

借助PerfXCloud和dify开发代码转换器
描述
随着深度学习与高性能计算的迅速发展,GPU计算的广泛应用已成为推动技术革新的一股重要力量。对于GPU编程语言的选择,CUDA和HIP是目前最为流行的两种选择。CUDA是由NVIDIA推出的编程平台和API,专门用于其GPU硬件的开发;而HIP(Heterogeneous-Compute Interface for Portability)是AMD推出的一种跨平台编程模型,旨在为不同厂商的GPU提供一种通用的代码编写方式。
本文通过将PerfXCloud中的DeepSeek-R1模型接入dify,构建一个自动代码转换工具,实现CUDA代码和HIP代码的相互转换。经过内部实践,代码转换效率远高于程序员手动编写代码,在大多数情况下技术人员只需少量调整代码,即可直接使用。
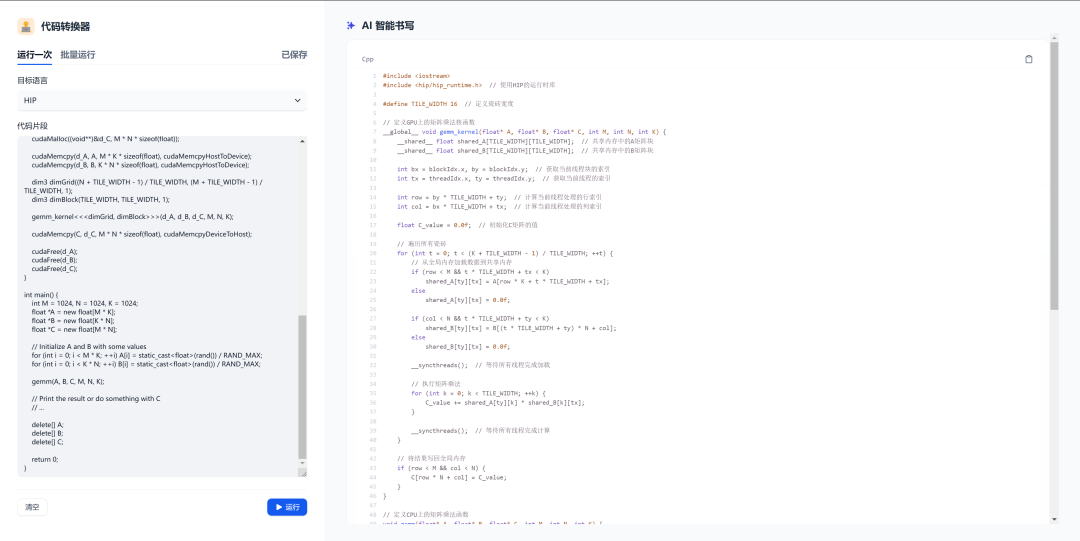
背景与需求
在GPU编程的世界里,CUDA作为NVIDIA的专有技术,已经获得了广泛的应用。许多深度学习框架(如TensorFlow、PyTorch等)以及高性能计算应用都依赖CUDA来加速计算。然而,随着GPU硬件的多样化以及AMD在GPU市场的不断扩展,越来越多的开发者开始考虑如何将现有的CUDA代码迁移到HIP平台,以便能够支持AMD GPU,甚至跨多个厂商的硬件平台。
然而,直接手动转换大量的CUDA代码往往需要付出高昂的成本。程序员需要深入了解两者的编程模型、API差异、底层硬件差异以及如何最大化地利用不同GPU的性能优势。正是在这种背景下,我们借助了LLM及相关工具来自动化这一过程,开发了一种代码转换器,能够高效实现CUDA代码和HIP代码的相互转换,从而大大提高了跨平台移植的效率与准确性。
Dify与PerfXCloud配置
在进行代码转换器搭建前,首先要进行PerfXCloud API KEY的创建,用户可在PerfXCloud DeepSeek专线进行注册并创建.
