

面向科学计算,第五代英特尔至强可扩展处理器优势何在
描述
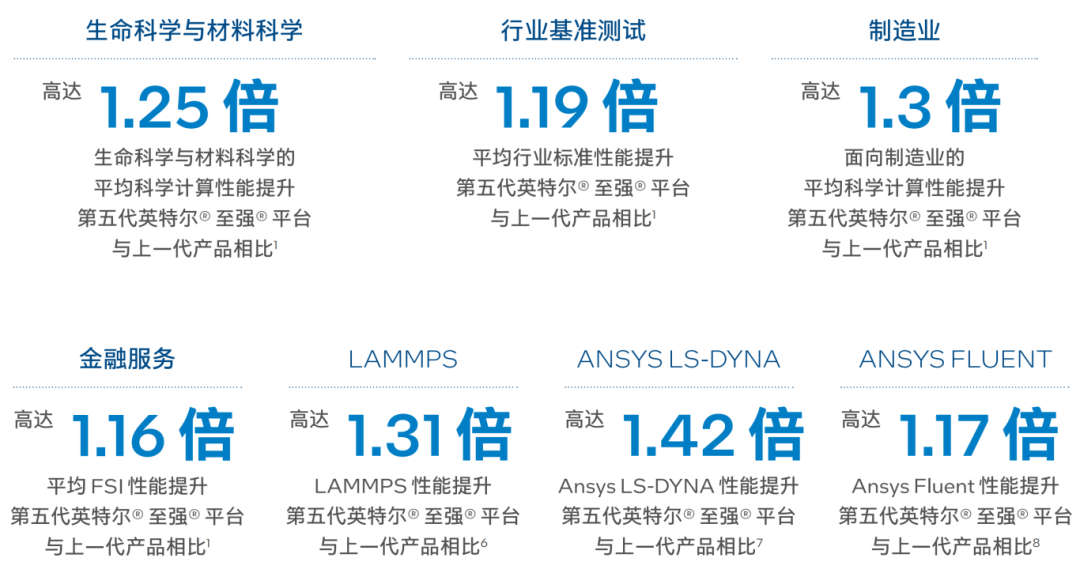
与上一代产品相比:第五代英特尔 至强 处理器的平均科学计算性能提升高达1.22倍,可以帮助企业显著提升基础设施的价值1;平均每瓦性能提升高达1.08倍,有助于降低成本和碳足迹。其基于硬件的安全功能和可扩展的特性,还可帮助企业和机构提升系统的正常运行时间以及构建面向未来IT基础设施。本代处理器还提供面向科学计算与AI融合工作负载的通用CPU平台,有助于加速价值实现。


虽然传统的科学计算系统是为单体应用设计的,但它正在向更灵活的方向转变,以应对更多样化的需求。同时,这种演变也让从业者更加重视开放标准的软硬件,以促使各类解决方案和工作负载能够共存,并在共享系统上实现更出色的结果。在未经优化的硬件上部署AI工作负载,可能无法实现每瓦性能目标。开放式跨架构编程模型可以避免为多种架构和异构加速器重新编码,其重要性日益凸显。这些模型还有助于避免专有软件绑定风险,延长科学应用的寿命,更好地应对未来需求。
第五代英特尔 至强 处理器依然受英特尔 软硬件生态系统的支持,能够助力加速传统科学计算以及科学计算与AI融合工作负载,更快获取价值。本代处理器非常适合具有高级迁移学习或调优要求的中小型专用模型。针对深度学习和通用工作负载的基于硬件的加速技术可为融合科学计算应用提供实时吞吐量和更低时延。
与第四代英特尔 至强 处理器相比,第五代英特尔 至强 处理器每路提供多达64个高性能内核(128条线程),三级缓存容量增加高达3倍3。这些变化可提升诸如电子设计自动化(EDA)和计算流体动力学(CFD)等要求严苛且高度并行工作负载的处理器内核利用率。第五代英特尔 至强 处理器提供速率高达5600MT/s的DDR5内存4以及多达80条PCIe5.0通道,I/O功能更强大,可优化时延并持续向内核传输数据。

第五代英特尔 至强 处理器与第四代英特尔 至强 处理器在软件和引脚上兼容,升级后可以延长IT投资的生命周期并提升回报率。如果是基于更早的英特尔 至强 处理器进行升级,这些优势将更为显著。持续的平台创新更广泛地优化了数据传输和处理,同样有助于科学计算与AI融合的实施。
英特尔 加速引擎
第五代英特尔 至强 处理器配备英特尔 加速引擎,凭借众多内置加速器,为AI、科学计算、数据分析、网络和存储等关键任务提升吞吐量。由于它们内置于处理器中,与独立解决方案或在内核上运行的基于软件的解决方案相比,不会产生从片外访问PCIe总线上独立加速器的时延,相应地,就节省了能耗。因此,英特尔 加速引擎能够帮助企业和机构实现更好的性能并节省资本支出(CapEx)和运营支出(OpEx)。
• 性能:专用的加速器大幅提升目标工作负载的吞吐量。其中,英特尔 高级矩阵扩展(Intel AdvancedMatrixExtensions,英特尔 AMX)可加速CPU上的AI工作负载,无需额外的专用硬件即可提高吞吐量。
• 运营和系统成本:使用内置加速器可以减少对额外系统投资的需求,而系统占用空间的减少可以节省大量能源。 基于第五代英特尔 至强 处理器的科学计算与AI融合解决案采用先进的指令集架构(ISA),旨在加速常见的AI和机器学习任务。例如,英特尔 矢量神经网络指令(VNNI)通过将三条指令合并为一条,以完成INT8运算中的乘累加,从而加速推理。支持的新数据类型还包括BF16,这种16位浮点格式可以加速推理,同时保持模型准确性。通过使用较低精度并降低计算要求,能够缩短模型训练时间(或推理时间)。

