

定制本地的ChatFile的AI问答系统
描述
写在前面
"这份 200 页的技术文档,能帮我总结一下核心内容吗?" "刚收到客户 100 页的需求文档,有办法快速理解吗?" "团队的知识库太庞大了,想问个问题都要翻半天..."
是不是经常会遇到这样的困扰?今天,我们将利用下面两个技术为自己定制一个本地的 ChatFile 的 AI 问答系统:
1. Google 最新开源的生成式 AI 模型: Gemma 2
2. 检索增强生成技术: RAG (Retrieval - Augmented Generation)
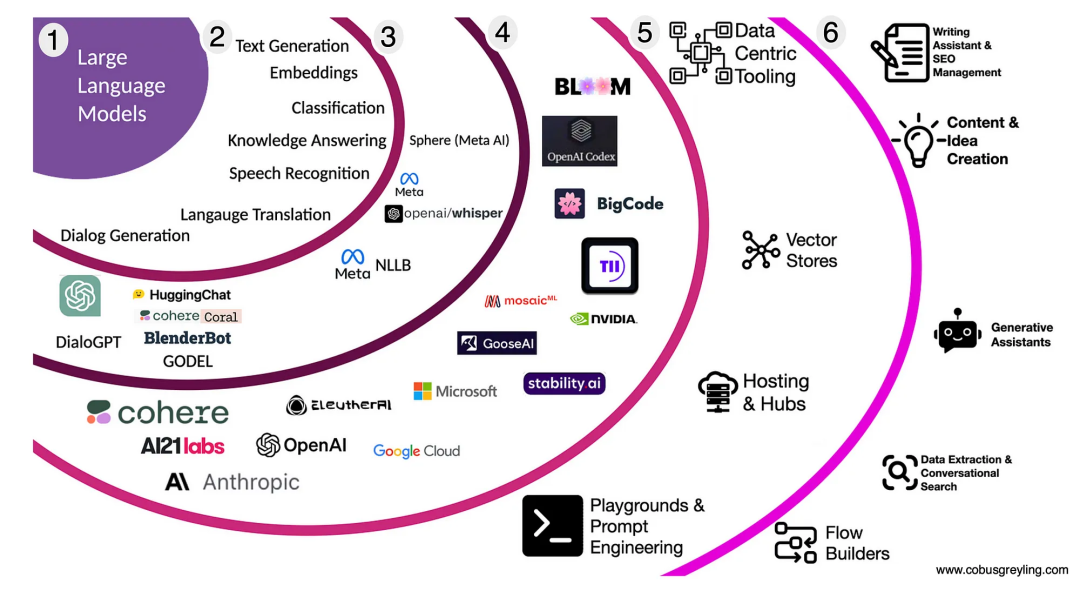
Gen AI 技术发展
LLM 技术生态全景
Google 生成式 AI
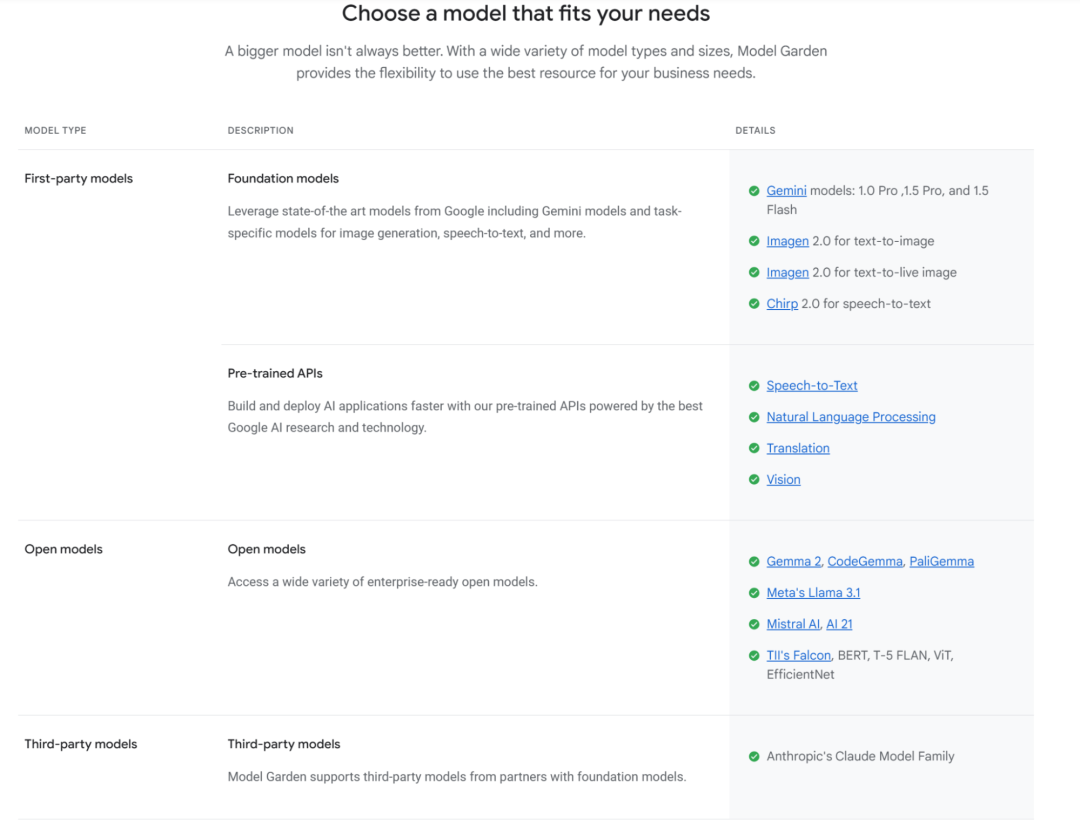
Google 在 AI 领域采取了双轨制战略:
闭源商业模型
Gemini 系列 (1.0/1.5 Flash/1.5 Pro/2.0 等) - 语言文本模型/多模态模型
Imagen 系列 - 文生图模型
Embedding Models - 文本 embedding/多模态 embedding
开放模型
Gemma 系列 (Gemma 1|2, Code Gemma, Pali Gemma 等)
Gemma 是 Google 的一系列轻量级开放模型,继承了 Gemini 的核心技术。其中 Gemma 2 是截止目前最新的模型版本。
Gemma 2 提供了三个不同规模的版本:
2B 参数版本: 适合边缘计算场景
9B 参数版本: 平衡性能和资源需求
27B 参数版本: 提供最佳性能
快速了解 RAG
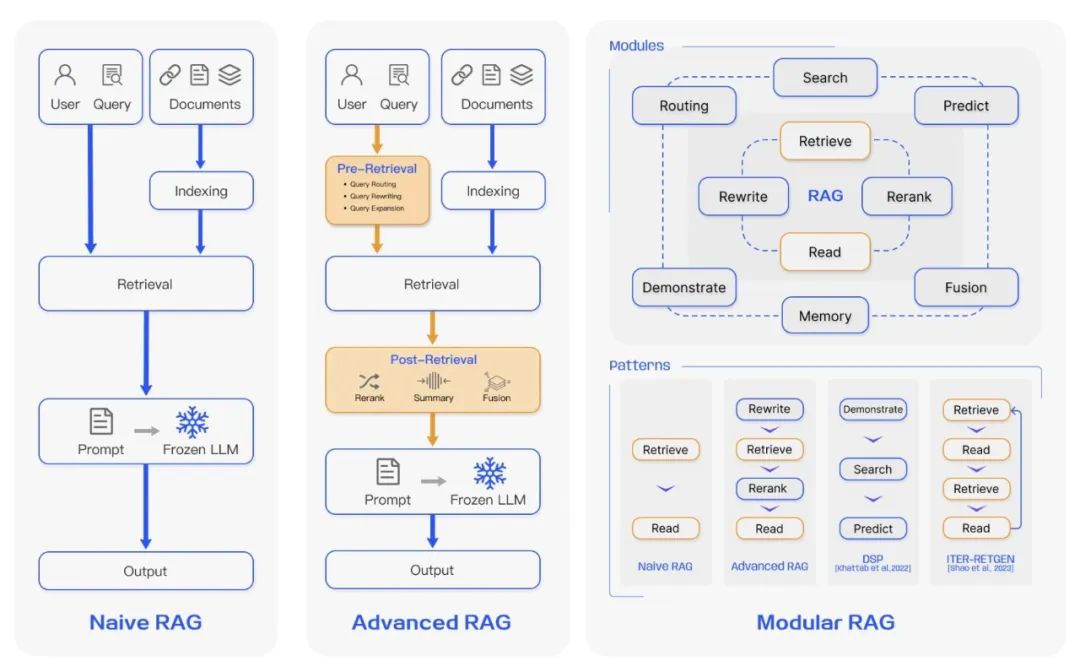
△ Comparison between the three paradigms of RAG
(来源: https://arxiv.org/abs/2312.10997v5)
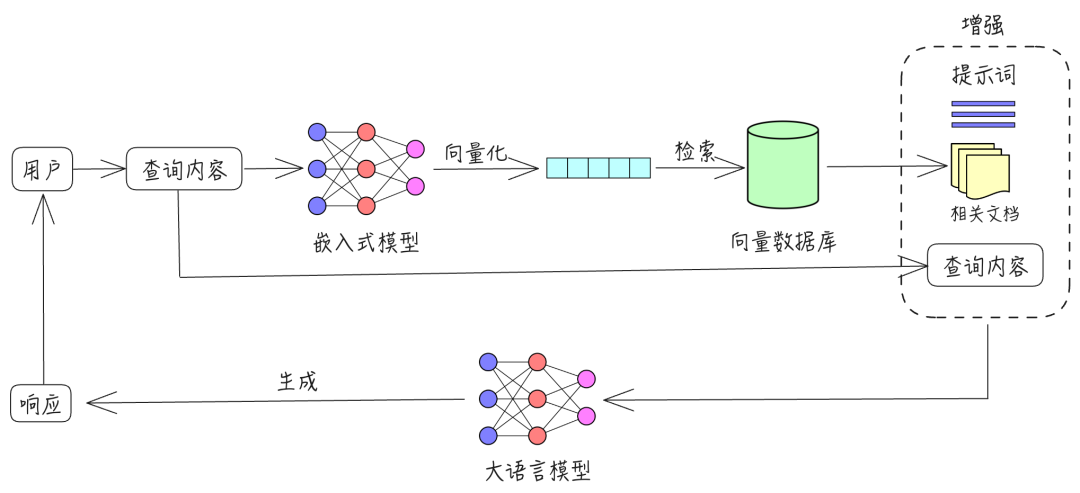
RAG 通过几个主要步骤来帮助增强生成式 AI 输出:
检索和预处理: RAG 利用强大的搜索算法查询外部数据,例如网页、知识库和数据库。检索完毕后,相关信息会进行预处理,包括标记化、词干提取和停用词移除。
生成: 经过预处理的检索到的信息接着会无缝整合到预训练的 LLM 中。此整合增强了 LLM 的上下文,使其能够更全面地理解主题。这种增强的上下文使 LLM 能够生成更精确、更翔实且更具吸引力的回答。
