

用Reality AI Tools创建模型
描述
三创建模型与部署
本节要点
在第二步采集到的数据基础之上,用Reality AI Tools创建模型。
步骤
1.1点击Asset Tracking,激活此项目。
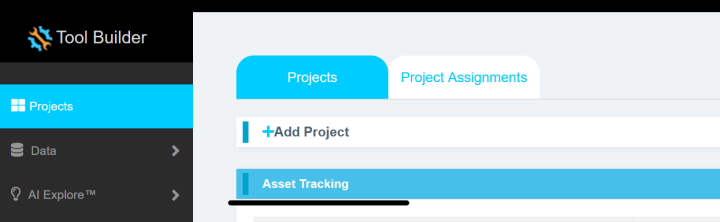
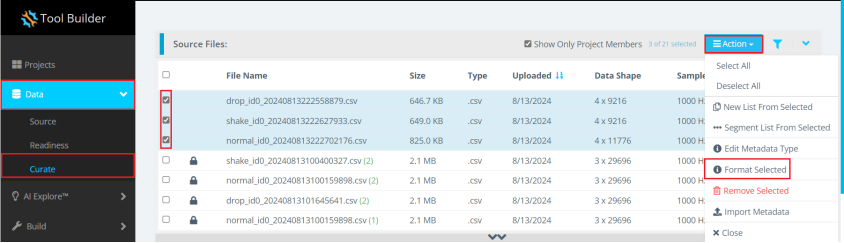
点击左侧Data界面,按照如下步骤操作:
点击Curate。
点击数据文件展开按钮。
勾选数据文件。
点击Action。
点击Format Selected。
1.2在弹出的窗口中,按下述步骤操作:
点击#1 Data,并下拉到最下面,选择Ignore。(注意:这一步非常重要)。
输入采样率1600。
点击Confirm。

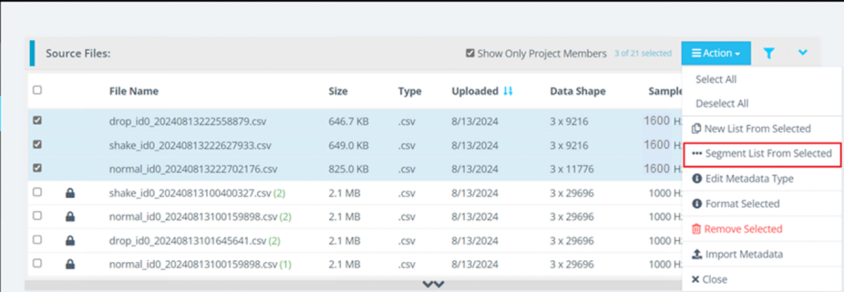
1.3点击Action->Segment List From Selected,进行数据分段。
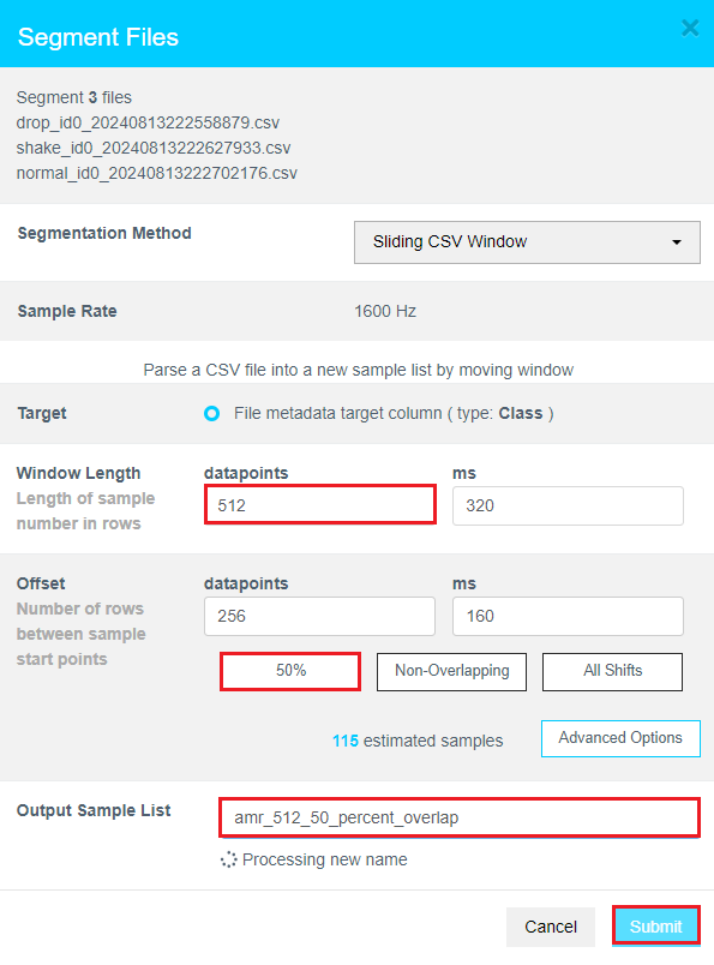
1.4按照如下步骤:
Window Length Datapoints选择512。
Offset Datapoints选择50%。
List名称为amr_512_50_percent_overlap。
点击Submit。
在这里解释一下,滑动窗口的作用:
