

展望PostgreSQL 18的新特性
描述
作者: xiongcc,来源:PostgreSQL学徒
前言
距离 PostgreSQL 17 正式发布已近半年,按照每年发布一个大版本的惯例,PostgreSQL 18 预计将在 2025 年底发布。距离正式发布还有一段时间,社区的开发工作仍在如火如荼地进行中。
虽然本文中列举的许多新特性最终可能会有变化,但这并不妨碍我们展望 PostgreSQL 18 中可能引入的新特性,让我们一览为快 ~
可观测性
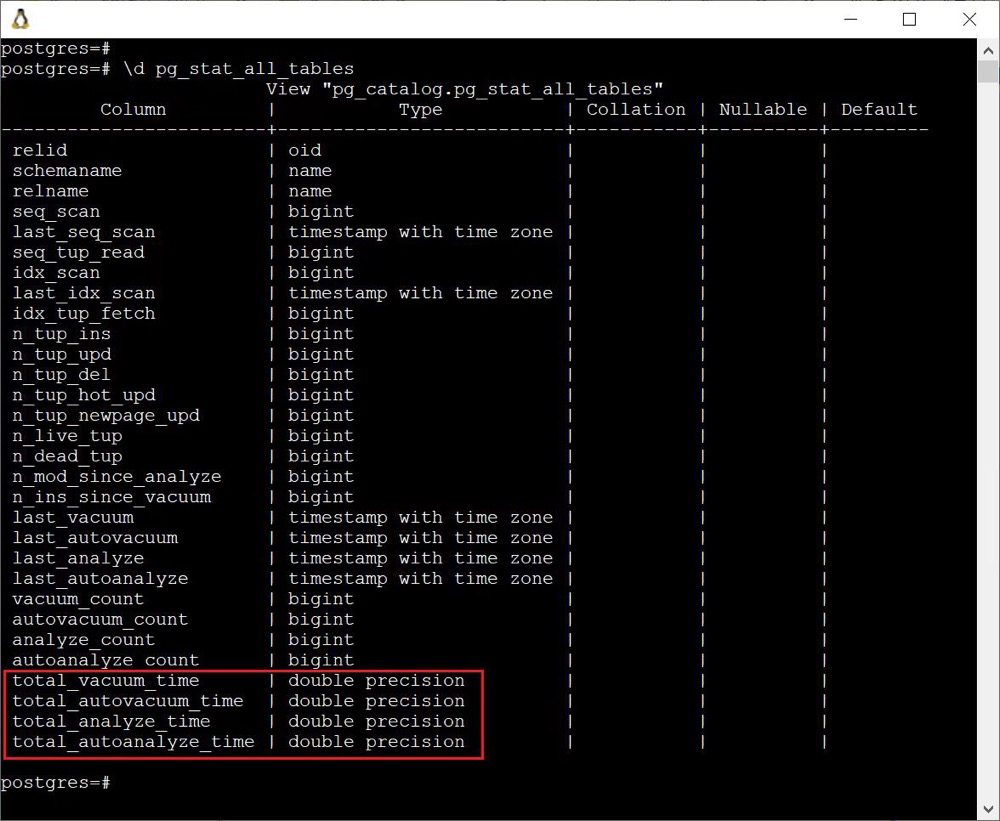
pg_stat_all_tables
在 pg_stat_all_tables 中新增了 (auto) vacuum 和 (auto) analyze 的相关耗时指标,这对于我们诊断 VACUUM 问题的时候无疑大有裨益。
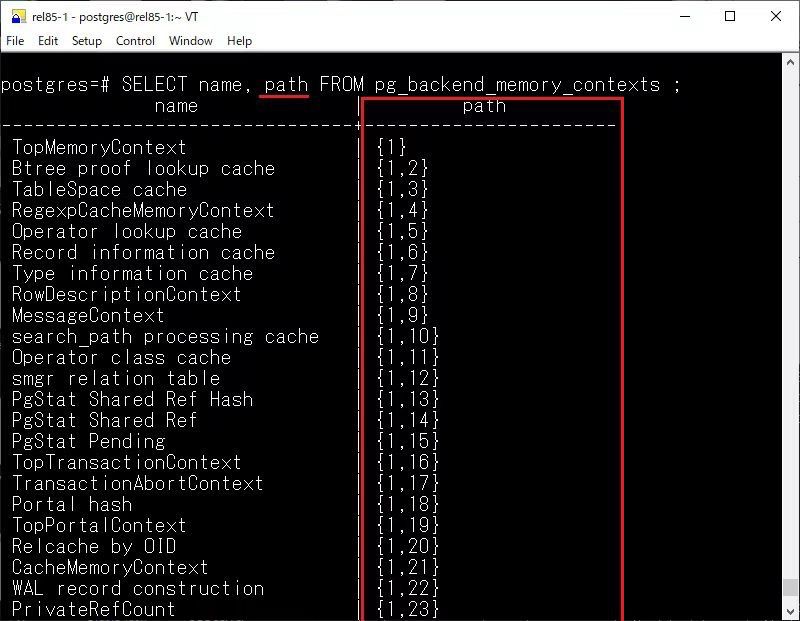
内存上下文
在 pg_backend_memory_contexts 视图中新增了 type、path 和 parent 三个字段,关于内存上下文就不再赘述,感兴趣的可以阅读:https://smartkeyerror.com/PostgreSQL-MemoryContext[1]

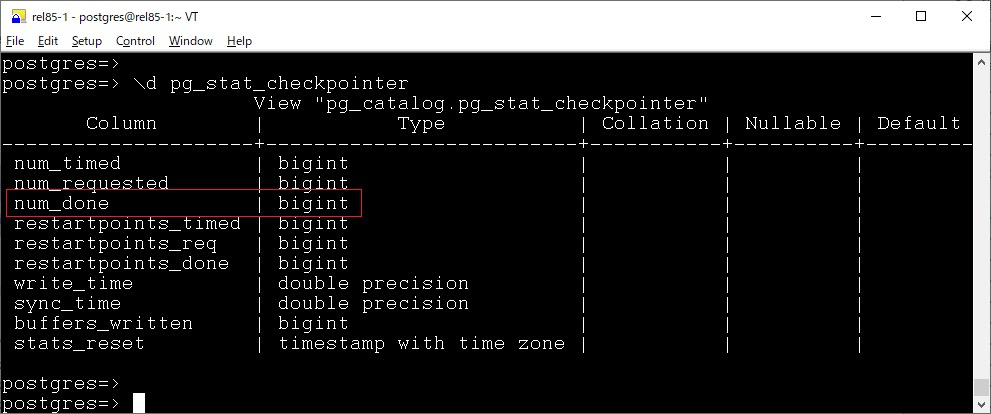
pg_stat_checkpointer
在 pg_stat_checkpointer 视图中,新增了 num_done 字段,pg_stat_checkpointer 中现有的 num_timed 和 num_requested 计数器用于跟踪已完成和跳过的检查点,但无法仅计数已完成的检查点。
因为在 PostgreSQL 中,检查点也有 skip 机制,当非停库、REDO 完成或者强制触发检查点时,如果数据库没有写入操作,则直接返回,不需要再去遍历一下 shared buffer 去刷脏,提升检查点的性能。
/*
* If this isn't a shutdown or forced checkpoint, and if there has been no
* WAL activity requiring a checkpoint, skip it. The idea here is to
* avoid inserting duplicate checkpoints when the system is idle.