RAG 的运行方式是: 首先, 使用 LLM 生成的查询从数据库中检索相关信息。然后, 将这种检索到的信息整合到 LLM 的查询输入中,使其能够生成更准确且与上下文更相关的文本
实战从 0-1 构建智能文档助手
在本教程中,我们将带您了解如何设置和使用一个命令行工具,通过它您可以使用最先进的语言模型 Gemma 2 与您的 PDF 文件进行对话交互。
公开源代码
https://github.com/Julian-Cao/chat-file-with-gemma.git
项目概述
我们将构建一个 Python 的命令行应用程序,实现:
1. PDF 文本提取
2. 文本向量化
3. 智能问答生成
系统模块
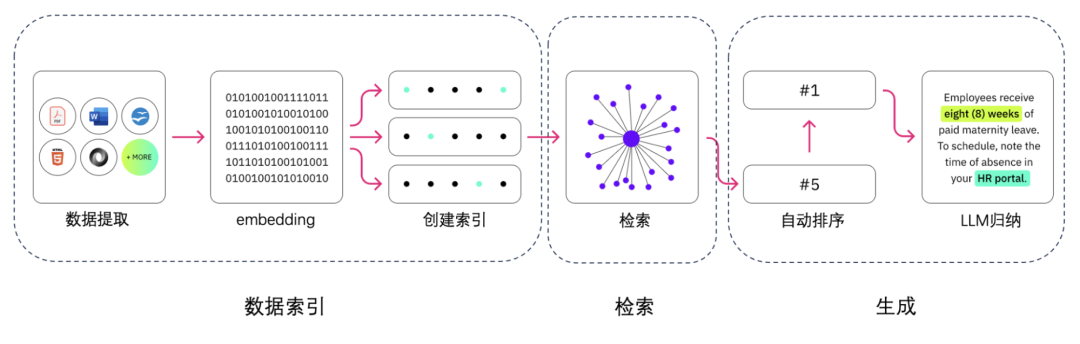
文档解析处理器 (Parser Chunks)
使用 PyMuPDF 处理 PDF 等办公文件
实现文本分块和预处理
向量化处理 (Embedding Model)
使用 text-multilingual-embedding-002 模型
将文本转换为高维向量表示
向量数据库 (Vector Database)
实现基于本地文件的向量存储
支持高效的相似度检索
生成式 AI 模型 (Gen AI Model)
通过 Groq 直接使用 Gemma 2
处理自然语言理解和生成
对话记忆管理 (Chat Memory)
基于本地文件系统
维护上下文连贯性
前置条件
在开始之前,请确保您已准备:
1. Python 3.7 或更高版本
2. 系统已安装 Git
3. 用于 Vertex AI 的 Google Cloud 账号
4. 申请用于访问 Gemma 2 的 Groq API 密钥
5. 安装 Python Typer 库命令行应用程序构建工具
步骤 1: 环境设置
首先,让我们克隆代码仓库并设置环境:
# Clone the repository git clone https://github.com/Julian-Cao/chat-file-with-gemma.git cd chat-file-with-gemma # Create and activate a virtual environment python -m venv venv source venv/bin/activate # On Windows, use `venvScriptsactivate` # Install the required dependencies pip install -r requirements.txt
步骤 2: 配置
在项目根目录创建 config.json 文件,包含您的 Google Cloud 和 Groq API 凭证:
{
