

Meta万卡GPU集群稳定性剖析与最佳实践
描述
一、背景
本文中我们将具体介绍 Meta 对其万卡 AI 集群稳定性的剖析和刻画,以及在其中遇到的各种挑战,并在其中补充了一些真实场景中遇到的 Case,便于理解。
对应的论文为:[2410.21680] Revisiting Reliability in Large-Scale Machine Learning Research Clusters [1](文末附下载)
二、摘要
可靠性是运维大规模机器学习基础设施的重要挑战,尤其是 ML 模型和训练集群的规模在不断扩大,这一挑战更加明显。尽管对基础设施故障的研究已经有数十年历史,但不同规模下作业故障的影响仍然不是特别明确。
本文中,作者从管理两个大型多租户 ML 集群的视角,提供了相应的定量分析、运维经验以及在理解和应对大规模可靠性问题上的见解(PS:我们也会重点标记其对应的 12 个见解)。分析表明,尽管大型作业最容易受到故障影响,但小型作业在集群中占大多数,也应纳入优化目标。作者识别了关键工作负载的属性,进行了跨集群比较,并展示了扩展大规模 ML 训练所需的基本可靠性要求。
本文中,作者引入了一种故障分类法和关键可靠性指标,分析了两个最先进的 ML 集群 11 个月内的数据,涉及超过 1.5 亿 GPU 小时和 400 万个作业。基于数据,作者拟合了一个故障模型,以预测不同 GPU 规模下的平均故障时间。作者也进一步提出了一种方法,根据作业参数估计相关指标——有效训练时间比(Effective Training Time Ratio,ETTR),并利用该模型评估潜在的缓解措施在大规模环境中的有效性。
三、Infra 系统
本节中作者阐述了工作负载如何影响集群的设计。尽管集群可以特化以针对特定工作负载进行优化,但集群会面对持续变化并且可能难以预见潜在的工作负载需求。因此,作者认为集群应该具备通用性,以最大化生产力,并最小化附带复杂性。作者重点关注早期的两个 A100 集群(PS:Meta 后续又搭建了 2 个 24K H100 GPU 的集群),RSC-1 和 RSC-2,它们遵循相同的设计模板。
RSC-1 是一个通用 ML 集群(例如,训练一些 LLM),规模为 16,000 个 A100 GPU;
RSC-2 专注于计算机视觉应用,规模为 8,000 个 A100 GPU。
后续章节也会具体介绍,工作负载的差异体现在不同的使用模式中,例如,RSC-2 上的工作负载显著倾向于 1-GPU 的作业,同时也有高达 1,000 个 GPU 的作业。
3.1 调度和存储 Infra
RSC-1 和 RSC-2 集群设计以易用性为优先考量,同时追求简洁性。其优势在于整个技术栈相对成熟,无需大规模定制相关数据中心设计。此外,设计也力求在不附加任何条件的情况下为用户提供所需数量的 GPU,以最大化生产力——用户无需应对新型硬件或虚拟化带来的复杂性。如下图 Fig 1 展示了用户如何与集群进行交互,用户提交包含多个任务的作业,每个任务均可运行于节点的 GPU 上:
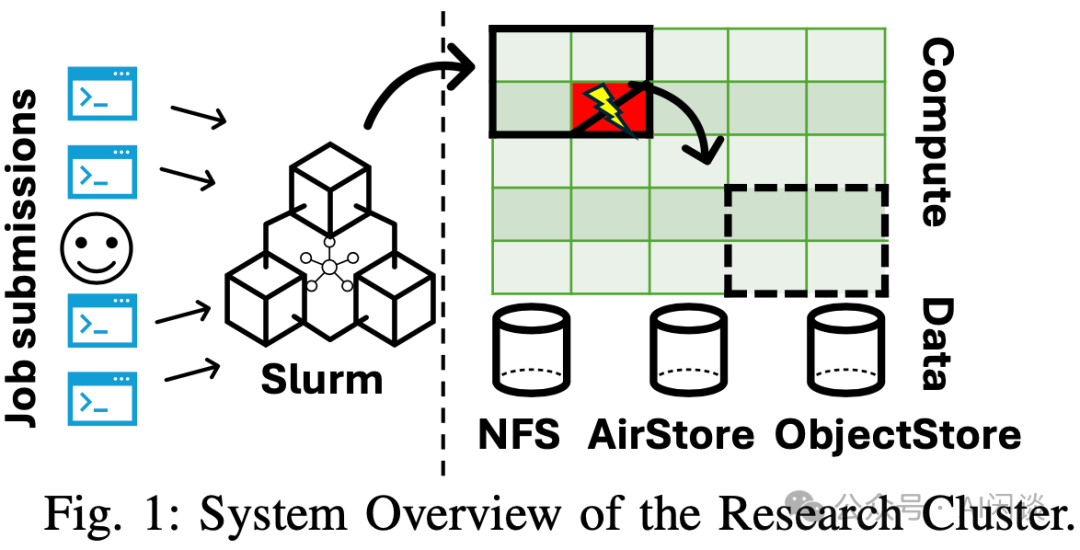
调度器(Scheduler):依托高性能计算(HPC)技术栈,作者的机器采用基于裸金属分配的 Slurm 调度器(Slurm Workload Manager [2])。用户通过 Shell 脚本(sbatch)或 Python 装饰器(submitit)提交作业。Slurm 则根据物理网络拓扑放置任务。作业运行 2 小时后可以被抢占,并且最长生命周期为 7 天。Scheduler 根据优先级顺序安排任务,优先级受多种变量影响,包括项目配额以及任务时长。
ML工作负载遵循 Gang Scheduling 语义。Gang Scheduling 确保同一作业的多个任务所需的资源同时分配,这对于大规模 ML 工作负载的性能和效率优化至关重要。然而,如上图 Fig 1 所示,单个任务失败可能导致整个作业的重新分配。针对这种情况,通常会采用容错策略,比如 Checkpointing 和冗余计算,以支持集群的容错调度。Checkpointing 确保作业可以从保存的状态恢复,减少对整体作业的影响,而冗余计算则降低作业失败的概率。基础设施会为用户提供这种保障机制——若健康检查导致作业终止,系统会自动将作业重新排队,且保留相同的作业 ID。整体而言,RSC-1 集群平均每日提交 7.2k 作业,RSC-2 集群平均每日提交 4.4k 作业,并分别实现 83% 和 85% 的集群利用率。
存储(Storage):输入、输出数据以及作业的 Checkpoint 需要具备持久性,并独立于特定作业的生命周期。作者的集群提供了 3 种存储服务,使用户能够在易用性和性能之间进行权衡选择:
基于闪存存储,采用 NFS 协议并兼容 POSIX 的存储服务。便于使用,为用户提供主目录、Python 环境及执行常见操作(如 Checkpointing)的读写能力。
AirStore,自定义、高带宽的存储服务。通过自定义的高性能只读缓存服务 AirStore 加速数据集访问,同样依托于大规模闪存存储。
ObjectStore,高容量与高吞吐量的对象存储服务。用于 Checkpoint 和文件存储,应对 NFS 存储有限的问题。
3.2 计算和网络 Infra
高性能计算集群的核心硬件组件包括计算、网络和存储。用户通过提交给 Scheduler 的作业来提供使用这些组件的指令。集群的拓扑结构如下图 Fig 2 所示,其中展示了节点系统的布局以及单个节点的内部结构:
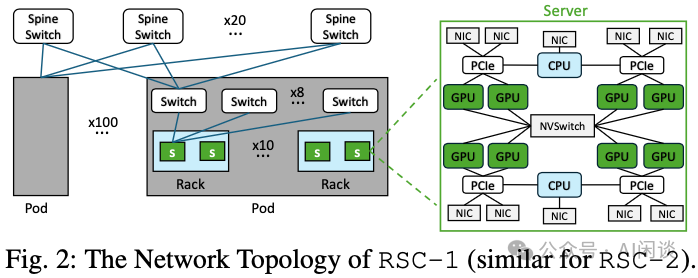
计算(Compute):RSC-1 和 RSC-2 两个集群均为基于 DGX 的裸金属集群,每个节点配备双 AMD Rome 7742 CPU 和 8 块 NVIDIA A100 80GB GPU。GPU 之间通过高带宽的 NVLink + NVSwitch 互联。
