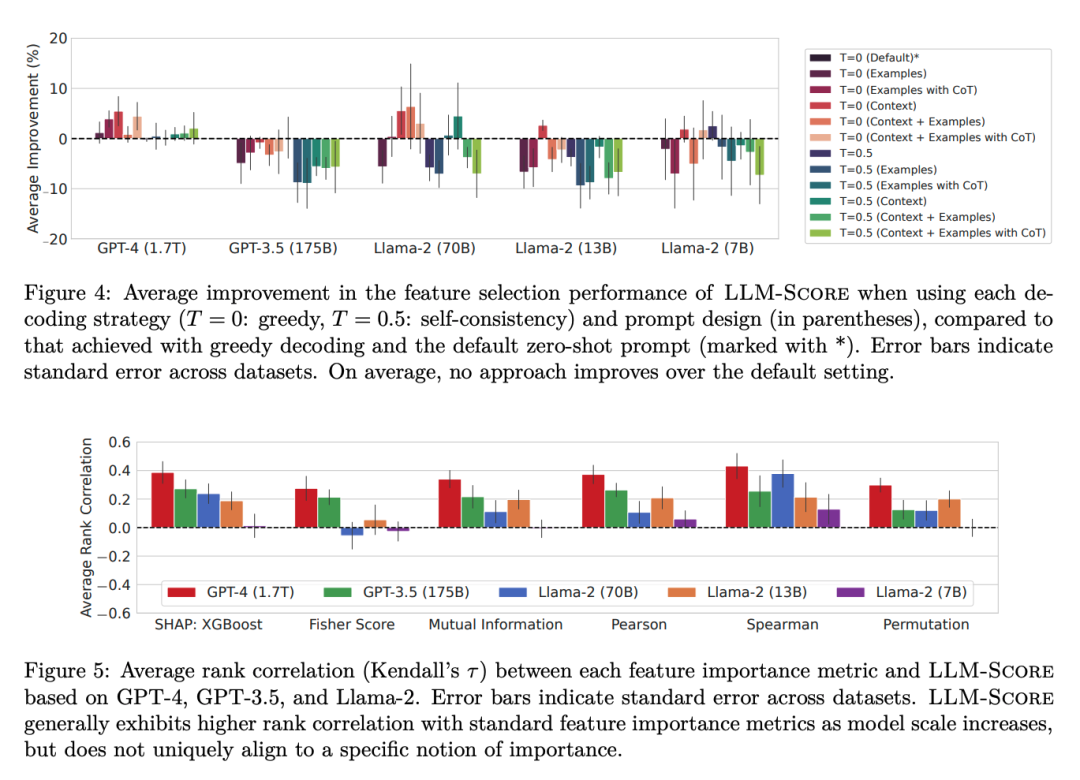
GPT-4基于LLM-Score在folktables数据集上整体表现最佳,在MIMIC-IV数据集上显著优于LassoNet和随机特征选择基线。LLM-Score在选择前10%和30%的特征时,与最佳数据驱动基线的性能相媲美,且明显优于随机选择。在医疗保健等复杂领域,LLM-Score即使在没有访问训练数据的情况下,也能有效地进行特征选择。
参考文献
https://arxiv.org/pdf/2408.12025
- https://arxiv.org/pdf/2407.02694
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
C语言链表知识点(2)2023-08-22 712
-
STM32 RTOS知识点2023-08-01 847
-
滚珠螺杆的基本知识点2023-07-07 2686
-
数字电路知识点总结2023-05-30 7361
-
C语言最重要的知识点2023-02-16 1074
-
详解射频微波基础知识点2023-01-29 3669
-
电力基础知识点合集2022-03-14 1390
-
嵌入式知识点总结2021-07-30 2046
-
BFC的基础知识点有哪些?2020-11-05 1877
-
使用PADS软件进行PCB设计,有哪些基础知识点?2019-08-20 13948
-
PWM知识点详解2017-03-16 1962
-
高一数学知识点总结2016-02-23 1560
-
基于知识点的改进型遗传组卷算法的研究2013-01-08 697
-
计算机组成原理考研知识点归纳2010-04-13 2052
全部0条评论

快来发表一下你的评论吧 !
