

基于 Flexus X 实例云服务器的评测 - 大模型对比评测
电子说
描述
大家好,我是雄雄,欢迎关注微信公众号:雄雄的小课堂
@TOC
写在前面
华为云 828,领 8280 元上云礼券,买高性能服务器!!!
这不,手里就拿到了一台 4 核 12G,10M 的 Flexus X 实例云服务器,拿到后,就想着测测它的性能,看看有没有官网说的那么神奇!!!
官网的活动地址在这里,领 8280 元券:点我查看
服务器配置情况
下面,简单的给大家看看我手里的这台服务器的配置,做个铺垫,待会儿给大家上大招!!!
cpu 的情况
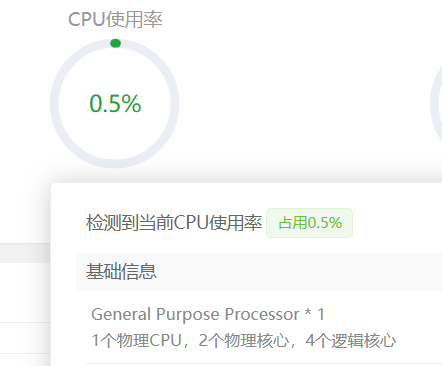
内存情况
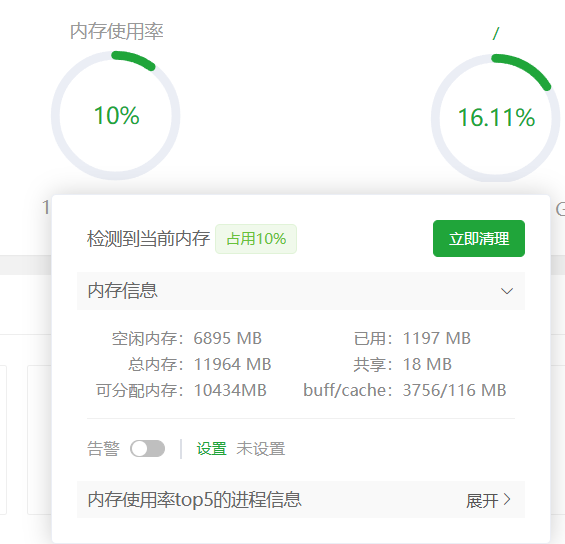
硬盘情况
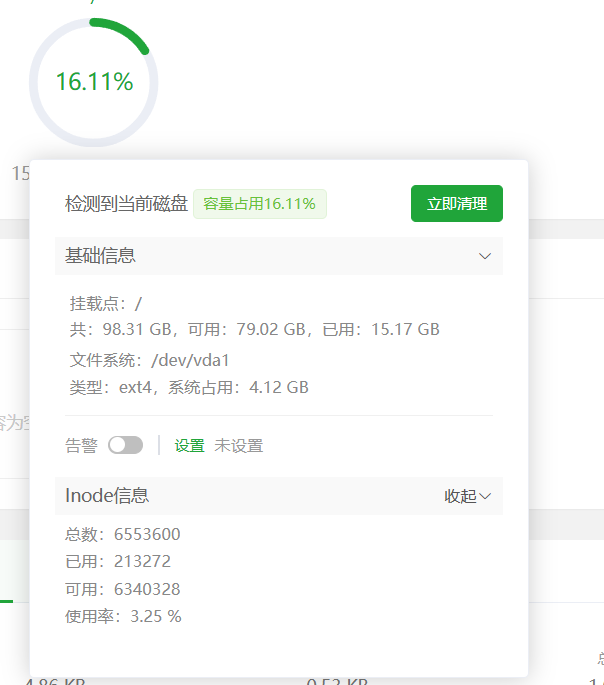
拿到服务器后,我不想再装环境上浪费时间,所以就安装了个宝塔,这个面板在服务器中,占不了多少内存,但是方便了装环境,不用执行装环境的命令,只需要在软件商店中,找到需要安装的软件,点击后面的安装即可。
评测之前环境准备
在正式评测之前,我们需要准备以下环境:
1. docker,不会安装的可以自行百度
2. ollama,这个也很简单,执行个命令就完事儿了
假使我们这两个环境现在在云服务器上都安装成功啦。
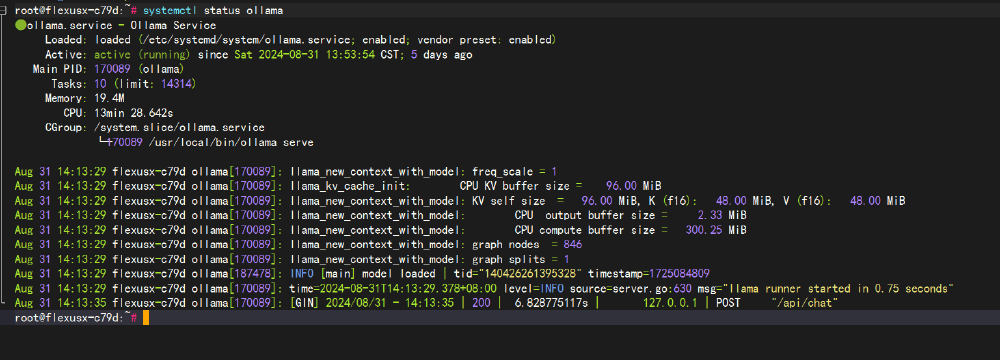
那么,现在我们开始正式评测!!!
华为云 Flexus X 实例大模型评测
下面,我们开始基于华为云的 Flexus X 实例云服务器评测一下大模型,因为我们现在还不知道这款服务器能跑多大的模型,所以我们就先从小模型开始跑。
先来个小模型,下面我们可以直接使用 ollama 开始跑模型,大家进入 ollama 的官网,点击右上角的 model 菜单:
然后就能看到下面所有 ollama 支持的大模型啦。
找到 qwen2,我们可以看到下面的 tag 里面分别有:0.5B,1.5B,7B,72B,这几种。
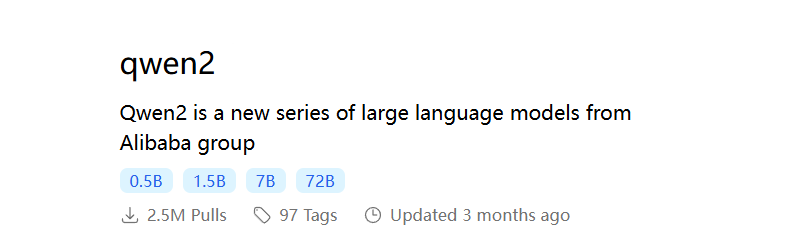
千问 0.5B 大模型
下面,我们先以最小的为例,试试看看:(注意,模型的质量我们暂且不管,我们只评测响应速度以及 CPU 和内存的占用情况)
占用情况以宝塔面板上的统计图为例,待会儿给大家截图。
执行下面的命令,开始跑 0.5B 的大模型:
ollama run qwen2:0.5b
运行情况如下:

占用情况如下:
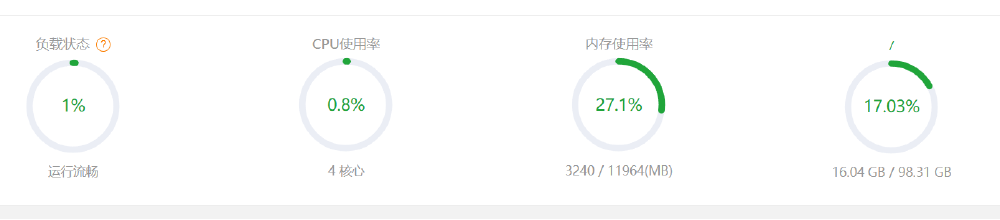
结论:0.5B 的大模型,可以看到,这个速度快的惊人,没说的,继续测下个大模型。
千问 1.5B 大模型
这次我们测 1.5B 的大模型,比 0.5B 的多 1,看看这款 Flexus X 实例云服务器的表现怎么样。
同样,执行下面的命令:
ollama run qwen2:1.5b

这里需要等待半天,让下载。
下载过程中,我们可以看看宝塔上的内存和 CPU 的占比情况。
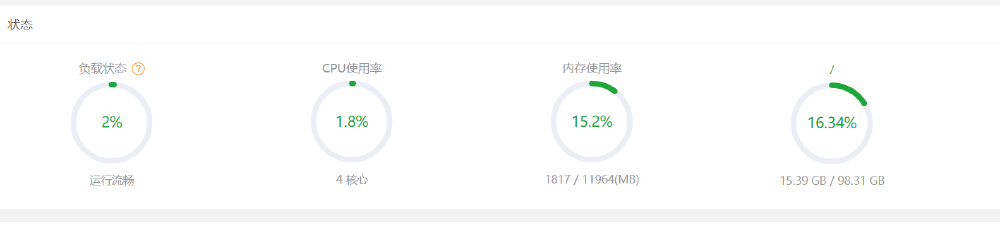
基本上毫无压力,继续等待!!!
等待的过程有点漫长.....