网络(Networking):在实际应用中,一个作业可能使用数百个节点,这些节点通过前端(Frontend)和后端(Backend)两种方式互联。前端网络主要用于以太网管理平面(即调度和 TCP 连接)和存储流量。同时,如上图 Fig 2 所示,节点后端网络通过 IB 链接,在模型训练期间可以实现低延迟的梯度交换。通信被划分为逻辑域:每个机架包含 2 个节点,10 个机架通过优化的网络连接,形成一个 Pod,Pod 内的通信只用通过 Leaf 交换机,Pod 间的通信需要通过 Spine 交换机。
Scheduler 和模型训练框架(如 Pytorch)应抽象出网络的大部分复杂性,提供基于传统集合通信的模型,该模型应具备跨多种作业分配的可移植性和高效性。关键在于,后端网络软件能够利用存在的局部性(例如,可能的话,优先使用高带宽的 NVSwitch,而非同构机架顶部的 Tor Switch 连接)。
3.3 集群 Infra 的见解
见解 1:集群正常运行时间至关重要。作者的集群处于满负载状态,任何停机都会导致过度排队,并被视为重大事件。集群应该能够实时适应故障,理想情况下应自动重新排队与 Infra 相关的故障。
健康检查:由于机器学习作业的 Gang Scheduling 调度语义,故障对整个作业的可靠性影响巨大——系统组件的单一故障可能导致数千个 GPU 闲置。此外,在大规模集群中,组件故障之间的间隔时间可能很短。为此,作者的 Infra 设计侧重于检查作业是否在健康硬件上运行,并在发生故障时将作业在不同节点重启。
为了发现、检测并移除故障节点,Scheduler 相应会接收集群中每个节点定期执行的一系列健康检查的结果,通过这些健康检查也可以分析作业故障。作者的训练集群设计的核心理念是力求避免异常节点导致的二次作业失败——故障节点不是一个好的调度候选。
Slurm 可以在作业运行前后执行健康检查。此外,也会每 5 分钟执行一次健康检查,并返回表示成功、失败和警告的 Code。每个健康检查都会检查节点的几个方面,涵盖从 GPU 错误(如 XID 错误)到文件系统挂载错误及服务状态(例如,Scheduler)。需要注意的是,检查可能具有重叠的故障域信号,例如,即使 GPU 本身未发生相应的 XID 事件,PCIe 故障也可表明 GPU 不可用。这种情况在 RSC-1 上出现的频率为 57%,在 RSC-2 上为 37%。因此,即使某一检测未能如期触发,另一重叠的检测也有望捕捉到这一问题。此种情况最极端的例子是 NODE_FAIL,用于当节点未能对其他检测做出响应时,通过 Slurm 的心跳机制实现的全面捕获手段。
定期健康检测对于防止同一异常节点导致的重复作业失败至关重要。此外,这些检测也经过一系列调整,以降低误报率,这使得成功完成的作业中观察到健康检查失败的比例低于 1%,当然,也只是观察到相关性而非因果关系。
不同检测的严重程度各异。当节点健康检查失败时,节点将进入修复状态,直到修复完成且所有检测通过前,无法再进行作业调度。
高严重性检测异常会立即向 Scheduler 发出信号,移除该节点并重新调度所有在该节点上执行的作业。包括 GPU 不可访问,NVLink 错误,不可纠正的 ECC 错误,行重映射(failed row-remaps),PCIe 或 IB 链路错误,块设备错误或挂载点缺失。
而较低严重性的检测异常则会等节点上的作业完成(无论成功与否)再向 Scheduler 发送移除节点信号并进行修复。
未触发任何健康检查异常的节点可用于作业调度。
健康检查的重要性也可以通过反向实验验证,比如在可能存在异常的节点上调度。即使只有一小部分节点异常,随着规模的扩大,作业调度到异常节点的概率会呈指数级增加。需要强调的是,健康检查是确保可靠 Infra 的第一道防线。
见解 2:一颗老鼠屎坏了一锅汤。健康检查机制能够防止因反复调度到故障节点而引起的关联性故障(也就是“循环重启”)。若无法将此类节点移除,将导致无法有效运行大规模作业,并严重削弱集群效率,唯有确保故障节点能够可靠地移除,从随机故障中恢复才会有实际效果。
3.4 指标
有三个关键指标可以帮助理解机器学习集群性能:有效训练时间比(Effective Training Time Ratio,ETTR)、模型浮点运算利用率(Model Flops Utilization,MFU)和 有效产出(Goodput)。
有效训练时间比(ETTR):ETTT 定义为生产性运行时间与作业运行时间的比值。一个作业运行包含一个或多个与同一逻辑任务相关的调度任务。例如,一个为期数周的 LLM 预训练作业可能包含多个不同的任务,这些任务因为抢占、中断或 Infra 异常而切分(忽略用户空间故障对 ETTR 的影响)。作业运行时间定义为多任务运行中某个任务被调度或符合调度条件但正在队列中等待的总时间。生产性运行时间为工作负载取得实质性进展的时间(比如,模型在真正训练的时间)。生产性运行时间的精确定义因上下文而异,作者认为其存在两种非生产性调度时间:1)从上次 Checkpoint 加载后的追赶时间:在最新 Checkpoint 和作业中断之间重新训练;2)重启开销:重启后需要执行所有初始化操作,这些操作在正常情况下是不必要的。这两者高度依赖具体的作业,目前缺乏可靠的大规模追踪方法,作者根据和各团队合作找那个遇到的合理值进行填充。
ETTR 的取值范围从 0(作业从未取得实质性进展)到 1(100% 的时间用于实际训练,没有排队或非生产性时间)。ETTR 类似于经典的作业延迟指标,然而,ETTR 额外考量了非生产性时间,并反转了比例,以期获得更好的可解释性。