可立即部署的科学计算与AI融合工具
在各行各业以及各科学领域的科学计算工作流程中,AI的应用越来越普遍,有望显著提高效率。AI与科学计算的融合可能发生在应用或工作流程层面。在科学计算领域中,可运用AI模型替代传统模型来完成某些任务,比如从粗网格(coarsemesh)中创建细网格(finemesh)结果。AI模型可能会以更短的时间和更高的精确度完成这项工作。在科学计算工作流程中,AI可用于后处理,以评估结果并为用户生成洞察,也可用于预处理,以改进科学计算工作负载中使用的输入数据集。
英特尔 软件开发工具由oneAPI提供支持,包括编译器、库、框架和性能工具,用以构建、分析和调整面向英特尔 架构优化的高质量跨平台软件。具体而言,英特尔 软件开发工具简化了英特尔 加速引擎在解决方案中的应用,有助于提高CPU、GPU以及FPGA等其他硬件的性能和效率。这些工具包括英特尔 oneAPI基础工具套件和英特尔 oneAPIHPC工具套件,用于在共享和分布式内存计算系统中构建、分析和扩展应用,以及英特尔 AI工具,用于加速端到端数据科学和机器学习管线。
此外,英特尔还通过参与开源和将新增值优化提交至上游,以及与整个解决方案生态系统建立合作伙伴关系,坚定地致力于生态系统的支持。有了这些支持措施,开发人员就可以用更短的时间和更少的精力与英特尔的技术路线图保持一致,并能以经济高效的方式提高解决方案的性能、效率和未来就绪性。
更出色的性能和总体拥有成本优势
第五代英特尔 至强 处理器提高了一系列科学计算基准测试和工作负载的吞吐量。这些优势主要得益于更多的内核数、更大的三级缓存以及更大的内存带宽。除了提高系统资本投资的价值外,第五代英特尔 至强 处理器还有助于减少能源消耗,从而优化总体拥有成本(TCO)。
为满足各种科学计算和AI融合用例,解决方案架构师可以采用额外的配套英特尔 硬件技术,而无需移植或重构代码,从而保持整个环境的软件兼容性。为了改善要求严苛的内存带宽敏感型工作负载的性能,英特尔 至强 CPUMax系列在处理器封装上集成了高达64GB的HBM2e高带宽内存,减少了通过内存总线获取数据的需求。 多样化的英特尔 软硬件技术为科学计算与AI融合从业者提供了面向未来的创新能力,让他们能够更快、更经济高效地解决复杂的计算问题。
注释:
1. 英特尔锐炫 B580 提供出色的性能与价格平衡,是一款建议零售价在250至300美元之间的显卡。在1440p超高清的光栅化和光线追踪设置下测试了40多款游戏。截至2024年11月13日的测试日期,价格与建议零售价相比一直保持稳定。详情请见intel.com/performanceindex。
2. XeSS 2中的XeSS帧生成技术可带来高达3.9倍的性能提升,这是在1440p超高清分辨率下使用英特尔锐炫 B580运行游戏F1 24,启用XeSS超高性能模式的测试结果。详情请见intel.com/performanceindex。
3. 与上一代英特尔锐炫A750限量版相比,基于在1440p超高清分辨率下对各种游戏进行平均测试得出的结果,第二代Xe核心可为英特尔锐炫B系列带来高达70%的每Xe核心性能提升。详情请见intel.com/performanceindex。
4. 与上一代英特尔锐炫A750限量版相比,基于在1440p超高清分辨率下对各种游戏进行平均测试得出的结果,第二代Xe核心可为英特尔锐炫B系列带来高达50%的每瓦特性能提升。详情请见intel.com/performanceindex。
5. 在1440p超高清设置下的各种游戏中,英特尔锐炫 B580比英特尔锐炫A750限量版快24%,其中选定的游戏启用XeSS性能模式(如果可用)。详情请见intel.com/performanceindex。
AI功能可能需要购买软件、订阅、由软件或平台提供商启用,可能会有特定的配置或兼容性要求。详情请见intel.com/AIPC。结果可能会有所不同。
-
宁畅B5000 G5多节点服务器采用第五代英特尔至强可扩展处理器2024-05-27 1817
-
第五代英特尔至强处理器,AI特化的通用服务器CPU2024-03-18 6928
-
英特尔至强处理器优化升级,助力打造未来高能效数据中心2024-02-26 1843
-
第五代英特尔至强可扩展处理器以强劲性能,打造更“全能”的计算2024-01-19 1412
-
H3C UIS超融合方案采用第五代英特尔至强可扩展处理器2024-01-13 2909
-
英特尔专家为您揭秘第五代英特尔® 至强® 可扩展处理器如何为AI加速2023-12-23 1492
-
宝德服务器全面升级到第五代英特尔®至强®平台2023-12-21 1703
-
64核+高内存带宽!英特尔发布第五代至强服务器,加速AI原生应用落地2023-12-20 3908
-
64核+高内存带宽!英特尔发布第五代至强可扩展处理器,加速AI原生应用落地2023-12-19 6445
-
第五代英特尔至强可扩展处理器 AI 性能大幅提升,英特尔加注推动人工智能无处不在2023-12-18 1456
-
英特尔发布酷睿Ultra和第五代至强可扩展处理器2023-12-16 2735
-
英特尔第五代、第六代处理器相关参数曝光2023-09-08 2392
全部0条评论

快来发表一下你的评论吧 !
