

NVIDIA RTX 5880 Ada显卡部署DeepSeek-R1模型实测报告
描述
DeepSeek-R1 模型在 4 张 NVIDIA RTX 5880 Ada 显卡配置下,面对短文本生成、长文本生成、总结概括三大实战场景,会碰撞出怎样的性能火花?参数规模差异悬殊的 70B 与 32B 两大模型,在 BF16 精度下的表现又相差几何?本篇四卡环境实测报告,将为用户提供实用的数据支持和性能参考。
1 测试环境
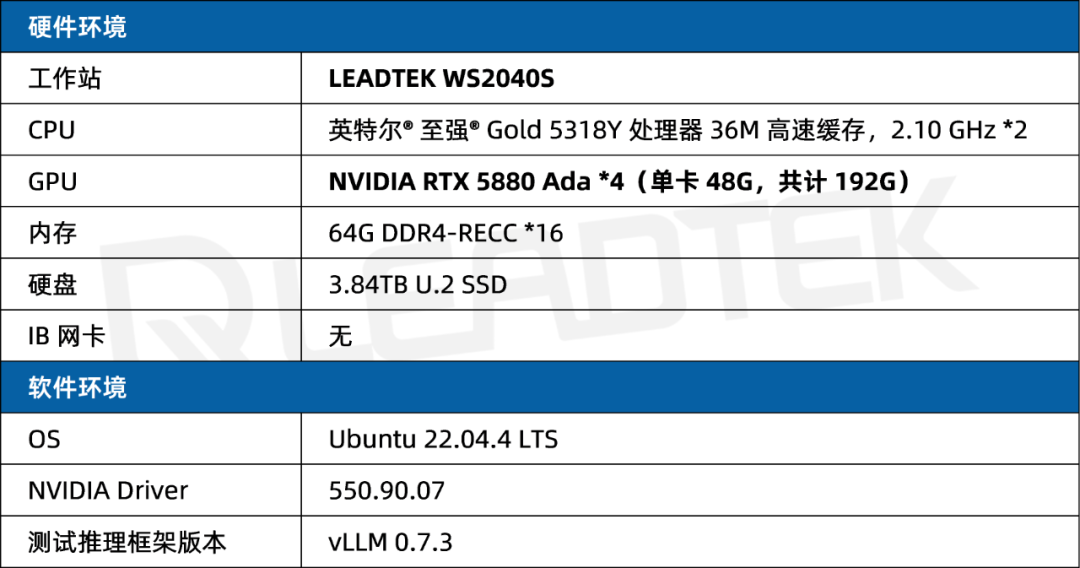
2 测试指标
首次 token 生成时间(Time to First Token, TTFT(s))越低,模型响应速度越快;每个输出 token 的生成时间(Time Per Output Token, TPOT(s))越低,模型生成文本的速度越快。
输出 Token 吞吐量(Output Token Per Sec, TPS):反映系统每秒能够生成的输出 token 数量,是评估系统响应速度的关键指标。多并发情况下,使用单个请求的平均吞吐量作为参考指标。
首次 Token 生成时间(Time to First Token, TTFT(s)):指从发出请求到接收到第一个输出 token 所需的时间,这对实时交互要求较高的应用尤为重要。多并发情况下,平均首次 token 时间 (s) 作为参考指标。
