

NXP AFCI工具链操作指南 工程师从“小白”到“大神”的进阶之路
描述
之前介绍恩智浦基于MCXN系列带有NPU的MCU产品开发了AFCI电弧检测方案智能守护,安全无忧:恩智浦MCX N系列NPU电弧检测技术解析,加快用户产品开发流程。基于NPU的AFCI检测方法无论在检测线路距离还是检测灵敏度都比传统方案具有一定优势。
本文着重介绍恩智浦AFCI工具链的操作方法,加快您的上手速度。首先看硬件连接:
硬件连接

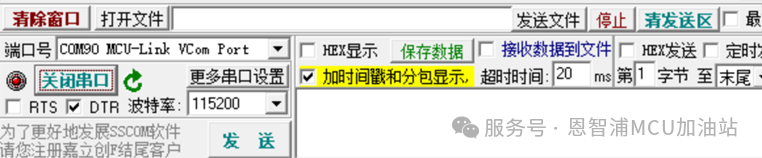
拿到开发套件,底板为如上图所示的FRDM-MCXN947开发板,首先通过上图橙色标注的USB口使用板载的MCU-Link烧写MCU固件到开发板,在程序正常运行时,此接口同时具备虚拟串口的输出功能。可以使用串口工具查看AFCI检测输出结果,配置如下图所示:
接着,将AFCI扩展板插入Arduino扩展口,如上图所示,注意加入方向。板子上的跳线帽可保持默认状态。将CT传感器接入AFCI扩展板的P1或者P2接口(红框标注最左边绿色插座)。硬件连接完毕以后,就可以进行接下来的步骤了。

接下来我们看如何运行软件工具:
运行
程序分发时为压缩包,其中应包含“_internal”,“models”与“afci.exe”三个文件(文件夹),将它们解压在同一位置,点击运行“afci.exe”即可。”_internal”文件夹包含程序运行时所需要的各种运行库,请不要对其进行任何修改;“models”文件夹包含了可以使用的模型结构;
运行“afci.exe”来打开应用,程序在运行过程中占用8050与8051端口,请确保这两个端口没有被其他应用占用。应用打开时需要加载深度学习相关运行库,取决于环境配置因素,打开速度可能较慢。
在第一次运行应用时,会自动在同一目录下创建“data”文件夹,该文件夹用来保存程序运行中收集到的数据、手动标注的收据与训练后的模型。
训练并部署一个完整的电弧检测模型共分为5个步骤,分别对应应用侧栏的5个页面。接下来会详细介绍各个功能。
