

人工智能发展需要新的芯片技术
描述
人工智能的繁荣发展需要新的芯片技术。
1997年,IBM的“深蓝”超级计算机打败了国际象棋世界冠军加里•卡斯帕罗夫。这是超级计算机技术的一次突破性展示,也首次让人们看到了高性能计算有一天可能超越人类智能。在接下来的十年里,我们开始将人工智能用于许多实际任务,如面部识别、语言翻译以及电影和商品推荐。
又过了15年,人工智能已经发展到可以“结合知识”的地步。ChatGPT和Stable Diffusion等生成式人工智能可以写诗、创作艺术作品、诊断疾病、编写总结报告和计算机代码,甚至可以设计出与人类设计相媲美的集成电路。
人工智能很有可能成为未来所有人类活动的数字助手。ChatGPT就是一个很好的例子,它展示了人工智能有助于推动高性能计算的普及性应用,为社会中的每一个人带来益处。
所有这些奇妙的人工智能应用都归功于3个因素:高效机器学习算法的创新、可用于训练神经网络的海量数据,以及通过半导体技术发展实现的节能计算进步。虽然最后这一项贡献无处不在,但它在生成式人工智能革命中的重要性却未得到应有的重视。
在过去30年里,人工智能的重要里程碑都是通过当时最先进的半导体技术实现的,没有它们,这些里程碑就不可能实现。深蓝计算机是通过结合0.6微米和0.35微米节点的芯片制造技术实现的;赢得ImageNet竞赛并开启当前机器学习时代的深度神经网络是用40纳米技术实现的;AlphaGo使用28纳米技术征服了围棋世界,初版ChatGPT是在采用5纳米技术的计算机上训练的。而最新版的ChatGPT则依靠使用了更先进的4纳米技术的服务器提供支持。从软件和算法到架构、电路设计和设备技术,人工智能所涉及的每一层计算机系统都是提高人工智能性能的倍增器。但公平地说,基础晶体管技术是实现上层进步的关键。
如果人工智能革命要继续按照当前的速度发展下去,将需要半导体行业提供更多的支持。10年内,它将需要拥有1万亿个晶体管的GPU,是目前常见GPU所拥有的晶体管数量的10倍。
人工智能模型规模的持续增长
过去5年里,人工智能训练所需的计算能力和内存访问量提高了几个数量级。例如,训练GPT-3需要相当于每秒超过5000千万亿次的运算持续一整天,并需要3万亿字节(3TB)的内存容量。
新的生成式人工智能应用所需的计算能力和内存访问量还在继续快速增长。现在,我们需要回答一个紧迫的问题:半导体技术如何才能跟上这一步伐?

从集成器件到集成芯粒
自集成电路发明以来,半导体技术一直致力于缩小特征尺寸,以便将更多的晶体管塞进极小的芯片中。今天,集成已经上升到了一个更高的层次;我们将超越二维缩放,进入三维系统集成。我们正在将许多芯片组装成一个紧密集成的大规模互连系统。这是半导体技术集成的范式转变。
