

关于堆栈的深入理解
电子说
描述
一、这些个概念怎么来的以及怎么记得住
这里,只限于整理我个人对堆/栈/堆栈在内存管理方面的理解。其他,在数据结构方面讲的堆/栈目前不在我整理范围之内。
这里提了三个概念: 堆,栈,以及堆栈。我把栈和堆栈的概念等同了。所以,接下来只要把两个概念弄清楚就可以了:堆和栈。
先说由来。由于我的工作大部分是和单片机相关的,因此也是基于嵌入式的这个方面的理解。
每片MCU有一定的内存,这些内存分:程序存储区;数据存储区。举例就是:我们写的每行代码,都会保存到程序存储区里面;而定义的一些全局变量,静态变量,局部变量之类的,就保存到数据存储区。
程序存储区,对于写代码的人来说,可以说是黑盒子:只要你的代码不超过程序代码空间,everything will be fine. 代码究竟是如何执行的,取决于你的编程思想,就是说,你让程序往东走,它就会往东走;让它原地踏步,它也会照做;前提是你的代码要写好。所以,对于编程经 验成熟的人,同样的算法,他可能会少敲几行代码,并且算法出错的几率少一些;不怎么会编程的人,就多敲几行,多测试一下。研究深一些的人,可能还会对代码 执行效率深入研究。我决定就此止步。继续黑盒子的话题,程序员的代码会烧写到程序存储区里面,至于哪条语句存哪里,这个是不用研究的。反正,一旦发现软件 没按照你设计的那样跑,基本就是程序自身的问题,不是存放程序的存储区的问题。
数据存储区,让程序员发挥的空间就很大了。由于程序是动态地执行的,执行的结果是怎么样,会产生什么数据就不是一个确定的事情。
举个例子说说这个程序和数据之间的表象吧。举例的事件就是:一个MP3播放器的上/下键的操作。加入在播放器里有10首歌,若当前是第3首,那 么按下[上]键后,应该是播放第2首。因此,实现播放第2首的,就是程序员写程序实现的,他的代码让[上]键实现了能从第3首切换到第2首的操作。这里, 表现的就是代码。而且,这个代码是确切的行为,从第3首按了[上]键之后,一定是播放到第2首。这个是确切的行为,如果不能实现,就是代码有bug了,需 要改正。终于可以扯到数据了。第2首是什么歌呢? 就是说第2首歌的内容是什么呢? 当然在程序员写代码的时候,他是不知道的,他要做的,就是预先开一片数据空间,以存放歌曲相关的数据。这片数据空间,想放什么就放什么,是灵活的。听烦了 这几首歌以后,再更换其它音频文件就是了。再说具体一点,程序就相当于修的一条路,让车可以在上面跑;但车上面装了什么,程序员是不知道的。
堆和栈属于数据存储区的范畴,也可以算是数据管理的手段或方法。基于此,不能一概而论,说哪个手段高明一些;他们也是基于现实的需要而产生的。黑格尔说:存在就是合理的。
这样的概念大家都不陌生:军队的管理是很严格的,很死板的;但是对于一些年轻的技术公司来说,员工就享有很高的自由度。
如果我说,墙角边整齐地摆放着10本书; 以及墙角边的书凌乱地放着。你闭上眼睛,能区分出两种画面吗? 如果没有,就不用往下看了。
栈的特性,就是严格/有序/规范的。栈的英文就是Stack. 如果我说,there are books stacked in that corner,你应该能知道书是怎么放的吧。
相反,堆呢,就是自由/灵活/随意的。堆的英文是Heap. 如果我说,there are books heaped in that corner,你应该能知道书是怎么放的吧。
二、get closer to the real STACK/HEAP。
栈: 由系统自动分配和回收的。
堆: 由程序员分配和回收的。
基于第一部分的理解,不用想都知道,作为“堆”的数据空间,也必须是灵活的,因为成千上万的程序员在写什么程序是未知的。但可知道的一点,就是他们是跑在确定的某个OS里面的。
因此,也不过就是给系统管理的数据空间起了个名字,就栈;给程序员使用的空间,起了个名,就堆。
我接下来就会废话:起什么名字都不重要,重要的是,我们得对这两种数据存储区的管理的机制由来,方法有深刻认识;这样,即便几个世纪以后它们更名为阿猫阿狗了,我们依然能认知它们。
举例:
void Check_Pro_Code( uint8 style )
{
uint8 i;
switch( style )
{
......