1. 收集数据 – Record
2. 标注数据 - Dataset
3. 训练模型 - Train
4. 测试模型 - Test
5. 部署至MCU – Deploy
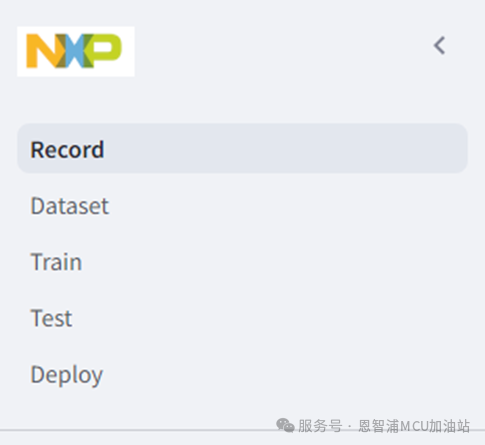
收集数据
收集数据的相关功能在“Record”页面下,该页面也是应用默认打开的功能。第一次打开后页面显示如下图所示,主要分为四个功能区。
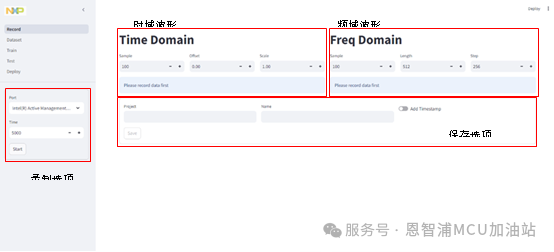
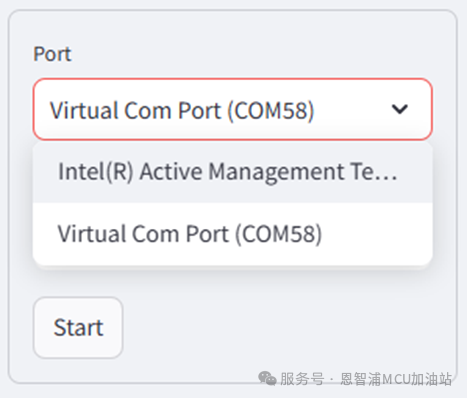
为了开始收集数据,首先请将开发板烧录正确固件,并按照第一章中所示连接方式,将烧录开发板连接至PC。正确连接后刷新页面,可以在录制选项区域中的“Port”选项中可以看到正确的串口设备,在图示例子中为”Virtual Com Port (COM58)”。并在左侧的Port一栏中选择正确的USB设备与录制时间,如果在选项中没有发现设备,请尝试刷新页面。在“Time”一栏中填入合适的时间,单位为毫秒。在例子中,选择端口“Virtual Com Port (COM58)”,录制时间填入10000,即10秒钟。点击“Start”开始录制,在录制完成前请不要重复操作设备。
录制过程中,界面如下图所示:
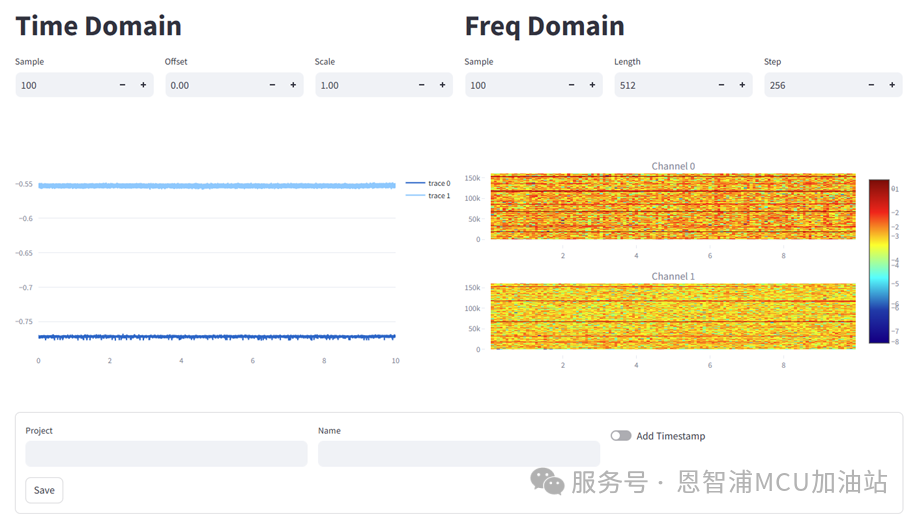
录制完成后,界面会自动刷新,展示录制到数据的时域图与频域图。该界面可分为上下两个部分,上部分可以对展示的时域或频域图设置。共有6个设置: - Sample:设置原始数据的采样间隔
- Offset:原始数据的偏移
- Scale:原始数据的缩放比例
- Length:频谱图分割长度
- Step:频谱图分割步进
在时域图中,原始数据首先通过“Sample”进行采样,然后通过“Offset”与“Scale”计算最终结果,(x-Offset) * Scale.