注册地址为:https://deepseek.perfxlab.cn。
完成API KEY创建后,可在dify中配置模型供应商,将PerfXCloud配置为模型供应商后,即可使用DeepSeek系列模型。本文中使用本地私有化部署的dify进行,用户可在dify项目首页查看部署说明。
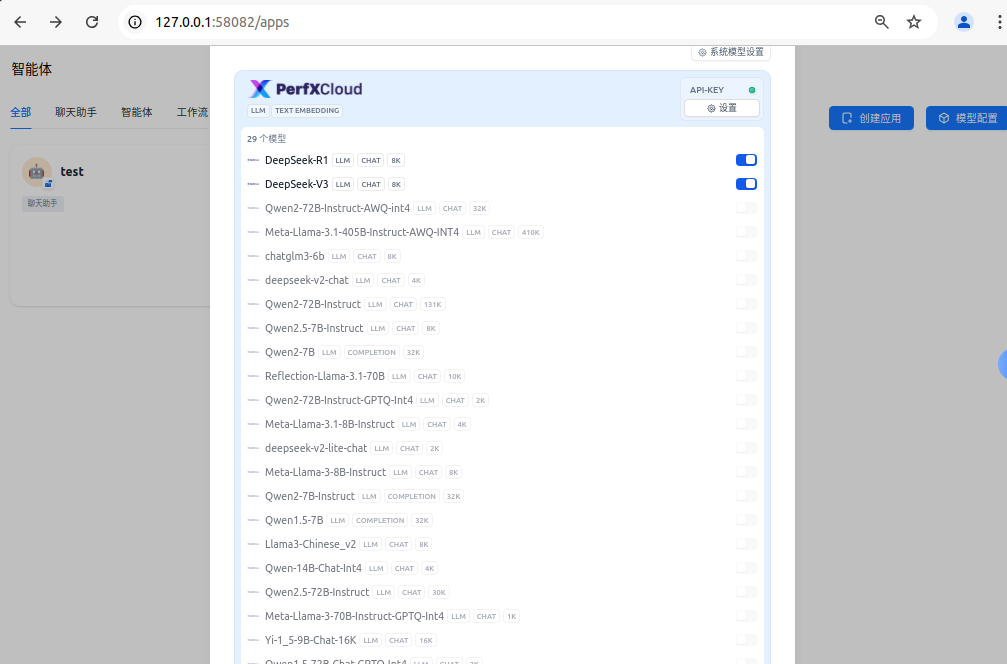
完成配置后,可以看到DeepSeek最新模型已经是可用状态。
代码转换器的设计与实现
LLM模型具备强大的自然语言理解与生成能力,通过对大量CUDA与HIP代码的样本进行学习,模型能够识别并自动转换两种语言中的语法、库函数、内存管理方式等细节。
具体来说,CUDA和HIP虽然在整体结构上有相似性,但在API调用、内存管理、线程调度等方面存在一些差异。例如,CUDA中的cudaMalloc在HIP中被转换为hipMalloc,而对于某些特定功能,例如核函数的调用和设备内存的管理,CUDA与HIP的实现方式可能有显著的不同。为了完成代码的相互转换,我们借助DeepSeek-R1模型强大的代码编写能力来完成这部分工作。
首先在dify中新建一个聊天助手,输入如下提示词,并将模型配置为DeepSeek-R1,如下图所示。完成配置后即可发布运行。
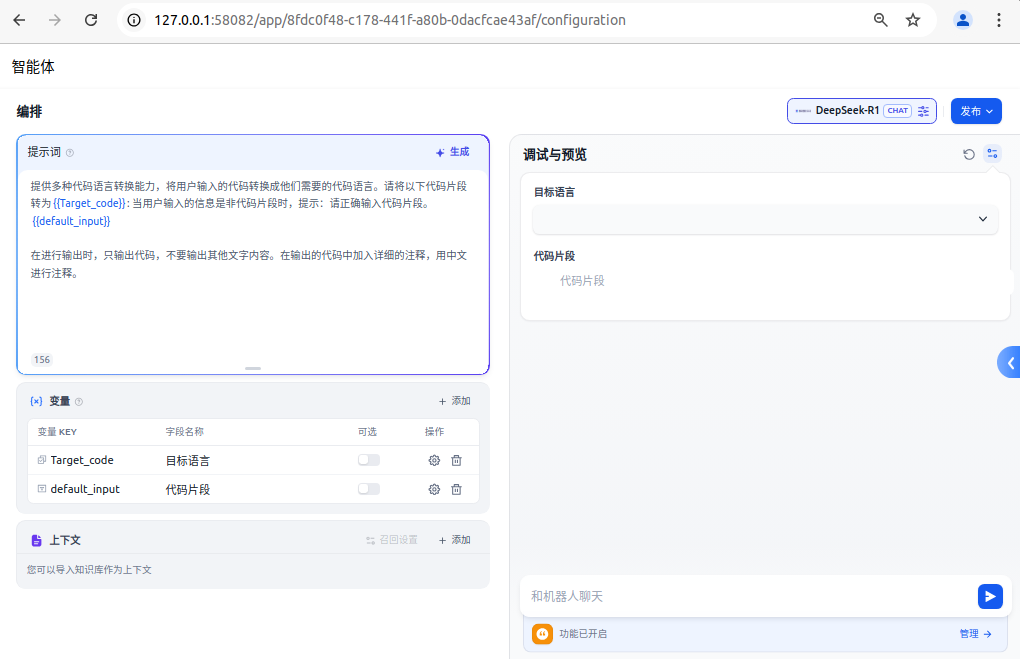
自动化与手动校验的结合
为了确保转换器生成的代码能够高效运行,我们并不仅仅依赖LLM工具的自动转换。自动化的代码生成是一个基础,但我们还需要通过手动校验和调试来进一步优化转换结果。通过结合人工智能与开发者的专业知识,代码转换器能够在保证转换精度的同时,提高对复杂场景的适应性。
