

DeepSeek-R1本地部署指南,开启你的AI探索之旅
描述
春节期间突然被DeepSeek刷屏了,这热度是真大,到处都是新闻和本地部署的教程,等热度过了过,简单记录下自己本地部署及相关的内容,就当电子宠物,没事喂一喂:D,不过有能力的还是阅读论文和部署完整版的进一步使用。
论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
1|0一、什么是 DeepSeek R1
2025.01.20 DeepSeek-R1 发布,DeepSeek R1 是 DeepSeek AI 开发的第一代推理模型,擅长复杂的推理任务,官方对标OpenAI o1正式版。适用于多种复杂任务,如数学推理、代码生成和逻辑推理等。
DeepSeek-R1 发布的新闻:https://api-docs.deepseek.com/zh-cn/news/news250120

根据官方信息DeepSeek R1 可以看到提供多个版本,包括完整版(671B 参数)和蒸馏版(1.5B 到 70B 参数)。完整版性能强大,但需要极高的硬件配置;蒸馏版则更适合普通用户,硬件要求较低
DeepSeek-R1官方地址:https://github.com/deepseek-ai/DeepSeek-R1
完整版(671B):需要至少 350GB 显存/内存,适合专业服务器部署
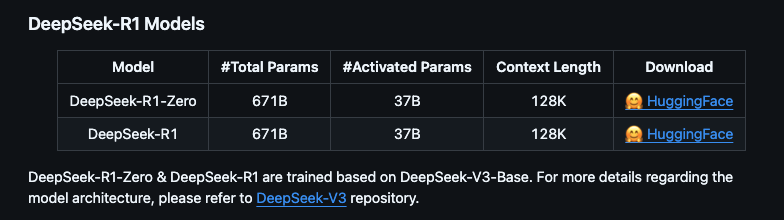
蒸馏版:基于开源模型(如 QWEN 和 LLAMA)微调,参数量从 1.5B 到 70B 不等,适合本地硬件部署。
蒸馏版与完整版的区别
| 特性 | 蒸馏版 | 完整版 |
|---|---|---|
| 参数量 | 参数量较少(如 1.5B、7B),性能接近完整版但略有下降。 | 参数量较大(如 32B、70B),性能最强。 |
| 硬件需求 | 显存和内存需求较低,适合低配硬件。 | 显存和内存需求较高,需高端硬件支持。 |
| 适用场景 | 适合轻量级任务和资源有限的设备。 | 适合高精度任务和专业场景。 |
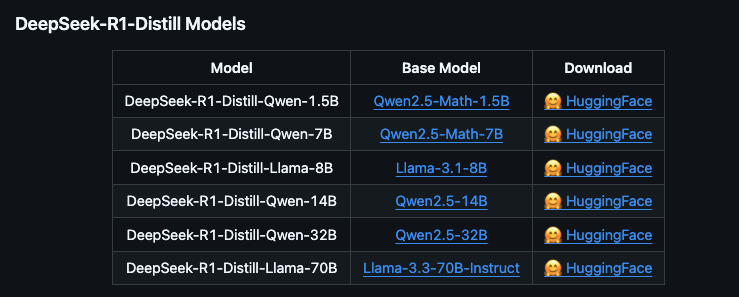