在频域图中,原始数据首先通过“Sample”进行采样,然后对数据以“Length”为长度、以“Step”为步进进行分割,对于每一段数据应用海宁窗(hann)以减少截断数据造成的频谱泄露,然后使用连续傅里叶变换计算频谱图。
请注意,目前该工具并不支持自动触发相关功能,所以在实际录制数据时,请调整录制时间以配合拉弧发生设备或者实际系统,以使拉弧或者其他想要采集到的信号发生在录制时间内。如果对采集到的数据不满意,可跳过保存步骤直接进行下一次录制。
对采集的数据满意,可以进行数据保存步骤,将本次测试数据保存到“data”文件夹下。保存功能共有三个选项:“Project”、“Name”、“Add Timestamp”。“Project”为项目名,采集到的数据、标注与模型均保存在项目下,"Name"为本次录制数据的名称,勾选“Add Timestamp"会在保存文件的名字加上录制时间尾缀。如果留空"Name",请勾选"Add Timestamp"以保证保存文件名合理,建议将"Name"项填入合适的名称,如"Arc" "Noise"等,以便后续区分。在本例中,保存数据如下图所示。

重复进行上述步骤,在录制到足够多的数据后,可进入标注阶段。
标注数据
标注数据的功能在“Dataset”页面下。打开该页面会自动加载最近的项目与最近录制的数据。如下图所示。
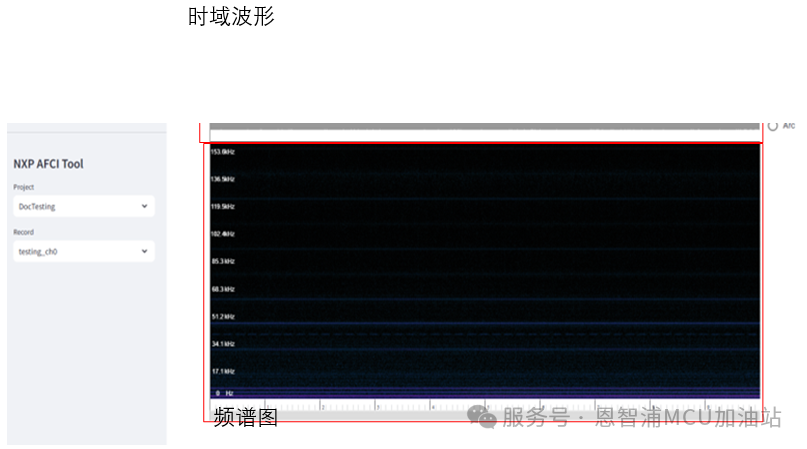
可以在左侧设置栏中选择录制好的数据,或随应用提供的测试数据,进行标注。在这我们选择示例项目“example_project”。该项目内置了24条数据,并对其中的部分数据进行了提前标注,标注好的数据会有“*”前缀,如下图所示。
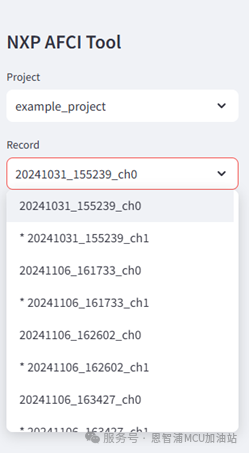
在该测试项目中,仅使用了单通道录制数据,通道0中不包含任何信息,所以请使用通道1数据进行标注与训练。打开任意一条标注好的数据,如下图所示。
