

eIQ Time Series Studio工具使用教程
描述
本期为大家带来eIQ Time Series Studio工具使用攻略-输入文件格式的介绍。
时间序列数据与视觉和语音数据不同。视觉数据通常由三个或一个通道组成,每个通道具有固定的宽度和高度。语音数据则始终保持一个或两个通道,输入为麦克风波形。时间序列数据通常来自一个或多个传感器,通道的数量是不同的,例如:
原始传感器数据可以有不同的采样率,如何选择最佳采样率?
原始传感器数据输出是按照时间顺序并连续的。如何更好地将连续数据分割成段数据?
多个传感器生成的异构数据集并非机器学习算法期待的的数据集。
视觉和语音数据是人类可理解的,而时间序列数据则以浮点格式呈现,难以直接阅读和理解。
因此算法设计与视觉和语音AI/ML有所不同。
为了了解时间序列数据,以3轴加速度传感器的数据样本为例:
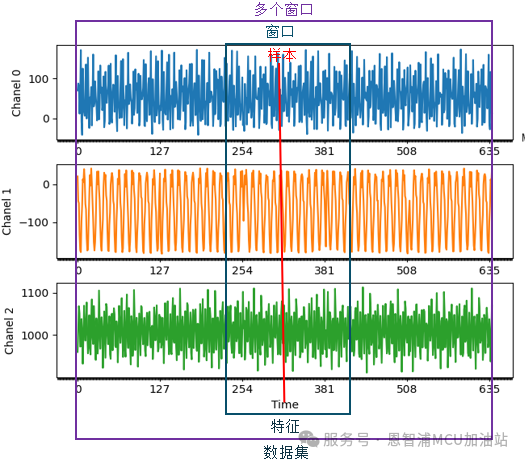
可以从图表中得到:
传感器有三个通道,分别命名为C1、C2、C3轴,大多数传感器可能只有一个通道。
一个采样点包含每个通道的一个数据点,由 C1、C2、C3 组成。
一个采样时间窗口包含多个按时间顺序排列的采样点,顺序为 C1 C2 C3 C1 C2 C3…C1 C2 C3。
整个数据集由多个随机顺序的时间窗口组成。
同一传感器的每个通道都在相同的采样率下运行,因此所有通道的数据规模都是相同的。
连续数据:
硬件传感器始终按时间顺序以连续格式输出原始数据,见下图:
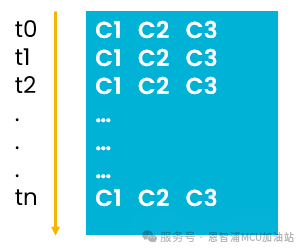
建议用户按上述格式保存连续的原始数据,并确保每行代表一个时间增量,建议使用空格作为分隔符。逐行加载数据时按时间顺序执行。
分段数据:
工具支持分段数据输入,用户可以自行处理数据或通过"Data Logging"采集连续数据并通过"Data Intelligence"进行数据分析并保存为分段数据。以下图表解释了分段数据的格式。
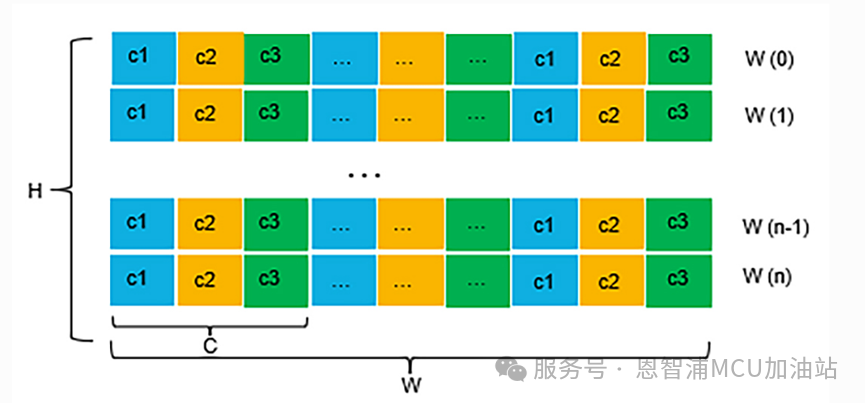
每一行作为一个样本,样本点按通道顺序排列。
多个按行排序的样本组成一个训练数据集,用于算法研究。
逐行分割的数据样本可以保持随机,但里面的每个样本必须保持时间顺序。
可以选择多个数据文件作为一种类型导入工具进行训练和测试,数据加载器会自动合并。
Time SeriesStudo 数据格式
需要用户导入正确的数据集,工具仅支持CSV文件格式,数据集以分段格式保存,数据间以:空格,逗号,Tab, 分号隔开,对于不同的训练任务,请按照以下指南导入适当的CSV格式文件。
异常检测&分类算法:
数据文件格式:每行一个样本,包含所有通道数据,样本由分隔符(空格、逗号、tab和分号)分隔。这是一个数据文件示例,其中包含 m+1个样本,每个样本有 n+1个采样点,每个采样点的数据包含 3 个通道(x、y 和 z)。

对于异常检测,必须导入两类数据文件:正常样本和异常样本文件。每个类必须加载至少一个数据文件。
对于分类项目,必须导入 n (n>=1) 类数据文件。每个类必须加载至少一个数据文件。
异常检测和分类需要导入不同类别的样本数据文件,为了得到可信的训练结果,最好保持各个类别的样本数量总体平衡。
回归算法
数据文件格式:每行一个样本,包含所有通道数据,样本之间用分隔符(空格、逗号、制表符和分号)分隔。前 k+1 (k 是Input/Outputtargets参数值,在创建回归项目时设置,k >= 0)列是要预测的目标值。这是一个数据文件示例,中包含 m+1个样本,每个样本有 n+1个采样点,每个采样点的数据包含 3 个通道(x、y 和 z)和 k+1个目标。

-
恩智浦eIQ Time Series Studio 工具使用攻略(四)-数据导入2025-03-06 2176
-
恩智浦eIQ Time Series Studio工具使用教程之数据记录2025-05-24 1313
-
恩智浦eIQ Time Series Studio 工具使用全攻略2024-12-12 3083
-
eIQ Time Series Studio工具使用攻略(三)-工程创建2025-01-09 2576
-
恩智浦 eIQ Time Series Studio 工具使用攻略(七)-部署2025-04-17 2422
-
NXP eIQ Time Series Studio 工具使用攻略(九)-数据标签2025-05-22 1857
-
恩智浦eIQ Time Series Studio工具使用教程之数据智能2025-06-05 1821
-
恩智浦eIQ Time Series Studio工具使用教程之数据操作2025-06-16 1892
-
恩智浦eIQ AI和机器学习开发软件增加两款新工具2024-11-01 2054
-
恩智浦eIQ Time Series Studio的工作流程2024-12-09 1776
-
恩智浦eIQ Time Series Studio工具使用教程之模型训练2025-03-25 2046
-
恩智浦eIQ Time Series Studio工具使用教程之仿真2025-04-07 1459
-
恩智浦eIQ Time Series Studio简介2025-07-02 2129
全部0条评论

快来发表一下你的评论吧 !
