

Python拉勾网数据采集与可视化
描述
全文简介
本文是先采集拉勾网上面的数据,采集的是Python岗位的数据,然后用Python进行可视化。主要涉及的是爬虫&数据可视化的知识。
爬虫部分
先用Python来抓取拉勾网上面的数据,采用的是简单好用的requests模块。主要注意的地方是,拉勾网属于动态网页,所以会用到浏览器的F12开发者工具进行抓包。抓包以后会发现,其实网页是一个POST的形式,所以要提交数据,提交的数据如下图:
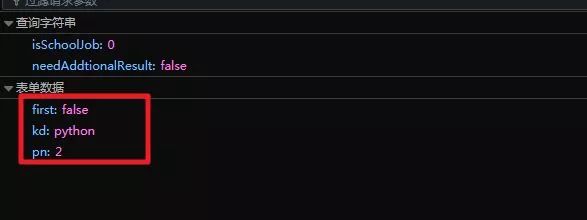
真实网址是:
https://www.lagou.com/jobs/positionAjax.jsonneedAddtionalResult=false&isSchoolJob=0
在上图也可以轻松发现:kd是查询关键词,pn是页数,可以实现翻页。
代码实现
import requests # 网络请求
import re
import time
import random
# post的网址
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0'
# 反爬措施
header = {'Host': 'www.lagou.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'X-Anit-Forge-Code': '0',
'Content-Length': '26',
'Cookie': 'user_trace_token=20171103191801-9206e24f-9ca2-40ab-95a3-23947c0b972a; _ga=GA1.2.545192972.1509707889; LGUID=20171103191805-a9838dac-c088-11e7-9704-5254005c3644; JSESSIONID=ABAAABAACDBABJB2EE720304E451B2CEFA1723CE83F19CC; _gat=1; LGSID=20171228225143-9edb51dd-ebde-11e7-b670-525400f775ce; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DKkJPgBHAnny1nUKaLpx2oDfUXv9ItIF3kBAWM2-fDNu%26ck%3D3065.1.126.376.140.374.139.129%26shh%3Dwww.baidu.com%26sht%3Dmonline_3_dg%26wd%3D%26eqid%3Db0ec59d100013c7f000000055a4504f6; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; LGRID=20171228225224-b6cc7abd-ebde-11e7-9f67-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_search; SEARCH_ID=3ec21cea985a4a5fa2ab279d868560c8',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'}
for n in range(30):
# 要提交的数据
form = {'first':'false',
'kd':'Python',
'pn':str(n)}
time.sleep(random.randint(2,5))
# 提交数据
html = requests.post(url,data=form,headers = header)
# 提取数据
data = re.findall('{"companyId":.*?,"positionName":"(.*?)","workYear":"(.*?)","education":"(.*?)","jobNature":"(.*?)","financeStage":"(.*?)","companyLogo":".*?","industryField":".*?","city":"(.*?)","salary":"(.*?)","positionId":.*?,"positionAdvantage":"(.*?)","companyShortName":"(.*?)","district"',html.text)
# 转换成数据框
data = pd.DataFrame(data)
# 保存在本地
data.to_csv(r'D:Windows 7 DocumentsDesktopMyLaGouDataMatlab.csv',header = False, index = False, mode = 'a+')
注意:抓取数据的时候不要爬取太快,除非你有其他的反爬措施,比如更换IP等,另外不需登录,我在代码加入了time模块,用于限制爬取速度。
数据可视化
下载下来的数据长成这个样子:
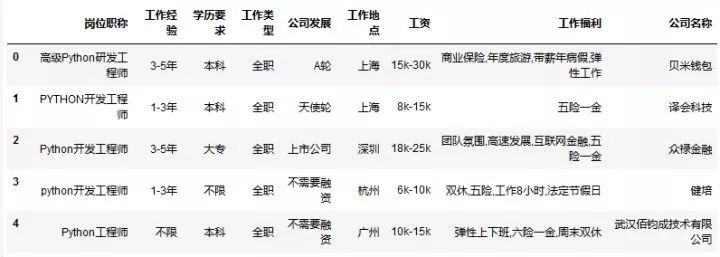
注意标题(也就是列明)是我自己添加的。
导入模块并配置绘图风格
import pandas as pd # 数据框操作
import numpy as np
import matplotlib.pyplot as plt # 绘图
import jieba # 分词
from wordcloud importWordCloud# 词云可视化
import matplotlib as mpl # 配置字体
from pyecharts importGeo# 地理图
mpl.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
# 配置绘图风格
plt.rcParams["axes.labelsize"] = 16.