模型浮点运算利用率(MFU):业界普遍采用的指标。对应于模型理论上利用的浮点运算次数与硬件峰值浮点运算次数的比值,MFU 可用于捕获性能下降或次优实现的情况。两者虽然不同,但是在测量运行时间与理想状态的比例方面是可比的,且都介于 0 到 1 之间,不过 MFU 往往更低,比如 LLaMA 3 在 H100 训练,MFU 只有 38%-43%,而 ETTR 可以超过 80%。
有效产出(Goodput):上述两个指标主要用于衡量每个作业,而 Goodput 可以用于衡量整个集群,即单位时间内完成的有成效工作的总量。Goodput 可以通过最大可能有效产出进行归一化,介于 0-1 之间。本文中讨论的集群在高负荷下运行(潜在 Goodput 仅受容量限制而非可用工作量),因此,任务抢占,资源碎片化和故障是 Goodput 损失的主要来源。
3.5 故障分类
故障分类是指将作业失败的责任归咎于某一原因的过程。作者的经验表明,故障归类是一个充满挑战且复杂的过程。例如,NCCL 超时现象相对常见。在 Pytorch 中,当某个节点观察到集合操作在几分钟内未完成时,将发生 NCCL timeout。这可能意味着网络问题,但也可能是其他节点因为故障未能启动相同的操作,例如,加载下一个 Step 数据时阻塞。在此情况下,超时的节点功能完好,而故障节点可能因为用户软件问题或基础设施错误而无法响应。从用户堆栈 Trace 中追溯根因,需要跨越多层次、精确的分布式日志记录,包括从 ML 应用到分布式集合通信操作以及底层 Infra 的各个方面。
因此,如下图 Table 1 所示,作者的故障分类法基于以下原则:任何给定症状可能存在多种潜在根因,限制假设空间的唯一途径是排除不太可能的原因。作者因此提出了通过故障域的差异诊断来诊断并根除错误——利用多种性能指标标记错误可能发生的区域,从而将特定故障限定于少数可能的原因。

作者的故障域涵盖用户代码、系统软件(如驱动程序、Pytorch、操作系统)以及硬件。正常情况下,用户应确保其程序无明显错误。从集群运维角度考虑,硬件错误需进一步分类为瞬态错误(如 ECC 错误、链路抖动)或永久性错误(如需要供应商维修或更换硬件)。与故障分类相关的信息追踪必须实现自动化管理(例如,通过健康检查),原因在于:1)程序与机器的配对具有不确定性;2)故障通常是罕见事件。
作者发现,拥有涵盖硬件和系统软件多个方法的丰富信息,有助于更快地确定特定症状集合的成因。在某些情况,多个同时触发的健康检查可能指向同一错误(例如,PCIe 异常可能影响 GPU)。
如下图所示,以我们的一个 Case 为例,训练时遇到过 Pytorch 抛出 CUDA error: an illegal memory access was encountered 错误:

同时查看相关系统信息发现 GPU 有 Xid 31 的错误:

进一步根据 NVIDIA Xid 文档(1. Introduction — XID Errors r555 documentation [3])可知,Xid 31 大部分为用户程序问题,比如访存越界等,但也有一定可能是驱动 Bug 或硬件 Bug:

见解 3:警惕误导性线索。具有多种潜在成因的错误难以诊断,例如,NCCL 超时错误可能被简单归咎于近因(proximal cause),比如网络问题而非死锁。网络具有更广泛的影响范围,导致可能横跨整个系统堆栈。其他错误则与特定节点硬件相关,随着其发生频率增加,可能性也随之上升,如上图 Table 1 是作者总结的分类法和相关经验。
同样以我们自己的一个 Case 为例,如下图所示,训练中可能会遇到 NCCL timeout 的错误,由于缺乏有用的信息,通常很难稳定复现这类异常,调试起来非常困难。

为了解决这个问题,常见的方式是 Fork NCCL 代码,添加相应的时间戳信息,以便更好地显示崩溃发生时正在执行的消息或操作,从而确定哪个 Node 或 GPU 可能阻塞了,如下图所示为 ImbueAI 在解决类似问题时的方案(https://github.com/boweiliu/nccl/commit/0966031bdb5905b8ea5aef3fb2a8ce6317040234)。
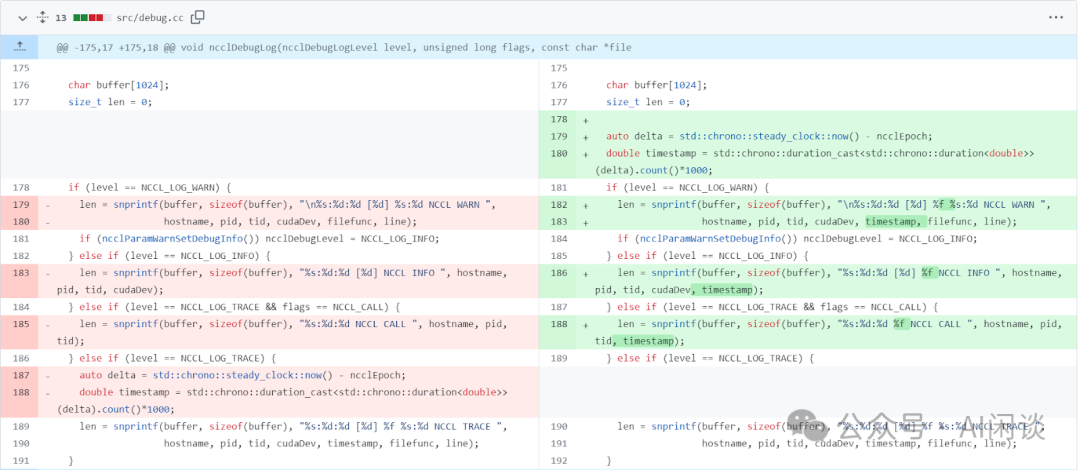
Meta 在 LLaMA 3 的技术报告(The Llama 3 Herd of Models | Research - AI at Meta [4])也提到相关的解决方案。具体来说,为了增加有效训练时间,减少作业启动和 Checkpointing 时间,LLaMA 3 作者开发了用于快速诊断和解决问题的工具。其主要是利用 Pytorch 内置的 NCCL flight recorder(参考 PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation [5]),将集合通信的元数据以及堆栈信息捕获到 ring buffer 中,基于此可以快速诊断 Hang 以及性能相关问题,尤其是与 NCCLX(Meta 的内部 NCCL 版本) 相关的问题。利用此功能,可以有效地记录每个通信事件以及每个集合通信操作的持续时间,并且可以自动将 Trace 信息转存到 NCCLX Watchdog 或 Heart timeout。也可以在生产环境中在线修改配置,以便根据需要选择性地实现计算密集型的跟踪操作和元数据收集,而无需发布代码或重新启动作业。
四、理解大型 ML 训练集群的现状
这里的分析基于上述的两个集群,涵盖 11 个月的观察数据。分析建立在 Slurm Scheduler 和前面介绍的健康检查的基础上。需要说明的是,这里讨论的集群存在过度配置现象,因此项目级的 QoS 和服务分配是决定哪些作业可以运行的主要因素。