单 Token 生成时间(Time Per Output Token,TPOT(s)):系统生成每个输出 token 所需的时间,直接影响了整个请求的完成速度。多并发情况下,使用平均每个输出 token 的时间 (s) 作为参考指标。这里多并发时跟单个请求的 TPOT 不一样,多并发 TPOT 计算不包括生成第一个 token 的时间。
并发数(Concurrency):指的是系统同时处理的任务数量。适当的并发设置可以在保证响应速度的同时最大化资源利用率,但过高的并发数可能导致请求打包过多,从而增加单个请求的处理时间,影响用户体验。
3 测试场景
在实际业务部署中,输入/输出 token 的数量直接影响服务性能与资源利用率。本次测试针对三个不同应用场景设计了具体的输入 token 和输出 token 配置,以评估模型在不同任务中的表现。具体如下:

4 测试结果
4.1 短文本生成场景
使用 DeepSeek-R1-70B(BF16),单请求吞吐量约 19.9 tokens/s,并发 100 时降至约 9.9 tokens/s(约为单请求的 50%)。最佳工作区间为低并发场景(1-50 并发)。
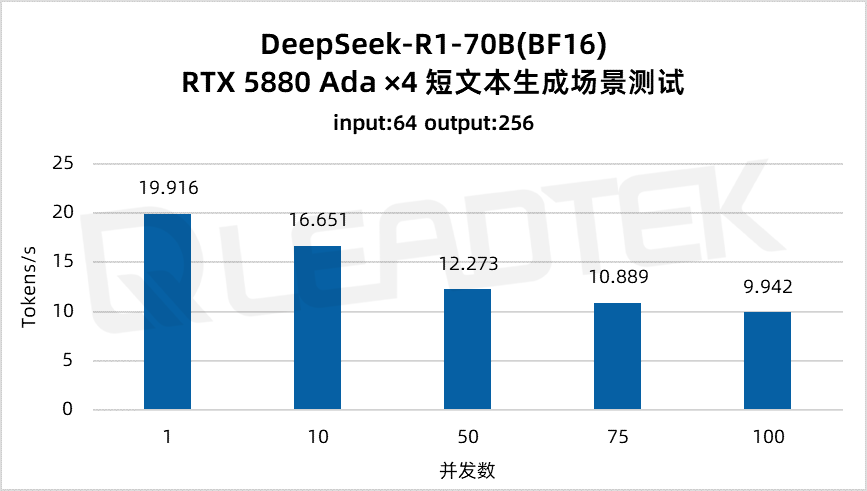