*/
if ((flags & (CHECKPOINT_IS_SHUTDOWN | CHECKPOINT_END_OF_RECOVERY |
CHECKPOINT_FORCE)) == 0)
{
if (last_important_lsn == ControlFile->checkPoint)
{
END_CRIT_SECTION();
ereport(DEBUG1,
(errmsg_internal("checkpoint skipped because system is idle")));
return;
}
}
但是现有的 num_timed 是无法区分的,所以此次提交引入了 num_done 计数器,它仅跟踪已完成的检查点,从而更容易查看实际执行了多少个检查点。
Note that checkpoints may be skipped if the server has been idle since the last one, and this value counts both completed and skipped checkpoints
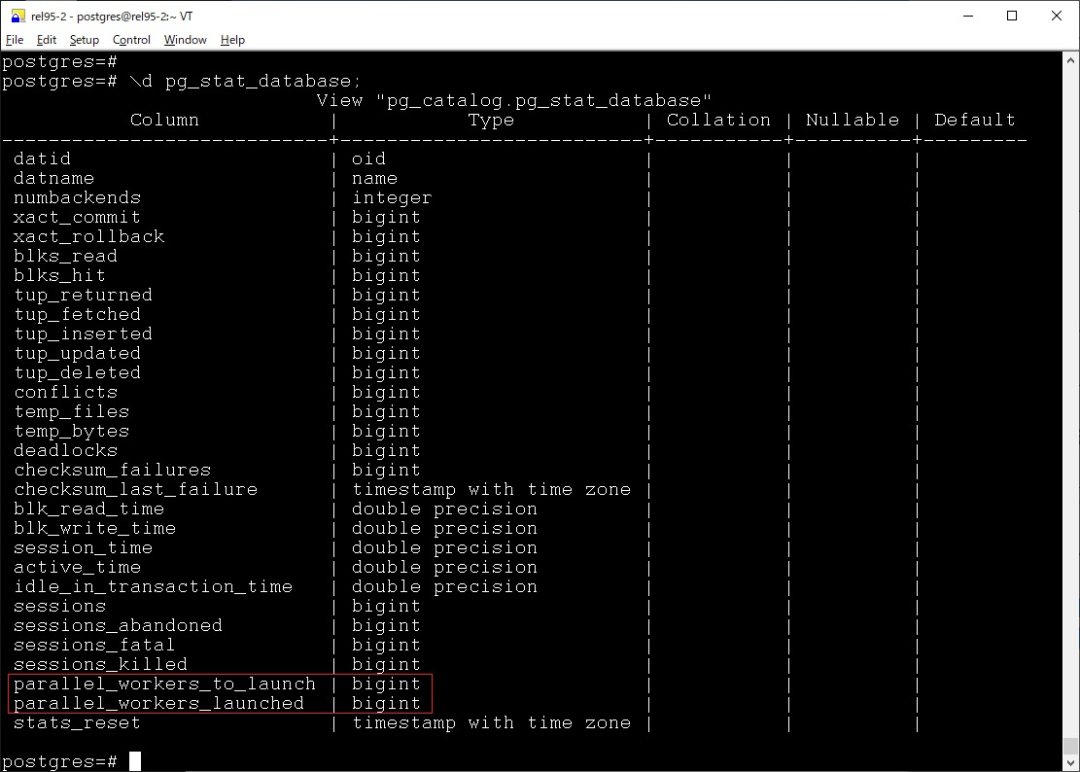
pg_stat_database
pg_stat_database 中新增了如下两个字段
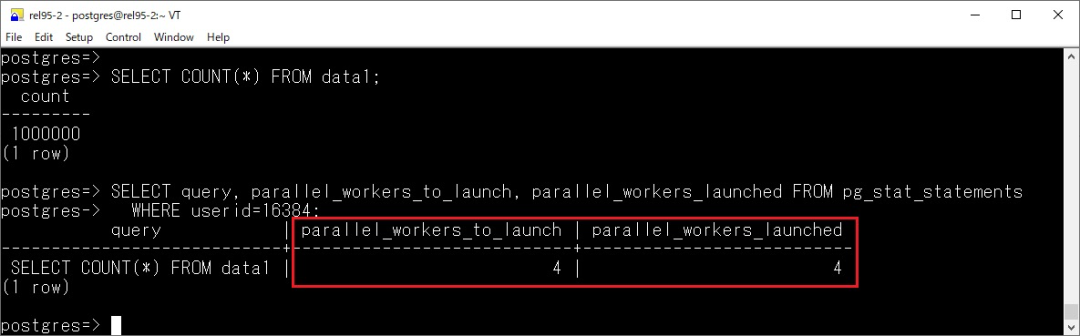
•parallel_workers_to_launch•parallel_workers_launched
顾名思义,看到这个数据库中并行的使用情况。
另外,在 pg_stat_statements 中也新增了额外两个类似指标
pg_stat_subscription_stats
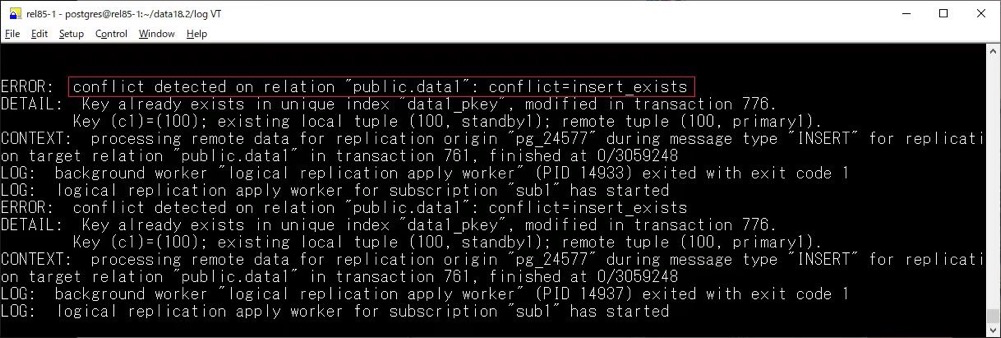
主要新增了一些用于观察冲突的列:
•confl_insert_exists•confl_update_origin_differs•confl_update_exists•confl_update_missing•confl_delete_origin_differs•confl_delete_missing
在日志中也有所体现:
pg_stat_get_backend_io
新增了 pg_stat_get_backend_io 函数,用于返回指定后端进程的 I/O 统计信息
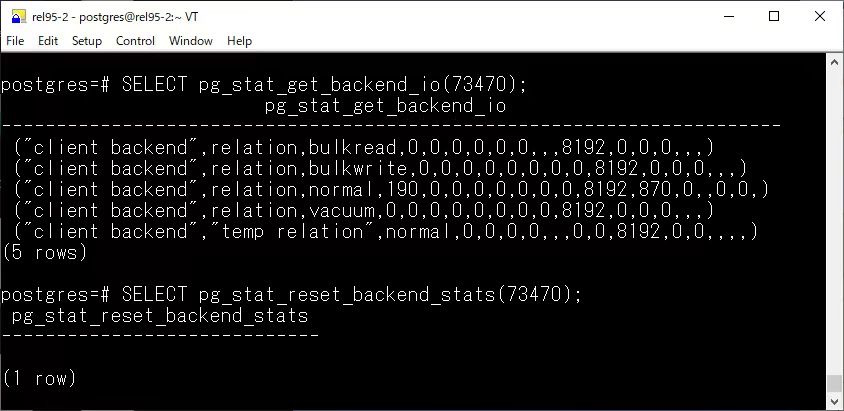
结合 pg_stat_activity,如虎添翼:
postgres=# SELECT * FROM pg_stat_get_backend_io( pg_backend_pid() ) WHERE backend_type = 'client backend' AND object = 'relation' AND context = 'normal'; -[ RECORD 1 ]--+--------------- backend_type | client backend object | relation context | normal reads | 122 read_time | 0 writes | 0 write_time | 0 writebacks | 0 writeback_time | 0 extends | 49 extend_time | 0 op_bytes | 8192 hits | 11049 evictions | 0 reuses | fsyncs | 0 fsync_time | 0 stats_reset |
