

专家与处理器架构未来
电子说
描述
一年一度的ISSCC(International Solid State Circuits Conference的简称,中文名固态电路年会)正式拉开帷幕,在这个被称为“集成电路奥利匹克”的会议上,来自全球各地的专家齐聚一堂,探讨集成电路的未来。计算机体系专家David Paterson也在会议上发表了题为《50 Years of Computer Architecture:from Mainframe CPUs to DNN TPUs and Open RISC-V》的演讲,让我们看一下体系结构专家眼里的处理器未来。
对过去处理器发展的回顾
他表示,在20世纪60年代初,当时IBM同时拥有4条完全不兼容的产品线(701 ➡ 7094、650 ➡ 7074、702 ➡ 7080和1401 ➡ 7010),IBM面临着非常严重的兼容性问题。其中每一条产品线都拥有各自完全独立的指令集体系结构(ISA),I/O系统和二次存储,磁盘存储系统,汇编程序,编译器,库以及市场利基。

这几条完全不兼容的产品线也使得当时的处理器设计变得异常复杂,设计者必须在数据存储路径和控制单元之间进行非常详细的区分。可以说,早期的计算机设计者所面临的最大问题就是控制单元的指令控制线是否正确,能够起到作用。
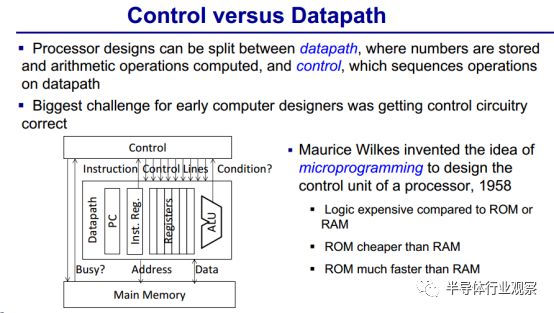
此前,Maurice Wilkes在1958年提出了用微程序设计的思想来设计控制单元,简化我们在设计过程中所遇到的问题,这种情况之下,我们只需要考虑一下几个问题:ROM和RAM的价格问题,ROM比RAM便宜,而且ROM比RAM速度更快。
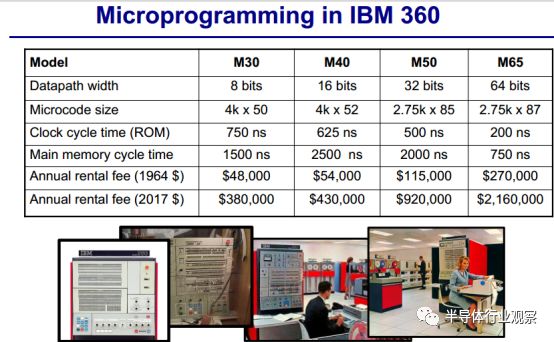
随着IC技术、微指令和CISC的发展,Logic、RAM和ROM都应用了相同的晶体管;半导体RAM和ROM的速度也差不多;随着摩尔定律的发展,控制指令的存储空间也逐渐增加;允许更多的CISC;类似TTL 服务器这样的小型计算机的出现,推动处理器产业进入了新阶段。

伴随而来的是微处理器技术的革新。
David Paterson表示,上世纪70年代,在MOS技术和主流ISA的推动下,计算机经历了快速的发展,出现了以Intel i432为代表的产品。

之后也推出了Intel 8086等划时代的产品。

之后就到了微指令机器的二十世纪八十年代。

从CISC到RISC,架构面临瓶颈
计算机发展之初,ROM比起RAM来说更便宜而且更快,所以并不存在片上缓存(cache)这个东西。在那个时候,复杂指令集(CISC)是主流的指令集架构。然而,随着RAM技术的发展,RAM速度越来越快,成本越来越低,因此在处理器上集成指令缓存成为可能。
同时,由于当时编译器的技术并不纯熟,程序都会直接以机器码或是汇编语言写成,为了减少程序设计师的设计时间,逐渐开发出单一指令,复杂操作的程序码,设计师只需写下简单的指令,再交由CPU去执行。