这里我们详细看下蒸馏版模型的特点
| 模型版本 | 参数量 | 特点 |
|---|---|---|
| deepseek-r1:1.5b | 1.5B | 轻量级模型,适合低配硬件,性能有限但运行速度快 |
| deepseek-r1:7b | 7B | 平衡型模型,适合大多数任务,性能较好且硬件需求适中。 |
| deepseek-r1:8b | 8B | 略高于 7B 模型,性能稍强,适合需要更高精度的场景。 |
| deepseek-r1:14b | 14B | 高性能模型,适合复杂任务(如数学推理、代码生成),硬件需求较高。 |
| deepseek-r1:32b | 32B | 专业级模型,性能强大,适合研究和高精度任务,需高端硬件支持。 |
| deepseek-r1:70b | 70B | 顶级模型,性能最强,适合大规模计算和高复杂度任务,需专业级硬件支持。 |
进一步的模型细分还分为量化版
| 模型版本 | 参数量 | 特点 |
|---|---|---|
| deepseek-r1:1.5b-qwen-distill-q4_K_M | 1.5B | 轻量级模型,适合低配硬件,性能有限但运行速度快 |
| deepseek-r1:7b-qwen-distill-q4_K_M | 7B | 平衡型模型,适合大多数任务,性能较好且硬件需求适中。 |
| deepseek-r1:8b-llama-distill-q4_K_M | 8B | 略高于 7B 模型,性能稍强,适合需要更高精度的场景。 |
| deepseek-r1:14b-qwen-distill-q4_K_M | 14B | 高性能模型,适合复杂任务(如数学推理、代码生成),硬件需求较高。 |
| deepseek-r1:32b-qwen-distill-q4_K_M | 32B | 专业级模型,性能强大,适合研究和高精度任务,需高端硬件支持。 |
| deepseek-r1:70b-llama-distill-q4_K_M | 70B | 顶级模型,性能最强,适合大规模计算和高复杂度任务,需专业级硬件支持。 |
蒸馏版与量化版
| 模型类型 | 特点 |