Scheduler 作业状态细分:Slurm 作业可能处于以下状态之一:Cancelled(取消)、Completed(完成)、Out_of_Memory(内存不足)、Failed(应用返回非零退出码)、Node_Fail(节点故障)、Preempted(为更高优先级作业让位)、Requeued(重新排队)或 Timeout(超时)。如下图 Fig 3 展示了 RSC-1 集群的 Scheduler 作业状态细分。60% 的作业成功完成,24% 和 0.1% 的作业分别有 Failed 和 Node_fail 失败,10% 的作业被抢占,2% 的作业重新排队,0.1% 的作业内存不足失败,0.6% 的作业超时。
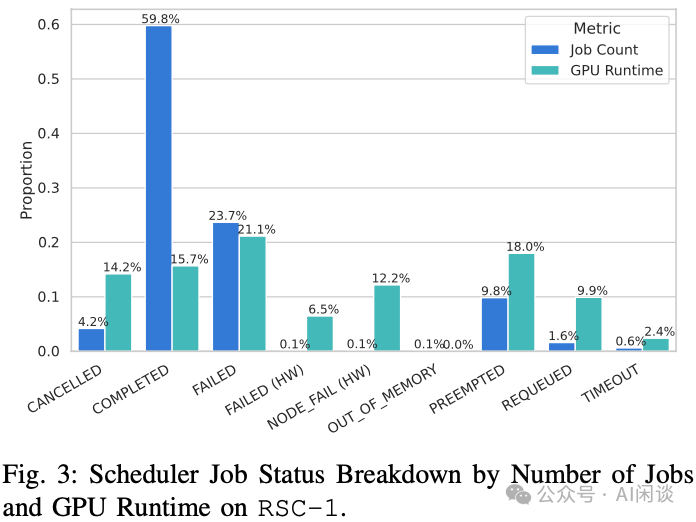
如上图 Fig 3 所示,其中 Infra 故障(HW)只影响了 0.2% 的作业,但影响了 18.7% 的运行时间。鉴于预期 Infra 故障会影响大型作业(这类作业数量很少,但占用大量运行资源),这一现象也并不意外(可以参考后文 Fig 6)。
见解 4:由于健康检查机制,硬件故障构成了一组罕见的结果。硬件故障只影响了不到 1% 的作业,但影响了 19% 的 GPU 运行时间。一旦考虑 Checkpointing 机制,这种影响显著减小,因为 Checkpointing 缓解了这种损失。
作业级故障刻画:归因于硬件的故障可根据归因进一步细分。这些原因可以按照节点级组件细分,如 GPU、网络及各种系统组件,如文件系统。如下图 Fig 4 中展示了 RSC-1 和 RSC-2 集群每小时每 GPU 的故障率。若故障原因在作业失败前 10 分钟内或失败后 5 分钟内被检测到(Failed 或 Node_Fail),则将故障归因于该原因。需要注意的是,作者根据所开发的启发式方法报告了最可能的故障原因,该方法指示节点是否应被隔离以进行相关修复。某些故障可能有多重原因。一些 Node_Fail 事件并未与任何健康检查相关联,这可能是节点本身变得无响应。其中 IB 链路、文件系统挂载、GPU 内存错误和 PCIe 错误占比最大。
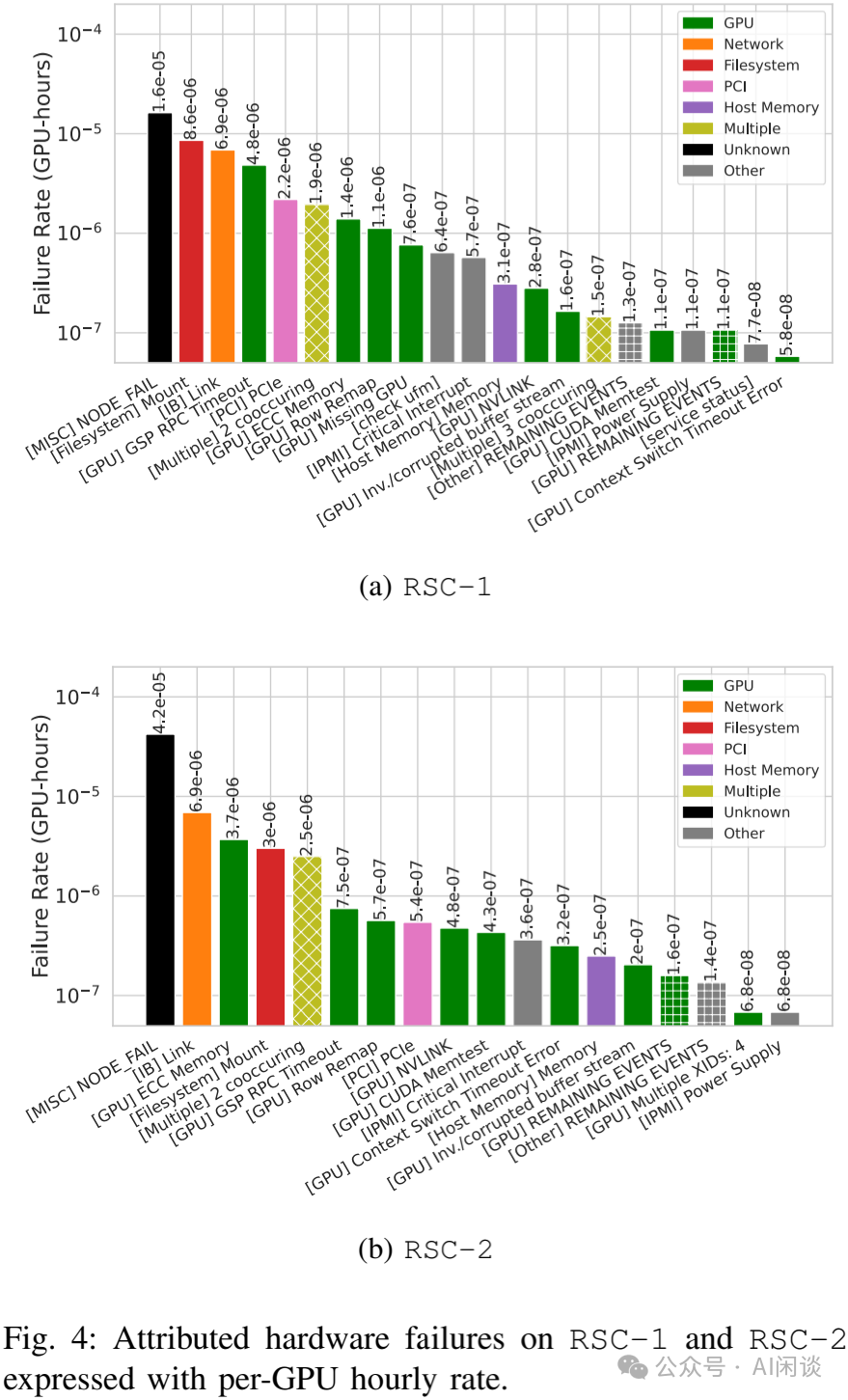
对于 IB 链路而言,似乎主要由 2024 年夏季少数节点在短时间内发生的众多 IB 链路故障相关,如下图 Fig 5 的黄色部分。其中 GSP 超时是由代码回退引起,该问题通过驱动补丁得以修复。
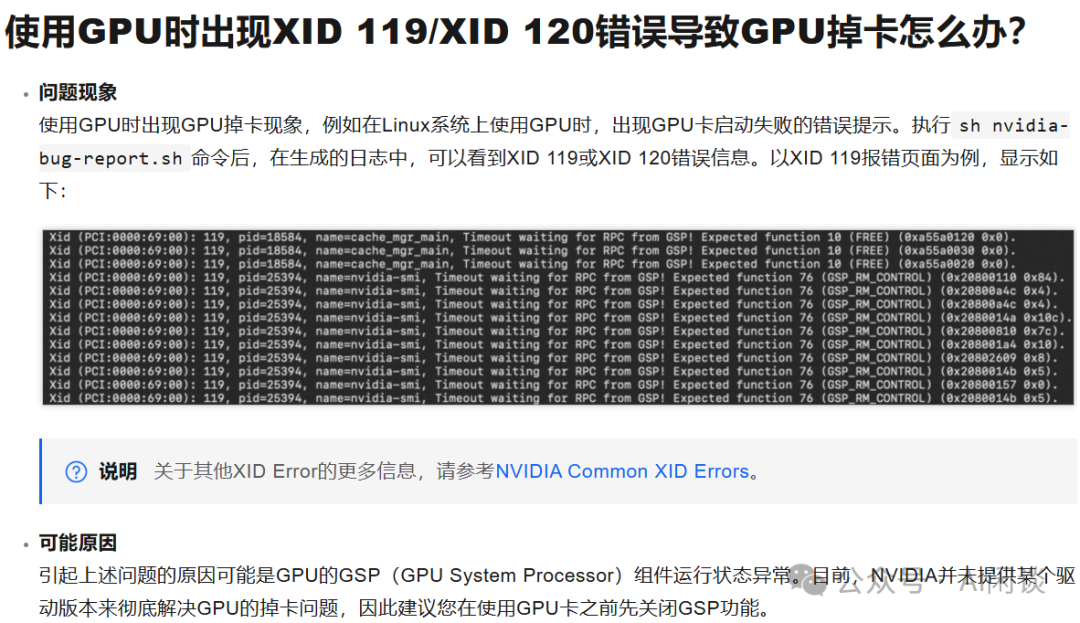
我们在 A100 中也遇到过 GSP(GPU System Processor) 相关问题,通过关闭 GSP 可以解决。阿里云的 FAQ 中也有相关介绍,如下所示,具体可以参考 ACK集群GPU使用常见问题和解决方法- 容器服务Kubernetes 版 ACK - 阿里云 [6]:
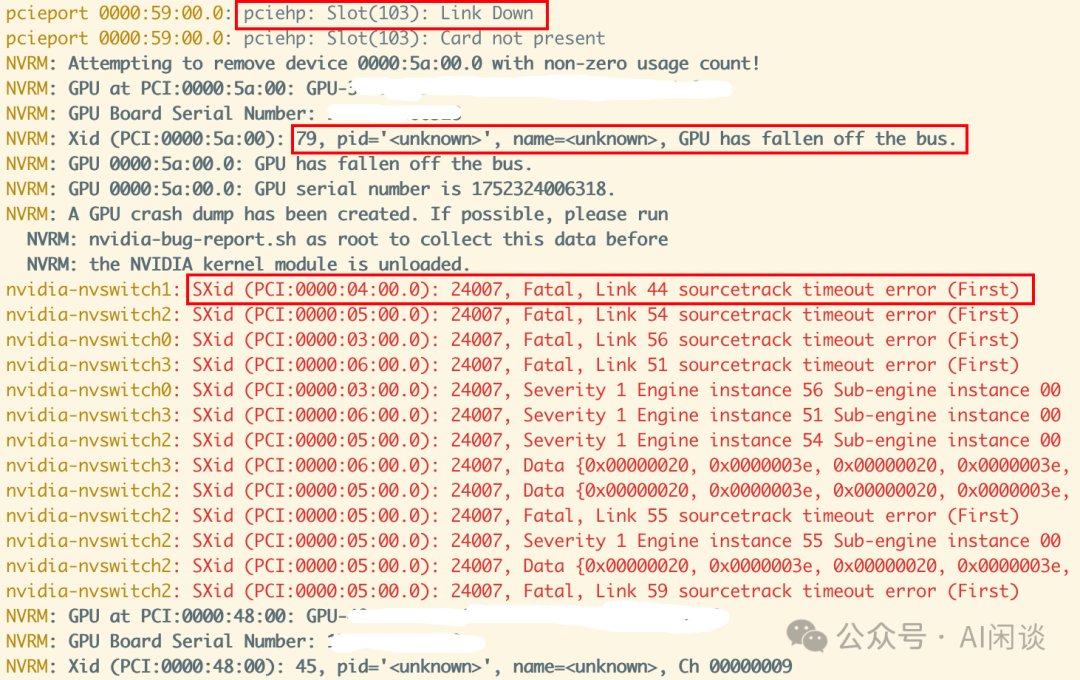
故障可能同时发生:RSC-1/RSC-2 上 3% 和 5% 的硬件故障伴随着类似优先级的共现事件,例如,作者观察到 PCIe 错误常与 XID 79(通常意味着掉卡,比如从 PCIe 总线上断开链接)和 IPMI “Critical Interrupt” 同时发生。在 RSC-1(及 RSC-2)上,作者观察到 43%(63%)的 PCIe 错误与 XID 79 共现,21%(49%)则同时包含所有上述 3 种事件类型。这是预料之中的,因为所有这些检查都与 PCIe 总线健康状况有重叠。此外,作者还观察到 2%(6%)的 IB 链路故障与 GPU 故障(如与总线断开连接)同时发生,这可能表明与 PCIe 存在关联。
同样以我们的一个 Case 为例,如下图所示,使用 Pytorch 训练时遇到 CUDA error: unknown error 的问题:

进一步排查发现系统中同时出现了 pciehp Link Down,Xid 79(GPU fallen off the bus)以及 NVSwitch timeout 的错误,与此同时还在后续出现 Xid 45 的错误,这个就是常见的掉卡问题。
其实 Xid 也经常会一起出现,如下图所示,一个 uncorrectable 的 ECC Error 往往会伴随多个不同的 Xid 同时出现:

见解 5:许多硬件故障未被归因,而最常见的故障归因于后端网络、文件系统和 GPU。GPU 有细粒度的 Xid,也有丰富的错误类别,不过主要的错误都与内存相关。PCIe 总线错误和 GPU 脱离总线也非常常见并且相关联。CPU 内存和 Host 服务对应用影响较小。
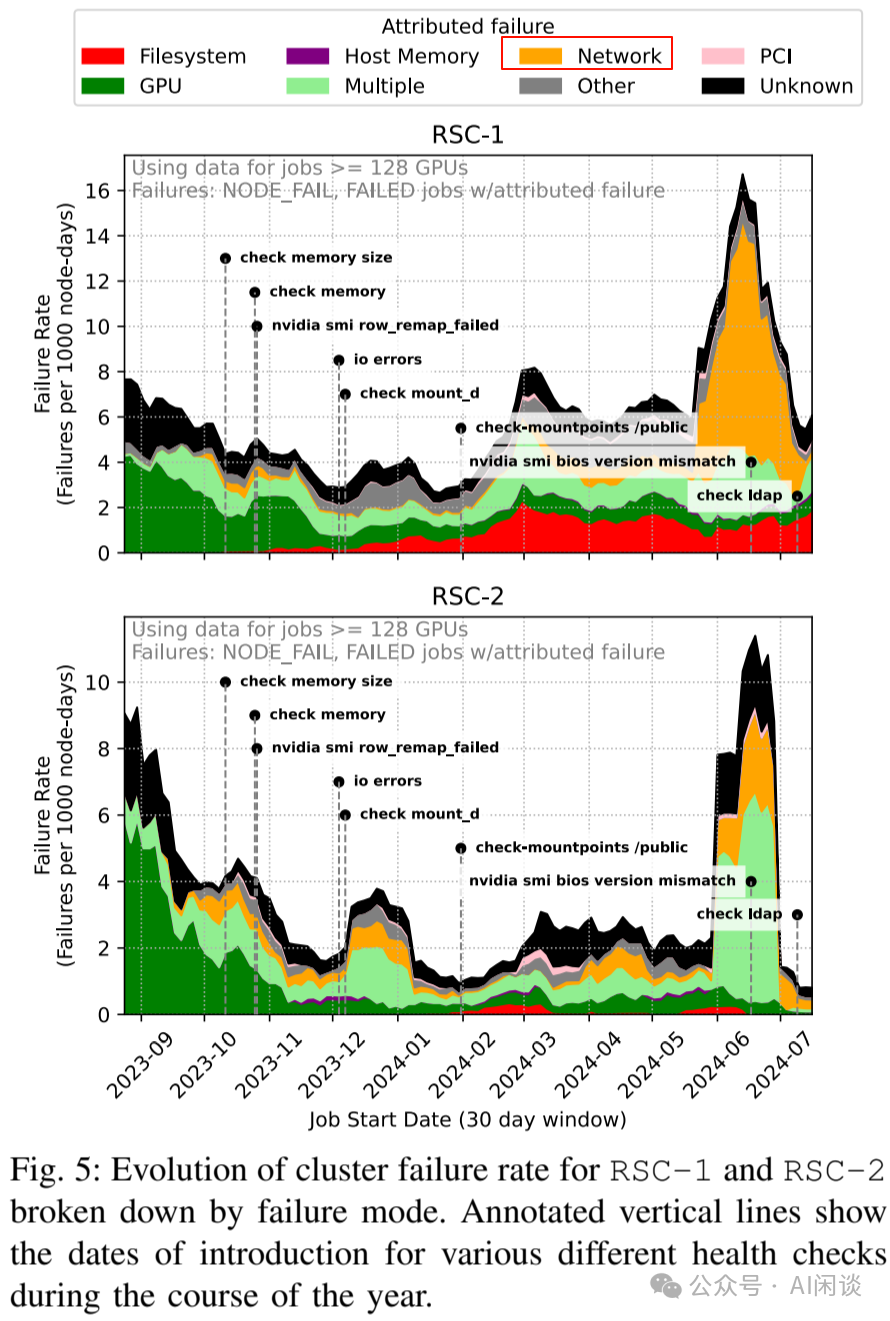
故障率随着时间演变:进一步将剖析转向更大规模的作业,相应也切换到节点级(而非 GPU 级)剖析。如上图 Fig 5 所示,作者展示了 RSC-1 在过去一年中的故障率情况,揭示了如下几点:
故障率持续波动。
故障模式起伏不定:比如 23 年末,驱动程序错误导致 Xid 错误成为 RSC-1 上作业失败的主要来源;24年夏季,IB 链路故障激增同样推高了两个集群的故障率。
新的健康检测揭示新的故障模式:图中标识了新的健康检查(之前就在发生,但未被准确识别)添加到集群的时间点,这也会导致故障率看似增加。
如下图所示,上海 AI Lab 等团队在 [2403.07648] Characterization of Large Language Model Development in the Datacenter [7] 中提到一个类似的故障,其 AI 集群在 2023.07(最热的月份) 时,机房温度升高了 5 度,导致故障率明显增加:

见解 6:集群故障具有动态性,集群故障是一场持续战斗,新的软件更新也就意味着集群在不断变化,工作负载和性能也在持续调整。