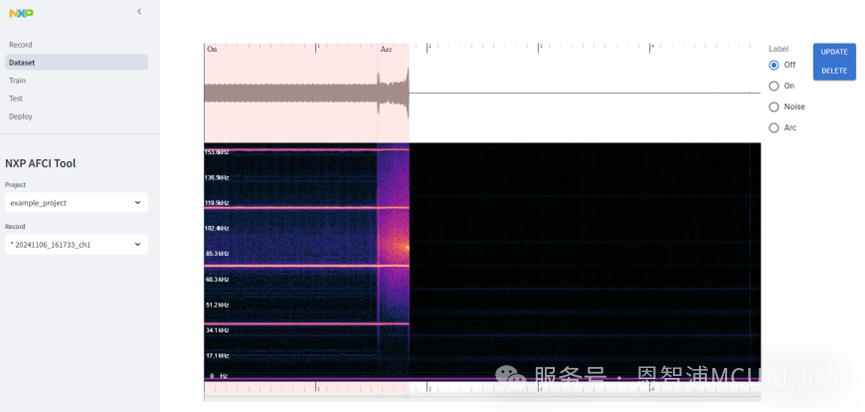
该条数据总时长5秒, 数据的前半部分,系统正常工作,在约1.5s后,系统出现电弧,直至约1.8s,系统停止工作。所以在右侧Label选项中选择“On”标签,并对应频谱图进行标注,框选从开始到约1.5s结束;选择“Arc”标签,框选约1.5s至1.8s区间。未被标注的区间会自动应用“Off”标签。粗略标注结束后,可以使用鼠标滚轮对图表进行放大,同时在右侧选中相应的标签,鼠标点击要修改的标注的边界进行拖动,或点击标注区域对标注进行整体拖动;如果对标注不满意,可以双击该标注来删除。请注意,所有对已有标注的修改都应该首先在右侧选择相应类别,才可解锁对应类别标注的修改功能。
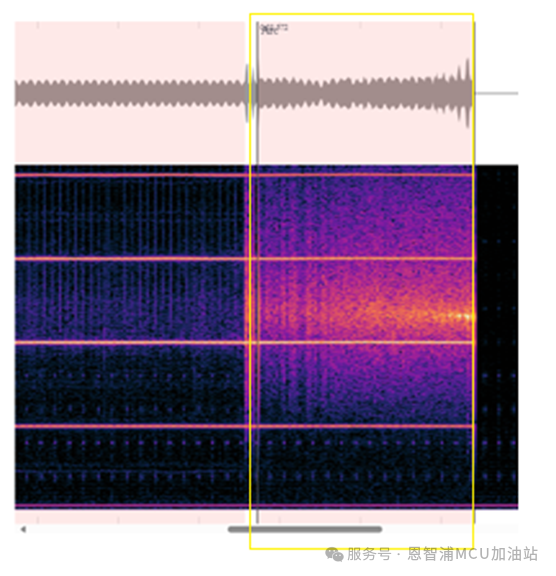
标注之间可以互相覆盖,在生成数据集时,会优先以“Arc”,“Noise”,“On”,“Off”的优先级去覆盖。
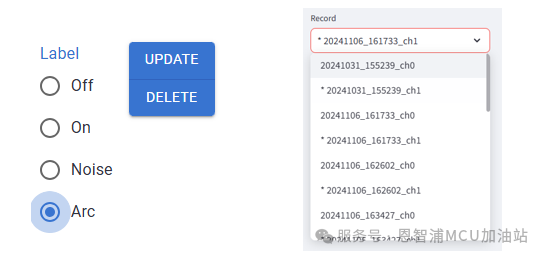
在标注结束后点击“Update”来把标注结果保存至硬盘。任何标注过的结果都会被用于后续训练,即使一条数据上没有任何标注(为标注区域默认为”OFF“)。如果想将某条标注过的数据删除,点击”Delete“以删除该条数据上的全部标注(包括默认的”OFF“),同时该条数据也不会进入后续的训练流程。会进入训练流程的数据在左侧会有*前缀标识。
模型训练
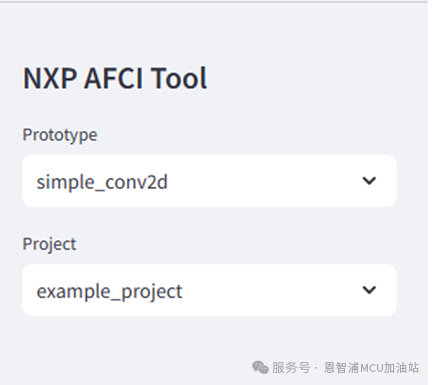
打开train标签页,进入训练页面。在左侧设置栏选择合适的项目与模型,在例子中让我们选择“example_project”与“simple_fc”,如下图所示。
界面右侧有三个标签页,分别为“dataset”,“model”,“train”,分别表示训练的三个步骤,请依次执行。
首先是“dataset”,该标签页用来根据前步骤录制的数据与标注的结果生成数据集。在该步骤中,程序会将拥有标注的录制数据进行分段,并对每个分段进行RFFT计算及一些后处理,并配合标注信息为每段数据生成分类数据。