避免窗口边缘特征的丢失。
增加样本的数量。
滑动窗口允许背靠背分段数据之间的重叠。
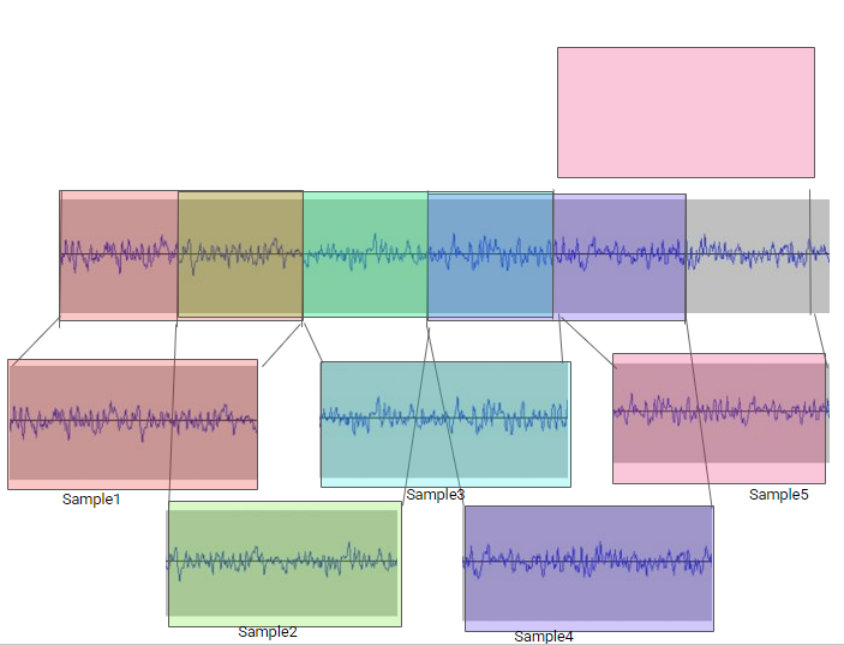
Sample 1和2之间有50%重叠。
Sample 2和3之间有50%重叠。
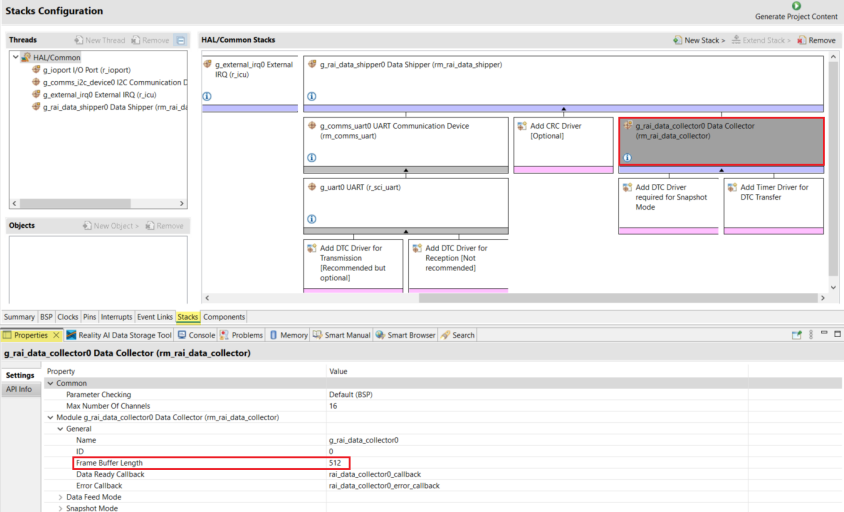
1.5在e2 studio中的configuration.xml中的stack部分Properties页面中Data Shipper/Data Collector/General/Frame Buffer Length,可以设置MCU采集数据时的滑动窗口大小。
本实验滑动窗口的设置是512。
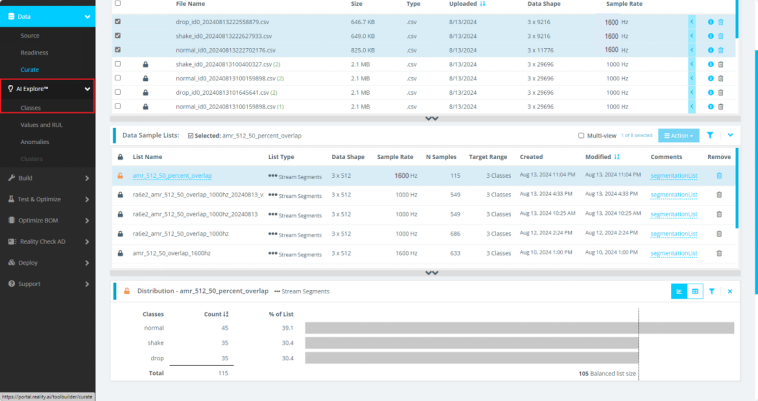
1.6当数据分段完成后,点击左侧AI Explore->Classes。
1.7点击先前创建的amr_512_50_percent_overlap。再点击界面下部的Start exploring。
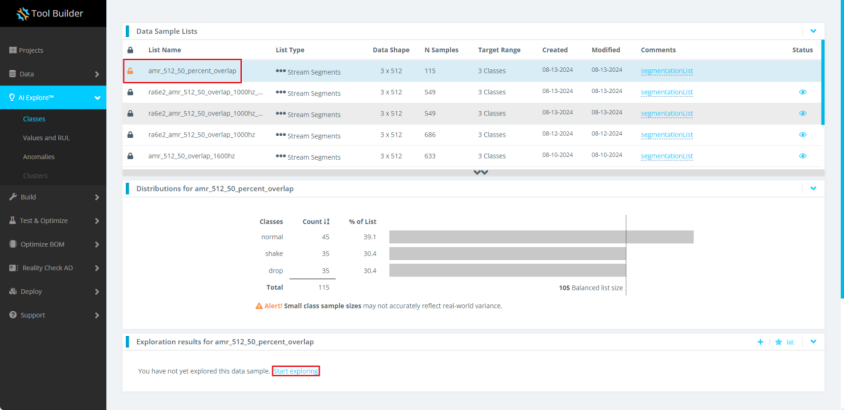
此时,模型正在生成中。模型生成的过程中,允许退出系统或者进行其他操作。这些操作并不会中断或者影响模型生成。

1.8大概等待10~25分钟左右后,模型生成完成,模型生成时长与训练数据大小有关。