训练任务多样性:必须考虑任务规模和时间,以在整体多样性和训练 GPU 小时数之间取得平衡。Scheduler 需要权衡单个训练作业的公平性、整体集群利用率及训练性能。如下图 Fig 6 所示,描绘了 RSC-1 集群中作业规模的分布,超过 40% 的训练作业使用单个 GPU 进行开发或者模型评估,仅有少数大模型作业,比如超过 1000 GPU。在同一个图中,作者还展示了相对于单个 GPU 作业的 GPU 时长的归一化结果。虽然有众多单 GPU 作业,但是 RSC-1 和 RSC-2 中分别有 66% 和 52% 的总 GPU 时间来自 256+ GPU 的作业。
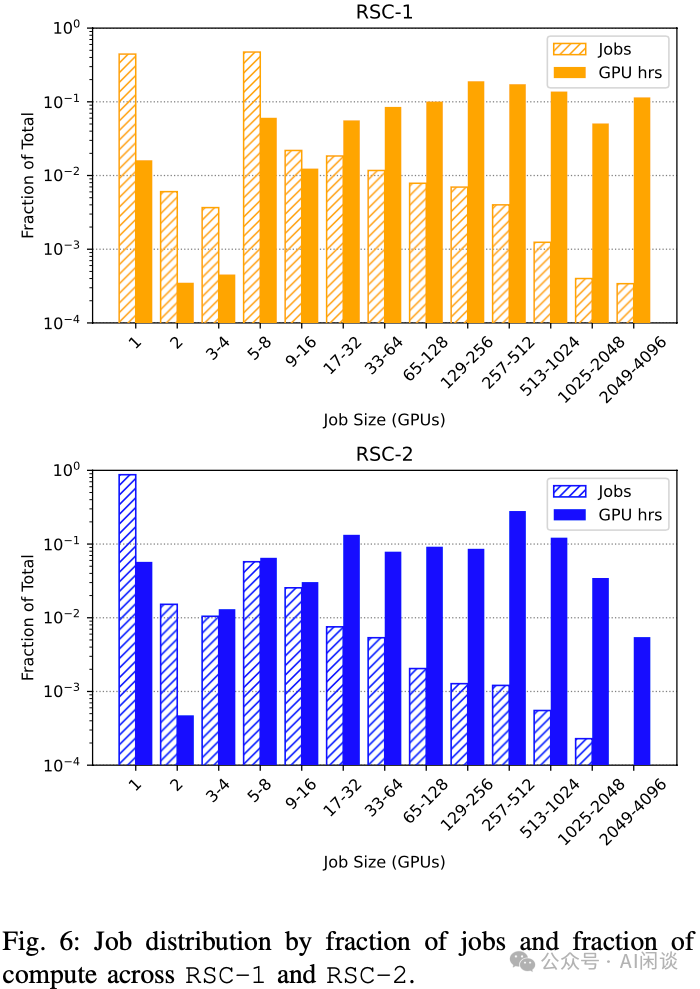
见解 7:超过 90% 的作业规模小于一台机器(包含 8 个 GPU),但仅占不到 10% 的 GPU 时间。RSC-1 集群倾向拥有更多 8 GPU 作业,而 RSC-2 则更倾向于 1 GPU 作业。RSC-1 集群往往包含规模最大的作业。
MTTF 随规模减小:如下图 Fig 7 所示,1024 GPU 作业的平均故障时间(MTTF)为 7.9 小时,比 8 个 GPU 作业(47.7 天)低约两个数量级。这也符合预期,经验上,硬件可靠性与 GPU 数量成反比,且在 32 个 GPU 以上时趋势更为一致。图 Fig 7 还展示了从集群节点故障率推导出的理论预期 MTTF(MTTF ∝ 1/Ngpus):MTTF=(Nnodesrf)-1,其中 rf 根据所有超过 128 个 GPU 作业的总故障数和节点运行天数计算,与较大作业(>32 GPU)的实际 MRRF 数据吻合:
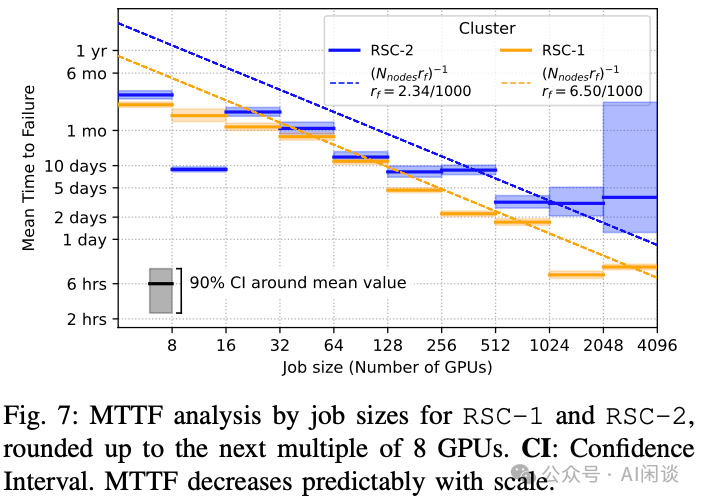
基于在上述集群中大规模训练任务所观测到的故障概率,作者预测 16384 个 GPU 任务的 MTTF 为 1.8 小时,131072 个 GPU 任务的 MTTF 为 0.23 小时。为了在故障发生时最大化 ETTR,必须加快故障检测与恢复过程。
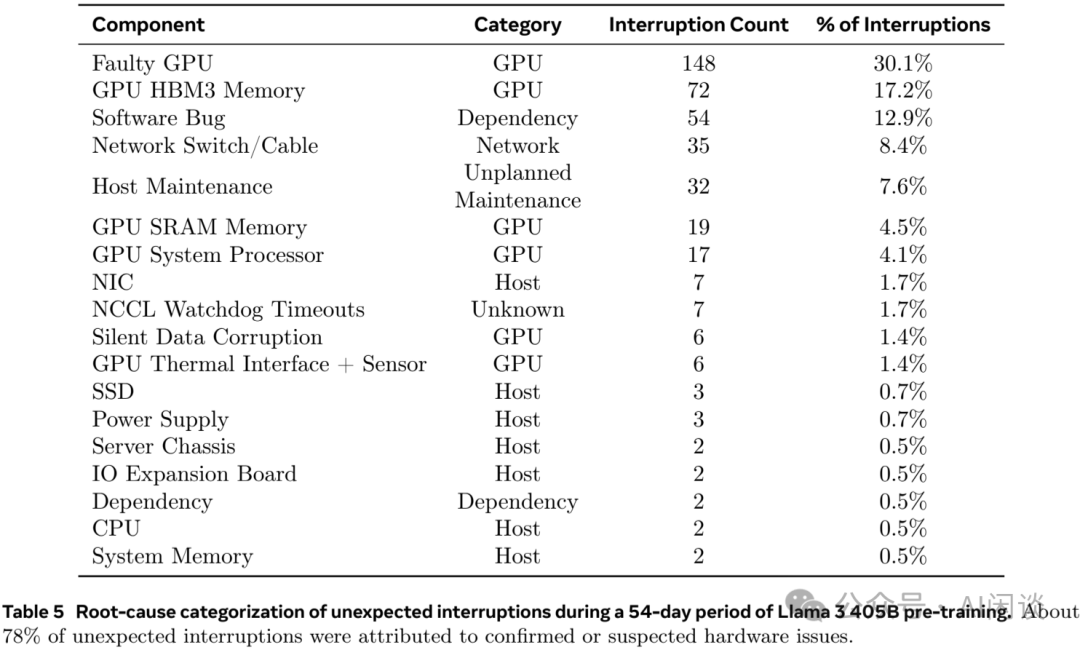
如下图 Table 5 所示,Meta 在 LLaMA 3 的技术报告(The Llama 3 Herd of Models | Research - AI at Meta [4])中也描述了相关故障率,其提到在 54 天的训练中,共遇到 466 个任务中断,包括 47 次的有计划中断,以及 419 次的预期外中断。在这些非预期中断中,78% 是硬件问题,例如 GPU 或物理机其他组件的异常,其中 GPU 相关问题占到 58.7%。其训练使用了 16384 H100 GPU,对应的平均故障时间为 54*24/419=3 小时,也就是平均每 3 小时出现一次故障。当然,组着通过自动化运维手段仍然可以获得超过 90% 的有效训练时间。
见解 8:尽管故障并不直接影响多数作业,但大型作业受其影响显著,故障率与理论趋势相符。在 4K 规模下,MTTF 约为 10 小时,并预计在 RSC-1 的更大规模下会进一步下降。MTFF 预测与 RSC-1 的 4-512 节点实测 MTTF 吻合。对于 RSC-2,预测趋势类似,但是 16 个 GPU 的实测 MTTF 数据波动较大,部分原因是一组相关任务引发多次 Node_Fail。总体上 RSC-1 和 RSC-2 趋势类似,部分差异可以归因于两个集群工作负载稍有不同触发了不同的故障。
抢占与故障级联:作业失败的次级效应之一是:对其他优先级较低且可能规模较小的作业的影响,从而导致级联效应。在实际操作中,大型作业往往具有较高的优先级,而小型作业优先级最低,这样大型作业通过抢占低优先级作业得以快速调度。当一个大型高优作业因硬件不稳定而失败时,Slurm 会重新调度该作业,在这个过程中可能抢占数百个作业。最糟糕的情况是循环崩溃,也就是配置为作业失败时重新排队。作者发现一个 1024 GPU 作业发生 Node_Fail 后重新排队 35 次,总共导致 548 次抢占,共涉及 7000 个 GPU。此类情况应尽可能的避免,不然会造成集群 Goodput 的损失。
在考虑作业失败时,抢占是一个次级效应。作者集群中,为了确保即使是最低优先级的作业也能取得进展,抢占只能在运行两个小时后发生。然而,如果没有精确的 Checkpointing 机制,作业被抢占时相应的工作进度也会丢失。关键在于,大型作业 1) 预计会损失大量工作,2) 失败频率更高,导致作业规模与 Goodput 吞吐之间呈二次函数关系。为了估计各种 Goodput 损失来源对整个集群 Goodput 的影响(包括重新调度失败作业发生的抢占),作者假设所有作业每个小时进行一次 Checkpointing,平均损失半个小时的工作量。通过 Slurm 日志可以确定相应作业 1)收到 Node_Fail(集群相关问题)或归因于硬件问题的 Failed 状态的作业,2)因引发 Node_Fail 或 Failed 而被抢占的作业,并估计损失的 Goodput(作业运行时间与 30 分钟的最小值,乘以分配给该作业的 GPU 数量)。
如下图 Fig 8 所示,RSC-1 因故障和二次抢占导致的大部分 Goodput 损失(y 轴),主要源自规模在 2K-4K 个 GPU (x轴)的大型作业。在 RSC-2 集群,由于作业构成的差异,中等规模作业占据 Goodput 损失的比例更高。此外,RSC-2 上 Goodput 损失比 RSC-1 上小一个数量级,这是作业构成和故障率差异的结果。尽管优化大型作业至关重要,但硬件故障导致的 Goodput 损失中,依然有 16% 源于二次抢占。
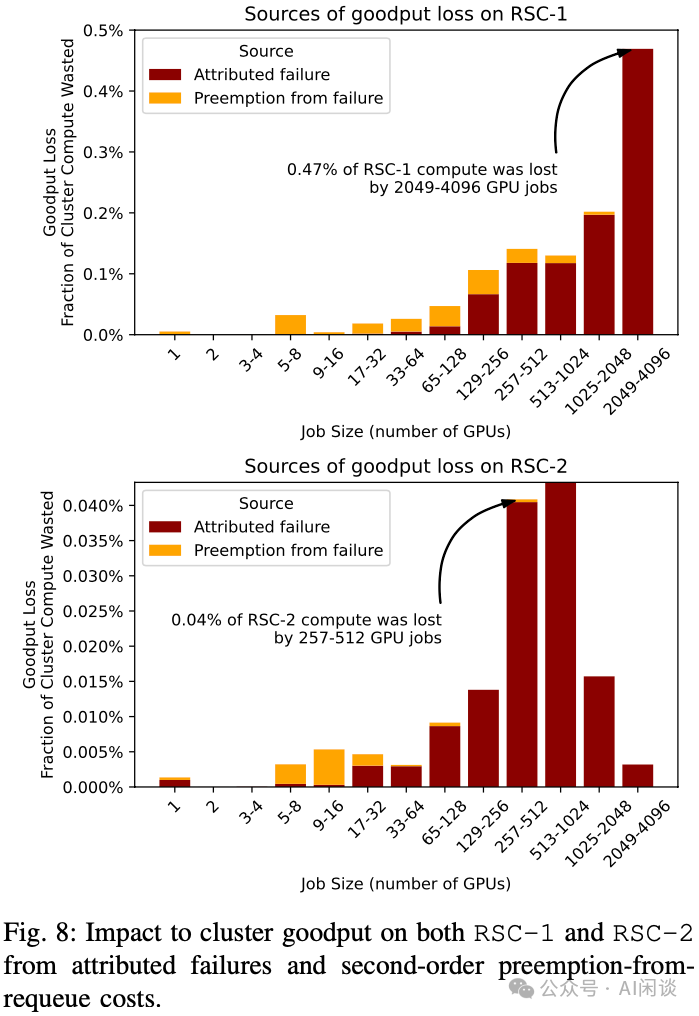
见解 9:大型、高优先级作业在故障时会使 Scheduler 产生波动。虽然 1K+ GPU 作业故障的一级效应显著,但总故障开销的 16% 来自于抢占其他作业。因此,作业多样性的增加为优化提供了额外的途径。