|---|---|
| 蒸馏版 | 基于大模型(如 QWEN 或 LLAMA)微调,参数量减少但性能接近原版,适合低配硬件。 |
| 量化版 | 通过降低模型精度(如 4-bit 量化)减少显存占用,适合资源有限的设备。 |
例如:
deepseek-r1:7b-qwen-distill-q4_K_M:7B 模型的蒸馏+量化版本,显存需求从 5GB 降至 3GB。
deepseek-r1:32b-qwen-distill-q4_K_M:32B 模型的蒸馏+量化版本,显存需求从 22GB 降至 16GB
我们正常本地部署使用蒸馏版就可以
2|0二、型号和硬件要求
2|12.1硬件配置说明
Windows 配置:
最低要求:NVIDIA GTX 1650 4GB 或 AMD RX 5500 4GB,16GB 内存,50GB 存储空间
推荐配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 内存,100GB NVMe SSD
高性能配置:NVIDIA RTX 3090 24GB 或 AMD RX 7900 XTX 24GB,64GB 内存,200GB NVMe SSD
Linux 配置:
最低要求:NVIDIA GTX 1660 6GB 或 AMD RX 5500 4GB,16GB 内存,50GB 存储空间
推荐配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 内存,100GB NVMe SSD
高性能配置:NVIDIA A100 40GB 或 AMD MI250X 128GB,128GB 内存,200GB NVMe SSD
Mac 配置:
最低要求:M2 MacBook Air(8GB 内存)
推荐配置:M2/M3 MacBook Pro(16GB 内存)
高性能配置:M2 Max/Ultra Mac Studio(64GB 内存)
可根据下表配置选择使用自己的模型
| 模型名称 | 参数量 | 大小 | VRAM (Approx.) | 推荐 Mac 配置 | 推荐 Windows/Linux 配置 |