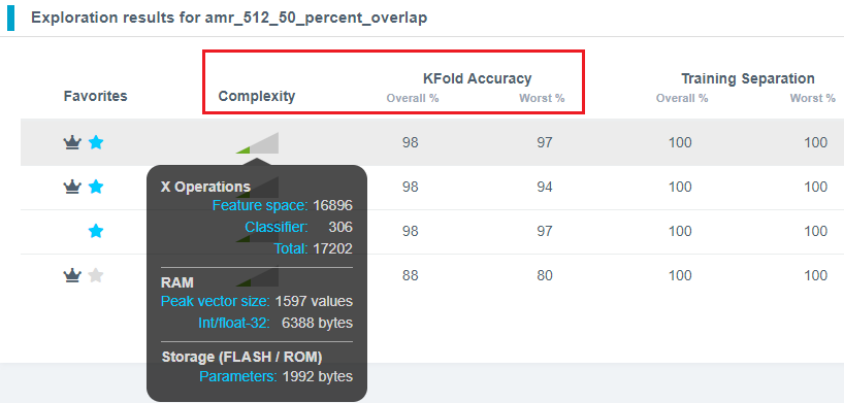
如何选择适合自己的模型呢?主要关注Complexity和KFold Accuracy两个指标。
点击Complexity列的三角图标,它显示当前模型的相关参数。
X Operations表示模型运行中的MAC(乘累加)操作数量。
RAM表示模型运行中所需RAM的大小。
Storage(FLASH/ROM)表示模型运行中所需FLASH的大小。
注意:上述的RAM和FLASH的数值,是以云端服务器硬件平台为基准显示的,仅供参考。部署到实际项目中的MCU/MPU平台中的RAM和FLASH的数值,可能会与这个不同。
KFold Accuracy表示K折交叉验证的模型精度。交叉验证的基本思想是将原始数据集分成多个部分,一部分当作训练集,另一部分作为验证集。先用训练集对算法模型进行训练,再用验证集测试训练得到的算法模型,反复利用这些部分进行模型的训练和验证。Overall %表示本模型的整体精度,数值越高越好,Worst %表示本模型的最差精度,数值越高越好。
点击图中“Create Base Tool”,来生成嵌入式端的模型。
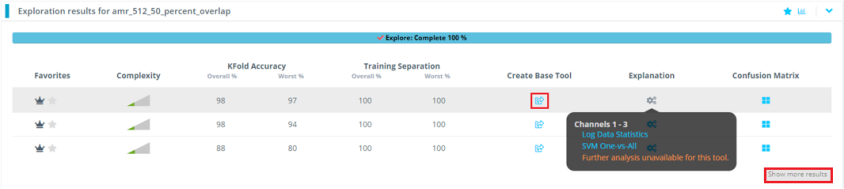
注意:Reality AI Tools会生成许多模型,点击右下角的” Show more results” 可以看到被折叠隐藏的更多模型。