量化大规模训练的 ETTR:ETTR 提供了一个可解释性的指标,用于量化中断、排队时间和开销对训练进度影响的程度。理解 ETTR 如何随着配置、调度及故障等不同因素的变化而变化,有助于评估各种措施的影响规模。
这个部分,作者提供了:
基于作业训练参数、作业优先级和集群资源可用性作为输入的 ETTR 期望值公式。这里,公式通过假设 Checkpointing 频率和重启开销,使得能够模拟作业的可靠性特征。需要注意的是,期望 ETTR(E[ETTR]) 对于较长的训练最为有效——根据大数定律,较长的训练趋向于使观测到的 ETTR 值更接近这一期望值。利用对期望 ETTR 的解析公式,可以帮助快速估算并理解优化措施的影响,例如将故障率减半的影响是什么?
利用作业级数据对 RSC-1 和 RSC-2 集群进行 ETTR 估计的设计空间探索研究。继续使用先前的参数作为工具,探索不同因素对作业开销的相对重要性——探讨在之后大规模 GPU 训练中,实现合理 ETTR(>=0.90)所需的必要条件。
解析近似 E[ETTR]:首先,定义 Q 为符合调度条件但处于排队等待的作业的时间,R 为有效运行时间,U 为无效运行时间。总时间为 W=Q+R+U。Checkpointing 之间的间隔为 Δtcp,初始化任务所需时间(如加载 Checkpoint)为 u0,提交后及每次中断后的期望排队时间为 q(假设排队时间服从独立正态分布 i.i.d,且在遭遇中断后并未系统性地缩短)。作业需要的节点数为 Nnodes,集群故障率 rf 表示每节点、每天内预期发生的故障次数。如下图所示可以得出期望 ETTR 的解析公式:

对于 RSC 集群,每个 GPU 节点(8 GPU)每天的故障率 rf 约为 5x10-3,tcp 约为 1 小时,也就是 0.04 天,u0 约为 5-20 分钟,而 (Nnodesrf)-1 >= 0.1 天。与预测各种期望值的蒙特卡洛方法相比,即便对于大型、长时间运行的假设性任务(例如 8000 GPU),上述近似值的误差也在 5% 以内。
与实际作业对比:作者将上述期望值公式与两个集群上实际作业的观察结果进行了比较。一个作业运行多个任务(可能具备不同的任务 ID),它们都属于同一训练作业。假设 Δtcp 为 60 分钟,u0 为 5 分钟。这里重点关注总训练时间为 24 小时的长时间作业,并针对以最高优先级运行的作业,以理解最高优先级作业的 ETTR。需要说明的是,这里计算作业 ETTR 时,不考虑健康检查,并且假设每个作业都因基础设施故障而中断,意味着对 ETTR 的数据估计应为低估。
为了获取计算 E[ETTR] 所需的机器级故障率 rf,作者将所有使用超过 128 个 GPU 且被标记为 Node_Fail 状态的作业以及那些因关键健康检查在作业最后 10 分钟(或完成后 5 分钟内)触发而状态变为 Failed 的作业,均计为故障。然后,将故障次数除以节点运行天数(节点运行天数乘以节点数的总和)。作者发现,RSC-1 的 rf 为每千节点日 6.5 次故障,而 RSC-2 的 rf 显著低于 RSC-1,为每千节点日 2.34 次故障。这一发现通过观察集群中 GPU 的交换率也可以得到印证,RSC-1 的 GPU 交换率为 RSC-2 的 3 倍。GPU 交换率和故障率的差异可能源于 RSC-1 上更为繁重的工作负载。
ETTR 结果分析:如下图 Fig 9 展示了作者的研究结果。除较小任务(< 64 GPU)外,E[ETTR] 与实际测量的任务运行平均 ETTR 相吻合,在 RSC-1 上,超大任务(> 1024 GPU)的 ETTR 高于 E[ETTR] 预测值(>0.9),原因在于这些大型任务运行的实际等待时间小于平均值。
在假设情景中,若 RSC-1 集群用于单一 16,000 GPU 训练任务,占据整个集群,60 分钟 Checkpointing 间隔下的期望 ETTR 为 0.7,缩短为 5 分钟 Checkpointing 间隔,期望 ETTR 增至 0.93,凸显了频繁 Checkpointing 对抵御中断的价值(PS:假设 Checkpointing 写入为非阻塞,可以通过异步、分布式存储实现,当前很多框架已经提供该能力)。
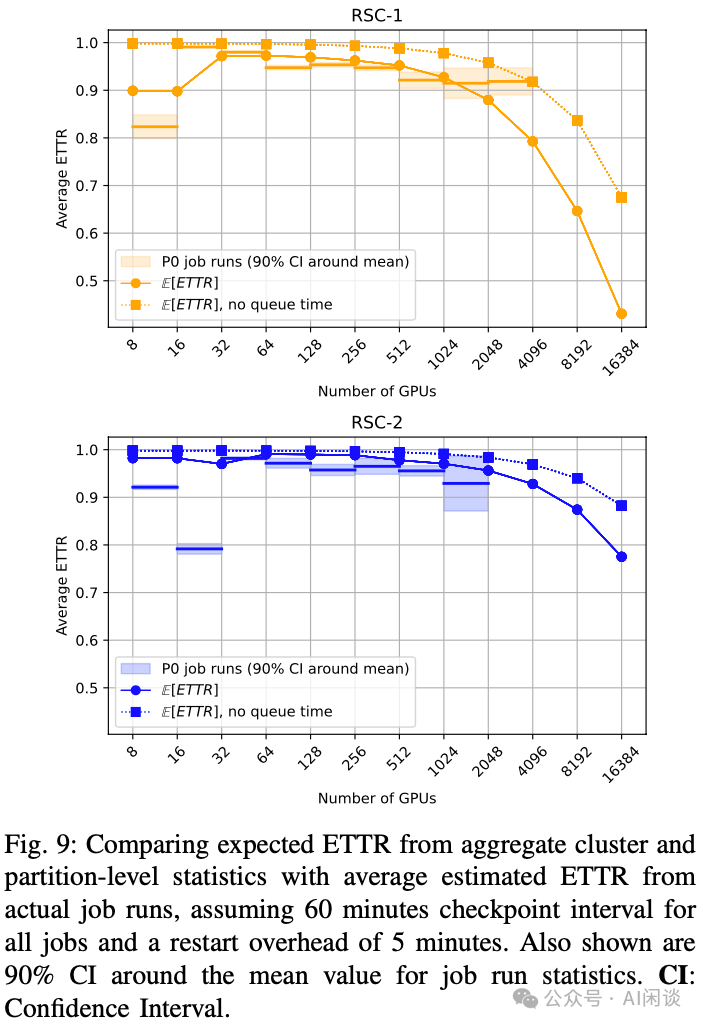
展望未来:对于未来需要 O(105) GPU 的其他集群,基于类 RSC-1 故障率(每千节点日 6.50 次故障)推导的 MTTF 为 15 分钟。这意味着 1 小时的 Checkpointing 间隔不可行。如图 Fig 10 展示了故障率与 Checkpointing 间隔的权衡,例如,对于类 RSC-1 故障率,需要 7 分钟的 Checkpointing 间隔才能实现 E[ETTR]=0.5,若故障率接近 RSC-2,则需 21 分钟。在类 RSC-2 故障率下要达到 E[ETTR] 0.9,需 2 分钟的 Checkpointing 间隔和 2 分钟的重启开销。
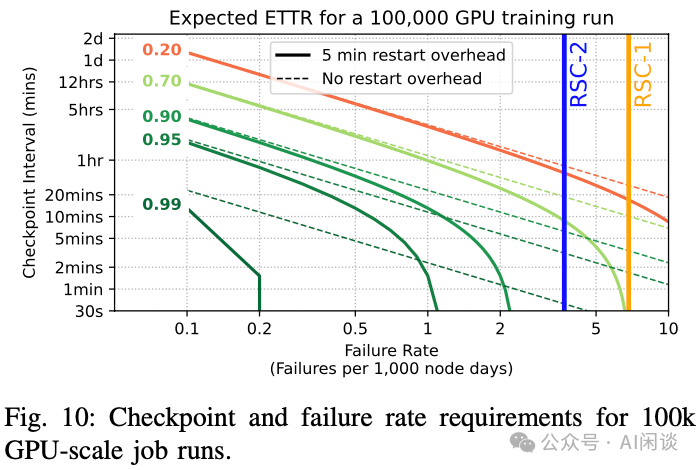
见解 10:RSC 集群对最大及最高优先级作业极为高效(ETTR > 0.9)。尽管 RSC-1 集群资源紧张且共享,在其上运行 2048-4096 GPU 且超过 1 天的作业,假设 1 小时的 Checkpointing 间隔,可以实现 ETTR 超过 0.9。若每次故障后的排队时间为 1 分钟, Checkpointing 间隔为 30 分钟,在 RSC-1 上可以实现最大可行训练(8,000 GPU,占 RSC-1 一半资源)ETTR 达到 0.9。在假设具有类 RSC-2 类故障率的集群上进行 100,000 GPU 训练时间,要达到 ETTR 0.9,Checkpointing 间隔和 Restart 开销需要为 2 分钟。(PS:如上所示,Meta 在 LLaMA 3 技术报告中也提到,其 LLaMA 3 在 16K H100 GPU 集群实现了 90% 的有效训练时间)
