

Arm NN:在移动和嵌入式设备上无缝构建和运行机器学习应用程序
电子说
描述
Arm NN
最近,Arm宣布推出神经网络机器学习(ML) 软件 Arm NN。这项关键性技术,可在基于 Arm 的高能效平台上轻松构建和运行机器学习应用程序。
实际上,该软件桥接了现有神经网络框架(例如 TensorFlow 或 Caffe)与在嵌入式 Linux 平台上运行的底层处理硬件(例如 CPU、GPU 或新型 Arm 机器学习处理器)。这样,开发人员能够继续使用他们首选的框架和工具,经 Arm NN 无缝转换结果后可在底层平台上运行。
机器学习需要一个训练阶段,也就是学习阶段(“这些是猫的图片”),另外还需要一个推理阶段,也就是应用所学的内容(“这是猫的图片吗?”)。训练目前通常在服务器或类似设备上发生,而推理则更多地转移到网络边缘,这正是新版本 Arm NN 的重点所在。
一切围绕平台
机器学习工作负载的特点是计算量大、需要大量存储器带宽,这正是移动设备和嵌入式设备面临的最大挑战之一。随着运行机器学习的需求日益增长,对这些工作负载进行分区变得越来越重要,以便充分利用可用计算资源。软件开发人员面临的可能是很多不同的平台,这就带来一个现实问题:CPU 通常包含多个内核(在 Arm DynamIQ big.LITTLE 中,甚至还有多种内核类型),还要考虑 GPU,以及许多其他类型的专用处理器,包括 Arm 机器学习处理器,这些都是整体解决方案的一部分。Arm NN 这时就能派上用场。
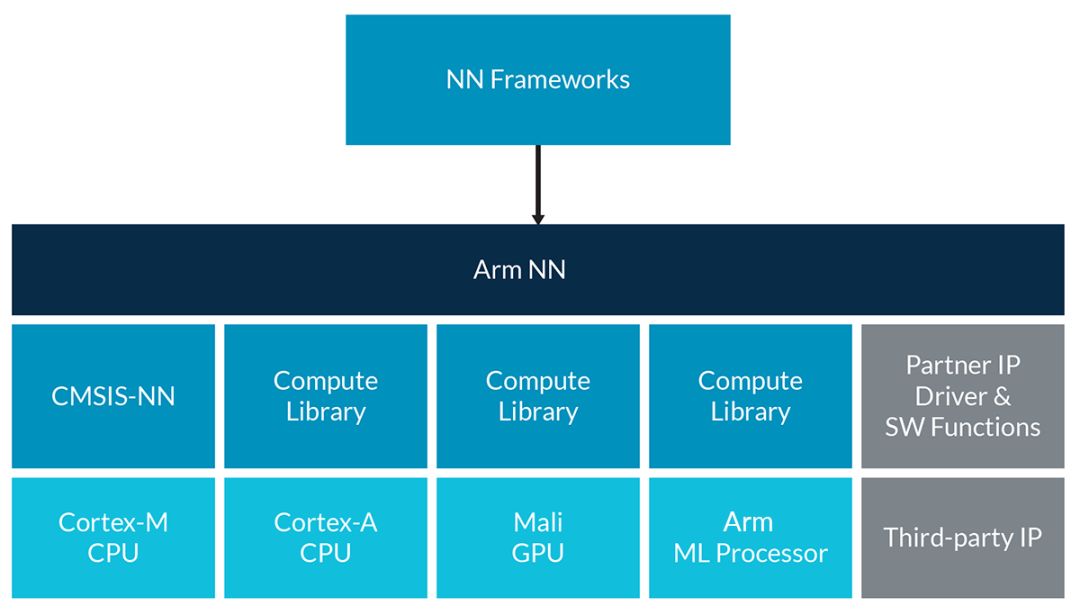
下图中可以看出,Arm NN 扮演了枢纽角色,既隐藏了底层硬件平台的复杂性,同时让开发人员能够继续使用他们的首选神经网络框架。


Arm NN SDK 概览(首次发布版本)