|---|---|---|---|---|---|
| deepseek-r1:1.5b | 1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
| deepseek-r1:7b | 7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
| deepseek-r1:8b | 8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
| deepseek-r1:14b | 14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
| deepseek-r1:32b | 32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
| deepseek-r1:70b | 70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
| deepseek-r1:1.5b-qwen-distill-q4_K_M | 1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
| deepseek-r1:7b-qwen-distill-q4_K_M | 7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
| deepseek-r1:8b-llama-distill-q4_K_M | 8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
| deepseek-r1:14b-qwen-distill-q4_K_M | 14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
| deepseek-r1:32b-qwen-distill-q4_K_M | 32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
| deepseek-r1:70b-llama-distill-q4_K_M | 70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
3|0三、本地安装 DeepSeek R1
我这里的演示的本地环境:
机器:M2/M3/M4 MacBook Pro (16GB RAM+)
模型:deepseek-r1:8b
简单说下在本地运行的好处
隐私:您的数据保存在本地的设备上,不会通过外部服务器
离线使用:下载模型后无需互联网连接
经济高效:无 API 成本或使用限制
低延迟:直接访问,无网络延迟
自定义:完全控制模型参数和设置
之后如果有Windows/Linux的场景需要在后续进行更新。
3|13.1部署工具
部署可以使用Ollama、LM Studio、Docker等进行部署
Ollama:
本地大模型管理框架,Ollama 让用户能够在本地环境中高效地部署和使用语言模型,而无需依赖云服务
支持 Windows、Linux 和 Mac 系统,提供命令行和 Docker 部署方式
使用命令 ollama run deepseek-r1:7b 下载并运行模型
LM Studio:
LM Studio 是一个桌面应用程序,它提供了一个用户友好的界面,允许用户轻松下载、加载和运行各种语言模型(如 LLaMA、GPT 等)
支持 Windows 和 Mac,提供可视化界面,适合新手用户
支持 CPU+GPU 混合推理,优化低配硬件性能
Docker:
支持 Linux 和 Windows,适合高级用户。
使用命令 docker run -d --gpus=all -p 11434:11434 --name ollama ollama/ollama 启动容器。
由于需要本地化部署语言模型的场景,对数据隐私和自定义或扩展语言模型功能有较高要求,我们这里使用Ollama来进行本地部署运行
如果只有集显也想试试玩,可以试试下载LM Studio软件,更适应新手,如果有需要后续更新
3|23.2 安装 ollama
官方地址:https://ollama.com/
选择自己的系统版本进行下载
