

谷歌开发了一种名为NSynth Super的合成器,利用机器出新声音
电子说
描述
世界上的乐器种类繁多,但这还不够。谷歌开发了一种名为NSynth Super的合成器,利用机器学习能够造出独一无二的新声音。今天谷歌将这一工具的代码开源,看看这个奇妙的“玩具”到底能变出什么花样吧。
什么是NSynth Super?
NSynth Super是谷歌研究项目Magenta正在进行的实验中的一部分,该项目的目的是探索机器学习如何帮助艺术家一新方式创作艺术和音乐。
科技在创造新声音方面一直发挥着重要作用——从声音的扭曲到合成电音。今天,机器学习和神经网络的进步为声音的创作提供了新可能。
在过去研究的基础上,Magenta创造了NSynth(神经合成器)。这是一种机器学习算法,利用深度神经网络学习声音的特征,然后根据这些特征创造出完全新的声音。
相比于简单的将声音组合起来,NSynth利用原声音的音色重新合成了全新的声音,所以你可以听到一半是笛子一半是西塔琴的声音。
自从NSynth发布后,Magenta就不断尝试开发不同的音乐交互工具,想让NSynth算法更容易上手。作为探索的一部分,Magenta与谷歌创意实验室(Google Creative Lab)合作,创造出了NSynth Super。这是一款开源的实验性工具,音乐家能通过里面默认的4种原始声音生成全新的声音。现在这款产品的原型正在音乐人圈子里进行小范围的实验,评估他们使用的感受。
NSynth Super是如何工作的?
在这个实验中,音乐家们在录音室里录制了跨15个音的16种原始声音源,然后将其输入到NSynth算法中,用算法生成新的声音。然后将生成的超过10万种新的声音加载到产品原型中。
每个旋钮代表四种不同的源声音,音乐家能通过控制旋钮选择不同音色,然后手指在触摸屏上滑动,将这四种声音结合起来。
NSynth Super可以通过任何MIDI源播放,例如DAW,音序器或者键盘。
NSynth算法是如何工作的?
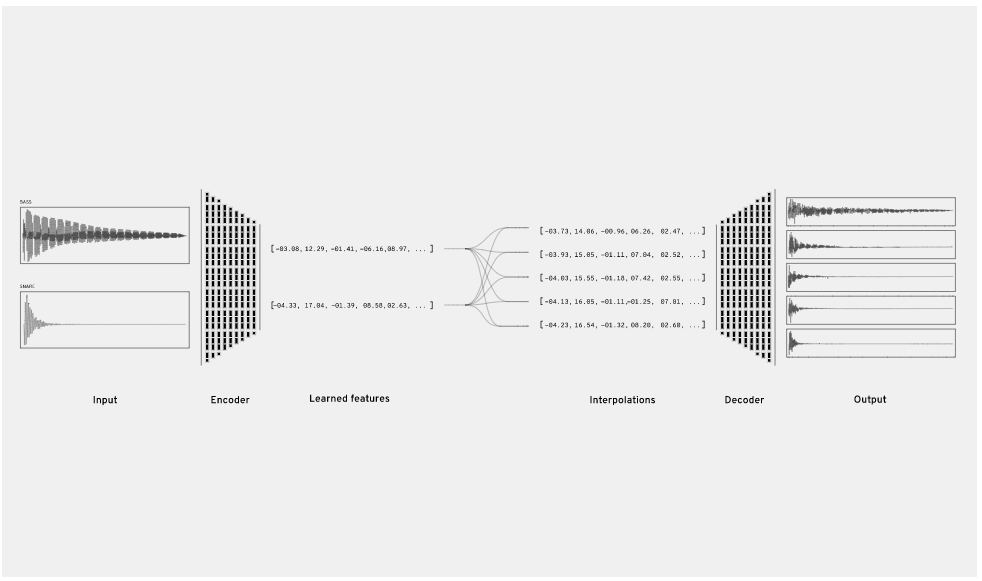
根据个人水平、风格不同,NSynth利用深度神经网络生成不同的声音。NSynth直接从数据中学习,可以让艺术家直接控制音色和节凑,并能够手动探索创造新的声音。
NSynth是一种算法,可以结合现有声音的特征来生成新的声音。为此,该算法将不同的声音作为输入。
使用自动编码器,它可以从每个输入中提取16个时间特征。然后将这些特征线性插入创建新的嵌入(每个声音的数学表示)。然后将这些新的嵌入解码成新的声音,这些声音具有两个输入的声音质量。
完整地介绍可以参见Magenta的博客,数据集合算法可以在原论文中找到。
如何才能得到NSynth Super?
触摸屏可发现新声音
音色选择钮
音色调整钮
和Magenta其他项目一样,NSynth Super建立在开源库之上,例如TensorFlow和openFrameworks,目的是让更多的艺术家、编程者和研究者体验这一创造性的过程。NSynth Super的开源版本包含所有开源代码、简图和设计模板,都可以在GitHub上下载。
-
多环锁相频率合成器的设计2010-05-13 0
-
合成器2017-12-06 0
-
一种L波段频率合成器设计的详细介绍2019-06-20 0
-
一种基于FPGA的PLL数频率合成器设计2019-06-25 0
-
基于DDS的频率合成器设计介绍2019-07-08 0
-
如何利用FPGA设计PLL频率合成器?2019-07-30 0
-
什么是频率合成器2019-08-19 0
-
基于555定时器的合成器2022-07-20 0
-
一种中波DDS频率合成器的设计与实现2009-09-03 578
-
频率合成器,频率合成器原理及作用是什么?2010-03-23 14950
-
径向功率分配合成器的设计2012-02-17 1249
-
一种Ka波段基片集成波导功率合成器的设计2016-01-04 629
-
pll频率合成器工作原理与pll频率合成器的原理图解释2023-02-24 9632
-
如何制作一个音频合成器?2023-05-13 2112
-
一种用DDS激励PLL的X波段频率合成器的设计方案2023-10-24 215
全部0条评论

快来发表一下你的评论吧 !