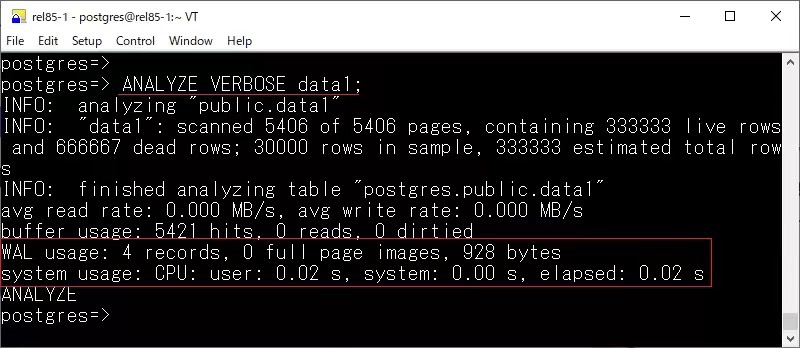
统计信息
对于 ANALYZE,在 18 版本中可以看到资源消耗情况以及 WAL 的使用情况
其次还新增了 ONLY 关键字,目的是解决在处理分区表时,VACUUM 和 ANALYZE 操作的一些不便之处。默认情况下,Autovacuum 进程不会自动对分区表执行 ANALYZE,用户必须手动执行。然而手动执行时,又会递归去分析每个分区,对于较大的分区表无疑会十分耗时,尤其是当表的列数很多时。为了解决这个问题,18 中引入了 ONLY 关键字,指定仅对主表进行操作,跳过对分区的处理。这样,用户可以避免在分区表上执行递归分析,节省时间。
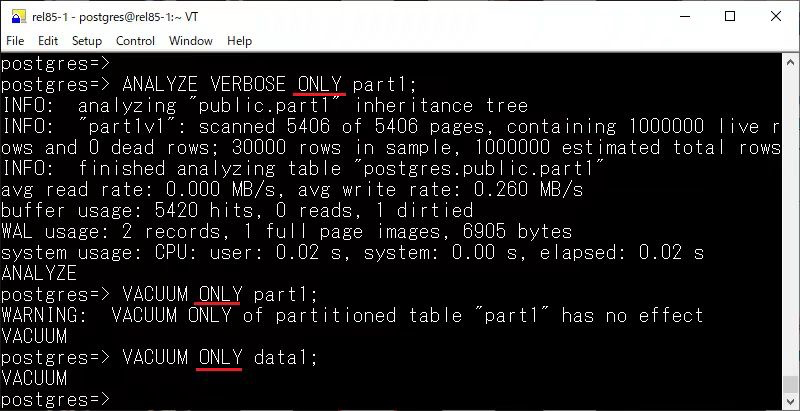
这个行为让我想起了在 Greenplum 中,有个针对根分区的 optimizer_analyze_root_partition 参数。
对于分区表,当在表上运行 ANALYZE 命令时收集根分区的统计信息。GPORCA 使用根分区统计信息来生成一个查询计划。而遗传查询优化器并不使用这些数据。
性能
Hash Right Semi Join
在 18 中,支持了 Hash Right Semi Join (也支持并行),是的 Richard Guo 大佬。
以下是 17 中的例子,优化器选择了基于大表 ticket_flights 进行 HASH,这无疑会消耗更多资源
=# EXPLAIN (costs off, analyze) SELECT * FROM flights WHERE flight_id IN (SELECT flight_id FROM ticket_flights); QUERY PLAN ------------------------------------------------------------------------------------------------ Hash Join (actual time=2133.122..2195.619 rows=150588 loops=1) Hash Cond: (flights.flight_id = ticket_flights.flight_id) -> Seq Scan on flights (actual time=0.018..10.301 rows=214867 loops=1) -> Hash (actual time=2132.969..2132.970 rows=150588 loops=1) Buckets: 262144 (originally 131072) Batches: 1 (originally 1) Memory Usage: 7343kB -> HashAggregate (actual time=1821.476..2114.218 rows=150588 loops=1) Group Key: ticket_flights.flight_id Batches: 5 Memory Usage: 10289kB Disk Usage: 69384kB -> Seq Scan on ticket_flights (actual time=7.200..655.356 rows=8391852 loops=1) Planning Time: 0.325 ms Execution Time: 2258.237 ms (11 rows)
在 18 中,第四行我们可以看到,优化器选择了 Parallel Hash Right Semi Join,基于 flights 去构建了 HASH,执行时间也有倍数的提升。