}
}
void main( )
{
uint8 j = 1;
Check_Pro_Code( j );
}
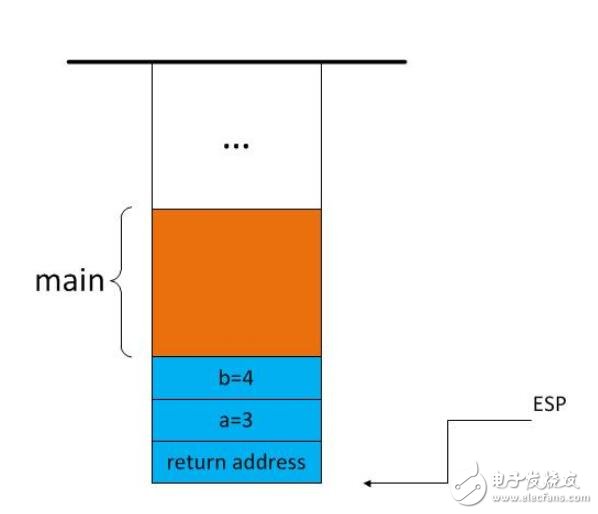
在main()函数里调用了Check_Pro_Code(...)函数,事先要对j进行入栈操作;当然这里函数调用的时候,涉及到几个入栈操作:程序的下一个执行地址;局部变量;形参。
这里,我就没有深入介绍了。
实在很惭愧的是,我写的嵌入式软件里,没有涉及到任何和堆操作相关的。我就是那样一个人,CM3内核里也没有移植操作系统,实在是汗颜,因为本人对RTOS实在是未曾涉猎。所以,我这里对于堆的介绍,是没有任何实战鹰眼的。并且为了堆我就堆了一下。你说,这样算学术造假吗?
void main( )
{
int j=10;
int *p;
p = malloc( 10 ); //话说这里就是堆,我是为了用而用,实在是无味地很。
p = "123456".
}
三、话说堆栈溢出
再次明确,堆栈溢出的堆栈是指栈。
1 当C程序函数的调用层次过深或者出现了递归调用,就容易使程序运行所需的堆栈空间超过系统能提供的最大堆栈空间范围,产生堆栈溢出。
这是很明白的,当A函数调用了B函数,而B()里面又调用了C(),C()里又调用了D()......当这样的调用太深的时候,就容易堆栈溢出了。
四、一级缓存/二级缓存
栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。
举个我知道的例子:
void main( )
{
int i,j;
static int flag = 1;
i = Sum_Of_Group( );
j = Check_Exist( );
}
这里,i,j的值都是给通用寄存器的,而不是给予确切的物理地址。而对于flag,由于其为静态变量,是在SRAM里面分配地址的。这里好像没有说到一级缓存二级缓存。时间限制,下回述。