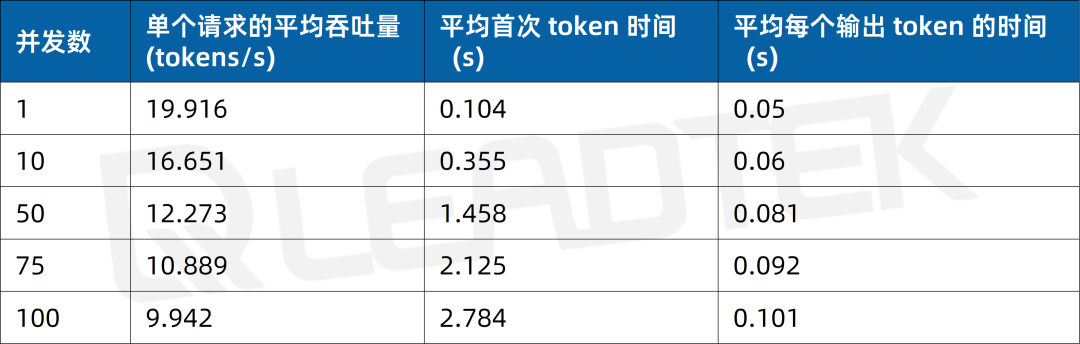
▲ DeepSeek-R1-70B(BF16) 测试结果图表
2025 丽台(上海)信息科技有限公司
本文所有测试结果均由丽台科技实测得出,如果您有任何疑问或需要使用此测试结果,请联系丽台科技(下同)
使用 DeepSeek-R1-32B(BF16),单请求吞吐量达约 39.5 tokens/s,并发 100 时仍保持约 18.1 tokens/s,能够满足高并发场景(100 并发)。
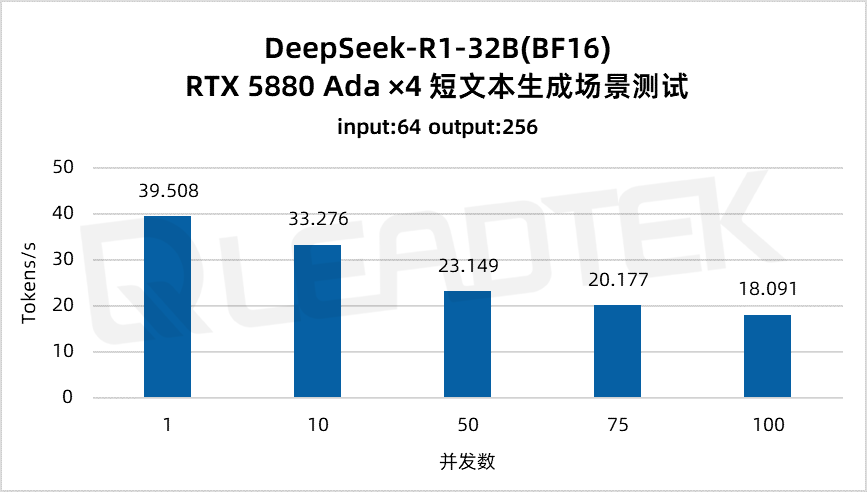
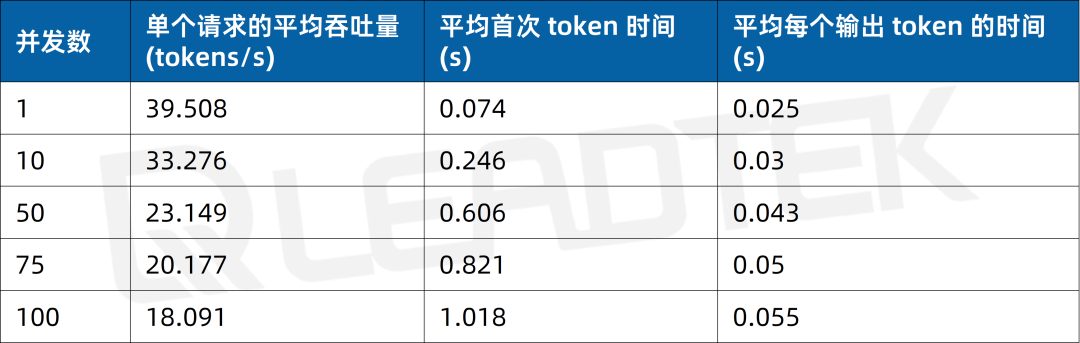
▲ DeepSeek-R1-32B(BF16) 测试结果图表
4.2 长文本生成场景
使用 DeepSeek-R1-70B(BF16),单请求吞吐量约 20 tokens/s,并发 100 时降至约 8.8 tokens/。最佳工作区间为低并发场景(1-50 并发)。
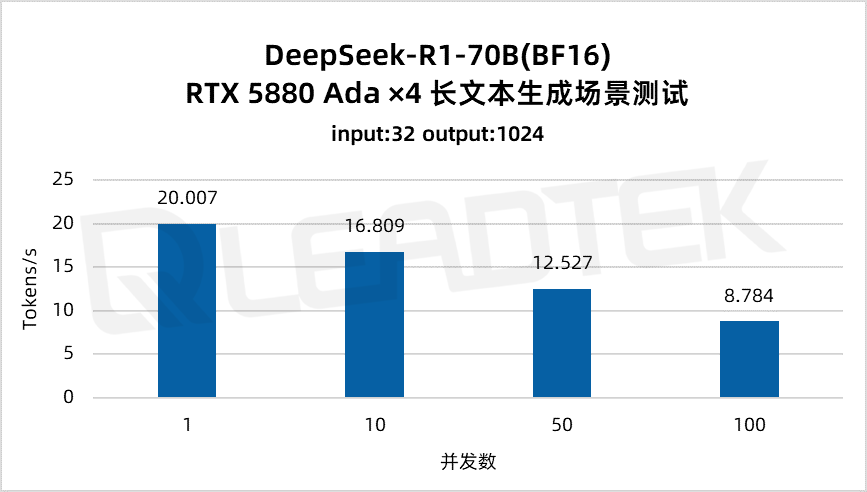
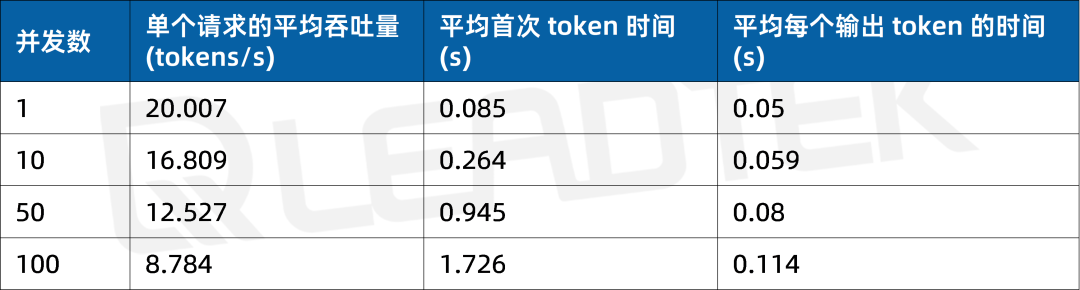
▲ DeepSeek-R1-70B(BF16) 测试结果图表