"project_id": "your-google-cloud-project-id",
"region": "your-google-cloud-region",
"groq_key": "your-groq-api-key"
}
步骤 3: 了解项目结构
项目的主要组件包括:
1. chat.py: 包含文本处理和交互的核心功能
2. requirements.txt: 列出所有 Python 依赖
3. demo.pdf: 示例 PDF 文件 — Attention Is All You Need
4. config.json: 存储你的 API 凭证 (需要自行创建)
5. README.md
Attention Is All You Need
https://arxiv.org/abs/1706.03762
步骤 4: 工作原理
让我们来分析 chat.py 文件的关键组件:
文本提取: 应用程序使用 PyMuPDF (以 fitz 导入) 从 PDF 文件中提取文本并将其分割成可管理的块。
文本嵌入: 使用 Vertex AI 的文本嵌入模型为文本块创建向量表示。这使得后续可以进行高效的相似度搜索。
相似度搜索: 当你提出问题时,应用程序通过比较问题的嵌入向量与文档块的嵌入向量找到最相关的内容。
响应生成: 通过 Groq API 使用 Gemma 2 基于相关上下文和你的问题生成响应。
步骤 5: 运行你的 ChatFile 应用程序
现在你可以运行应用程序:
python chat.py
应用程序会提示你提供 PDF 文件路径。处理完文档后,你就可以开始询问关于其内容的问题。
开始使用
根据提示,输入 PDF 文件的路径。
应用程序将处理文档,这可能需要一些时间,具体取决于文件大小。
处理完成后,你就可以开始询问文档相关的问题。
输入你的问题并按回车。应用程序将根据文档内容提供答案。
要切换到不同的文档,在提示输入问题时输入 **'c'**。
要退出应用程序,在提示输入问题时输入 **'q'**。
示例交互
> python chat.py Please enter the path to your file (or 'q' to quit): /path/to/your/document.pdf Initializing with file: /path/to/your/document.pdf Extracting text chunks… Processing chunks… Embedded all chunks Saved embedded chunks to embedded_chunks_1234567890abcdef.json Initialization