QUERY PLAN --------------------------------------------------------------------------------------------------- Gather (actual time=56.771..943.233 rows=150590 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Hash Right Semi Join (actual time=41.754..909.894 rows=50197 loops=3) Hash Cond: (ticket_flights.flight_id = flights.flight_id) -> Parallel Seq Scan on ticket_flights (actual time=0.047..221.511 rows=2797284 loops=3) -> Parallel Hash (actual time=40.309..40.309 rows=71622 loops=3) Buckets: 262144 Batches: 1 Memory Usage: 23808kB -> Parallel Seq Scan on flights (actual time=0.008..6.631 rows=71622 loops=3) Planning Time: 0.555 ms Execution Time: 949.831 ms (11 rows)
Self-Join Elimination
当查询中的表与自身进行内连接时,如果可以证明该连接在查询结果中没有实际作用,可以用扫描操作代替这个自连接。这种优化有助于减少查询计划的复杂度,特别是在涉及分区表时。该优化的主要效果包括:
•减少范围表的长度:特别是对于分区表,消除不必要的自连接有助于减少表列表中的项数。•减少限制条件的数量:从而减少了选择性估算,并可能提高查询计划的预测准确性。
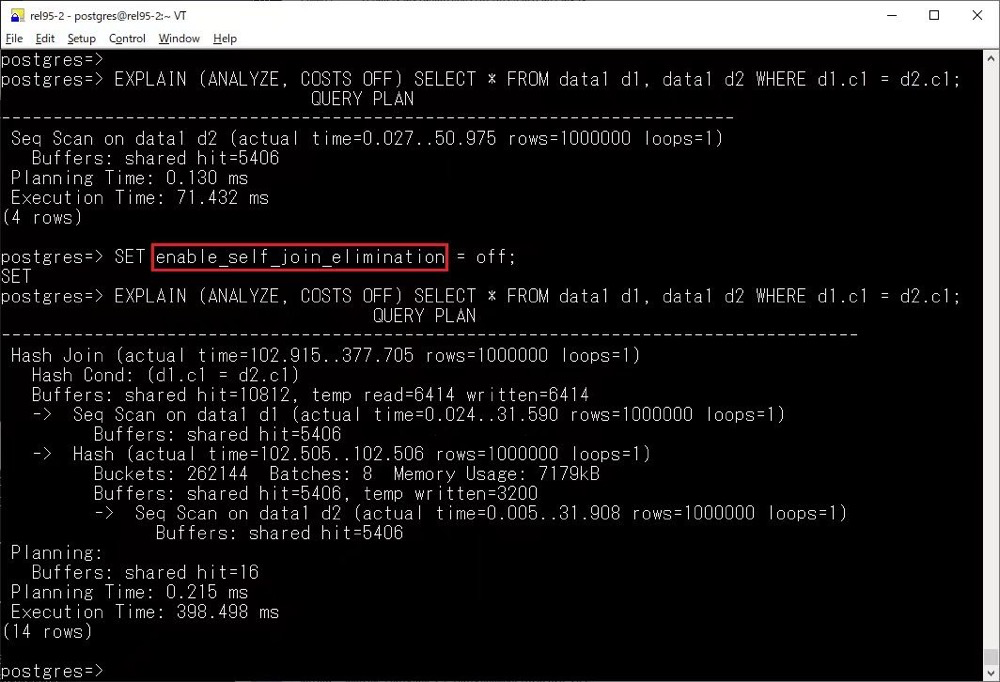
这项优化通过替代自连接为更高效的扫描操作来减少查询计划的复杂性,尤其在处理分区表时具有显著的性能优势。搭配上 Hash Right Semi Join,使得 18 中的优化器能力更上一层楼。
UUID v7
在 18 中,另一个比较令人惊喜的是 v7 UUID 的支持 — 结合了以毫秒为单位的 Unix 时间戳和随机位,提供唯一性和可排序性,UUID v7 采用时间戳作为生成 UUID 的核心部分,这意味着它是有序的。与 UUID v4 的随机性不同,UUID v7 生成的 UUID 在时间上具有自然的顺序。这样的有序性在数据库和分布式系统中具有重要优势,特别是在数据插入、索引和查询时,有序的 UUID 使得数据可以更好地分布和排序,避免了 UUID v4 生成的随机分布可能导致的性能问题。
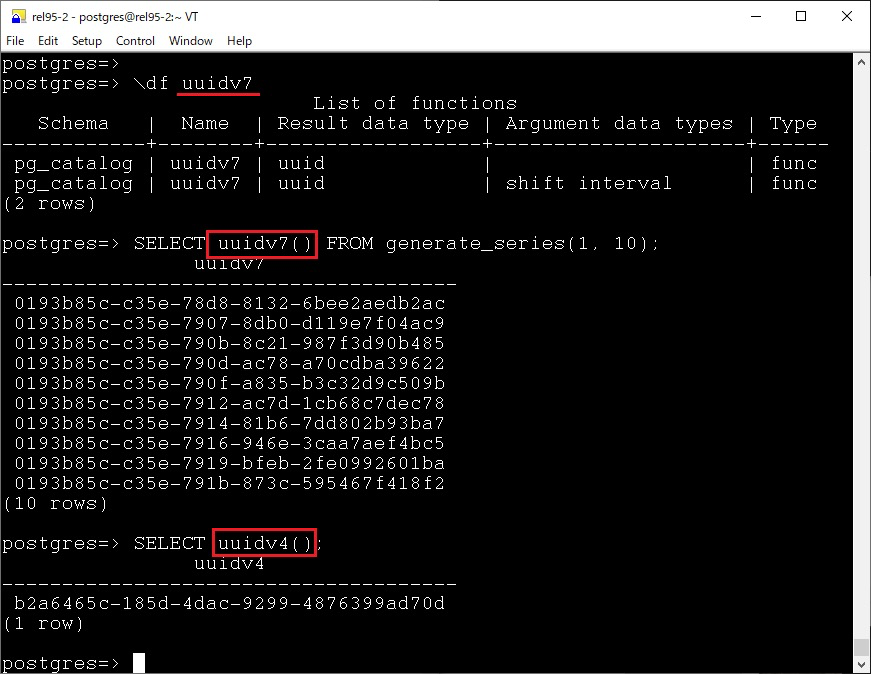
非 V7 的 UUID 其危害我已经写过不少文章进行阐述了,那么在 18 以前如何实现 v7 呢?可以参照 Howtos 里面的相关文章:
•https://postgres-howto.cn/#/./docs/64?id=how-to-use-uuid[2]•https://postgres-howto.cn/#/./docs/65?id=uuid-v7-and-partitioning-timescaledb[3]
使用唯一索引检测冗余的 GROUP BY 列
