

在英特尔哪吒开发套件上部署DeepSeek-R1的实现方式
描述
01本地部署 DeepSeek 的必要性
随着人工智能技术的快速发展,企业对 AI 模型的部署方式有了更多选择。本地部署 DeepSeek-R1 模型具有以下显著优势,使其成为许多企业和开发者的首选:
1. 数据隐私与安全
在本地环境中部署 DeepSeek-R1 模型,可以确保敏感数据完全隔离于外部网络,避免数据泄露的风险。这对于处理涉及商业机密、个人隐私或受监管数据的应用场景至关重要。
2. 定制化能力
本地部署允许企业根据自身业务需求对模型进行微调和优化。例如,通过领域知识微调,DeepSeek-R1 可以更好地适应特定行业的应用场景,从而提升模型的准确性和实用性。
3. 低延迟响应
本地部署减少了对云端服务的依赖,避免了网络传输带来的延迟。DeepSeek-R1 在本地环境中能够实现毫秒级的推理速度,这对于需要实时响应的应用(如智能客服、自动化流程等)尤为重要。
4. 成本可控
与依赖云端 API 调用相比,本地部署可以显著降低长期使用成本。例如,通过优化硬件配置和资源利用,DeepSeek-R1 的部署成本可以大幅降低,同时避免了按调用次数计费的高昂费用。
02在边缘终端部署本地大模型的好处
边缘终端,如树莓派和英特尔哪吒开发套件,通常具有较低的功耗和成本,同时具备一定的计算能力。在这些设备上部署 DeepSeek-R1 大模型,可以带来以下好处:
1. 降低云端依赖
边缘终端的本地化部署减少了对云端服务的依赖,使得设备能够在离线或网络不稳定的情况下独立运行。这对于一些需要在偏远地区或网络受限环境中使用的场景(如智能家居、工业物联网等)非常有价值。
2. 应用场景拓展
在边缘终端部署 DeepSeek-R1 可以推动 AI 技术在更多领域的应用,如教育、开发实验、智能家居等。这不仅降低了 AI 技术的使用门槛,还促进了技术的普及。
3. 隐私保护
由于数据处理完全在本地完成,边缘终端部署可以有效避免敏感信息的外泄,尤其适合对隐私有高要求的场景。
03在树莓派上部署 DeepSeek-R1 的实现方式
目前网上看到的在树莓派上部署大模型的主流实现方式是通过Ollama。
Ollama 是一个轻量级的 AI 模型部署工具,支持在树莓派等低功耗设备上运行 DeepSeek-R1 模型。用户可以通过简单的命令行操作下载并启动模型,例如运行 `ollama run deepseek-r1:1.5b` 来部署 1.5B 版本。它具有部署简单和资源占用低的优势,Ollama 提供了简洁的命令行操作界面,降低了部署的技术门槛。1.5B 版本的 DeepSeek-R1 模型对硬件资源的需求较低,适合树莓派等低配设备。
但也存在一些劣势,比如:
性能限制:树莓派的硬件性能有限,推理速度较慢,可能无法满足实时性要求较高的应用。
内存瓶颈:运行较大模型(如 8B 版本)时,树莓派可能面临内存不足的问题。
功能受限:部分高级功能可能因硬件限制无法充分发挥,例如复杂的多任务处理。
04在英特尔哪吒开发套件上部署 DeepSeek-R1 的实现方式
目前暂未看到有在英特尔哪吒开发套件上部署 DeepSeek-R1 的介绍。为填补这一空白,本文介绍如何采用 WasmEdge 本地部署 DeepSeek-R1 的方式。