安装完成
控制台验证是否成功安装
我们再回到ollama官网选择模型,选择需要的模型复制命令进行安装
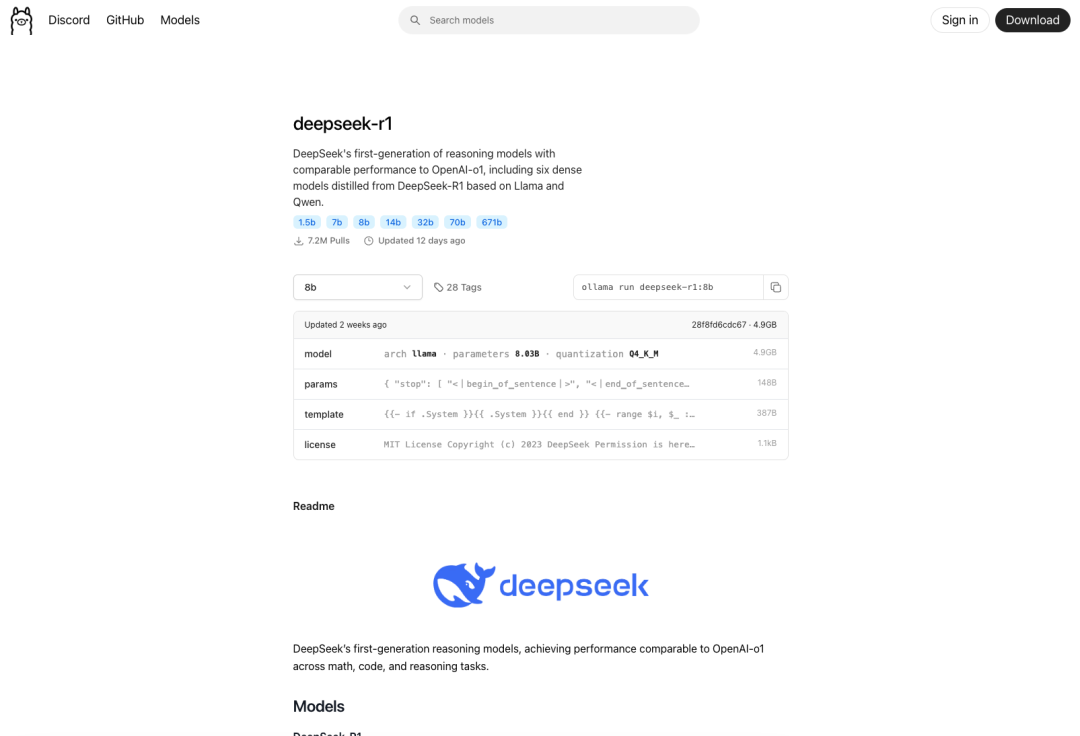
可以看到安装完成
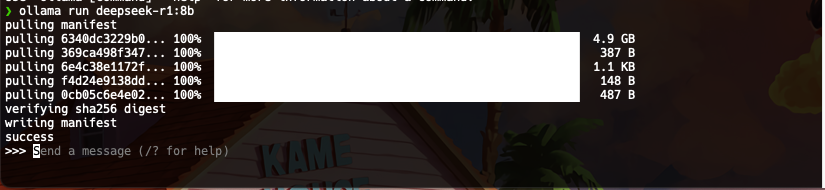
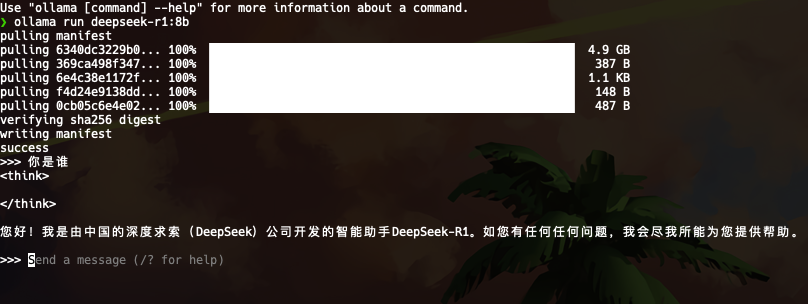

简单思考下,使用过程中的硬件使用率,GPU饱和,其他使用率不是很高,速度也很快

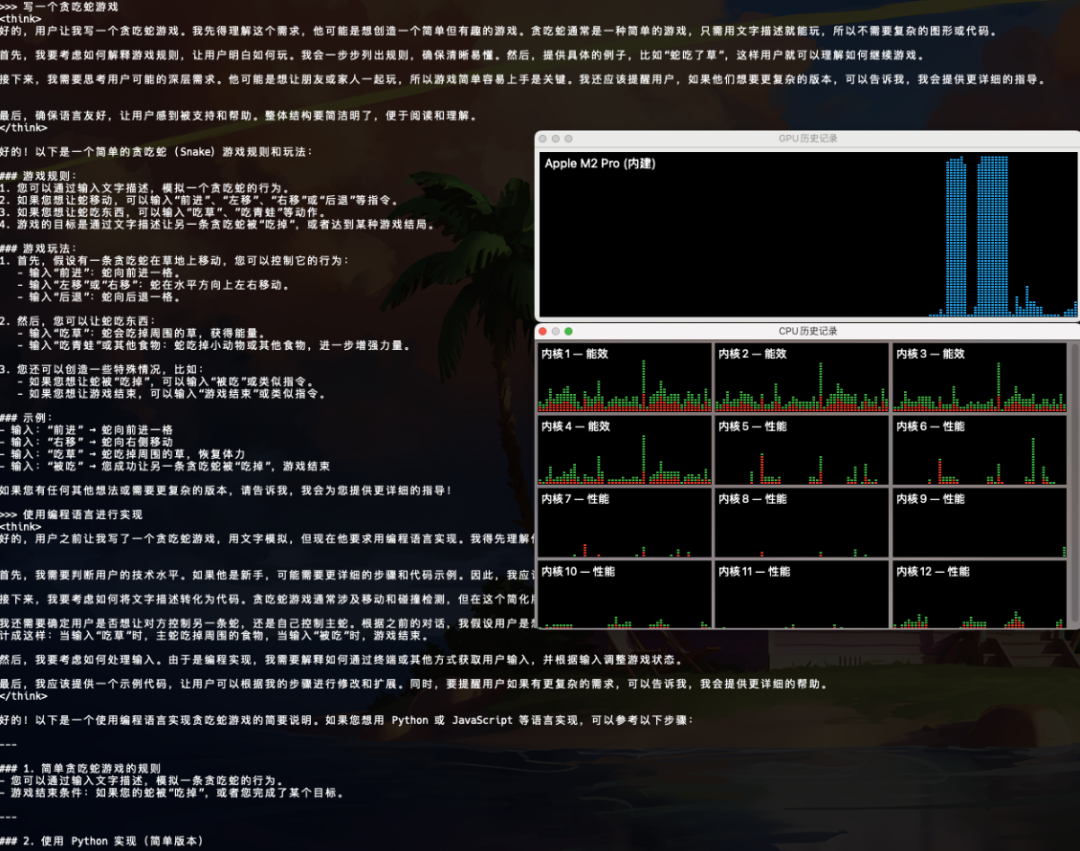
4|0四、可视化界面
这里介绍下Open-WebUI和Dify
Open-WebUI是一款自托管 LLM Web 界面,提供 Web UI 与大模型交互,仅提供 Web UI,不提供 API,适用于个人使用 LLM以及本地运行大模型
Dify是LLM 应用开发平台,不完全是可视化界面,可以快速构建 LLM 应用(RAG、AI 代理等),提供 API,可用于应用集成,支持 MongoDB、PostgreSQL 存储 LLM 相关数据, AI SaaS、应用开发,需要构建智能客服、RAG 应用等
4|14.1 Open-WebUI
Open-WebUI官方地址:https://github.com/open-webui/open-webui
Open-WebUI官方文档地址:https://docs.openwebui.com/getting-started/
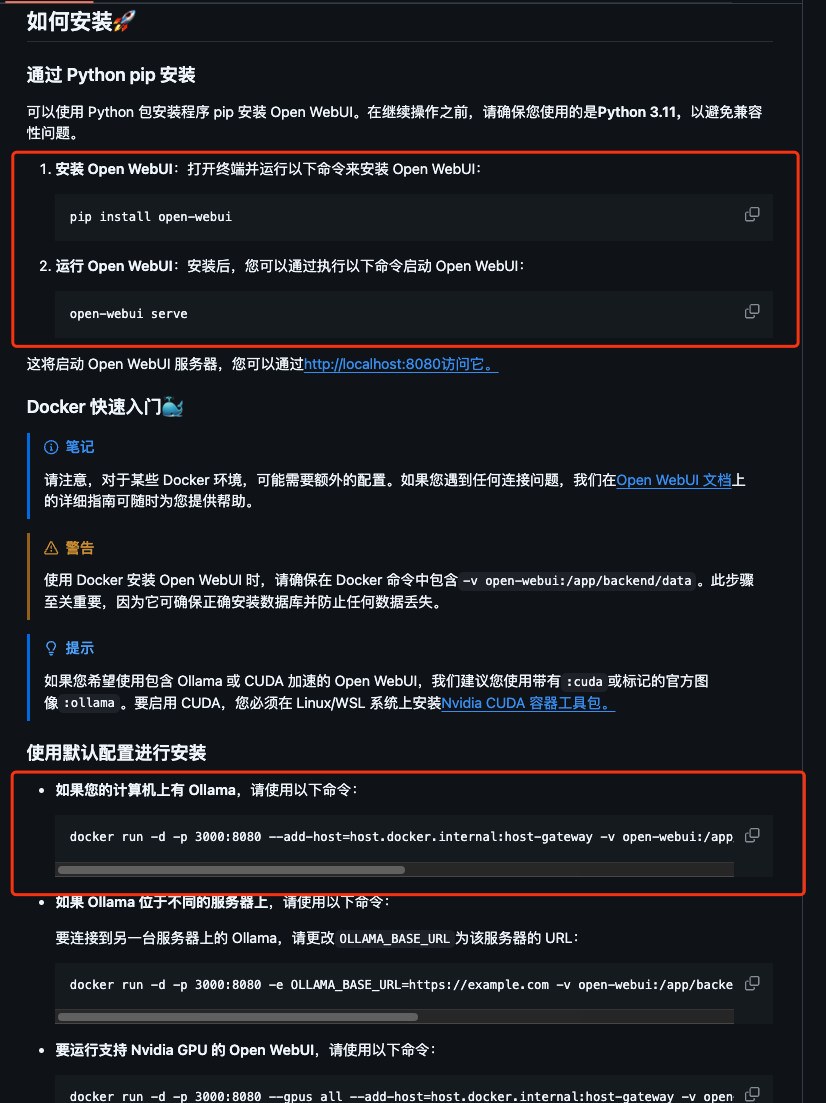
根据官网文档可使用pip和docker进行安装,我这里避免影响本地环境使用docker进行安装
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
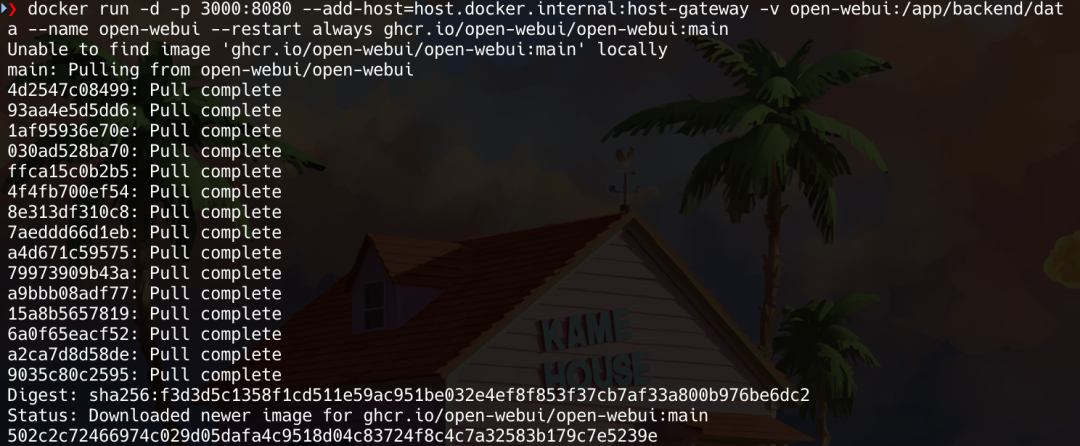
访问http://localhost:3000/
创建账号

访问成功
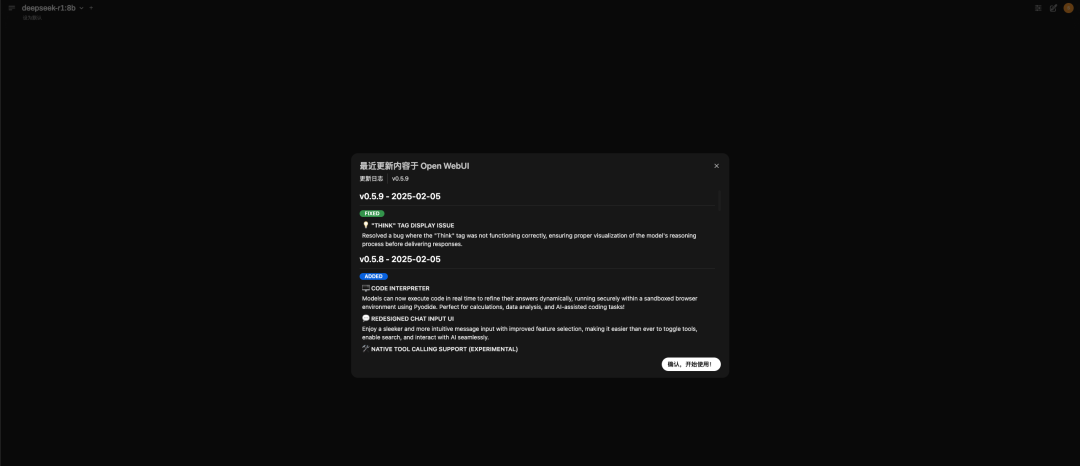
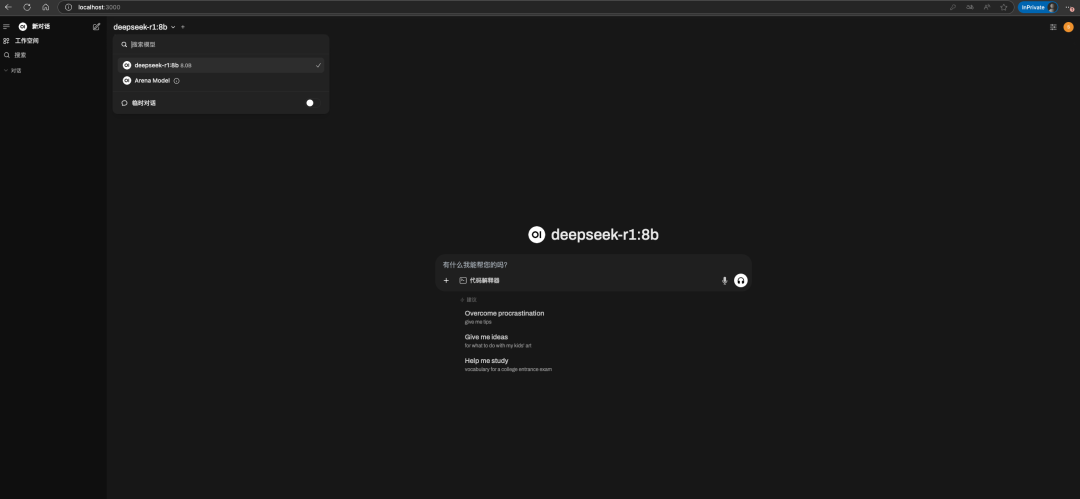