但是后来有人发现,整个指令集中,只有约20%的指令常常会被使用到,约占整个程序的80%;剩余80%的指令,只占整个程序的20%。
于是1979年,David Paterson教授提出了RISC的想法,主张硬件应该专心加速常用的指令,较为复杂的指令则利用常用的指令去组合。使用精简指令集(RISC)可以大大简化硬件的设计,从而使流水线设计变得简化,同时也让流水线可以运行更快。

Paterson教授重申了评估处理器性能的指标,即程序运行时间。程序运行时间由几个因素决定,即程序指令数,平均指令执行周期数(CPI)以及时钟周期。程序指令数由程序代码,编译器以及ISA决定,CPI由ISA以及微架构决定,时钟周期由微架构以及半导体制造工艺决定。对于RISC,程序指令数较多,但是CPI远好于CISC,因此RISC比CISC更快。

据介绍,RISC有以下多个优点:
指令长度固定,方便CPU译码,简化译码器设计。
尽量在CPU的暂存器(最快的存储器元件)里操作,避免额外的读取与载入时间。
由于指令长度固定,更能受益于执行线路管线化(pipeline)后所带来的效能提升。
处理器简化,晶体管数量少,易于提升运作时脉。比起同时脉的CISC处理器,耗电量较低。
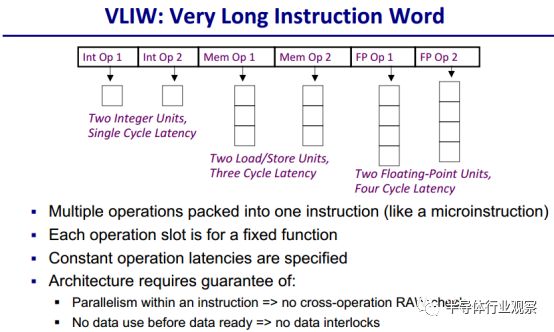
除了CISC和RISC之外,另一种流行(过)的ISA是超长指令字(VLIW)。
VLIW是美国Multiflow和Cydrome公司于20世纪80年代设计的体系结构,主要应用于Trimedia(全美达)公司的Crusoe和Efficeon系列处理器中。AMD的Athlon64处理器系列也是采用这一指令系统,包括其服务器处理器版本Operon。

同样Intel最新的IA-64架构中的EPIC也是从VLIW指令系统中分离出来的。VLIW架构采用了先进的EPIC(清晰并行指令)设计,我们也把这种构架叫做“IA-64架构”。每时钟周期例如IA-64可运行20条指令,而CISC通常只能运行1-3条指令,RISC能运行4条指令,可见VLIW要比CISC和RISC强大的多。
之后David Paterson还谈到了Intel 的安腾处理器和EPIC IA-64。

然而,VLIW架构遇到了巨大的失败。VLIW的问题,包括分支预测困难,Cache miss无法解决,代码爆炸以及最关键的,编译器过于复杂以至于无法实现。
此外,基于VLIW指令集字的CPU芯片使得程式变得很大,需要更多的内存。更重要的是编译器必须更聪明,一个低劣的VLIW编译器对性能造成的负面影响远比一个低劣的RISC或CISC编译器造成的影响要大。

David Paterson还对今天的ISA做了一个总结。他指出,目前处理器的ISA,已经30多年没有新的CISC ISA出现(Intel x86表面用的是CISC但是内部有硬件把CISC转换成RISC再真正执行)。VLIW在一些嵌入式DSP市场获得应用,但是在其他的市场都没有获得成功。考虑到处理器的数量,目前最主流的通用ISA还是RISC。