原本在 GROUP BY 包含关系表的所有主键列时,所有其他不属于主键的列可以从 GROUP BY 子句中移除,因为这些列在功能上依赖于主键,并且主键本身足以确保组的唯一性。这个优化特性被扩展到不仅适用于主键索引,还支持任何唯一索引。也就是说,如果表上存在一个唯一索引,优化器可以使用该索引来移除 GROUP BY 中冗余的列。
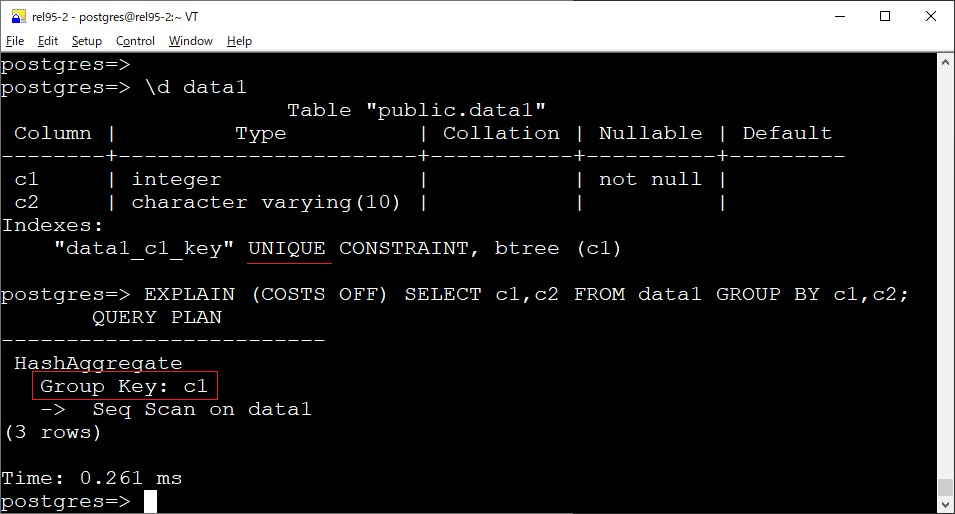
针对这个,让我想起了另一个内核知识点,我们知道,对于 group by,非聚合列必须包含在 group by 子句中,否则会报如下错误 xxx must appear in the GROUP BY clause or be used in an aggregate function
postgres=# create table test(id int primary key,info text); CREATE TABLE postgres=# insert into test values(1,'hello'); INSERT 0 1 postgres=# insert into test values(2,'world'); INSERT 0 1 postgres=# insert into test values(3,'postgres'); INSERT 0 1 postgres=# insert into test values(4,'postgres'); INSERT 0 1 postgres=# select * from test; id | info ----+---------- 1 | hello 2 | world 3 | postgres 4 | postgres (4 rows)
当非聚合列不包含在 group by 子句中会报错,但是如果按照主键的话,就不会报错
postgres=# select id,count(*) from test group by info; ERROR: column "test.id" must appear in the GROUP BY clause or be used in an aggregate function LINE 1: select id,count(*) from test group by info; ^ postgres=# select id,info,count(*) from test group by id; id | info | count ----+----------+------- 2 | world | 1 3 | postgres | 1 4 | postgres | 1 1 | hello | 1 (4 rows) postgres=# select id,info,count(*) from test group by id,info; id | info | count ----+----------+------- 2 | world | 1 3 | postgres | 1 4 | postgres | 1 1 | hello | 1 (4 rows)
因为如果是按照主键进行分组,由于主键的原因,那么该行必然是唯一的,即使加上其他的列,也是固定的分组。但是比较可惜的是,截止目前只能是主键,唯一约束 + not null 也不行,虽然语义是一样的,代码里有说明
/*
* remove_useless_groupby_columns
* Remove any columns in the GROUP BY clause that are redundant due to
* being functionally dependent on other GROUP BY columns.