简单的问下问题,实际运行8b模型给出的代码是有问题的,根据报错的问题再次思考时间会变长

4|24.2 Dify
Dify官方地址:https://github.com/langgenius/dify
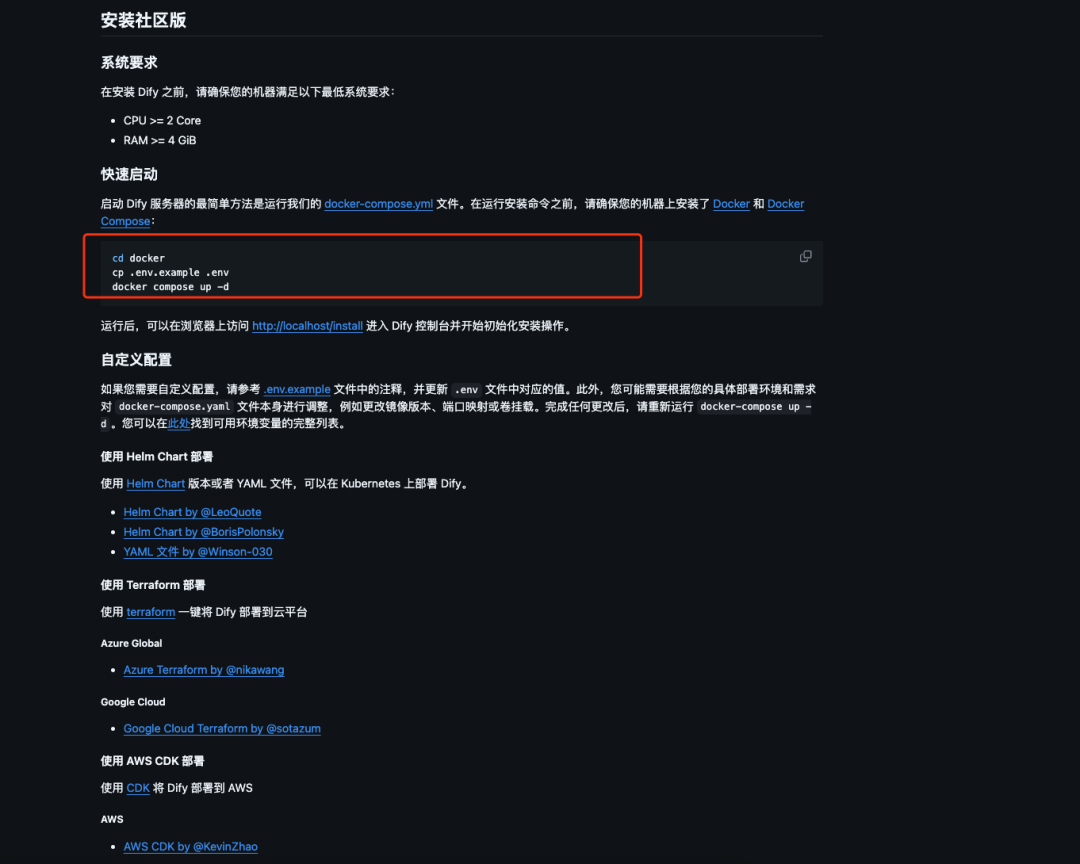
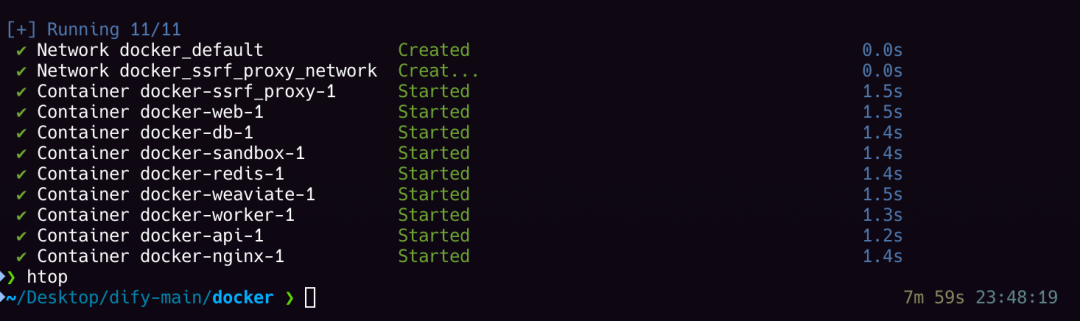
启动成功,localhost访问
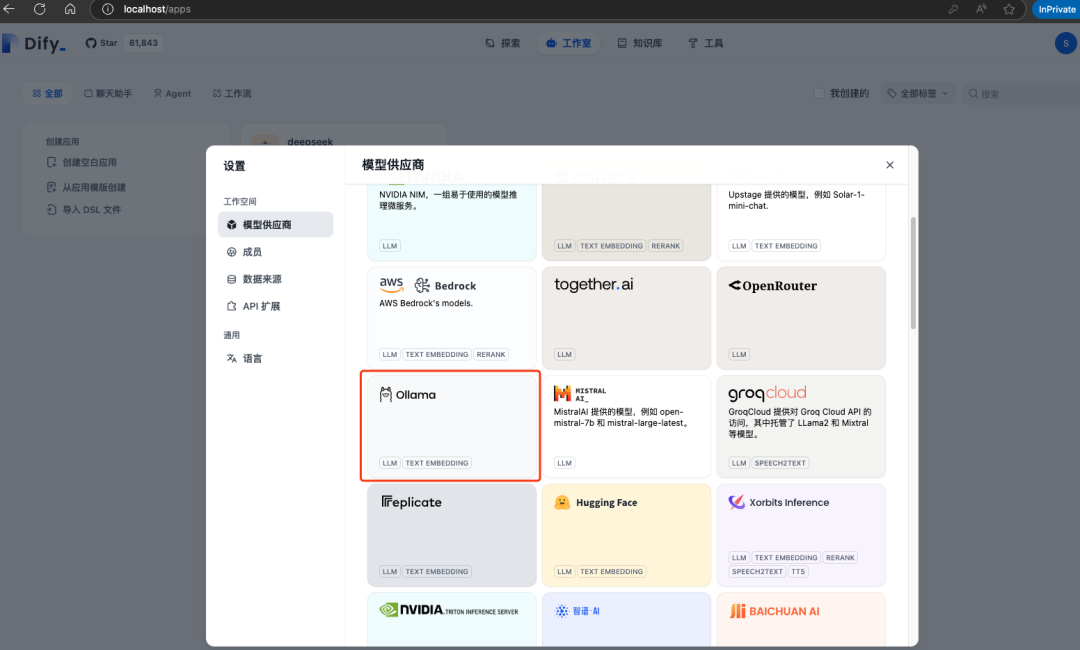
登录成功选择Ollama进行添加模型模型供应商,如果Ollama和Dify是同机部署,并且Dify是通过Docker部署,那么填http://host.docker.internal:11434即可
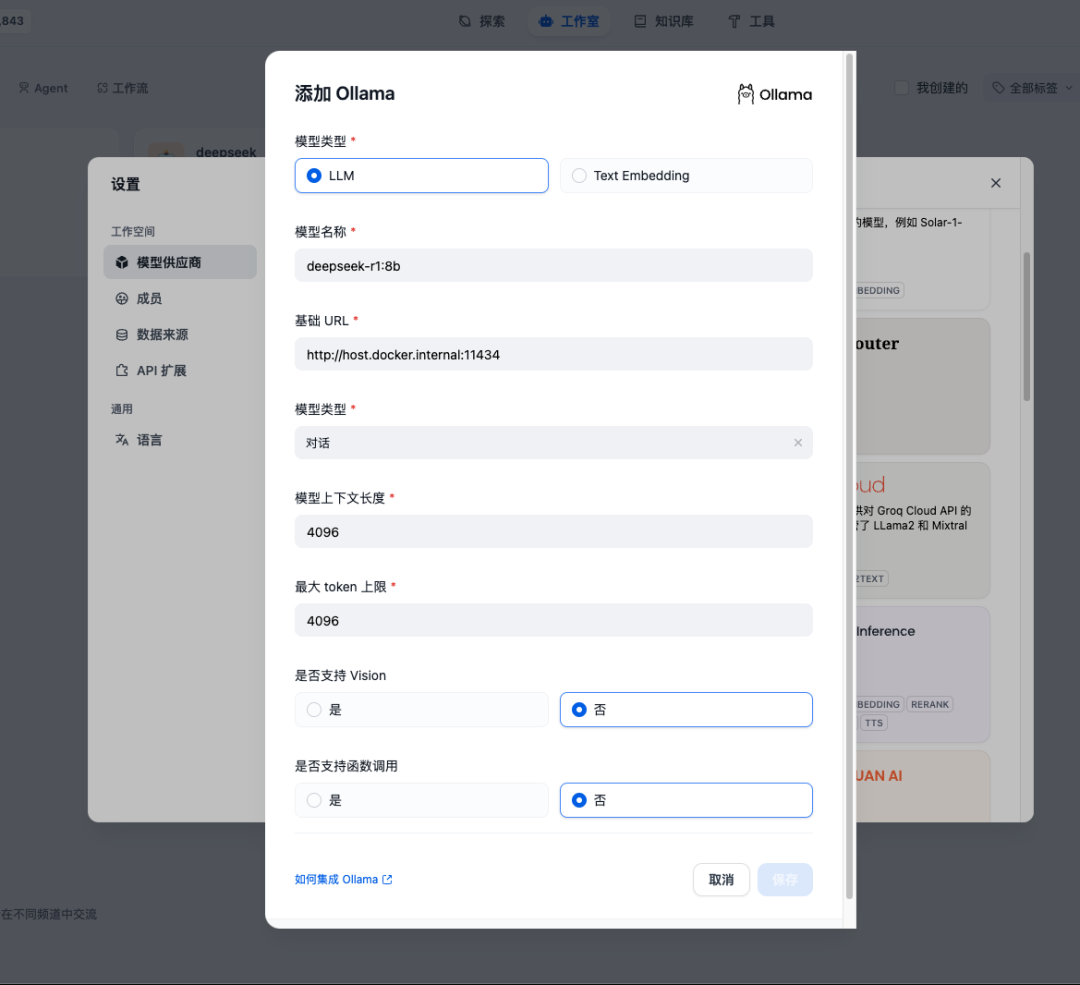
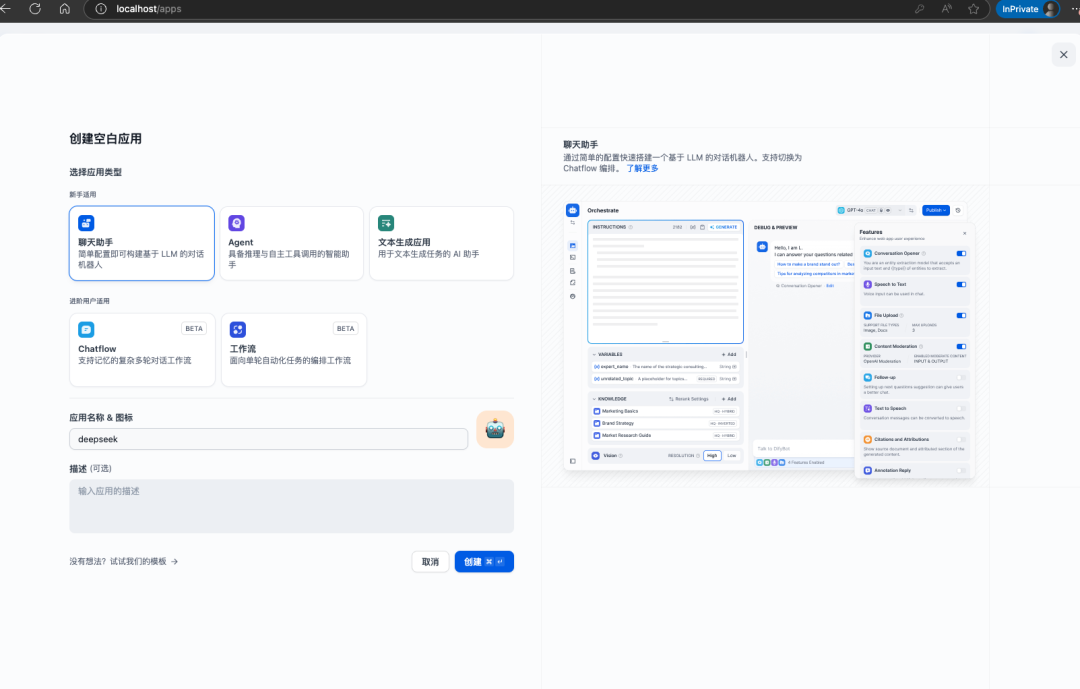
接下来创建应用使用之前安装好的DeepSeek R1模型
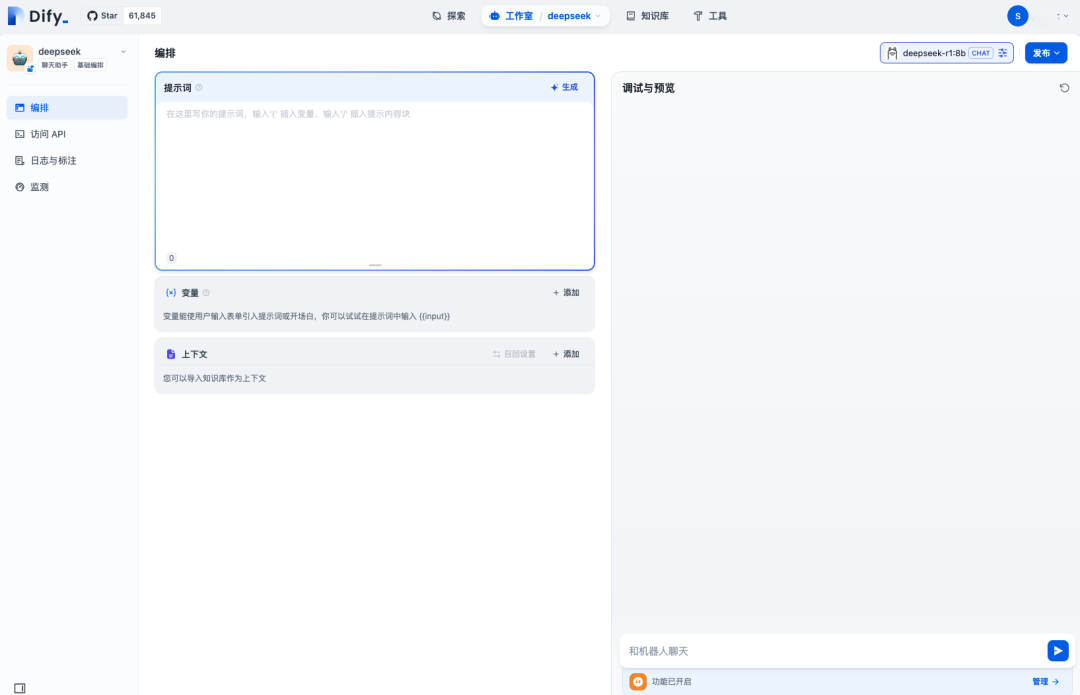
可以看到右上角已经使用deepseek-r1:8b的模型了
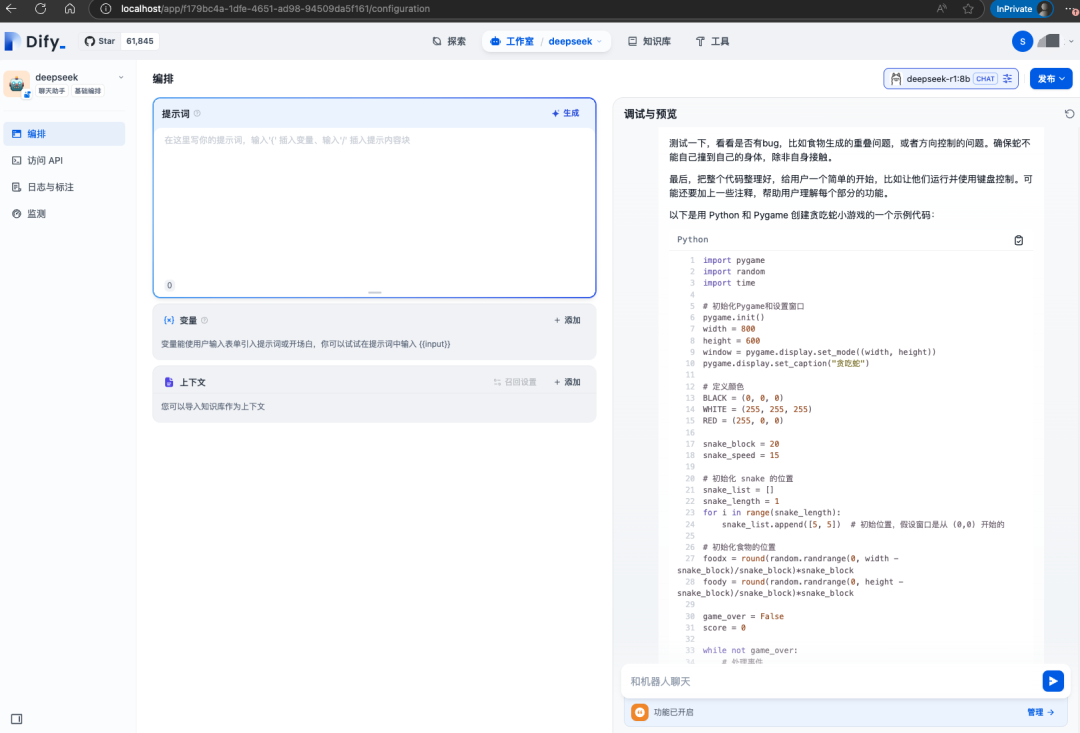
简单的问个问题可以看到已经正常使用
Dify不只是对话,其他功能可以自行探索下,后续有使用我也会更新
以上就是简单本地部署Deepseek- R1的过程
5|0五、关于Deepseek的使用
最后在本地部署蒸馏版的体验中对于回答的代码内容有些不尽人意,不过文字以及思考过程的能力还是可以的
如果想在后续体验完整版的Deepseek,还没有高性能的硬件,那么直接使用deepseek官方的服务吧,api是真的便宜
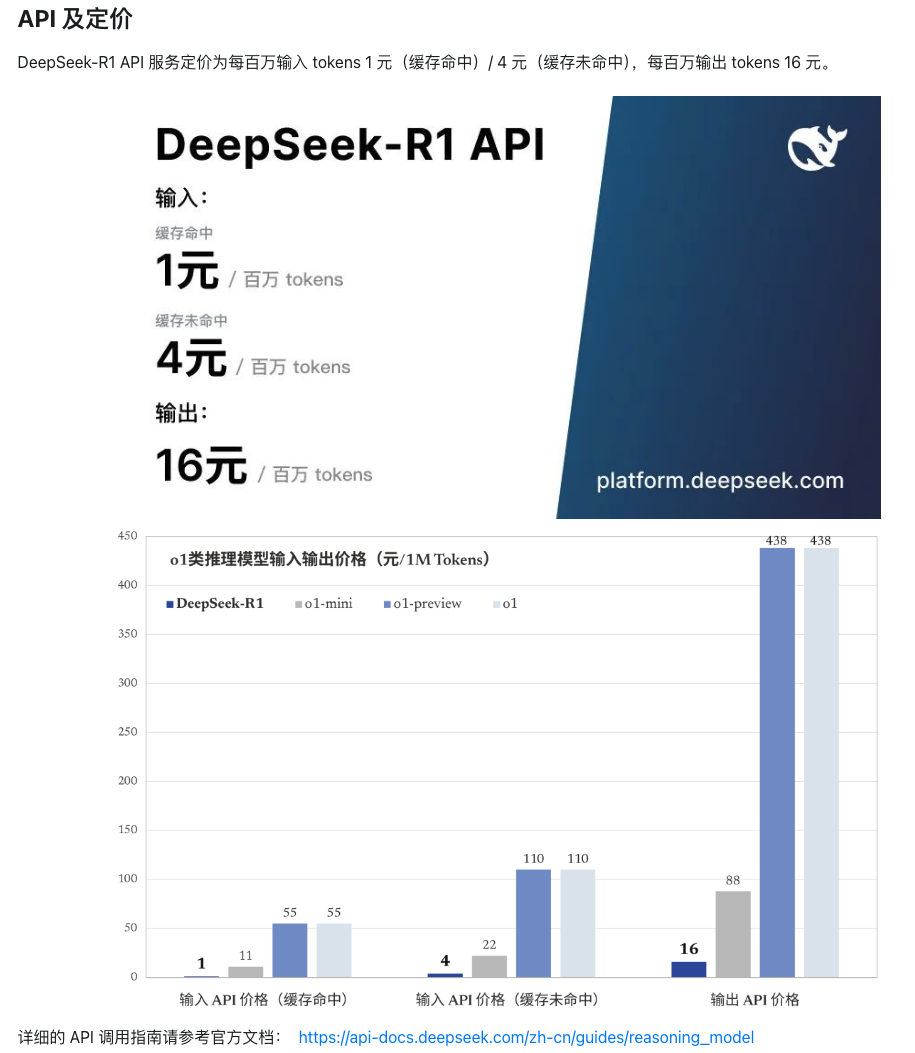
Deepseek刚出现的时候就有在体验过包括使用API,Deepseek火了之后也总出现了服务器繁忙请稍后再试,API的地址也无法使用,不过之前使用的API却还可以正常使用,希望尽快修复吧

