

谷歌FHIR标准协议利用深度学习预测医疗事件发生
医疗电子
描述
谷歌在arXiv上发表的一篇论文《Scalable and accurate deep learning for electronic health records》( Alvin Rajkomar et al.)。文中他们提出基于快速医疗保健互操作性资源(FHIR)格式的患者EHR原始记录表示,利用深度学习的方法,准确预测了多起医疗事件的发生。

论文摘要如下:
使用电子健康记录(EHR)数据的预测建模预计将推动个人化医疗并提高医疗质量。构建预测性统计模型通常需要从规范化的EHR数据中提取策略预测变量,这是一种劳动密集型过程,且放弃了患者记录中绝大多数信息。我们提出基于快速医疗保健互操作性资源(FHIR)格式的患者全部EHR原始记录的表示。我们证明使用这种表示方法的深度学习方法能够准确预测来自多个中心的多个医疗事件,而无需特定地点的数据协调。我们使用来自两个美国学术医疗中心的去识别的EHR数据验证了我们的方法,其中216,221位成年患者住院至少24小时。在我们提出的序列格式中,这一块EHR数据总计包含了46,864,534,945个数据点,包括临床说明。深度学习模型对预测院内死亡率(AUROC跨站点0.93-0.94),30天无计划再入院率(AUROC 0.75-0.76),延长住院时间(AUROC 0.85-0.86)以及所有患者的最终诊断(频率加权AUROC 0.90)等取得了极高的准确度。在所有情况下,这些模型的表现都优于传统的预测模型。我们还介绍了一个神经网络归因系统的案例研究,该系统说明临床医生如何获得预测的一些透明度。我们相信,这种方法可以为各种临床环境创建准确的、可扩展的预测,且附有在患者图标中直接高亮证据的解释。
在这项研究过程中,他们认为若想大规模的实现机器学习,则还需要对FHIR标准增加一个协议缓冲区工具,以便将大量数据序列化到磁盘以及允许分析大型数据集的表示形式。
昨天,谷歌发布消息称已经开源该协议缓冲区工具。下面为谷歌博文内容,小编编译如下:
过去十年来,医疗保健的数据在很大程度上已经从纸质文件中转变为数字化为电子健康记录。但是要想理解这些数据可能还存在一些关键性挑战。
首先,在不同的供应商之间没有共同的数据表示,每个供应商都在使用不同的方式来构建他们的数据;
其次,即使使用同一个供应商网站上的数据,可能也会有很大的不同,例如他们通常对相同的药物使用多种代码来表示;
第三,数据可能分布在许多不同表格中,这些表格有些存在交集,有些包含着实验数据,还有些包含着一些生命体征。
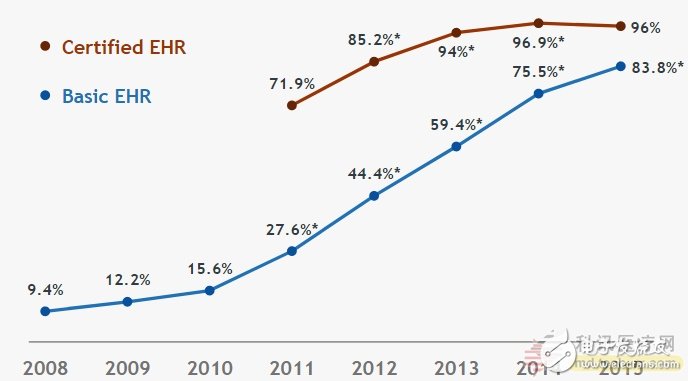
采用至少一个基本电子病历系统并拥有经过认证的电子病历系统的非联邦急性护理医院的百分比。Basic的电子健康记录( Electronic Health Record ,EHR)满足EHR系统的基本功能,Certified EHR表示医院已经与EHR有法律协议,但不等同于采用了EHR系统。
快速医疗保健互操作性资源(Fast Healthcare Interoperability Resources,FHIR)作为一项标准草案,描述的是用于交换电子病历数据格式和数据元以及应用程序界面,该标准由医疗服务标准组织Health Level Seven International制定。这项标准已经解决了这些挑战中的大多数:它具有坚实的、可扩展的数据模型,建立在既定的Web标准之上,并且正在迅速成为个人记录和批量数据访问中事实上的标准。但若想实现大规模机器学习,我们还需要对它做一些补充:使用多种编程语言的工具,作为将大量数据序列化到磁盘的有效方法以及允许分析大型数据集的表示形式。
今天,我们很高兴开源了FHIR标准的协议缓冲区工具,该工具能够解决以上这些问题。当前的版本支持Java语言,随后很快也将支持C++ 、Go和Python等语言。另外,对于配置文件的支持以及帮助将遗留数据转换为FHIR的工具也将很快推出。
FHIR作为核心数据模型
在过去几年中,我们一直在与学术医疗中心进行合作,利用机器学习的方法“去识别”(de-identified)医疗记录(即剥离任何个人身份信息,以预测未来可能的情况,可以在症候出现前预知患者的需求。),很明显我们需要正视医疗保健数据中的复杂性。事实上,机器学习对于医疗数据来说非常有效,因此我们希望能够更加全面地了解每位患者随着时间的推移发生了什么。作为红利,我们希望拥有一个能够直接应用于临床环境的数据表示。
尽管FHIR标准能够满足我们的大多数的需求,但是使用医疗数据将比“传统”的数据结构更容易管理,并且实现了对立于供应商的大规模机器学习。我们相信缓冲区的引入可以帮助应用程序开发人员(机器学习相关)和研究人员使用FHIR。
协议缓冲区的当前版本
我们已经努力使我们的协议缓冲区表示能够通过编程式访问以及数据库查询。提供的一个示例显示了如何将FHIR数据上传到Google Cloud的BigQuery(注:BigQuery 是 Google 专门面向数据分析需求设计的一种全面托管的 PB 级低成本企业数据仓库。)并将其提供给外部查询。我们也正在添加其他直接从批量数据导出并上传的示例。我们的协议缓冲区遵循FHIR标准(它们实际上是由FHIR标准自动生成的),但也可以采用更优雅的查询方式。
目前的版本还没有包括对训练TensorFlow模型提供支持,但未来将更新。我们的目标是尽可能地开源我们最近的工作,以帮我们的研究,使其更具可重复性并能够适用于现实世界的场景当中。此外,我们正与Google Cloud中的同事进行密切合作,研究更多用于管理医疗保健数据的工具。
-
谷歌深度学习插件tensorflow2018-07-04 0
-
利用ECS进行深度学习详细攻略2018-12-24 0
-
深度学习在预测和健康管理中的应用2021-07-12 0
-
深度学习模型是如何创建的?2021-10-27 0
-
使用keras搭建神经网络实现基于深度学习算法的股票价格预测2022-02-08 0
-
深度学习的机会网络链路预测2018-01-04 836
-
谷歌利用深度学习将眼睛视为个人健康的“指示器”2018-01-09 3471
-
谷歌使用深度学习分析视网膜图像来识别心脏病2018-02-23 8323
-
Google深度学习模型预测效果 优于传统EHR数据分析2018-05-23 1768
-
当机器翻译遇见深度学习2018-05-18 2728
-
谷歌开发机器学习模型,预警潜在危险2020-04-15 2771
-
谷歌利用VR技术和显微镜结合用于癌症检测2020-07-14 631
-
深度学习革命的10个领域2021-01-07 3672
-
基于深度学习的信息级联预测方法研究综述2021-05-18 941
-
癫痫发作预测可穿戴设备的深度学习2022-12-12 543
全部0条评论

快来发表一下你的评论吧 !
