

知行科技大模型研发体系初见效果
描述
数据的质量和规模才是端到端的“命脉”
11月,知行科技作为共同第一作者提出的Strong Vision Transformers Could BeExcellent Teachers(ScaleKD),以预训练ViT(视觉Transformer)模型作为教师,CNN网络作为学生进行学习。推进异构神经网络间知识蒸馏研究的具体范式/方法,被收录于NeurIPS 2024(第38届神经信息处理系统会议)。
这是知行科技构建大模型体系能力的初步成果之一。2024年年中,知行科技开始从资源、组织等多线程入手,打造面向大模型的研发架构体系,并完成组织架构调整,引入包括清华大学计算机博士背景的大模型架构师等多位大模型与自动驾驶领域专家,构建起对齐主流的研发组织架构和专家人才库,为2025落地端到端大模型系统上车做好准备。
01构建以数据为中心的开发体系
端到端让所有智驾玩家有机会重新站上起跑线,但做端到端的挑战并不全在于“模型”本身。
原特斯拉FSD研发负责人Andrej Karpathy曾表示,特斯拉自动驾驶部门将3/4的精力用在采集、清洗、分类、标注高质量数据上,只有1/4用于算法探索和模型创建。究其原因,数据是人工智能发展的燃料,而端到端大模型将AI的“油耗”水平推到了新的高度。
“100万个视频 Case 训练,勉强够用;200万个,稍好一些;300万个,就会感到Wow;到了1000 万个,就变得难以置信了。”特斯拉创始人马斯克曾这样量化FSD的训练数据需求。
问题是,虽然人类活动生生不息,有效数据却不是源源不断。ChatGPT 3 的开发文档中提到,45TB的纯文本质量过滤后,仅获得570GB的文本,有效数据仅为1.27%。大语言和多模态模型领域已经开始出现高质量的真实文本、视频数据耗尽,性能撞墙的情况。
对自动驾驶来说,高质量的数据多来自罕见路况和场景,产生条件苛刻,导致样本量相对语言类更为稀缺,更是难以满足大模型的参数需求。
目前,端到端自动驾驶系统上车带来更上限的同时,也开始遭遇数据分布问题、高质量数据不足,导致的部分场景性能回退、困难场景性能不稳定的情况。
数据的质量和规模才是端到端的“命脉”。知行科技在进入端到端赛道时,决定构建“以数据为中心”的研发体系,用以满足大模型对高质量数据“贪婪”的特性。
知行科技重构研发组织架构,形成大模型、模型部署、基础设施、大数据等多模块在内的主流人工智能开发框架。其中,大模型组不仅在模型层面提供新的技术支持,在数据自动标注算法、基于扩散模型的数据生成、基于多模态大模型的数据挖掘方面也都有发力,以更低成本的数据生产为目标,保质保量地满足知行科技端到端大模型的数据需求。
02仿真数据,数据战争的下一步
当数据需求是百万clips起步时,应该如何打这场数据战争?
知行科技一方面强化自有数据采集和标注能力,并与生态伙伴形成一定程度的数据协同;
在数据采集方面,知行科技已自建采集车队,自主搭建数据采集软件、车端采集系统和后端耦合系统,实现数据采集全链条的自动化和高度可控,日采集效率达20万帧,为BEV行泊车功能闭环量产提供必要的数据支持。
在数据标注方面,知行科技已经建成自动化标注体系并在不断地完善,在OD(障碍物检测)、LD(车道线检测)项目中实现完全自动标注,整体减少至少50%的数据标注成本。
与此同时,面向端到端系统海量数据需求,知行科技则借助大模型的能力,探索仿真数据的产业应用前景。
12月,OpenAI和谷歌先后发布了视频产品,提供文本、图像、视频转视频的功能,展现出扩散模型等大模型对现实世界极强的复现和“改写”能力。事实上,包括特斯拉在内的自动驾驶头部玩家,也已正在加大仿真数据领域的投入。
因为,仿真数据在数据生产降本,和稀有场景数据获得方面,有着至关重要的作用:
经过良好预训练的大模型能够“向前”,渲染复制现实世界生成图像,并通过在虚拟世界中车辆动态摆放,仅用几分钟生成成千上万段仿真场景信息;