您可能已经注意到,Arm NN 的一个关键要求是 Compute Library,它包含一系列低级别机器学习和计算机视觉函数,面向 Arm Cortex-A CPU 和 Arm Mali GPU。我们的目标是让这个库汇集针对这些函数的一流优化,近期的优化已经展示了显著的性能提升 – 比同等 OpenCV 函数提高了 15 倍甚至更多。如果您是Cortex-M CPU 的用户,现在还有一个机器学习原语库 – 也就是近期发布的 CMSIS-NN。
CMSIS-NN 是一系列高效神经网络内核的集合,其开发目的是最大程度地提升神经网络的性能,减少神经网络在面向智能物联网边缘设备的 Arm Cortex-M 处理器内核上的内存占用。Arm开发这个库的目的是全力提升这些资源受限的 Cortex CPU 上的神经网络推理性能。借助基于 CMSIS-NN 内核的神经网络推理,运行时/吞吐量和能效可提升大约 5 倍。
主要优势
有了 Arm NN,开发人员可以即时获得一些关键优势:
更轻松地在嵌入式系统上运行 TensorFlow 和 Caffe
Compute Library 内部的一流优化函数,让用户轻松发挥底层平台的强大性能
无论面向何种内核类型,编程模式都是相同的
现有软件能够自动利用新硬件特性
与 Compute Library 相同,Arm NN 也是作为开源软件发布的,这意味着它能够相对简单地进行扩展,从而适应 Arm 合作伙伴的其他内核类型。
适用于 Android 的 Arm NN
在五月举行的 Google I/O 年会上,Google 发布了针对 Android 的 TensorFlow Lite,预示着主要新型 API 开始支持在基于 Arm 的 Android 平台上部署神经网络。表面上,这与 Android 下的 Arm NN SDK 解决方案非常相似。使用 NNAPI 时,机器学习工作负载默认在 CPU 上运行,但硬件抽象层 (HAL) 机制也支持在其他类型的处理器或加速器上运行这些工作负载。Google 发布以上消息的同时,我们的 Arm NN 计划也进展顺利,这是为使用 Arm NN 的 Mali GPU 提供 HAL。今年晚些时候,我们还将为 Arm 机器学习处理器提供硬件抽象层。