IT领域面临新挑战,TPU横空出世
按照David Paterson的观点,现在的IT技术面临新的挑战。例如登纳德缩放定律的失效,功耗成为了关键的约束;摩尔定律也面临困难,晶体管的提升变慢。另外,在架构上也有新的问题出现。

同时,处理器性能增长也面临性能增长瓶颈。
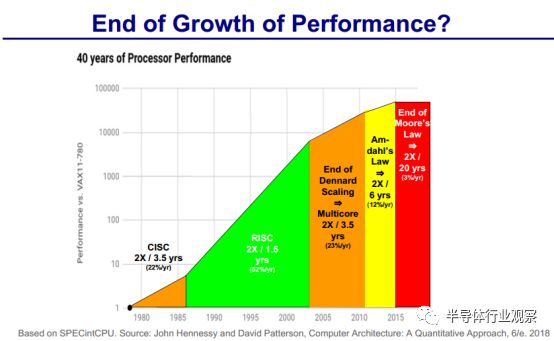
在David Paterson看来,对于任何运算来说,更换新硬件无非是为了两个目的:更快的速度和更低的能耗。但由于面临晶体管并没有变得更好、功率预算也不高等问题。许多架构师认为,现在只有领域定制硬件(domain-specific hardware)能带来成本、能耗、性能上的重大改进。