五、提升集群稳定性和效率
这个章节作者介绍了为提升集群可靠性所实施的缓解措施。健康检查只是其中之一,尤其擅长发现随机节点故障。然而,故障可能与特定节点(作者称为 lemon node)相关联,这可能是由于配置错误,老化或硬件缺陷所致。因此,健康检查工具也可以用以识别反复出现问题的节点。此外,作者也将其拓展到节点外,包括针对网络路由不可靠时的网络层缓解措施。最后,作者也概述了集群设计和工作负载本身如何影响集群级指标。
5.1 识别和修复故障节点
尽管健康检查机制在初始阶段可以帮助避免同一故障导致多个作业失败的情况,实践中作者也发现某些节点的作业失败率显著高于平均水平。因此,可以怀疑硬件可能正在退化或节点运行了错误配置的软件。遗憾的是,快速识别此类节点非常困难,需要长时间观察其故障行为以获得统计显著性。更糟糕的是,这些节点失败恢复后仍会导致新作业的不断失败,最终导致作业失败并延长整体恢复时间。
在存在故障节点的情况下,无论是由于训练集群中不同硬件组件的瞬时或永久性故障,研究人员通常会根据过往经验手动排除导致任务失败的节点。然而,这种做法难以扩展,且过度排除节点可能导致容量枯竭。
为提升 ETTR,作者设计了 lemon node 检测机制,以主动识别、隔离并替换 lemon node。lemon node 是指那些反复导致作业失败但无法通过现有健康检查和修复流程识别的节点。如前所示,导致训练作业失败的最重要因素之一是节点故障(Node_Fail),这凸显了主动处理 lemon node 的重要性。
lemon 检测信号:在每个节点上可用的数十种检测信号中,以下几种与 lemon node 最相关,尽管报告的结果是基于预测 lemon node 准确率和误报率人工调整的,依然可以将这些信号视为二分类模型的潜在特征。
excl_jobid_count:驱逐节点上的作业数量。
xid_cnt:节点上单一 Xid 错误数量。
tickets:为某节点创建的修复工单数量。
out_count:节点从 Scheduler 中移除的次数。
multi_node_node_fails:由单节点引起的多节点作业失败次数。
single_node_node_fails:由节点引起的单节点作业失败数量。
single_node_node_failure_rate:节点上单节点作业失败的比例。
如下图 11 所示,展示了基于 RSC-1 的 28 天数据快照信号分布情况,可以据此设定检测标准的阈值。x 轴表示每个 GPU 节点信号出现的归一化次数。y 轴表示经历每种信号的 GPU 节点的累积数量,同样进行归一化处理。作者发现,excl_jobid_count 信号与节点故障之间并无显著相关性,大量节点因至少一个作业而被排除。这促使作者主动检测 lemon node,而非将其留给用户。超过 85% 的已识别 lemon node 在某一测试中失败,失败类型详见 Table II。
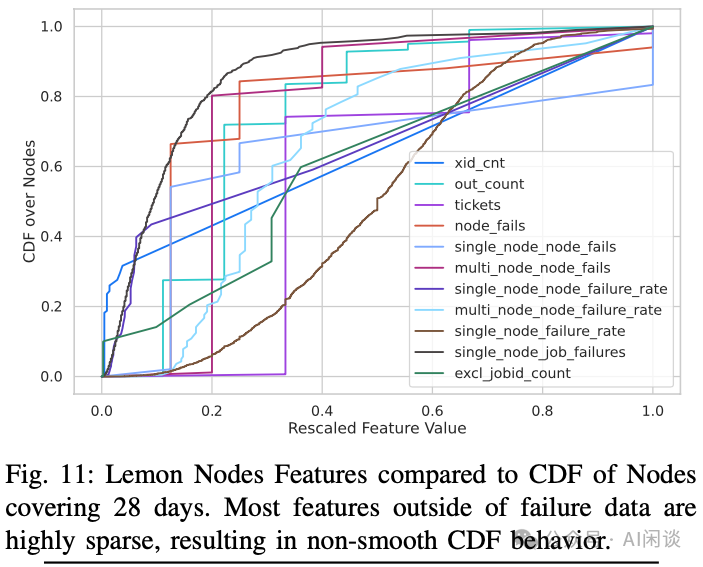

作者设计、实施并评估了 lemon 检测机制,成功识别出 RSC-1(24 个节点)和 RSC-2(16 个节点)中的 40 个故障节点,准确率超过 85%。这些被识别的 lemon node 占 RSC-1 总规模的 1.2%,每日作业的 13%。这种 lemon 检测机制使得大规模作业(512+ GPU)的失败率降低 10%,从 14% 降低至 4%。
见解 11:历史数据对于识别缺陷节点至关重要。实施 lemon node 检测技术可将大型任务完成率提升超过 30%。
5.2 通过自适应路由增强网络结构韧性
故障特征分析揭示了 IB 链路错误引发的故障的重要性。正如节点可能在不同阶段由于瞬时或永久性组件退化而异常,网络链路也可能因物理或电气特征的变化而表现出类似行为。大规模并行模型训练不可避免会遭遇故障链路,这些链路可能具有高错误率、在上下行状态间频繁切换的抖动行为、永久性断开或在高密度租户环境中出现严重拥塞。所有这些情况都会导致跨节点的通信性能下降。
大规模物理链路更换操作繁琐,因此 IB 网络结构配备了交换机级别的链路问题容错技术,其中一种自我修复技术称为 SHIELD,允许交换机在链路故障时进行协调。然而,即使启动了此功能,将链路视为断开的阈值可能过于保守,导致协议层面的重传及潜在的网络性能下降。特别是在 RSC-1 的启动阶段,作者观察到了 50%-75% 的带宽损失。
另一种更为先进的功能是自适应路由(AR),它根据实时网络状况动态调整路由决策。AR 平衡了所有网络链路上的流量,提高了整体链路利用率。通过允许数据包避开拥塞区域和不健康链路,自适应路由提升了网络资源利用率和效率,从而减少因网络问题导致的训练作业性能波动。作者在集群中启用了 AR 以提升性能的可预测性。
为了展示 AR 在作者集群中的重要性,作者进行了两项实验。
第一个实验中,使用 mlxreg 工具修改网络中的端口寄存器,引入位错误(BER)。随后,针对 512 GPU,在启用与未启用 AR 的情况下,运行 nccl-tests 中的 AllReduce 基准测试。如下图 Fig 12a 所示,在链路错误条件下,AR 能够维持更高的带宽。
第二个实验中,在 64 个节点上分组进行 AllReduce 的多轮迭代,每组包含两个节点(16 个 GPU),以展示 AR 在资源竞争环境下的表现。如下图 Fig 12b 所示,网络中充斥着多个 NCCL 环路时,使用 AR 的性能波动较小,且 AR 能实现更高的性能。这是因为 AR 能够保护 GPU 免受拥塞链路的瓶颈效应。通过使用交换机根据端口负载选择的输出端口,AR 将不良链路的影响分散到各个任务中,而非仅惩罚恰好映射到这些不良链路的训练任务。
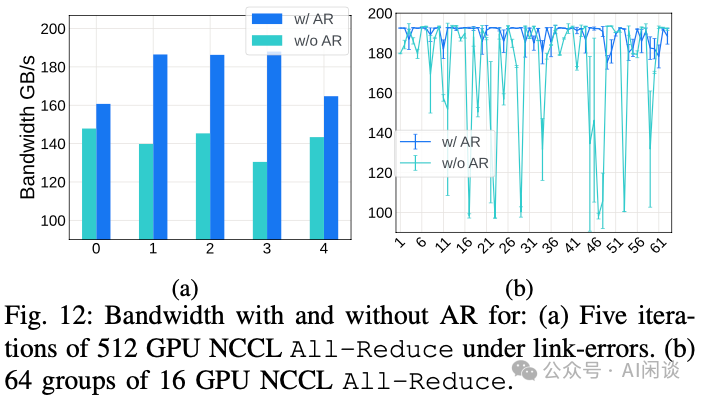