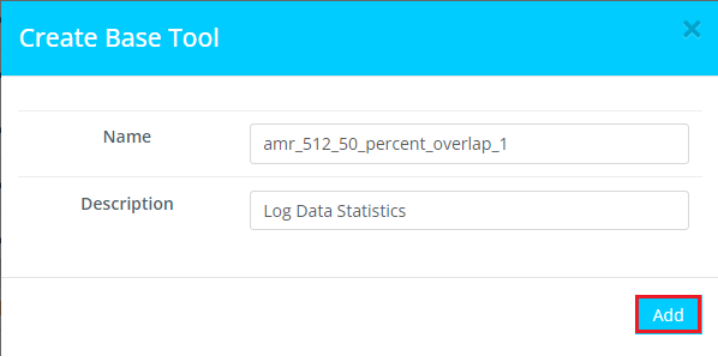
1.9使用默认的名称,或者输入模型名称和描述。点击“Add”。
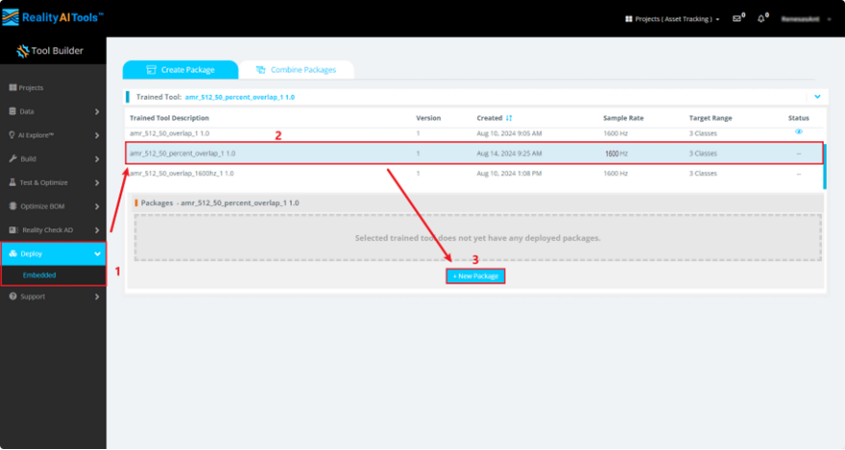
1.10现在开始创建嵌入式端侧部署模型,按照如下步骤:
点击Deploy->Embedded。
点击Trained Tool Description list。
点击 +New Package。
1.11输入DeployName,这个名字就是待会生成的API的前缀。在Inputs中的Data type中选择float32(float)。因为采集的数据是float32类型的。中间的outputs区域,显示了API的输出类型和含义。右侧的Build Options涵盖目标设备类型(目前RA6E2没有在列表清单中,暂时选择RA6E1),FPU类型选择M33 FPU,hard fp abi,Toolchain选择GNU GCC 13.2.1,优化类型选择Speed。
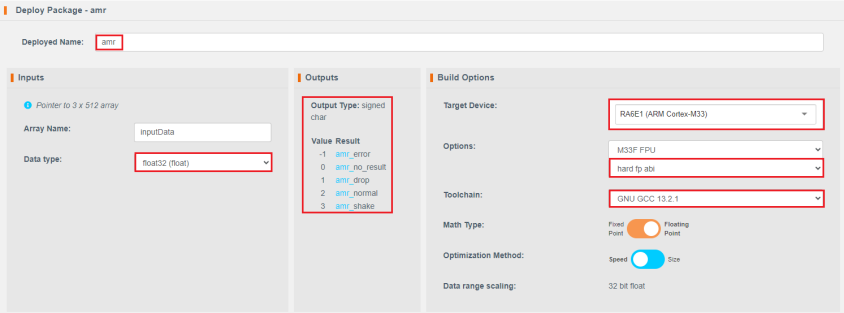
点击Generate New Package,创建模型。

1.12此时,可以看见右侧的Download显示

表示模型生成中。

大概10~25分钟左右。
等到右侧的Download显示

模型生成完成
点击
下载模型文件。