生成数据集共有4个选项,“Length”,“Step”,“To One-Hot”,“Add dimension for Conv Input”。其中“Length”与“Step”控制数据分段的长度与步进,勾选“To One-Hot“会生成分类模型,反之则会生成预测模型,建议勾选。勾选”Adddimension for Conv Input“会为生成的数据增加维度,以便卷积模型进行处理,建议勾选。在例子中,我们保持默认,如下图所示,点击”Create dataset”创建数据集。在创建成功后,黄色的“No datasetbuilt”信息会变为我们当前构建数据集的信息。

在构建数据集后,可以切换到“model”标签页创建模型,请确保在构建数据集后再创建模型,模型需要数据集的输入输出信息才可以创建。
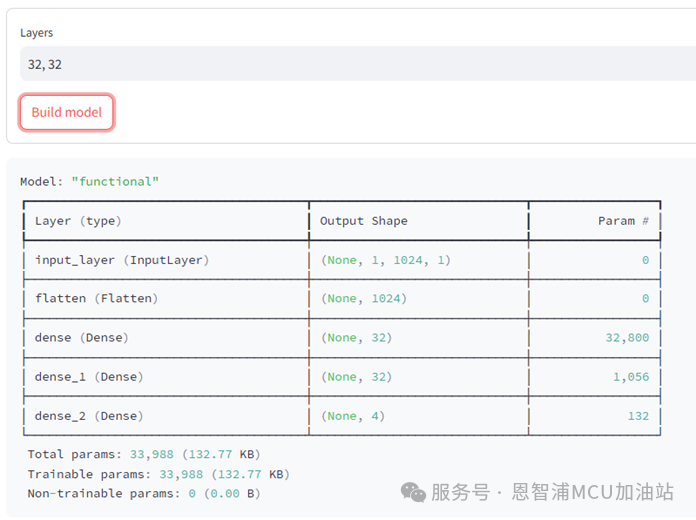
"simple_fc"模型有一个选项"Layers",用来调整模型的层数,在保持默认"32, 32"的情况下,点击"Build model"来创建模型,创建成功后,模型未创建的警告会消失,同时展示模型的输入输出、模型层数信息,如下图所示。
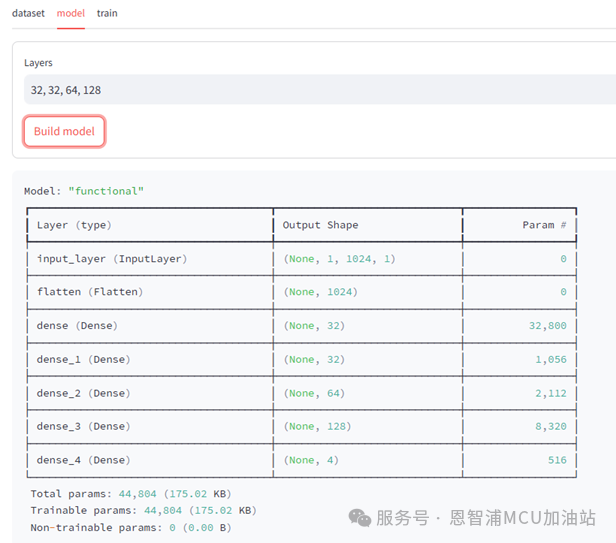
让我们对“Layers”选项进行修改,并重新构建模型,模型的结构也相应出现变化,如下图所示。以“simple_fc”模型的该选项为例,增加层数通常会使模型的大小增加、推理速度减慢、精度增加。
在模型创建后,切换到“train”标签页来对进行训练。训练共有如下四个选项,“Batch size”、“Epochs”、“Loss”、“LearningRate”。通过调整四个选项可以对训练效果进行微调,通常来说保持默认即可。在例子中,保持默认选项点击“Train”进行训练。
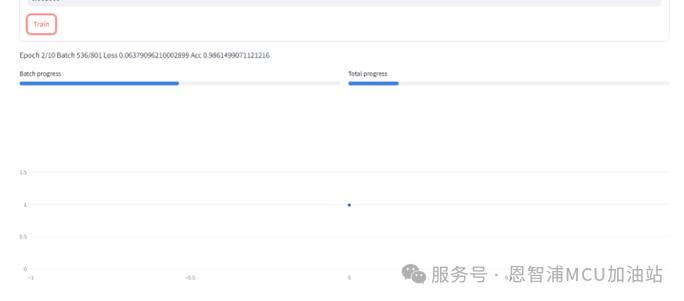