开测!!!

看看占用情况:
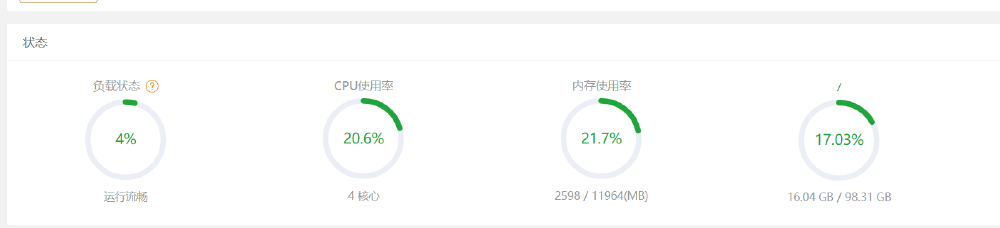
结论:比较完美,感觉和 0.5B 的区别不是很大,就是下载的时候慢了点,整体表现很棒。
gemma2 的 2b 大模型
0.5B 和 1.5B 的我们都测试过了,大家也可以从上图中看的出来,一点压力都没有,响应速度也很快,嗖嗖的就回答完毕了,质量也还行,而且最主要的是服务器的性能完全是过剩的,没跑满,所以,我们接着加大力度测试。
现在我们测测 gemma2 的 2b 大模型,运行如下命令:
ollama run gemma2:2b
又到了等待的过程中了,总是这么漫长~

在下载模型的过程中,我们可以看看占用情况:
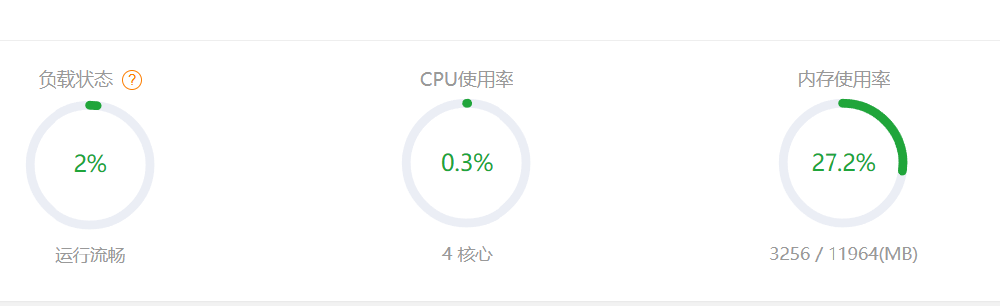
一点问题都没有,几乎没有占多少,现在我们继续等待。

等待完毕,开始问个问题测试一下:
效果展示情况:

资源占用情况:
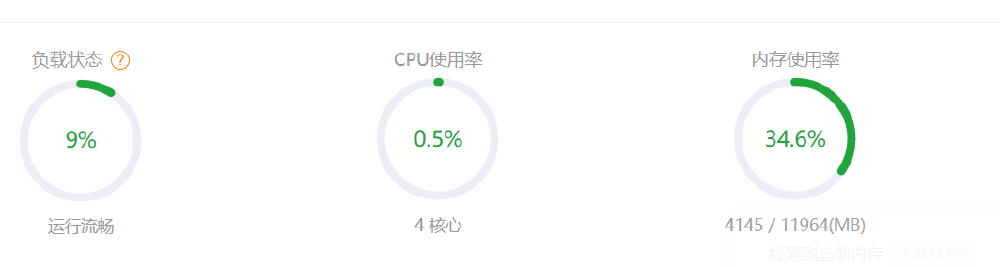
结论:通过效果图 gif 中可以看的出来,响应要比 1.5B 的稍微慢了点儿,但是这个速度还是可以接受,不过内存占用稍微偏高了,由原来的 27 增加到了 34,倒是也能接受,毕竟模型的大小由原来的 900 多 M 到现在的 1.4G 了。
千问 7B 大模型
现在,我们继续增大模型,看看表现效果怎么样。
这次我们测一下千问的 7B 大模型,这是 2B 的 3 倍多,看看这款 Flexus X 实例云服务器跑 7B 的模型是个什么情况。
同样,执行下面的命令:
ollama run qwen2:7b
继续等待:

7B 的模型,已经到了 4G 多了,期待他能有个很好的表现。
现在是:2024 年 9 月 6 日 00:02:43,我的 7B 大模型还在下载中,已经困的不行了....