1.13生成的模型文件名称为amr.zip,里面一共有9个文件,
README.txt和model_info.xml是模型相关的信息,包括占用的ROM和RAM信息等。
librai_edsp_f32_arm.a是库文件。
example_classifier.c是模型调用的例子代码,实际使用的时候,不需要添加到工程中。
其余5个文件是模型相关的.c和.h文件。
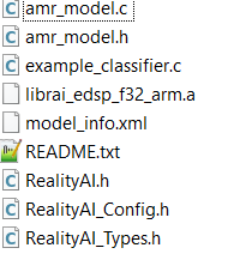
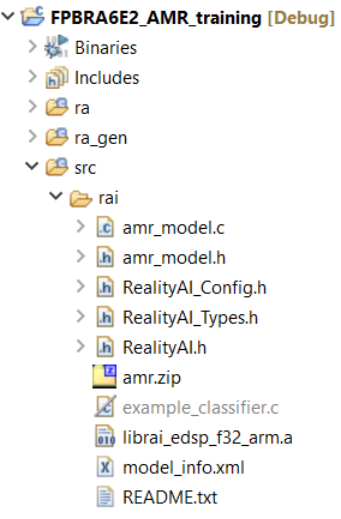
将上述的librai_edsp_f32_arm.a,amr_model.c,amr_model.h,RealityAI.h,RealityAI_Config.h,RealityAI_Types.h文件复制到Asset Tracking工程中的src/rai文件夹中。
1.14在hal_entry.c中添加#include "amr_model.h"。
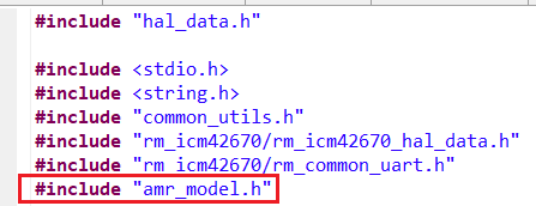
同时把hal_entry.c中的宏定义
#define DATA_COLLECTION_EN (1)
修改成
#define DATA_COLLECTION_EN (0)
表示代码进入推理阶段。
1.15点击图标

来编译工程。