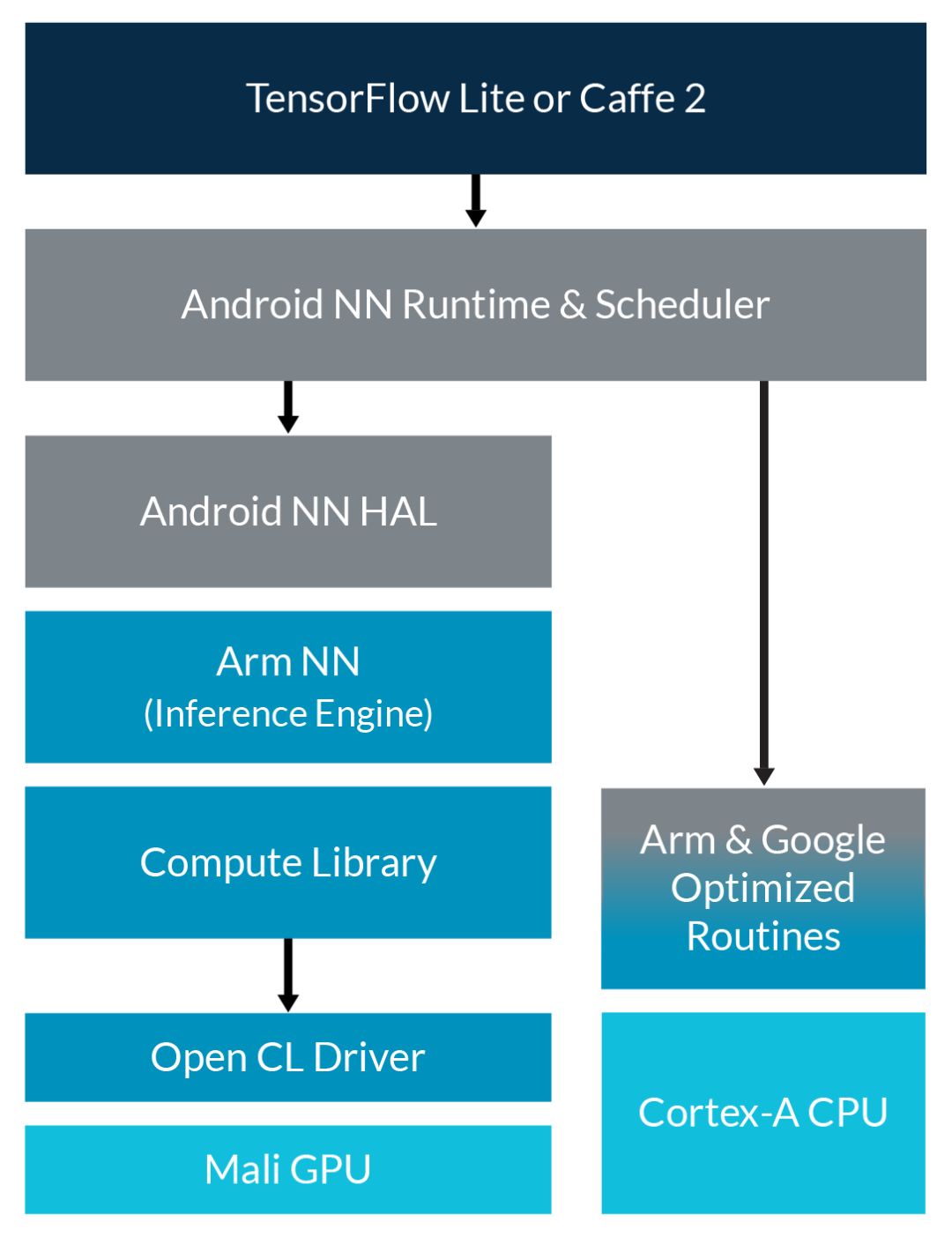
Arm 对 Google NNAPI 的支持概览
Arm NN 的未来发展
这只是 Arm NN 的第一步:我们还计划添加其他高级神经网络作为输入,对 Arm NN 调试程序执行进一步的图形级别优化,覆盖其他类型的处理器或加速器……请密切关注今年的发展!
-
如何将应用程序移植到运行在基于Arm的设备上的Windows?2023-08-02 663
-
嵌入式学习路线你知道吗?2023-06-14 1342
-
在Linux上使用Arm NN分析和优化运行推理的机器学习应用程序的步骤2022-09-27 2296
-
介绍一种Arm ML嵌入式评估套件2022-08-12 3173
-
使用Streamline分析在Linux上运行的Arm NN机器学习应用程序2022-08-11 2975
-
如何构建和编译一个Qt界面应用程序2021-11-04 1445
-
嵌入式Linux应用程序开发-(1)第一个嵌入式QT应用程序2021-11-01 1177
-
嵌入式Linux应用程序例程2021-07-30 1384
-
构建和优化嵌入式和物联网应用程序2020-05-31 2834
-
一种基于ARM的嵌入式图像处理系统设计2019-07-08 3842
-
移动和嵌入式设备上也能直接玩机器学习?2018-03-22 7858
-
嵌入式学习路线2016-09-20 6351
-
ARM嵌入式应用程序架构设计工具2016-09-13 866
-
ARM嵌入式应用程序架构设计工具-字库2016-07-08 1049
全部0条评论

快来发表一下你的评论吧 !