紧接着,David Paterson介绍了谷歌的TPU。
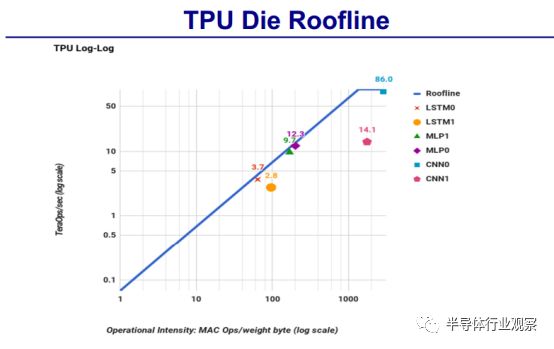
TPU 的核心是一个65,536的8位矩阵乘单元阵列(matrix multiply unit)和片上28MB的软件管理存储器,峰值计算能力为92 TeraOp/s(TOPS)。
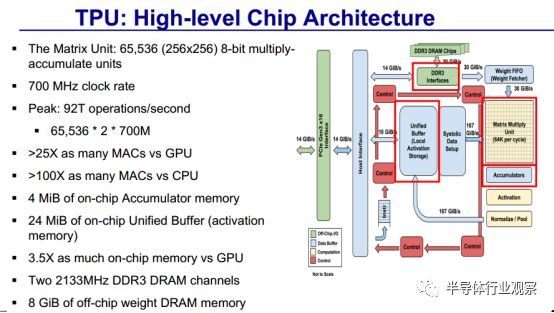
与CPU和GPU由于引入了Cache、乱序执行、多线程和预取等造成的执行时间不确定相比,TPU 的确定性执行模块能够满足 Google 神经网络应用上 99% 相应时间需求。
CPU/GPU的结构特性对平均吞吐率更有效,而TPU针对响应延迟设计。正是由于缺乏主流的CPU/GPU硬件特性,尽管拥有数量巨大的矩阵乘单元 MAC 和极大的偏上存储,TPU 的芯片相对面积更小,耗能更低。
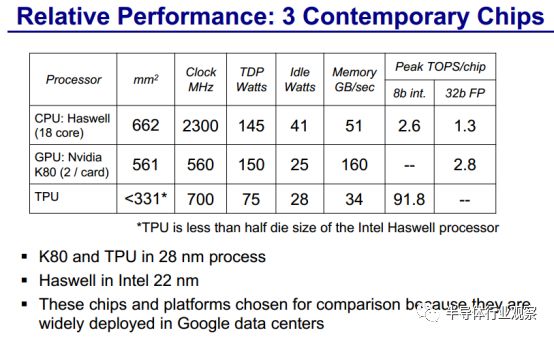
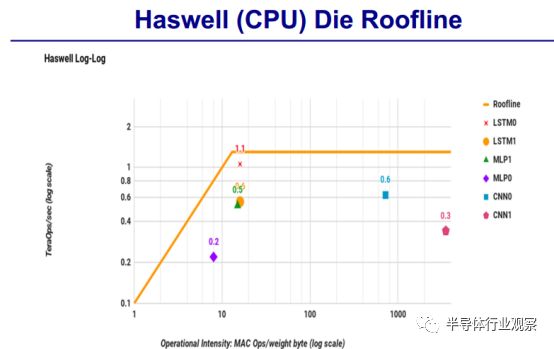
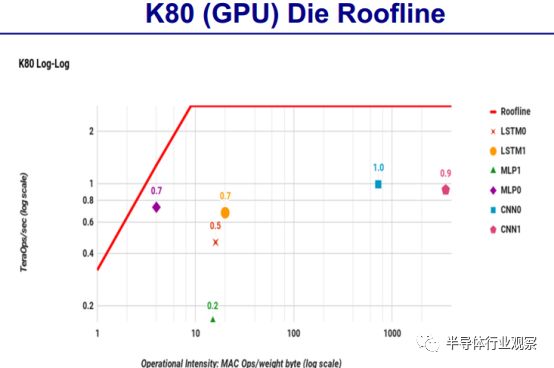
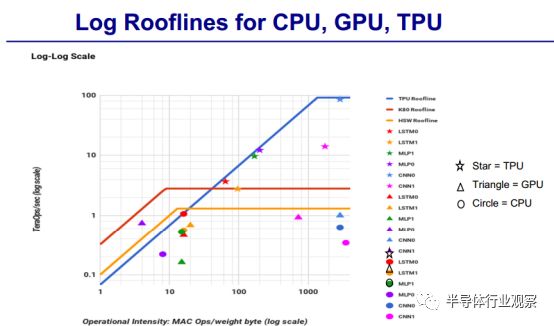
根据David Paterson的介绍,TPU是一个神经网络加速器芯片,将 TPU 与服务器级的 Intel Haswell CPU 和 Nvidia K80 GPU 进行比较,这些硬件都在同一时期部署在同个数据中心。测试负载为基于 TensorFlow 框架的高级描述,应用于实际产品的 NN 应用程序(MLP,CNN 和 LSTM),这些应用代表了我们数据中心承载的95%的 NN 推理需求。