除了基本的语法和API转换,通常需要在转换后针对代码进行优化。将代码从CUDA迁移到HIP的过程中,可能会遇到一些性能瓶颈。由于CUDA与HIP底层硬件架构的差异,直接的代码转换并不总是能够保证最优的性能。因此,在编译运行阶段,需要借助澎峰科技异构计算软件栈进行性能分析与优化。例如,我们可以针对特定硬件平台(如NVIDIA和AMD的GPU)提供不同的优化策略。对于NVIDIA的GPU,可能需要优化线程块的调度和共享内存的使用;而对于AMD的GPU,可能需要调整内存访问模式和计算核的调用方式。我们的工具可以根据目标硬件平台,自动进行调整,并生成经过优化的代码。
结语
在跨平台计算需求日益增长的今天,GPU编程语言的多样化与跨平台开发已成为技术发展的重要趋势。通过结合LLM的强大能力,我们开发的CUDA到HIP代码转换器显著提高了编码效率,帮助开发者快速实现代码迁移,减少了手动编写和调试的时间成本。借助PerfXCloud的高性能算力,用户可以轻松上手并使用最新的DeepSeek模型,进一步加速开发流程。
-
Dify零基础开发本地Agent智能体 -51cto2026-03-23 389
-
17|部署Dify-Dify 开发:AI Agent 进阶实战-极客时间2026-02-28 229
-
在Dify中使用PerfXCloud大模型推理服务2024-07-15 3870
-
PerfXCloud大模型开发与部署平台开放注册2024-07-02 1064
-
Buck转换器如何工作油泼辣子 2023-11-18
-
借助LDO提高降压转换器的轻负载效率2022-11-21 691
-
如何借助LDO提高降压转换器的轻负载效率 – I2022-11-04 599
-
145. 逐次比较型AD转换器#AD转换器电路设计快学 2022-07-29
-
如何借助LDO提高降压转换器的轻负载效率2018-09-12 2004
-
G代码转换器V1.2.0-鲁班DIY2017-12-11 1120
-
数据转换器代码2011-12-12 908
-
KeeLOQ三轴代码转换器HCS473及其应用2009-04-25 569
全部0条评论

快来发表一下你的评论吧 !