进行训练后,下方会出现训练的进度条,与模型精度随训练过程变化的折线图,如下图所示:
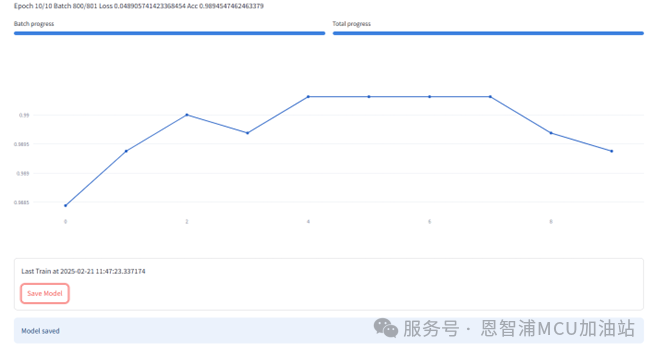
在训练完成后,点击保存来保存当前训练完成的模型,如下图所示:
自定义模型
如果要实现一个自定义模型,需要实现以下接口:
1. get_model_options() -> dict
2. get_training_options() ->dict
3. build_model(input_shape,is_classification, num_classes, **kwargs)
上述三个接口中 get_model_options 得到的选项会用来调用 build_model,get_training_options 得到的选项会用来调用model.compile()。具体实现可以参考simple_fc.py.
import streamlit as st
import keras
def get_model_options():
return dict()
def get_training_options():
return dict()
def build_model(input_shape, is_classification, num_classes, **kwargs):
inputs = keras.Input(input_shape)
x = inputs
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(num_classes)(x)
x = keras.layers.Softmax()(x)
outputs = x
return keras.models.Model(inputs=inputs, outputs=outputs)
测试模型
选择test页面,即可进行测试及量化。页面内容如下。右侧共有四个标签页,其功能分别是测试精度、转换TfLite、转换TfLite并量化、选择录制数据进行测试。