本工程经过编译后,应改没有任何errors或者warnings。
1.16点击按钮

启动调试并检查控制台中的内容是否成功建立了连接。
1.17打开Debug文件中的FPBRA6E2_AMR_training.map文件。
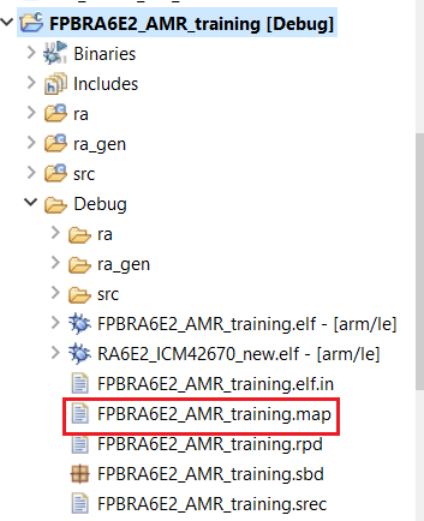
搜索到.bss._SEGGER_RTT字段并复制红色框处地址。
注意:下图中的地址可能和实际的工程不相符,以自己手中的文件为准。
1.18打开J-Link RTT-Viewer,点击File->Connect。
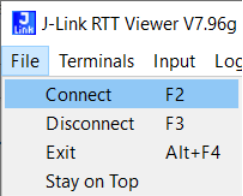
在弹出的窗口中,按照以下图片配置。注意,左下角的地址,输入的是上一步骤复制的地址,点击OK。
看到下面的Log输出框,表示连接成功。
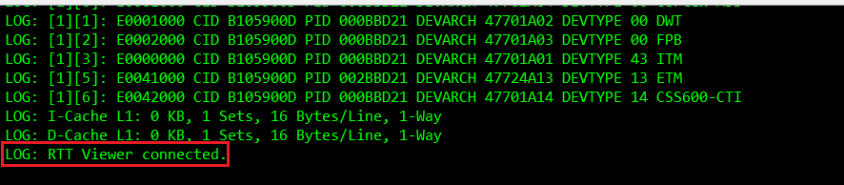
1.19点击Terminal 0标签页。
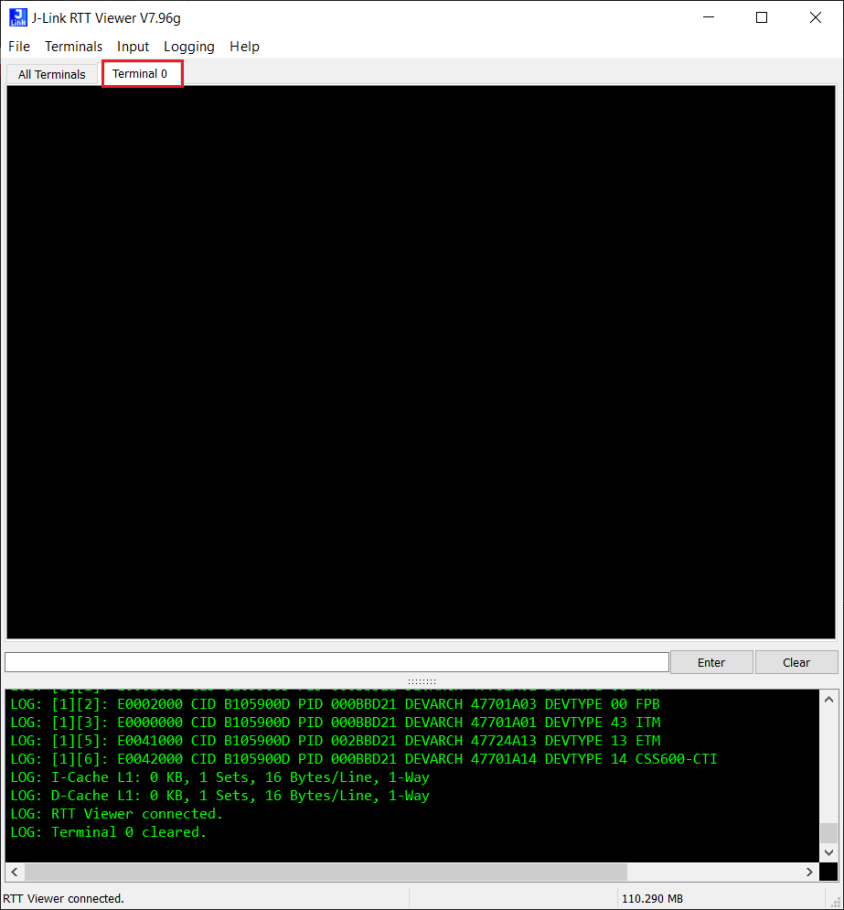
1.20点击图标

两次
此时,程序正常运行起来。

如果在运行的工程中,发现程序停留在startup.c中Default_Handler中。
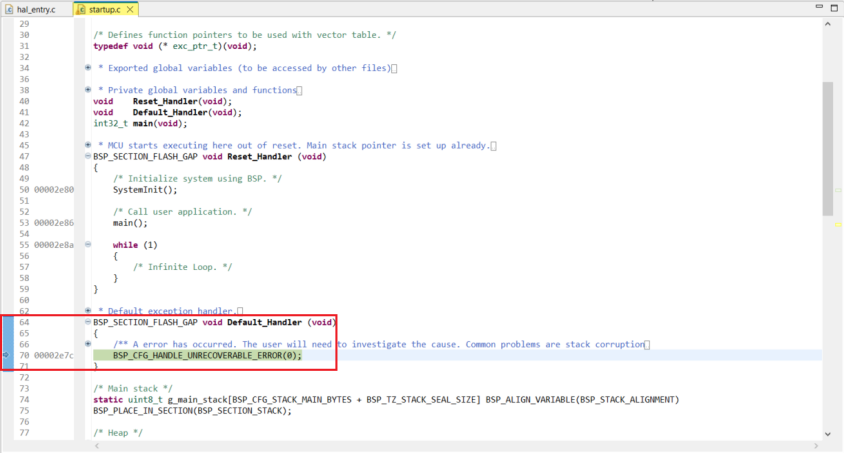