再等等....

终于等它下载完啦,一共 4.4G,等的我都快做梦啦。切记,如果有大文件上下传的场景,买服务器的时候一定要选择个大带宽的,我的这个是 10M 的带宽,感觉遇到大文件了,还是有点不足。
下面我们开始进行评测,首先还是老规矩,先运行看看效果:

资源占用情况:
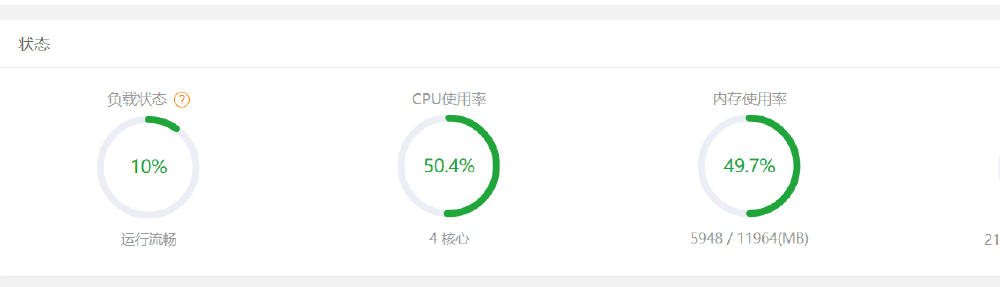
结论:大家可以看看效果图中,可以发现,很明显,相比起 2B 1.5B 的这种小模型来比,7B 的模型,在响应方面确实是稍微慢了点儿,但是也没有慢到一个字一个字的往出蹦,还是可以接受的。资源占用情况的话,CPU 占用上升到了 50.4% ,内存在原来的 34 增加到了 49。也没有跑满服务器。
总结
先放一张各个大小的模型之间的对比吧,从 0.5B,到 1.5B,再到 7B,以及 72B。
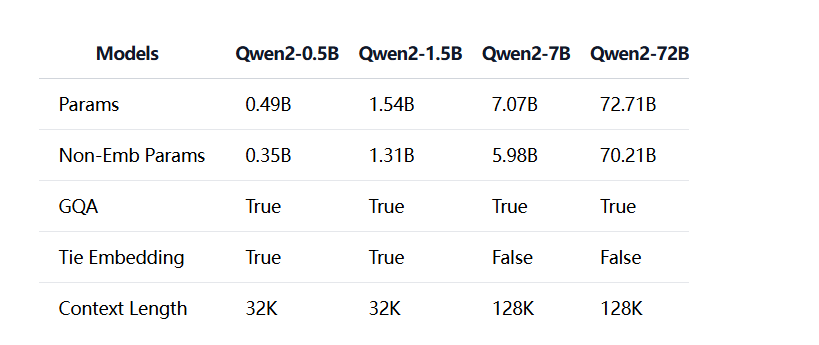
大家可以从上图中看的出来,模型越大,params 就越大,本文我们通过对 0.5b,1.5b,2b,7b 这几个模型进行评测对比,总体来说,比我预想的要好很多,我以为 7b 的会卡的很,结果表现的很棒,这么看来,跑 8B 以内的模型是没有问题的。
在往上的大模型,可能会吃力,不过 8B 以内,其实小微企业足矣!!!
审核编辑 黄宇
-
华为云 Flexus X 实例云服务器部署即时通讯 IM 项目2025-02-07 1127
-
Flexus 云服务器 X 实例实践:部署思源笔记工具2025-02-06 1621
-
Flexus 云服务器 X 实例实践:安装 SimpleMindMap 思维导图工具2025-01-17 5819
-
Flexus 云服务器 X 实例实践:部署 Alist 文件列表程序2025-01-14 2065
-
Flexus 云服务器 X 实例实践:安装 Ward 服务器监控工具2025-01-13 1403
-
华为云 Flexus 云服务器 X 实例之 openEuler 系统下部署 dufs 文件服务器2025-01-08 1399
-
Flexus 云服务器 X 实例:在 Docker 环境下搭建 java 开发环境2024-12-30 1315
-
华为云 Flexus X 实例 MySQL 性能加速评测及对比2024-12-25 1282
-
华为云 Flexus 云服务器 X 实例的购买及使用体验2024-12-24 1437
全部0条评论

快来发表一下你的评论吧 !