使用 DeepSeek-R1-32B(BF16),单请求吞吐量达约 39.7 tokens/s,并发 250 时仍保持约 10.6 tokens/s,能够满足较高并发场景(250 并发)。
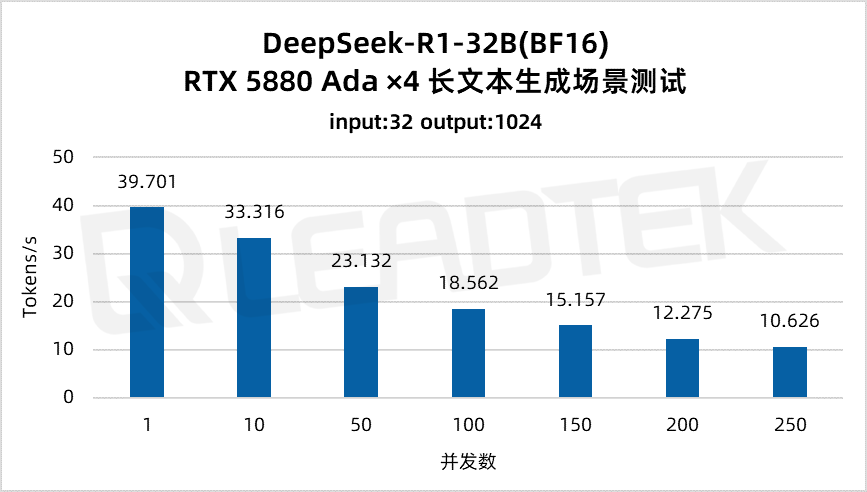
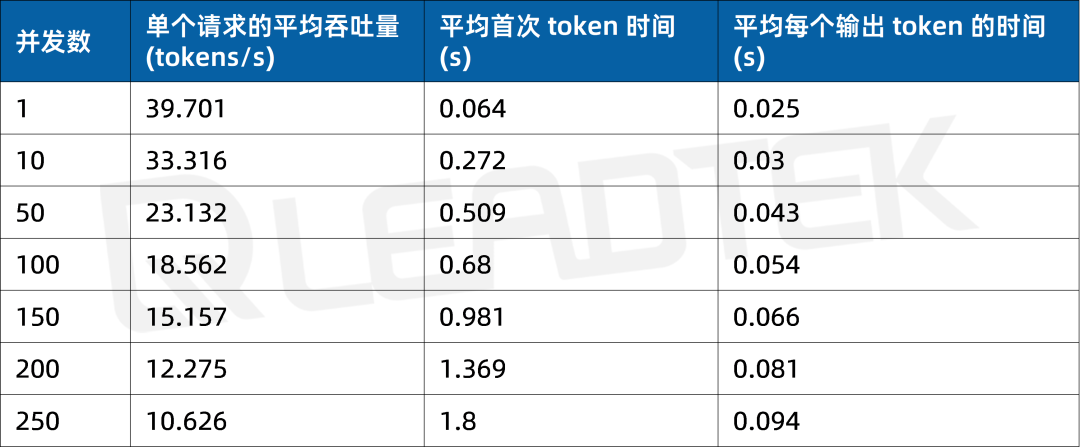
▲ DeepSeek-R1-32B(BF16) 测试结果图表
4.3 总结概括场景
使用 DeepSeek-R1-70B(BF16),单请求吞吐量约 18.7 tokens/s,并发 10 时降至约 10.9 tokens/。最佳工作区间为低并发场景(10 并发)。
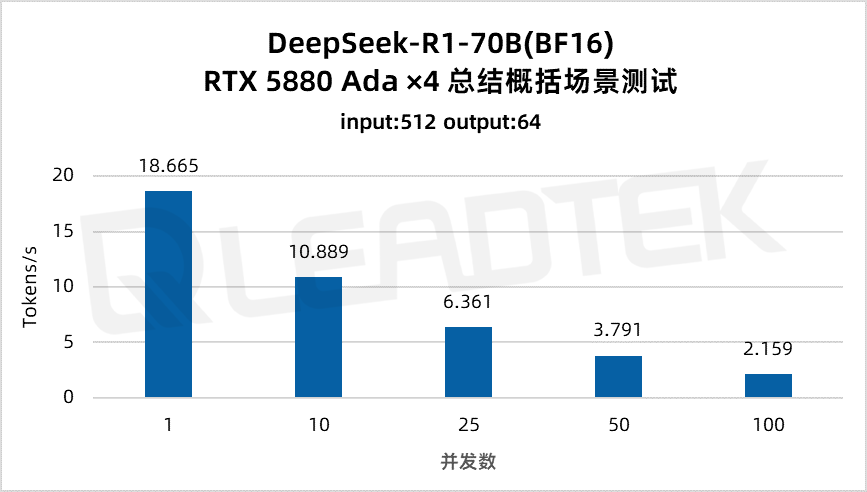
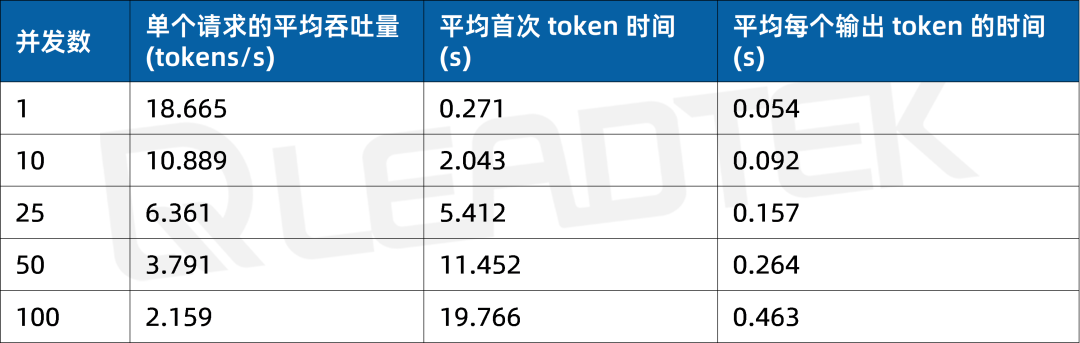
▲ DeepSeek-R1-70B(BF16) 测试结果图表
使用 DeepSeek-R1-32B(BF16),单请求吞吐量达约 37 tokens/s,并发 25 时仍保持约 15.3 tokens/s,能够满足中等并发场景(25 并发)。
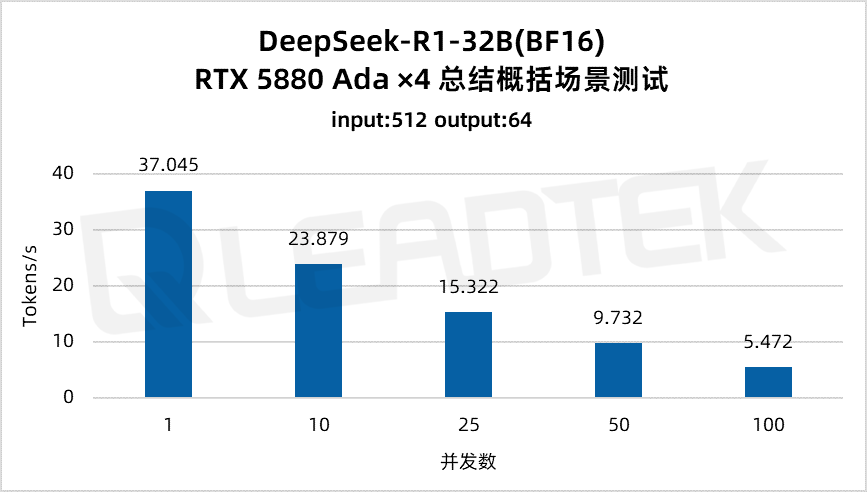
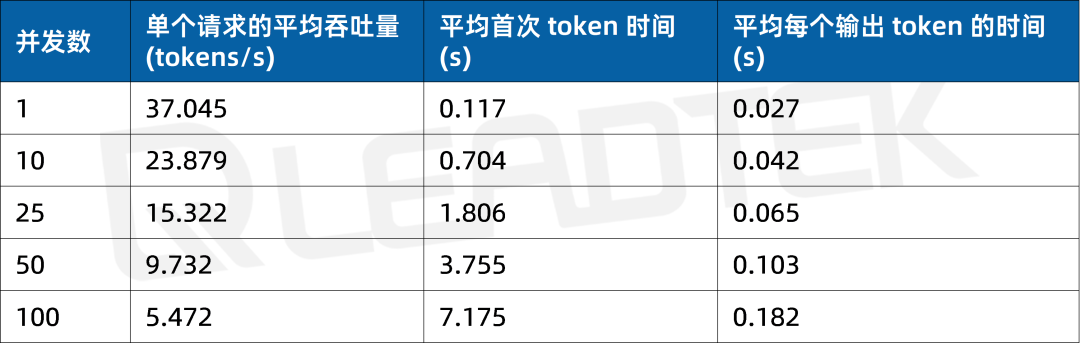
▲ DeepSeek-R1-32B(BF16) 测试结果图表