plt.rcParams["xtick.labelsize"] = 14.
plt.rcParams["ytick.labelsize"] = 14.
plt.rcParams["legend.fontsize"] = 12.
plt.rcParams["figure.figsize"] = [15., 15.]
注意:导入模块的时候其他都容易解决,除了wordcloud这个模块,这个模块我建议大家手动安装,如果pip安装的话,会提示你缺少C++14.0之类的错误,导致安装不上。手动下载whl文件就可以顺利安装了。
数据预览
# 导入数据
data = pd.read_csv('D:Windows 7 DocumentsDesktopMyLaGouDataPython.csv',encoding='gbk') # 导入数据
data.head()
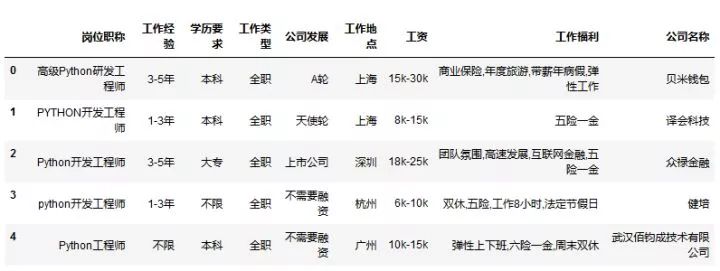
read_csv路径不要带有中文
data.tail()
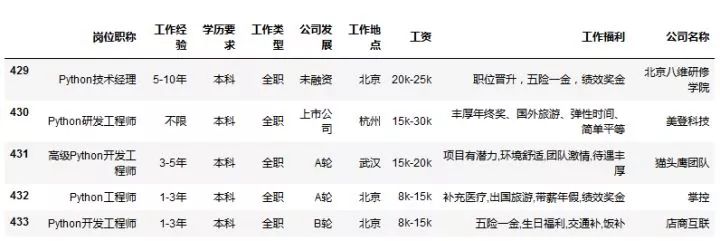
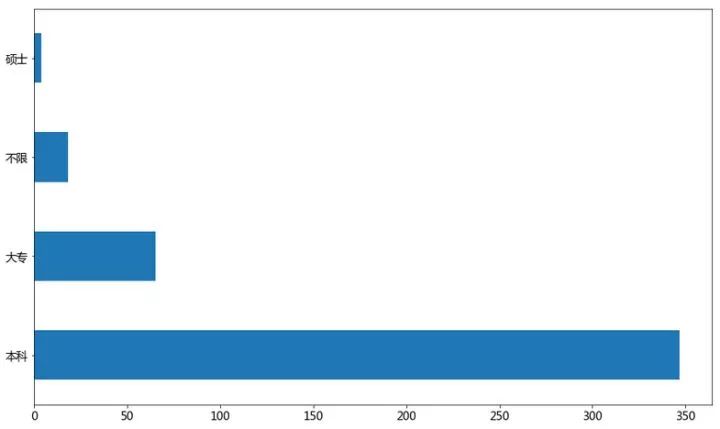
学历要求
data['学历要求'].value_counts().plot(kind='barh',rot=0)
plt.show()
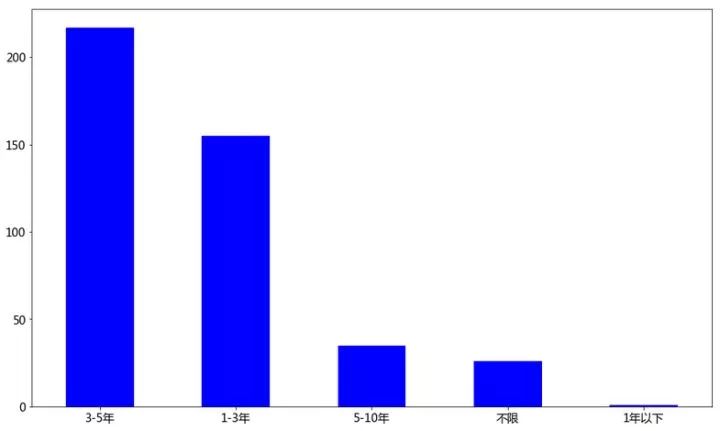
工作经验
data['工作经验'].value_counts().plot(kind='bar',rot=0,color='b')
plt.show()
Python热门岗位
final = ''
stopwords = ['PYTHON','python','Python','工程师','(',')','/'] # 停止词
for n in range(data.shape[0]):
seg_list = list(jieba.cut(data['岗位职称'][n]))
for seg in seg_list:
if seg notin stopwords:
final = final + seg + ' '
# final 得到的词汇

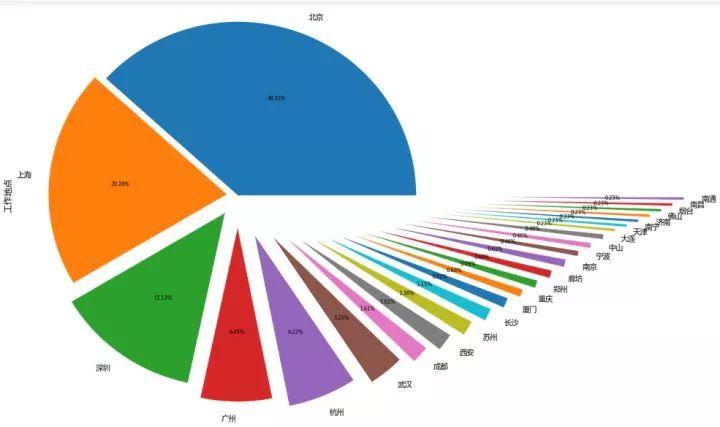
工作地点
data['工作地点'].value_counts().plot(kind='pie',autopct='%1.2f%%',explode = np.linspace(0,1.5,25))
plt.show()
工作地理图