英特尔哪吒开发套件搭载了英特尔N97处理器(3.6GHz),配备64GB eMMC存储和8GB LPDDR5内存。英特尔N97处理器属于 Intel Alder Lake-N 系列,采用仅 E-Core 的设计,专为轻量级办公、教育设备和超低功耗笔记本电脑设计,成本和功耗更低,更适合嵌入式设备。
更关键的是!英特尔哪吒最大的优势就是自带集成显卡,Intel UHD Graphics,我们可以在iGPU上运行大模型。
WasmEdge 是一种高性能的 WebAssembly 运行时,适用于在边缘设备上部署轻量级应用。WasmEdge 提供了良好的跨平台支持,能够在多种硬件平台上运行,包括树莓派和 Intel 哪吒开发套件。这使得开发者可以使用同一套部署方案适配不同的硬件环境,降低了开发成本。
WasmEdge 本身轻量级,启动速度快,适合资源受限的边缘设备。通过 WebAssembly 的高效执行机制,可以显著提升模型的推理速度,优化资源利用率。
WebAssembly 的设计使得模型能够在边缘设备上以接近原生的速度运行。此外,WasmEdge 还支持多线程和并行计算,进一步提升了推理效率。
05具体部署方案
1、下载依赖
apt update && apt install -y libopenblas-dev
2、克隆 WasmEdge 仓库
git clone https://github.com/WasmEdge/WasmEdge.git
3、源码编译
cmake -GNinja -Bbuild -DCMAKE_BUILD_TYPE=Release -DWASMEDGE_PLUGIN_WASI_NN_BACKEND="GGML" -DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_BLAS=OFF -DCMAKE_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu
4、执行编译后的文件
cmake --build build
5、安装
cd build sudo cmake --install . --prefix /home/hans/WasmEdge
6、运行模型
选用的是8B的DeepSeek- R1蒸馏模型(量化后3G大小),一般看到树莓派上只能跑1.5B的DS蒸馏模型。
运行命令
wasmedge --dir .:. --nn-preload defaultAUTO:/home/DeepSeek-R1-Distill-Llama-8B.gguf llama-chat.wasm -p llama-3-chat
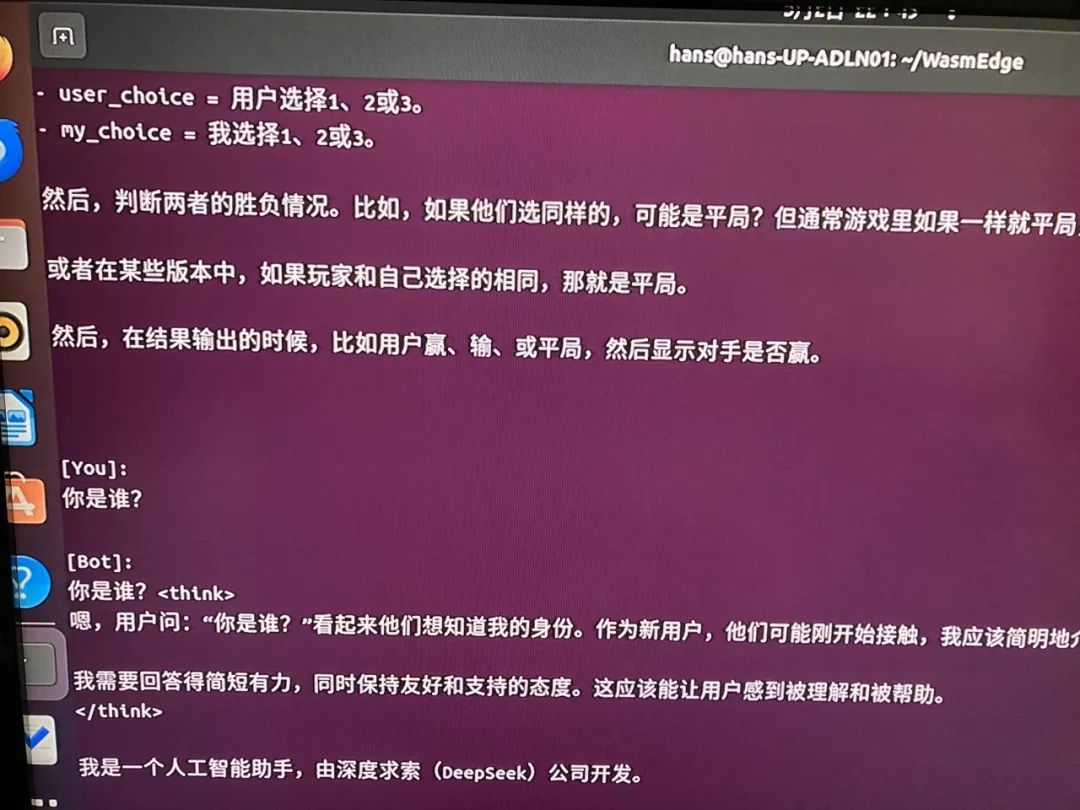
7、运行效果
总结
在探索了 DeepSeek-R1 的本地部署之旅后,我们不禁感叹:AI 的世界正变得越来越触手可及!从企业对数据隐私的严守,到边缘设备上的高效推理,再到英特尔哪吒开发套件上的灵活部署,DeepSeek-R1 正在以一种前所未有的方式,将智能的力量带到每一个角落。
而当我们站在技术的十字路口,回望这一路的探索,或许会发现,真正的魔法并非来自模型本身,而是我们对技术的掌控和创新。
最后,让我们以 DeepSeek-R1 的智慧之光,照亮未来的每一步。正如那句诗所言:“智能入世万象新,笑与人间共潮生。”在这个充满无限可能的时代,Intel 哪吒开发套件不仅仅是一个开发板,它是我们通往智能未来的钥匙。
-
如何使用OpenVINO运行DeepSeek-R1蒸馏模型2025-03-12 2682
-
DeepSeek-R1:别被它的光环迷了眼,这些能力局限你得知道!2025-03-11 1164
-
RK3588开发板上部署DeepSeek-R1大模型的完整指南2025-02-27 2126
-
英特尔赋能DeepSeek本地运行,助力汽车升级“最强大脑”2025-02-17 1272
-
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择2025-02-14 4018
-
用DeepSeek-R1实现自动生成Manim动画2025-02-07 5410
-
使用英特尔哪吒开发套件部署YOLOv5完成透明物体目标检测2024-11-25 1468
-
英特尔开发套件『哪吒』在Java环境实现ADAS道路识别演示 | 开发者实战2024-04-29 1786
-
【转载】英特尔开发套件“哪吒”快速部署YoloV8 on Java | 开发者实战2024-03-23 1845
-
基于OpenVINO在英特尔开发套件上实现眼部追踪2023-09-18 1647
-
使用英特尔物联网商业开发套件改变世界2020-05-31 3113
-
英特尔的945GME高速芯片组开发套件2017-10-30 895
-
英特尔82801HM IO控制器开发套件2011-12-07 1184
全部0条评论

快来发表一下你的评论吧 !