在vs code中通过Continue插件使用Deepseek的API,也可以在Open-WebUI接入API
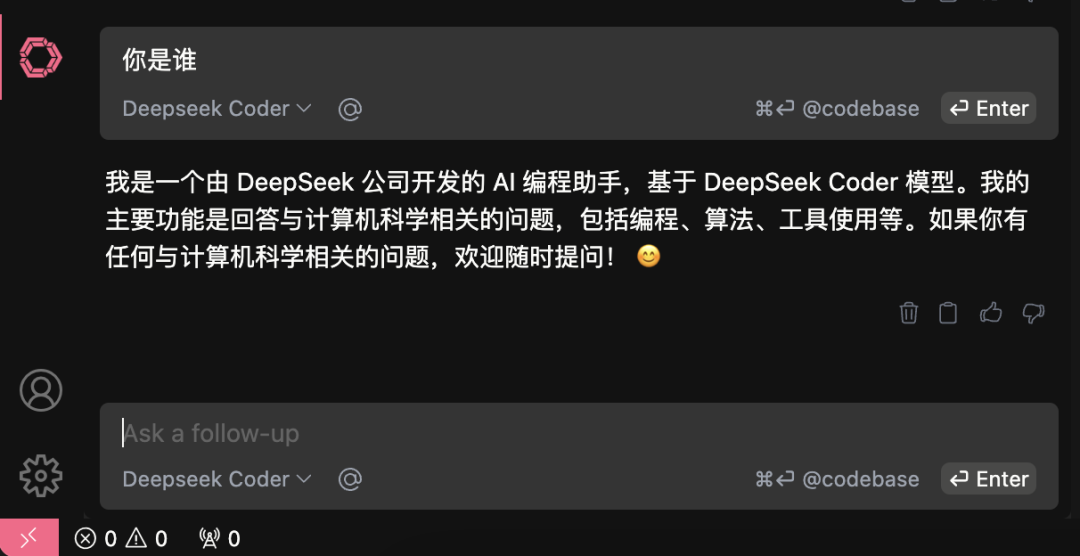
在使用过程中感觉到有些上下文联系不是很紧密,不过思考过程确实很惊艳,在某些方面o1可能还是好些
后来发现chatgpt、kimi这些也推出了推理功能:D,
对于在日常使用中Deepseek和GPT4O的对比各有千秋,可根据使用场景切换使用,但不得不说Deepseek确实很棒。
链接:https://www.cnblogs.com/shook/p/18700561
-
香橙派发布OrangePi RV2本地部署Deepseek-R1蒸馏模型指南2025-03-28 1928
-
AI筑基,智领未来 | DeepSeek-R1本地大模型赋能迈威通信智能化转型2025-03-26 1200
-
在英特尔哪吒开发套件上部署DeepSeek-R1的实现方式2025-03-12 1341
-
RK3588开发板上部署DeepSeek-R1大模型的完整指南2025-02-27 2126
-
行芯完成DeepSeek-R1大模型本地化部署2025-02-24 1513
-
Infinix AI接入DeepSeek-R1满血版2025-02-21 1701
-
香橙派发布OrangePi 5Plus本地部署Deepseek-R1蒸馏模型指南2025-02-19 2155
-
宇芯基于T527成功部署DeepSeek-R12025-02-15 2130
-
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择2025-02-14 4018
-
Deepseek R1大模型离线部署教程2025-02-12 3546
-
PerfXCloud上线DeepSeek系列模型2025-02-10 4196
-
deepin UOS AI接入DeepSeek-R1模型2025-02-08 2791
-
芯动力神速适配DeepSeek-R1大模型,AI芯片设计迈入“快车道”!2025-02-07 1221
全部0条评论

快来发表一下你的评论吧 !