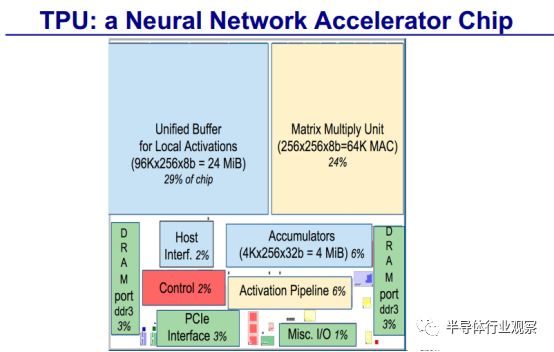
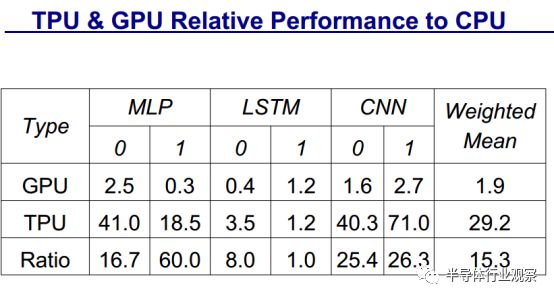
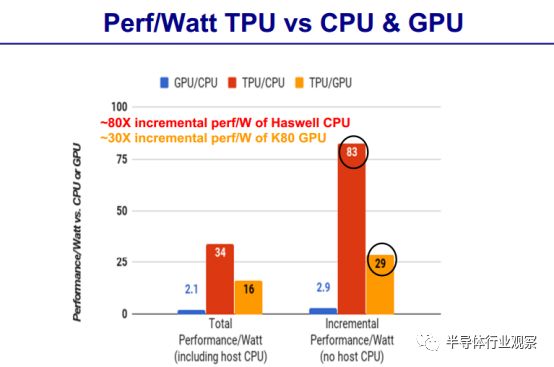
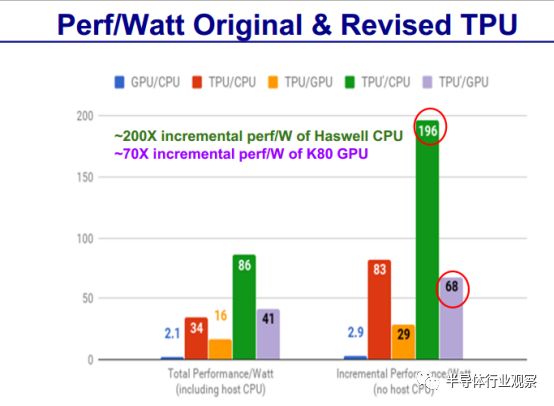
尽管在一些应用上利用率很低,但 TPU 平均比当前的 GPU 或 CPU 快15~30倍,性能功耗比(TOPS/Watt)高出约 30~80 倍。此外,在 TPU 中采用 GPU 常用的 GDDR5 存储器能使性能TPOS指标再高 3 倍,并将能效比指标 TOPS/Watt 提高到 GPU 的 70 倍,CPU 的 200 倍。
David Paterson还做了一个可视的性能模型。
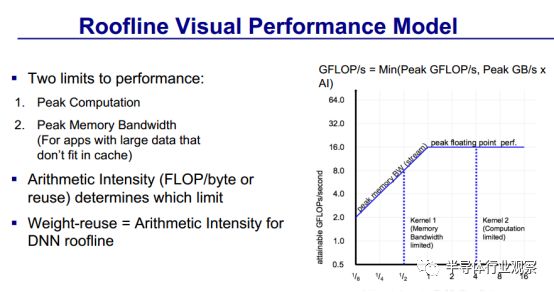
还对TPU /CPU/GPU 的Die Roofline做了对比。
TPU:
CPU:
GPU:
之后David Paterson还对CPU、GPU和TPU的Log Rooflines做了对比。
另外还有Linear Rooflines
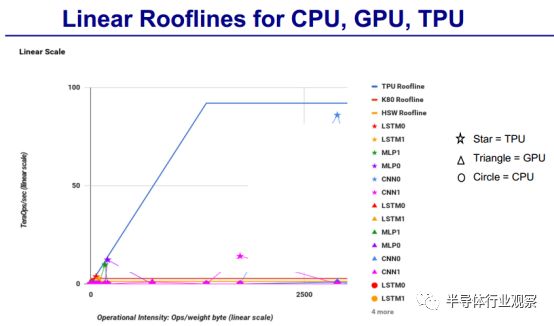
他还将TPU & GPU的相关性能与CPU对比
在性能方面,David Paterson也做了对比。
还对TPU做了数据对比
按照David Paterson的总结了通用CPU开始变慢,特定架构的处理器将会流行与谷歌的TPU在DNN中发生重要作用,能够帮助完成不少任务等问题:

RISC V也是未来的一个机遇
David Paterson表示,SoC上拥有了很多ISA。

紧接着,他提出,我们是否真的需要不同的ISA?这些指令集是否真的需要归属于专人?
况且在ISA领域,之前并没有公认的标准,也没有开源免费的ISA,仅有商用的ISA,这让整个ISA领域的生态显得死气沉沉。David Paterson就提出了是否存在一个免费的ISA让所有人都能够使用的问题?于是,RISC-V应运而生。
要做开源的ISA,基于x86和ARM都几乎不可能,因为它们都太复杂,而且还存在IP的问题。
在2010年夏天,Paterson教授带领团队开始从头开始设计一个干净的ISA。经历了很多年,经过多次流片验证,终于在2014年发布了最终版spec,就是RISC-V(V是第五代的意思)。

RISC-V作为一个开源ISA,首先要满足对ISA的一般要求。
首先,它必须与现存的主流编程语言和软件兼容。
第二,它必须有直接硬件实现,而不是一个虚拟机。
第三,它必须有很好的弹性,能满足小至微控制器(MCU)大到超级计算机的需求。
第四,能与各种实现方式兼容,包括FPGA,ASIC,全定制CPU,以及未来的其他实现。
第五,需要与各种微架构配适,包括有序执行,无序执行,单发射,超标量等等。
最后,还需要满足可扩展性(可以作为基础ISA,在特殊用途中加上额外的增强ISA),以及稳定性(不会一直变化,不会突然消失等等)。
除了满足一般的需求外,RISC-V还有自己的特色。
这个新近流行的架构还具备以下特点:
首先,它很简单,比其他的商用ISA规模都要小很多。
第二,它很干净,例如在用户与特权ISA之间泾渭分明,有非常清晰的界限。另外,RISC-V中没有与微架构或实现方式有关的特性,因此具有普适性。
第三,RISC-V是模块化的ISA,它的基础ISA集很小,但是可以根据用户需求去加载扩展集。
最后,RISC-V特别为了可扩展性和专精化做了优化,使用了可变长度的指令编码,并且有许多空间以供指令集扩展。

最特别的一点是,RISC-V支撑了一个开源的社区,包含了非盈利基金会以及开源代码库。RISC-V的愿景是未来各种灵活而低价处理器芯片的基础。RISC-V一开始的贡献者包括伯克利和SiFive(一家初创公司),目前在征求各类设计者加入开源社区,需要代码以及其他硬件IP(如PLL,PHY等等)。

现在的RISC-V联盟拥有了过百个会员:

另外还有很多的工作组:
David Paterson最后还总结一下几大使用RISC和RISC-V的理由。
第一,35年以来,RISC始终是一个好主意。
第二,RISC-V是免费开源架构,无须付费。
第三,它的ISA比起其他ISA来说简单许多,因此验证起来也方便许多。RISC-V可以在各种设计中比起其他ISA更高效,面积、功耗和性能都更好
第四,RISC-V很稳定,不用担心突然发生很大变化或者直接就消失。
第五,RISC-V可以作为各种SoC核的基础ISA。
现在RISC-V的小目标,是成为一种适合各种计算设备的业界标准ISA。一个新的处理器时代即将到来。
-
专用处理器,未来电机驱动的主流2015-12-31 5350
-
多核处理器的优点2019-06-20 5177
-
浅谈ARM处理器架构2020-08-18 4340
-
谈谈嵌入式处理器的体系架构2021-12-15 1904
-
全新微处理器架构SPEAr13002010-06-04 1105
-
专家观点:处理器核心越多越好吗?2012-03-08 4219
-
ARM专家:未来处理器向多核心架构、高效能发展2013-05-05 2642
-
ARM公版架构 真的是麒麟处理器的槽点吗?2017-01-04 3910
-
基于面向i.MX应用处理器的可靠架构2017-10-31 1842
-
音频处理器的架构_音频处理器的延时怎么调整2020-04-09 6169
-
EE-243:使用SHARC®处理器的专家DAI2021-04-17 1470
-
车载处理器如何赋能未来汽车电子电气架构?本文告诉你……2022-11-16 2147
-
处理器架构与指令集2023-04-26 9025
-
简单认识MIPS架构处理器2023-11-29 4238
-
微处理器的指令集架构介绍2024-08-22 3925
全部0条评论

快来发表一下你的评论吧 !