也能够“向后”推理,基于已有场景和环境信息,进行规划控制的学习,打通整个感知和规划链路;
此外,基于对物理世界的理解,大模型还能够通过改变场景中的关键数值,提升数采场景的有效比例。
目前,知行科技通过大模型进行数据生成已取得阶段性成果:能够使用原图进行天气,光照等条件的修改达到快速扩充真值的目标;通过给定特殊控制量,达到数据生产的目的。通过在自动标注和大模型数据生成方面的全面布局,知行科技在数据生产的降本和质量提升方面,已取得实质性进展。
此外,在数据挖掘方面,知行科技已初步建成ImoGPT-多模态大模型的安全解决方案,通过MoE(混合专家系统)大模型,进行文本理解、图片理解和视频理解。其将在实现场景可解释性、数据挖掘、端到端安全方案等多方面发挥重要作用。
03大模型,有教无类的“良师”
大模型可以是数据的生产者,也可以是端侧小模型的“好老师”。
如ChatGPT解释,凭借庞大的参数量和复杂的结构,大模型能够通过海量数据训练,发现新的、更高层次的特征和模式,表现出未能预测、更复杂的能力和特性,实现智能的涌现。“涌现能力”也是大模型扩大使用场景,提升泛化性的核心。但大模型也存在计算资源消耗巨大、推理速度慢、模型可解释性差的问题,难以被部署在计算和能耗都非常有限的端侧。
如何使端模型也获得相应的知识和泛化能力,知识蒸馏(Knowledge Distillation)技术应运而生:将大模型学到的知识迁移到一个更小的模型中,保持性能的同时降低模型部署难度和计算开销。
知行科技被NeurIPS 收录的ScaleKD,正是一种大模型知识蒸馏方法。
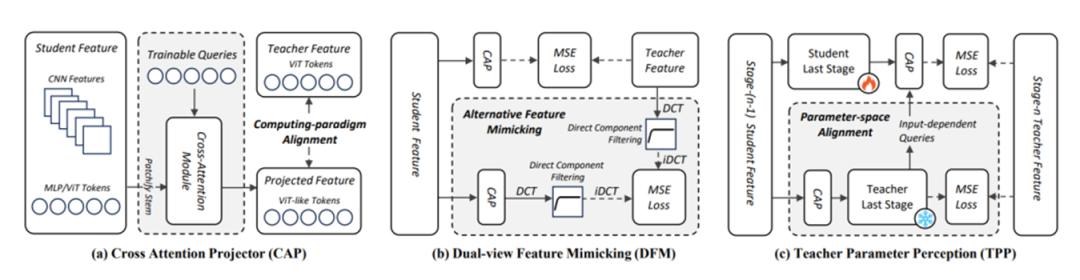
ScaleKD通过结合三个紧密耦合的组件(交叉注意力投影器,双视图特征模仿和教师参数感知),对齐云端教师模型和端侧学生模型之间的特征计算范式差异、型规模差异和知识密度差异,实现任何目标学生模型在大规模数据集上的时间密集的预训练范式。
这意味着,大模型能够作为“有教无类”的良师,将知识和规律“复制”到端侧模型,大幅提升其性能和泛化性。
从前沿学术研究出发,知行科技将根据实际中使用的端模型,构建对应的老师模型进行训练,获得更强的能力,从而通过知识蒸馏提高端模型的学习效果和速度。
端到端大模型的应用,为智能驾驶玩家带来重新开局的机会。中国的场景复杂性、市场需求,中国团队工程化和应用落地的能力,以及大模型技术领域不断涌现的新能力,使后来者能够快速、确定性地切入赛道。
知行科技着力构建的数据生产能力,积累的高质量数据,将为端到端模型训练提供源源不断的”燃料“,推动智驾功能从“能用”、“好用”,走向消费者“爱用”的未来。
-
国防科技大学数模讲义2009-09-15 5457
-
解决研发管理问题的途径2013-09-11 2629
-
【招聘季】记忆&忆联 研发体系最新***201712212017-12-22 1785
-
记忆/忆联研发体系最新*** 201801082018-01-08 2248
-
嵌入式硬件系统与存储体系2021-12-17 934
-
105ARM体系结构-编程模型_EXTI2015-11-17 664
-
基于RSM代理模型的武器装备体系优化算法2017-12-12 1009
-
知行科技近期成功通过ASPICE Level 2认证!2021-06-29 3954
-
[原创]初见ethercat笔记及自己的理解2021-12-08 511
-
研发体系理想模型怎么形成的2022-11-02 1415
-
蚂蚁集团正研发贞仪大模型2023-06-21 1560
-
大模型开源开放评测体系司南正式发布2024-02-05 1803
-
如何评估AI大模型的效果2024-10-23 4574
-
知行科技获超2亿元融资,加速AI高阶智驾研发与海外拓展2025-02-13 902
-
知行汽车科技宣布更名“知行科技”2025-03-13 921
全部0条评论

快来发表一下你的评论吧 !