在人工智能时代,系统能力直接与系统集成的晶体管数量成正比。限制晶体管集成数量的主要因素之一是光刻芯片制造工具被设计成只能制造不超过约800平方毫米的集成电路,这被称为“光罩限制”。但现在,我们可以将集成系统的尺寸扩展到光刻技术的光罩限制之外。通过将几块芯片连接到一个更大的中介层(一块内置互连的硅片)上,我们可以集成一个能够比单芯片包含更多器件的系统。例如,台积电的基板上晶圆芯片(CoWoS)技术可以容纳多达6个光罩范围的计算芯片,以及十几个高带宽存储器(HBM)芯片。
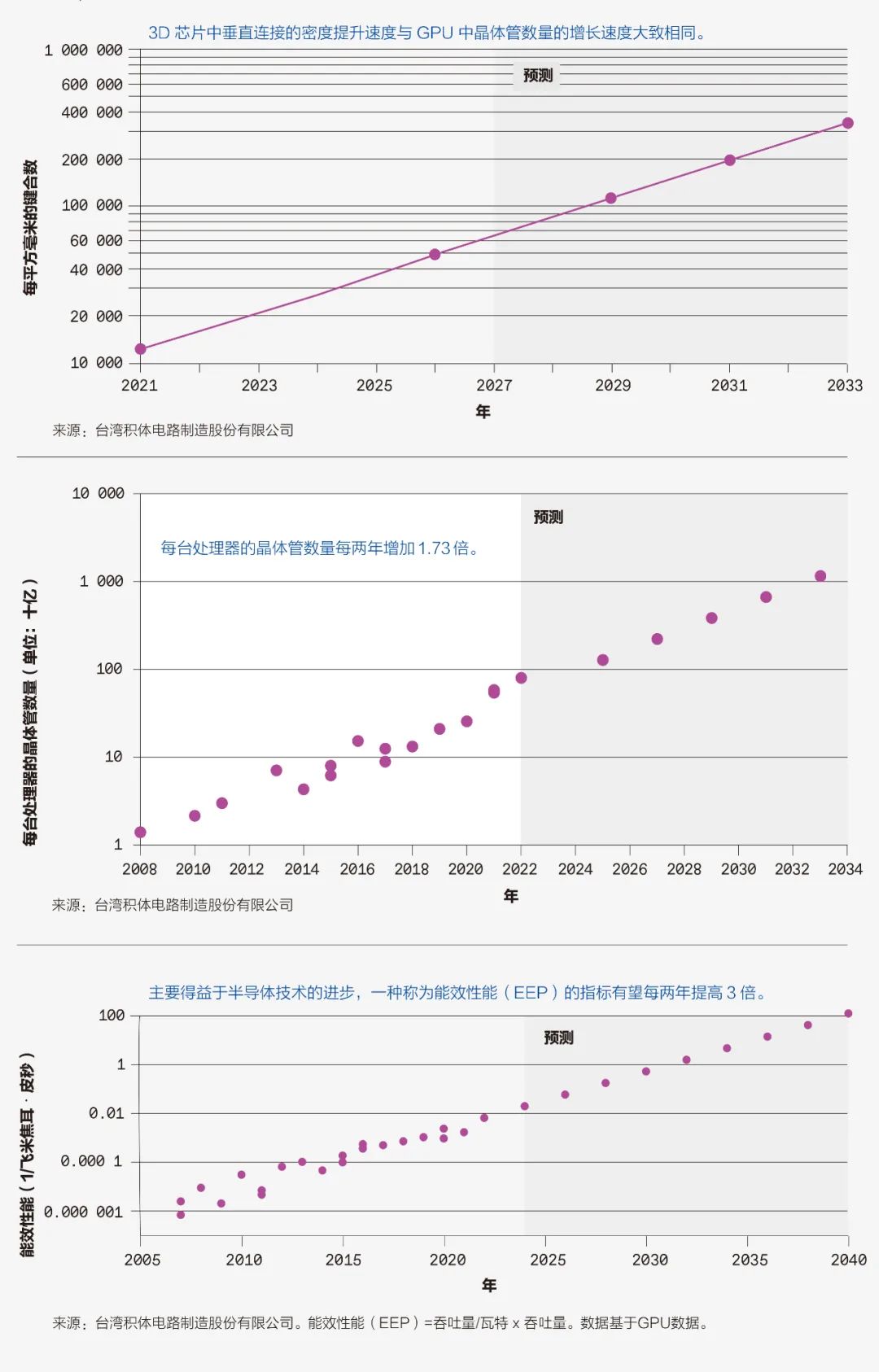
高带宽存储器是另一种对人工智能而言越来越重要的关键半导体技术:该技术可将芯片堆叠在一起进行系统集成,台积电称之为“集成片上系统”(SoIC)。高带宽存储器由一堆动态随机存取存储器(DRAM)垂直互连芯片组成,位于控制逻辑集成电路之上。它使用了称为“硅通孔”的垂直互连来让信号通过每块芯片,并使用了焊锡球连接内存芯片。如今,高性能图形处理器(GPU)广泛使用了高带宽存储器。
未来,3D 系统级集成单芯片技术可以为目前的常规高带宽存储器技术提供替代方案,在堆叠芯片之间实现更密集的垂直互连。最新进展显示,高带宽存储器测试结构使用混合键合堆叠了12层芯片,相较于目前使用的焊锡球,这种铜对铜连接实现了更高的密度。这种内存系统在低温下在较大的基础逻辑芯片之上进行键合,总厚度仅为600微米。
随着由大量芯片组成的高性能计算系统运行大型人工智能模型,高速有线通信可能很快会限制计算速度。如今,数据中心已经在使用光互连来连接服务器机架。很快,我们将需要基于硅光子技术与GPU和中央处理器(CPU)一起封装的光学接口。它们将提高带宽的能源效率和面积效率,实现直接的GPU到GPU光学通信,使成百上千台服务器像一个具有统一内存的巨型GPU一样工作。人工智能应用的需求将让硅光子技术将成为半导体行业最重要的使能技术之一。
迈向万亿晶体管GPU
如前所述,用于人工智能训练的典型GPU芯片已经达到了光罩范围限制,其晶体管数量约为1000亿个。要持续晶体管数量增多的趋势,将需要用2.5D或3D集成互连的多芯片来执行计算。通过基板上晶圆芯片、集成片上系统或相关的先进封装技术集成多个芯片,可以使每个系统的总晶体管数量远远超过单块芯片所能容纳芯片的数量。我们预测,在10年内,一个多芯粒GPU将拥有超过1万亿个晶体管。
我们需要在一个3D堆栈中将所有这些芯粒连接起来,不过幸运的是,业界已经能够迅速缩小垂直互连的间距,从而提高连接的密度,而且还有很大的进步空间。我们认为互连密度完全可以提高一个数量级,甚至更多。
GPU的能效性能趋势
那么,这些硬件创新技术将如何提升系统性能?