见解 12:网络必须具备故障排除和绕行能力,若缺乏弹性机制,可能会损失超过 50% 的带宽。
六、关键教训和研究机会
在介绍了集群运维和优化方面的经验后,作者认为有多个机会可以提升可靠性、管理日益增长的 Infra 复杂性,并与框架和算法共同设计解决方案。
训练可靠性:作者展示了如何通过运行监控检测和历史分析来发现瞬态故障,这些故障阻碍了可靠性的保障;作者也介绍了 lemon node 检测,通过移除 lemon node 可以将大型作业完成率提高 30%。展望未来,也看到了进一步给 Scheduler 和分布式算法暴露可靠性信息的重要机会,以便工作分配可以最大化可靠性和 Goodput。此外,作者也注意到网络结构本身在弹性方面的潜在改进机会,例如,能够重新调整拓扑以绕过故障,这也与上述的 AR 部分相对应。因此,作者设想未来的 Infra 系统应试图使不可靠不那么明显,而不是试图完全消除。此外,当未来的 GPU 系统,比如 NVIDIA GB200,将修复单元从单个节点转为整个机架时,可能需要重新思考整个系统。
更接近应用层面:训练作业的预期训练恢复时间是与故障相关的延迟开销的函数。提高 ETTR 的有效方式之一是尽量减少重启延迟成本,同时降低重启的概率。如之前工作(字节 [2402.15627] MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs [8])介绍,像 NCCL 初始化等操作可能会随着 GPU 节点数量的增加而表现不佳。因此,未来的软件系统支持快速且可靠的程式(优化重启的延迟开销)显得尤为重要。作者认为,完全替代类似 MPI 的集合通信机制以及提升硬件预检测效率等措施将成为未来的关键发展方向。
调试工具:在通过健康检查排除大量且显著故障后,剩余的故障通常表现为近端故障,这些故障并不立即提示根本原因。NCCL 超时是此类故障中最常见的症状之一,其根本原因可能涉及网络基础设施、有缺陷的模型代码或其他组件。
定期检查硬件基础设施的健康状况可以帮助主动发现网络或硬件问题,减少 NCCL 超时的频率,这样这些问题可以在表现为 NCCL 内核卡住之前就被发现。然而,识别剩余超时的根本原因则需要引入新的健康检查或进行错误修复。通过回溯性识别 NCCL 超时的根本原因,可以提高训练的成功率,比如,通过比较参与集合通信的不同 Rank 记录的数据来实现。例如,记录每个集合通信的启动 Rank 及其之间的关系,可以找到某些 Rank 启动而其他 Rank 未启动的第一个集合通信操作,并进一步调查缺失的 Rank。如果所有集合通信 Rank 都进行通信但未退出,可以进一步检查集合通信内的网络流量,以识别哪个组件未发送或接收预期的 Message。从未来的作业中删除所有有问题的 Rank 或网络组件,将降低这些作业遇到相同问题的可能性。为了实现高效且可靠的大规模分布式训练,需要更完善的诊断和调试工具。可以扩展现有的管理工具,如 IPMI,以通过带外网络提供机器调试信息,并缩小归因差距。
编程模型:诊断 NCCL 超时的一个复杂因素是 Pytorch 中实现的 SPMD 编程模型,如果不同 Rank 意外的以错误顺序发出集合通信指令,如 AllReduce,任务将陷入死锁,导致 NCCL 超时。因此,调试 NCCL 超时的第一步是确定训练脚本是否存在缺陷,这为追踪 Infra 的不稳定性增加了复杂性。动态检测错误程序并引发异常而非死锁,有助于提升系统稳定性。或者,可以完全消除集合通信操作不匹配的可能性,例如,Pathways 引入了单一的通信调度入口,确保每台机器的通信调度一致。
七、参考链接
https://arxiv.org/abs/2410.21680
https://slurm.schedmd.com/overview.html
https://docs.nvidia.com/deploy/xid-errors/index.html
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
https://pytorch.org/assets/pytorch2-2.pdf
https://www.alibabacloud.com/help/zh/ack/ack-managed-and-ack-dedicated/user-guide/gpu-faq#55a6b327214cg
https://arxiv.org/abs/2403.07648
https://arxiv.org/abs/2402.15627
-
国产千卡GPU集群完成大模型训练测试,极具高兼容性和稳定性2024-06-11 5637
-
HarmonyOS官网上线“稳定性”专栏 助力更稳定流畅的鸿蒙原生应用开发2025-02-17 155
-
高精度压力测量器:国产万分级精度零点稳定性和满量程稳定性能应用场景分析2025-10-28 447
-
阿里巴巴测试环境稳定性提升实践2018-03-07 5079
-
如何提高lwip的稳定性?2019-07-09 4184
-
运放稳定性的标准及测试2021-04-06 4721
-
浅析环路稳定性原理与DCDC Buck环路稳定性2021-11-17 3101
-
电感的稳定性2009-08-22 1990
-
什么是热电偶稳定性?如何检测热电偶稳定性?2019-12-31 3589
-
怎么分析电路的稳定性?2023-09-17 4147
-
热稳定性科学:确保反向偏置二极管的最佳性能2023-09-26 634
-
摩尔线程、无问芯穹合作完成国产全功能GPU千卡集群2024-05-27 1618
-
万卡集群解决大模型训算力需求,建设面临哪些挑战2024-06-02 7613
-
反射内存卡是如何保障数据传输的稳定性的2024-11-14 1395
-
库存平台稳定性建设实践2024-12-11 1414
全部0条评论

快来发表一下你的评论吧 !