# 提取数据框
data2 = list(map(lambda x:(data['工作地点'][x],eval(re.split('k|K',data['工资'][x])[0])*1000),range(len(data))))
# 提取价格信息
data3 = pd.DataFrame(data2)
# 转化成Geo需要的格式
data4 = list(map(lambda x:(data3.groupby(0).mean()[1].index[x],data3.groupby(0).mean()[1].values[x]),range(len(data3.groupby(0)))))
# 地理位置展示
geo = Geo("全国Python工资布局", "制作人:挖掘机小王子", title_color="#fff", title_pos="left", width=1200, height=600,
background_color='#404a59')
attr, value = geo.cast(data4)
geo.add("", attr, value, type="heatmap", is_visualmap=True, visual_range=[0, 300], visual_text_color='#fff')
# 中国地图Python工资,此分布是最低薪资
geo
- 相关推荐
- 热点推荐
- Python Basics
-
【Aworks申请】基于Python的多路温度采集与数据管理系统2015-06-29 2552
-
可视化MES系统软件2018-11-30 3408
-
数据可视化之Python-matplotlib概述2019-07-22 1754
-
python数据可视化的方法和代码2019-10-14 1747
-
Python数据可视化专家的七个秘密2020-05-15 2626
-
python数据可视化之画折线图2020-05-27 1624
-
Python数据可视化2020-07-19 3379
-
使用Python可视化数据,机器人开发编程2018-03-15 10091
-
Python实现PLC数据可视化呈现于Web端2020-08-30 7989
-
Python数据可视化编程实战2021-06-01 1080
-
使用Python来收集、处理和可视化人口数据2023-06-21 2696
-
大屏数据可视化是什么?运用了什么技术2024-05-24 1933
-
可视化数据大屏的制作流程2024-07-24 2157
-
工业数据采集形成可视化数据看板解决方案2025-03-19 1367
-
工业设备数据集中监控可视化管理平台是什么2025-05-06 1236
全部0条评论

快来发表一下你的评论吧 !