*
* Since some other DBMSes do not allow references to ungrouped columns, it's
* not unusual to find all columns listed in GROUP BY even though listing the
* primary-key columns would be sufficient. Deleting such excess columns
* avoids redundant sorting work, so it's worth doing. When we do this, we
* must mark the plan as dependent on the pkey constraint (compare the
* parser's check_ungrouped_columns() and check_functional_grouping()).
*
* In principle, we could treat any NOT-NULL columns appearing in a UNIQUE
* index as the determining columns. But as with check_functional_grouping(),
* there's currently no way to represent dependency on a NOT NULL constraint,
* so we consider only the pkey for now.
*/
static void
remove_useless_groupby_columns(PlannerInfo *root)
{
Query *parse = root->parse;
Bitmapset **groupbyattnos;
Bitmapset **surplusvars;
ListCell *lc;
int relid;
值得一提的是,在 16 中支持了 any_value,用于解决这种问题。
pg_set_relation_stats
截止最新版 17,PostgreSQL 中还没有官方方法来手动调整优化器统计信息,在 18 中已经可以初步做到了
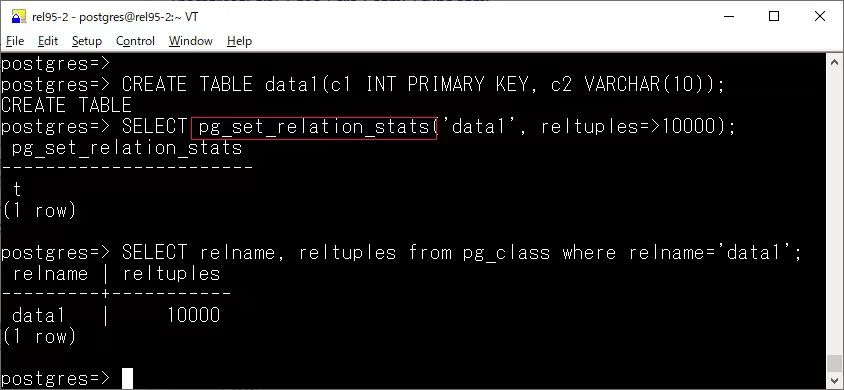
以这篇文章的例子为例 https://www.dbi-services.com/blog/postgresql-18-tweaking-relation-statistics/[4]
postgres=# create table t ( a int, b text ); CREATE TABLE postgres=# insert into t values (1,'aa'); INSERT 0 1 postgres=# insert into t select i, 'bb' from generate_series(2,100) i; INSERT 0 99 postgres=# analyze t; ANALYZE postgres=# create index i on t(b); CREATE INDEX postgres=# d t Table "public.t" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- a | integer | | | b | text | | | Indexes: "i" btree (b) postgres=# select relpages,reltuples