其中前三个标签页的主要功能是转换模型并测试精度。其中重要的部分是转换TfLite与量化TfLite,后续的步骤中需要将其转换后的模型。
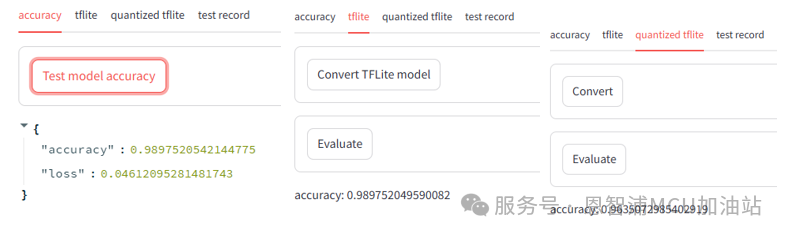
数字展示出来的精度并不直观,为了更加直接的展示模型的能力与准确度,请切换到“test record”标签页来对前面步骤中录制的数据进行测试。页面内容如下图所示:
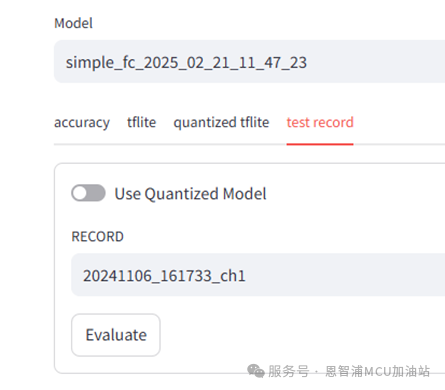
其中模型是我们刚刚训练并保存的模型,选择一条包含电弧的录制数据,点击“Evaluate”进行评估:
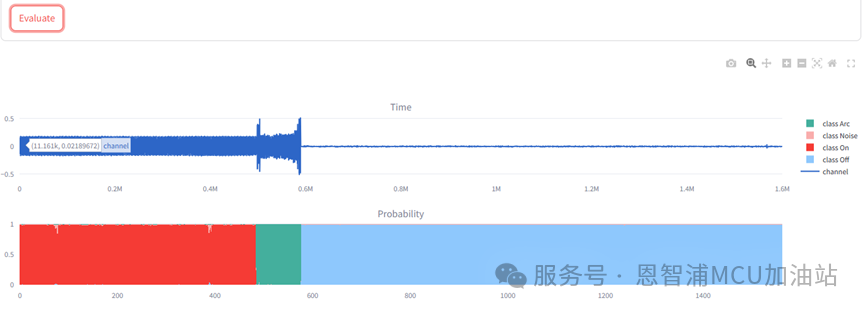
图中上半部分为该条数据的时域波形,下半部分为模型的推理概率图。可以看到时域波形中发生电弧的部分相对应的概率也几乎“Arc”标识,可以将鼠标悬浮在概率图上查看某一时刻推理的具体概率值。
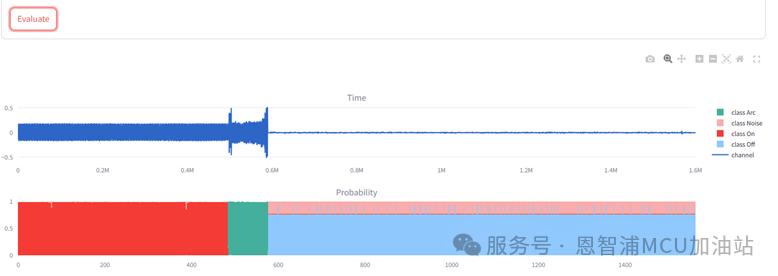
接下来可以勾选“Use Quantized Model”来使用量化模型进行测试,通常来说,对模型进行量化会提高推理速度、降低推理精度。使用量化模型的评估结果如下图所示。可以看到在波形的后半部分概率有较大变换,但对电弧部分数据并没有太大影响。
部署至MCU
选择“Deploy”来部署训练过的模型。同上一个步骤相同,请选择合适的项目和模型进行部署:
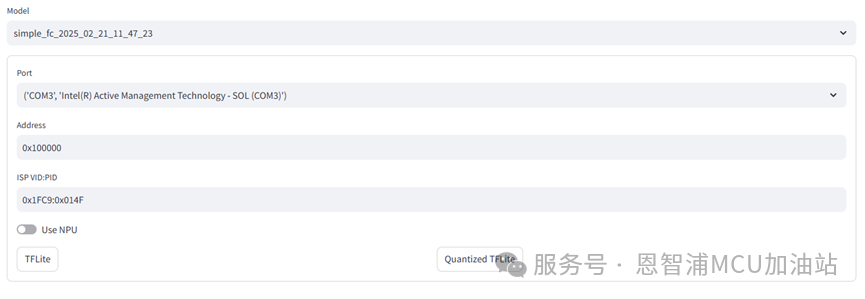
部署时共有四个选项,第一个选项应选择合适的端口,即MCU的USB接口。Address选项为模型部署的位置,默认为0x100000,该选项应配合MCU固件进行修改,否则会影响MCU程序的正常运行。”ISP VID:PID”选项则是为了在电脑连接了多个开发板时指定其中一块进行更新,通常来说不用修改。勾选“Use NPU”可以将模型转换为NPU专用的格式,使用NPU可以显著加速推理过程,请注意只有量化后的模型可以使用NPU进行加速。