complete. You can now start asking questions. Enter your question below (or 'q' to quit, 'c' to change file) Question: What is the main topic of this document? [Answer will appear here] - - Enter your question below (or 'q' to quit, 'c' to change file) Question: q Thank you for using the Interactive File Q&A System. Goodbye!
最后
恭喜!你已经设置并使用了由 Gemma 2 驱动的本地 ChatFile 应用。这个工具让你能够以对话方式与 PDF 文档交互。
此工具实现包含以下特性:
缓存嵌入,使用相同文档时能更快地运行
具有丰富文本格式的交互式命令行界面
无需重启应用程序即可在不同文档之间切换
-
直播预告|玄铁 x Canonical:从本地推理到 AI 工厂,基于 RISC-V 的 AI 基础设施创新路径探讨2026-05-15 177
-
京东方发布显示行业首款全员开放AI问答系统2026-03-02 3053
-
技嘉于 CES 2026 展示 AI TOP 产品线 推动以人为本的本地 AI 生态系统发展2026-01-12 1568
-
29.9元的问答式AI智能体套件打造智慧旅游产品2025-01-14 1314
-
给Java同仁单点的AI"开胃菜"--搭建一个自己的本地问答系统2024-09-27 1381
-
NVIDIA 知乎精彩问答甄选 | 探索 AI 如何推动工作流升级相关精彩问答2023-12-14 1164
-
NVIDIA 知乎精彩问答甄选 | 分享 NVIDIA 助力医学研究的相关精彩问答2023-11-24 1544
-
问答对话文本数据:解锁智能问答的未来2023-07-13 1490
-
【入群体验】电子行业首个群聊式AI问答机器人正式上线2023-04-12 1223
-
【CC3200AI实验教程11】疯壳·AI语音人脸识别-AI语音系统架构2022-08-30 25411
-
鸿蒙系统(HarmonyOS)精华问答集锦2020-10-10 5244
-
检索式问答系统是什么2020-05-20 837
-
问答系统总结2019-06-12 611
-
谷歌Edge TPU处理器可在电脑中安装定制,用户可在本地处理AI任务2018-07-29 5466
全部0条评论

快来发表一下你的评论吧 !