from pg_class where relname = 't'; relpages | reltuples ----------+----------- 1 | 100 (1 row) postgres=# explain select * from t where b = 'aa'; QUERY PLAN ------------------------------------------------- Seq Scan on t (cost=0.00..2.25 rows=1 width=7) Filter: (b = 'aa'::text) (2 rows)
虽然有索引,但是只有一个数据块并且只有一行满足条件,优化器认为走顺序扫描更快,现在可以通过 pg_set_relation_stats 调整统计信息 (临时的,手动或自动分析都会覆盖),让优化器走了索引扫描。
postgres=# select * from pg_set_relation_stats('t'::regclass, 1, 1000000 );
pg_set_relation_stats
-----------------------
t
(1 row)
postgres=# x
Expanded display is off.
postgres=# select relpages,reltuples from pg_class where relname = 't';
relpages | reltuples
----------+-----------
1 | 1e+06
(1 row)
postgres=# explain select * from t where b = 'aa';
QUERY PLAN
-----------------------------------------------------------------
Index Scan using i on t (cost=0.17..183.18 rows=10000 width=7)
Index Cond: (b = 'aa'::text)
(2 rows)
真不错,看似一小步,实则是一大步!在德哥的吐槽大会上,有一期[5]也是吐槽优化器的,有一段内容如下:

VACUUM
autovacuum_vacuum_max_threshold
新增了一个 autovacuum_vacuum_max_threshold 参数,PostgreSQL 默认使用 autovacuum_vacuum_threshold 和 autovacuum_vacuum_scale_factor 两个参数来计算何时对表进行自动清理。这两个参数通常适用于小型表,使其更频繁地进行 VACUUM 操作,以确保性能。然而,对于非常大的表,即使更新操作的绝对数量较多,按照比例计算,更新操作所占的比例仍然可能较低,导致这些表不太可能触发自动清理。
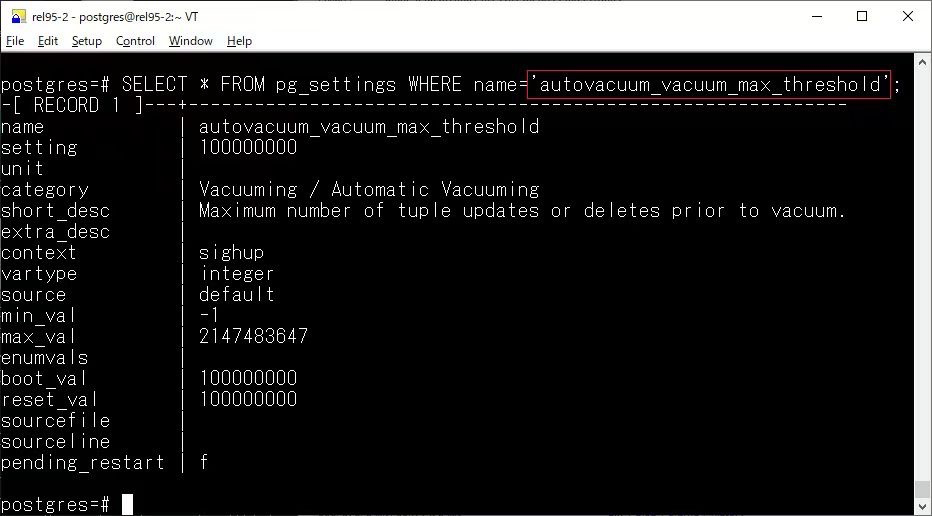
autovacuum_vacuum_max_threshold 解决了这个问题,简单粗暴,允许指定一个绝对的更新次数阈值,一旦表中的更新次数达到该阈值,就会触发自动清理操作。这可以确保对于那些更新数量很大的表,VACUUM 操作不会因为表的相对更新比例较低而被推迟。
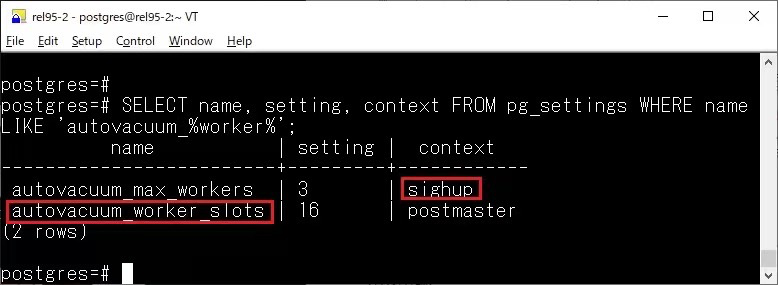
autovacuum_max_workers
现在修改 autovacuum_max_workers 不需要重启了,直接 reload 即可
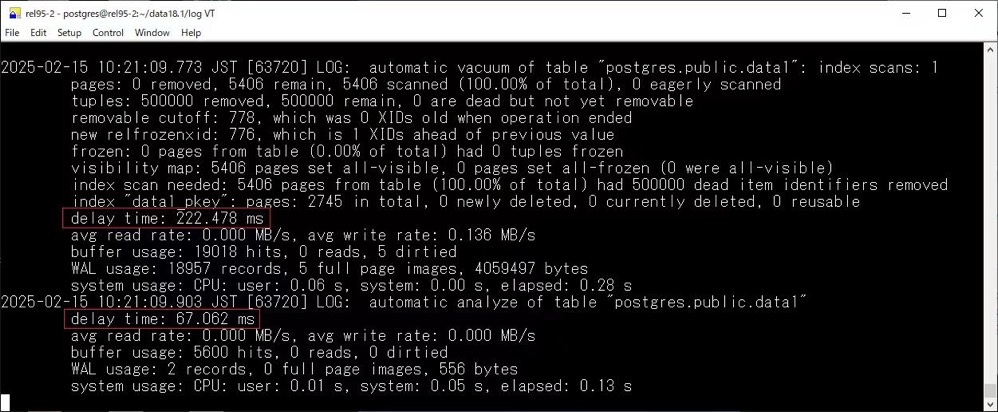