参考先前3.14步骤中下载的模型中的README.txt的Estimated Memory Utilization中的Parameters,Stack Usage和Pre-Allocated之和。还要考虑加上工程本身没有使用模型推理的代码的stack消耗。
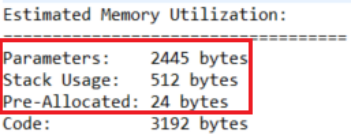
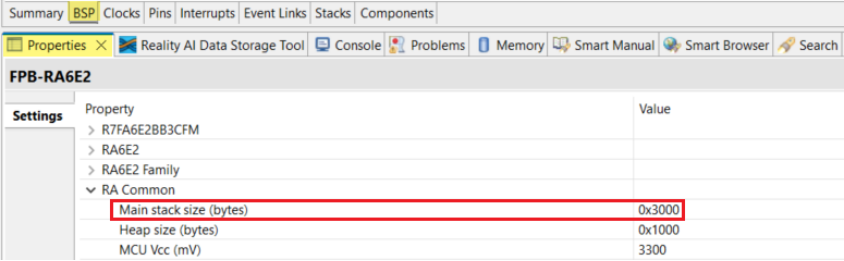
这是工程的stack设定过小,导致堆栈溢出,从而进入Default_Handler。需要在configuration.xml->BSP->Properties->RA Common中的Main stack size(bytes)进行修改。
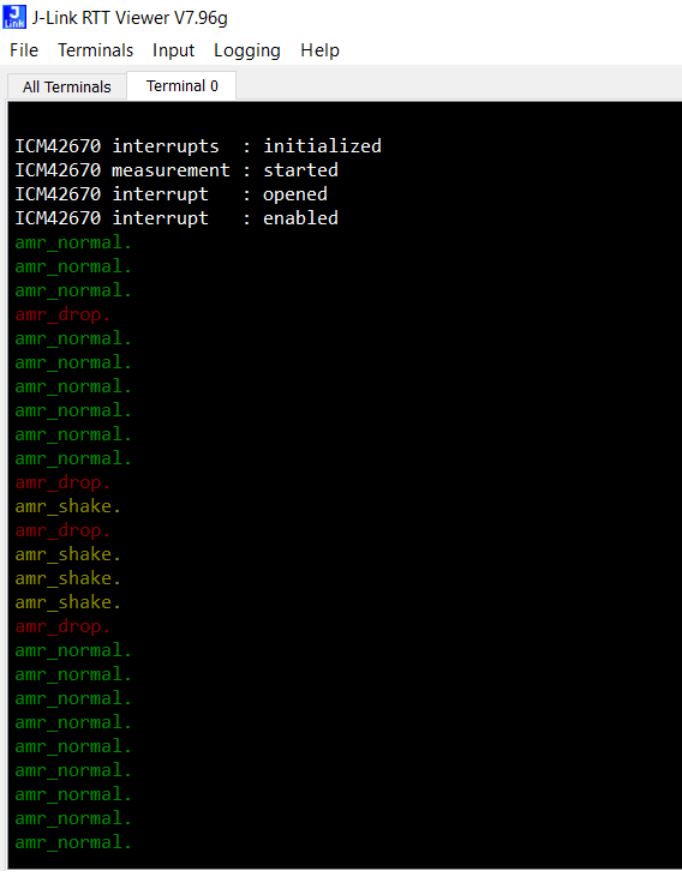
1.21观察J-Link RTT Viewer中的打印信息。通过扔(10cm高处跌落)、摇晃、静止FPB-RA6E2。可以发现得到如下信息:
红色表示FPB-RA6E2处于drop状态。
黄色表示FPB-RA6E2处于shake状态。
绿色表示FPB-RA6E2处于normal状态。
可以尝试采集更多类型动作数据,再次上传数据并训练,以便识别更多的动作。
-
使用cube-AI分析模型时报错的原因有哪些?2024-03-14 1271
-
使用CUBEAI部署tflite模型到STM32F0中,模型创建失败怎么解决?2024-03-15 908
-
STM CUBE AI错误导入onnx模型报错的原因?2024-05-27 1240
-
如何使用Patsy创建模型描述?2020-07-14 1195
-
STM32CubeMX AI介绍2021-08-09 1224
-
深度学习模型是如何创建的?2021-10-27 2415
-
创建Proteus原理图仿真模型2012-03-28 1541
-
land和lp向导创建模型快速而简单,轻松创建CAD库2019-10-12 5186
-
如何使用YAKINDU Statechart Tools创建数字手表2022-08-18 4686
-
十问十答快速了解Reality AI工具软件2023-01-06 2855
-
全新Reality AI Explorer Tier,免费提供强大的AI/ML开发环境综合评估“沙盒”2024-07-16 1335
-
瑞萨电子推出Reality AI Explorer Tier,用于开发AI与TinyML解决方案2024-07-19 1517
-
基于瑞萨电子Reality AI Tools工具的语音反欺骗应用示例2024-08-20 1555
-
瑞萨e2 studio中Reality AI组件的使用方法2025-01-21 2789
-
AI开发平台模型怎么用2025-02-11 1209
全部0条评论

快来发表一下你的评论吧 !