5 总结
5.1 测试模型性能
DeepSeek-R1-70B(BF16) 模型表现:
短文本生成:支持 75 并发量,单请求平均吞吐量>10.9 tokens/s
长文本生成:支持 50 并发量,单请求平均吞吐量>12.5 tokens/s
总结概括:支持 10 并发量,单请求平均吞吐量>10.9 tokens/s
DeepSeek-R1-32B(BF16) 模型表现:
短文本生成:支持 100 并发量,单请求平均吞吐量>18.1 tokens/s
长文本生成:支持 250 并发量,单请求平均吞吐量>10.6 tokens/s
总结概括:支持 25 并发量,单请求平均吞吐量>15.3 tokens/s
5.2 部署建议
基于 4 卡 RTX 5880 Ada GPU 的硬件配置下:
推荐优先部署 DeepSeek-R1-32B(BF16) 模型,其在高并发场景下展现出更优的吞吐性能与响应效率;
当业务场景对模型输出质量有更高要求,且系统并发压力较低时,建议选用 DeepSeek-R1-70B(BF16) 模型。
5.3 测试说明
本次基准测试在统一硬件环境下完成,未采用任何专项优化策略。
-
NVIDIA RTX 5880 Ada与Qwen3系列模型实测报告2025-05-09 4828
-
在英特尔哪吒开发套件上部署DeepSeek-R1的实现方式2025-03-12 1349
-
RK3588开发板上部署DeepSeek-R1大模型的完整指南2025-02-27 2135
-
行芯完成DeepSeek-R1大模型本地化部署2025-02-24 1523
-
宇芯基于T527成功部署DeepSeek-R12025-02-15 2140
-
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择2025-02-14 4034
-
超星未来惊蛰R1芯片适配DeepSeek-R1模型2025-02-13 1550
-
Deepseek R1大模型离线部署教程2025-02-12 3580
-
广和通支持DeepSeek-R1蒸馏模型2025-02-11 1278
-
deepin UOS AI接入DeepSeek-R1模型2025-02-08 2813
-
芯动力神速适配DeepSeek-R1大模型,AI芯片设计迈入“快车道”!2025-02-07 1227
-
RTX 5880 Ada Generation GPU与RTX™ A6000 GPU对比2024-04-19 6922
-
NVIDIA RTX 5000 Ada显卡性能实测报告2023-12-21 16336
全部0条评论

快来发表一下你的评论吧 !