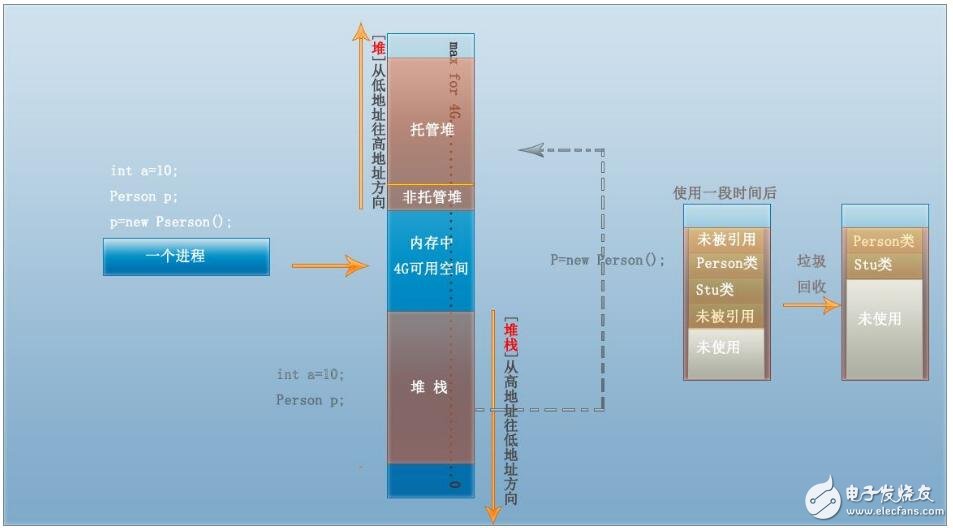
五、栈:在Windows下,栈是向低地址扩展的数据 结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因 此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
注:该段内容100%抄袭,出处:网络。
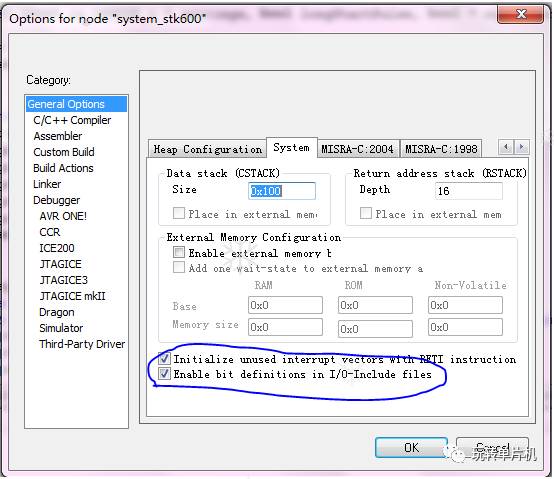
六、如何修改我自己的工程的STACK(以下内容不通用)
由于我自己的工程用的是LPC1765,刚好从网络抄到了比较有用的图片。摘于此。其他单片机的编译环境,应该也是差不多如法炮制的。
编译环境: IAR for ARM.
图一 :如何修改STACK的大小
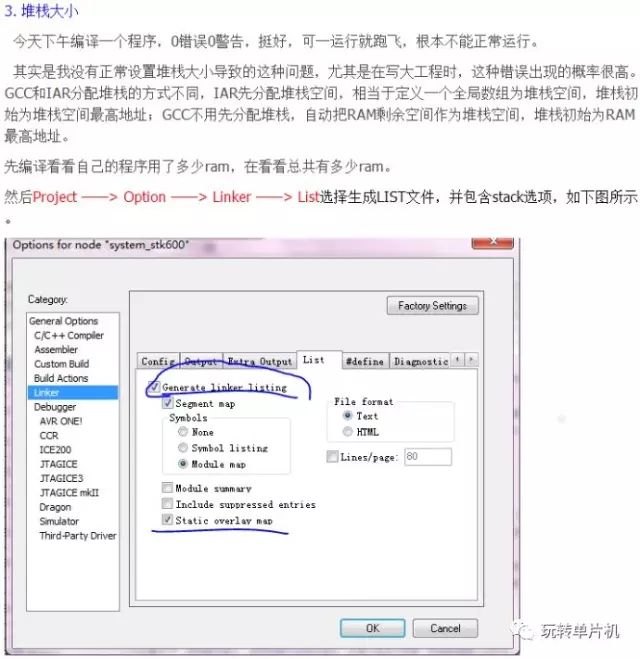
图二,如何知道自己的工程用了多少堆栈

- 相关推荐
- 热点推荐
- 堆栈
-
为什么要深入理解栈2022-02-15 1013
-
深入理解STM322021-08-12 1501
-
深入理解MOS管电子版资源下载2021-07-09 1485
-
如何深入理解ES6之函数2020-05-22 1481
-
深入理解lte-a2019-02-26 4224
-
《深入理解Android》文前2017-03-19 601
-
深入理解Android之资源文件2017-01-22 657
-
深入理解和实现RTOS_连载2014-05-29 5779
-
深入理解Android2012-08-20 3209
-
深入理解SD卡原理和其内部结构总结2012-08-18 2890
-
uCOS任务堆栈的深入分析2011-11-01 3454
全部0条评论

快来发表一下你的评论吧 !