如果关注能效性能(EEP)这一指标的稳步提升,我们便可以从服务器GPU中看到这一趋势。能效性能是系统能源效率和速度的综合衡量指标。在过去15年里,半导体行业的能效性能每两年提高大约3倍。我们相信这一趋势将按照历史速度继续。它将受到来自多方面创新的推动,包括新材料、设备和集成技术、极紫外光刻、电路设计、系统架构设计以及所有这些技术元素的协同优化等。
特别是我们在此讨论的先进封装技术,它将推动能效性能的提高。此外,系统技术协同优化等概念也会越来越重要,系统技术协同优化是将GPU的不同功能部分分散到各自的芯粒上,并使用性能最佳、最经济的技术来构建每个部分。
3D集成电路的米德-康维时刻
1978年,加州理工学院教授卡沃•米德(Carver Mead)和施乐帕洛阿尔托研究中心的琳•康维(Lynn Conway)发明了一种用于集成电路的计算机辅助设计方法。他们使用了一套设计规则来描述芯片尺寸,使工程师无须深入了解工艺技术就能轻松设计超大规模集成电路。
现在,3D芯片设计也需要类似的能力。如今的设计师需要了解芯片设计、系统架构设计以及软硬件优化。制造商需要了解芯片技术、3D集成电路技术和先进封装技术。正如1978年那样,我们再次需要一种描述这些技术的通用语言,让电子设计工具能够理解这些技术。这种硬件描述语言可以让设计师自由地进行3D集成电路系统设计,而不必考虑底层技术。这种语言已经在发展之中了,一种名为3Dblox的开源标准已经被当今大多数技术公司和电子设计自动化公司接受。
隧道尽头的未来
在人工智能时代,半导体技术是推动新的人工智能能力和应用发展的关键因素。新的GPU不再受制于过去的标准尺寸和形式因素。新的半导体技术不再局限于在二维平面上来缩小下一代晶体管。人工智能集成系统可以由尽可能多的节能晶体管、专用计算工作负载的高效系统架构以及软硬件优化关系组成。
在过去50年里,半导体技术的发展就像在隧道中行走。前方的道路是清晰的,因为有一条明确的路径,而且大家都知道需要缩小晶体管。
现在,我们已经走到了隧道的尽头,之后的半导体技术将越来越难开发。然而在隧道之外,还有更多的可能性在等待着我们。
-
人工智能是什么?2015-09-16 6273
-
人工智能技术—AI2015-10-21 9604
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 7652
-
人工智能发展的好与坏2017-06-24 7440
-
数据对人工智能发展的重要性2017-10-09 5462
-
人工智能就业前景2018-03-29 8275
-
2018人工智能芯片技术白皮书 中文版2018-12-13 5115
-
初学AI人工智能需要哪些技术?这几本书为你解答2019-01-21 9452
-
人工智能技术及算法设计指南2019-02-12 5023
-
人工智能语音芯片行业的发展趋势如何?2019-09-11 5088
-
人工智能和机器学习技术在2021年的五个发展趋势2021-01-27 4764
-
人工智能芯片是人工智能发展的2021-07-27 6405
-
人工智能和计算机技术对数控技术发展的影响有哪些?2021-11-01 2509
-
人工智能对汽车芯片设计的影响是什么2021-12-17 2060
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2201
全部0条评论

快来发表一下你的评论吧 !