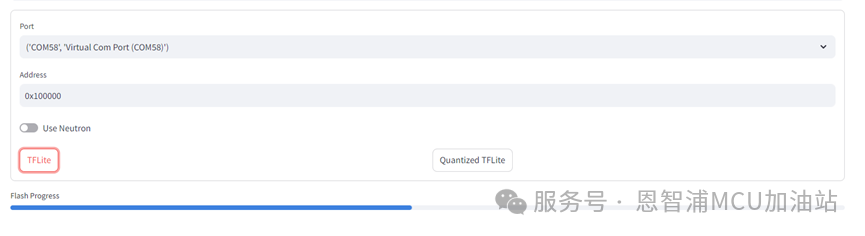
如果在上一步骤中转换过TfLite或者量化后的TfLite,则可以点击下方相应的选项,将模型烧录至合适的位置。在此处以TfLite为例,在烧录中会显示当前进度,在烧录结束后MCU会自动reset。
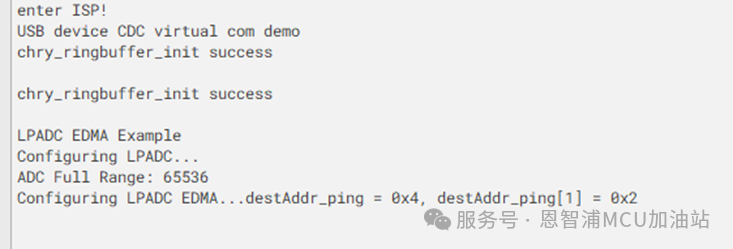
在成功烧录之后,可以打开串口工具观察当前的检测结果,如果成功检测到电弧,MCU端程序会通过串口打印字符串,并蓝灯闪烁提醒。搭建成功!
END
恩智浦致力于打造安全的连接和基础设施解决方案,为智慧生活保驾护航。
-
消费电子EMC整改:被动应对到主动防御的技术进阶之路2025-12-15 732
-
嵌入式工程师的进阶之路2025-08-13 4825
-
搞定EMC,工程师进阶的必经之路2022-11-03 2951
-
【EMC资料】搞定EMC,工程师进阶必经之路2022-08-08 1947
-
ETAS RTA-CAR工具链操作指南2022-02-23 12258
-
嵌入式开发工程师进阶之路相关资料推荐2021-11-05 1040
-
我的硬件工程师成长之路:从小白到大佬2021-02-23 8812
-
从小白到测试达人,【测试精英养成计划】为工程师打造进阶之路2020-06-22 1029
-
电子老顽童:分享电子工程师的技术及职业进阶指南2019-11-05 19390
-
【社区之星】从菜鸟到资深LabVIEW工程师--小鹰的fighting之路2015-12-24 18258
-
菜鸟到大神——硬件工程师进阶之路2015-05-19 10758
-
长城汽车招聘汽车电控研发工程师2014-04-17 2501
-
FPGA工程师进阶之路【独家原创】2012-02-24 18074
全部0条评论

快来发表一下你的评论吧 !