其次在日志中可以看到 delay time 了
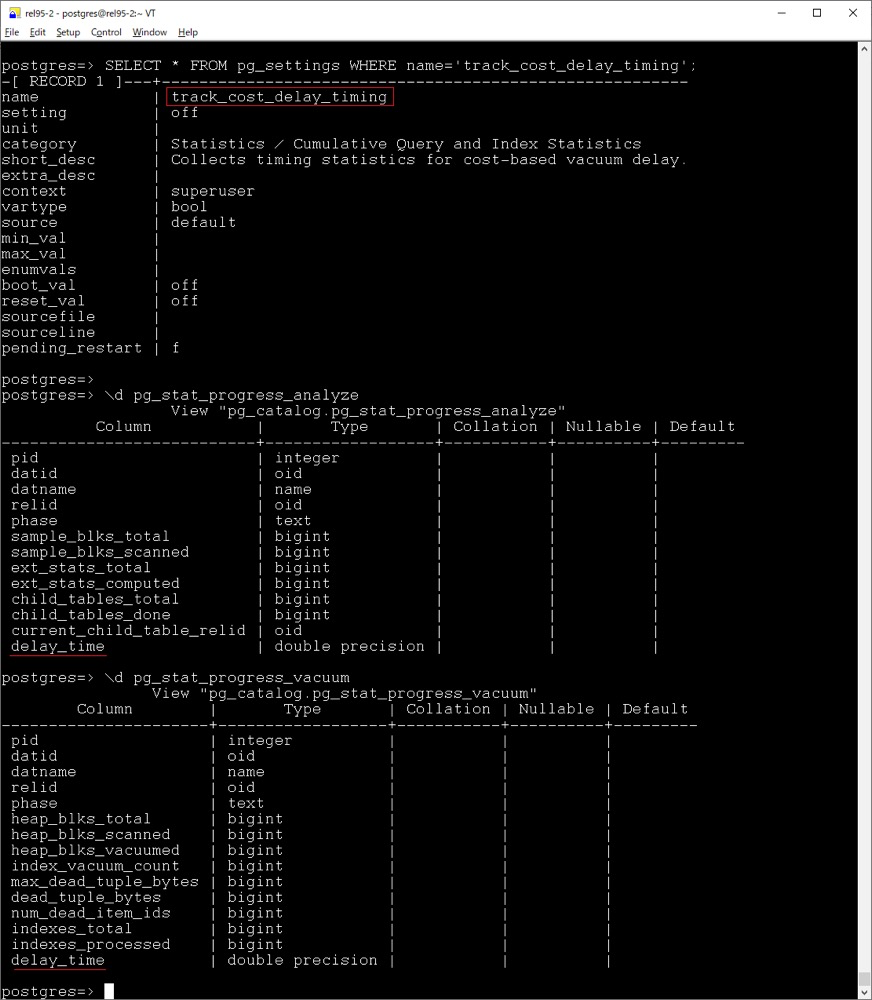
track_cost_delay_timing
另外新增了一个 track_cost_delay_timing 参数,启用后,将记录基于成本的清理延迟统计信息的时间,用于清理和分析操作,并将在 pg_stat_progress_analyze 和 pg_stat_progress_vacuum 中的 delay_time 列中可见,不过在计时较差的平台上,也可能会造成较大的性能影响,因此默认是关闭的。
vacuum_max_eager_freeze_failure_rate
新增 vacuum_max_eager_freeze_failure_rate 参数,参数设定了一个失败比例阈值,表示在扫描过程中,如果超过这个比例的页面无法成功冻结,VACUUM 将停止使用提前冻结方式,并回退到正常的冻结过程。这有助于避免因为大量冻结失败导致的性能下降。
其他
元命令
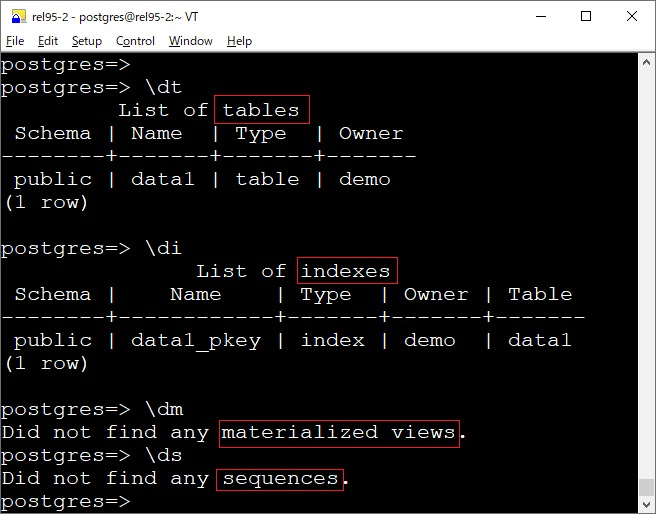
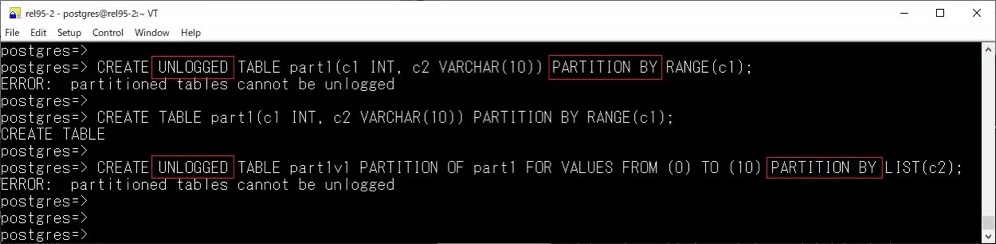
现在分区表不再允许 ALTER TABLE ... SET [UN]LOGGED 的操作:
COPY 新增 REJECT_LIMIT 选项:
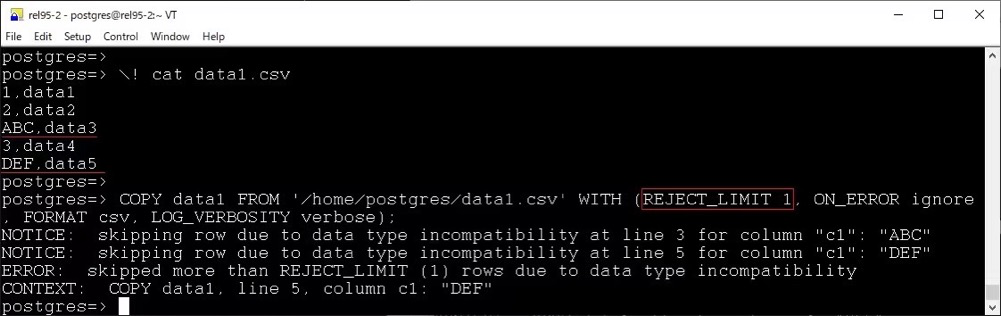
file_fdw 也新增了一个 REJECT_LIMIT 选项 (还新增了on_error 和 log_verbosity)。
temporal FOREIGN KEY contraints:https://www.depesz.com/2024/10/03/waiting-for-postgresql-18-add-temporal-foreign-key-contraints/[6]
小结
简而言之,18 也是一个值得期待的大版本,让我们拭目以待!
- 相关推荐
- 热点推荐
- 内存
- postgresql
-
PolarDB for PostgreSQL云原生数据库2022-06-17 701
-
postgreSQL命令的词法分析和语法分析2019-05-16 1571
-
PostgreSQL操作备忘录2019-05-23 1935
-
Linux PostgreSQL操作2019-07-18 1744
-
PostgreSQL的常见问题总结2019-07-24 1816
-
云栖干货回顾 | 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读2019-10-23 1232
-
RDS for PostgreSQL的插件的创建/删除和使用方法2022-04-25 3965
-
PostgreSQL 13正式发布2020-10-10 2541
-
多层面分析 etcd 与 PostgreSQL数据存储方案的差异2023-03-20 923
-
Devart:PostgreSQL GUI工具2023(下)2023-05-17 1615
-
PostgreSQL 插件那么多,怎样管理最高效?2023-06-30 1134
-
如何快速完成PostgreSQL数据迁移?2023-08-14 3571
-
为什么选择 PostgreSQL2023-09-30 2278
-
MySQL还能跟上PostgreSQL的步伐吗2024-11-18 1093
-
利用SSIS源、查找及目标组件集成PostgreSQL数据至ETL流程2025-02-07 2297
全部0条评论

快来发表一下你的评论吧 !
