

TECS OpenStack资源池主机磁盘分区使用率过高的问题处理
描述
故障现象
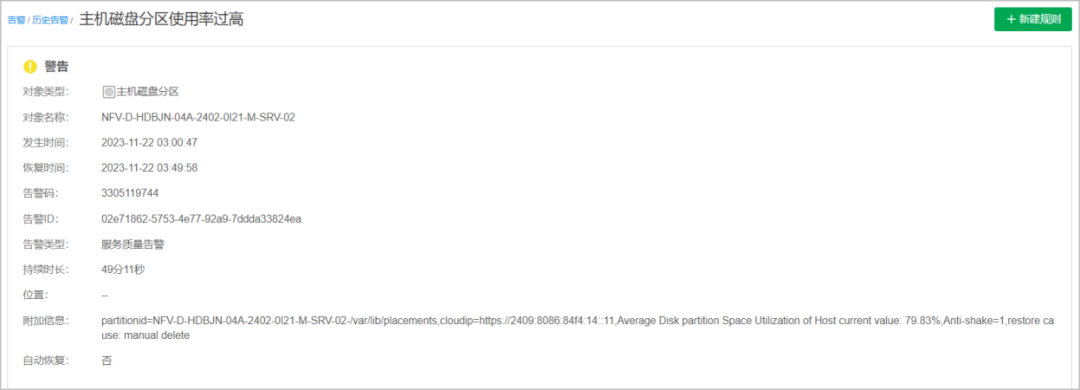
某运营商TECS资源池上报“主机磁盘分区使用率过高”的告警,如下图所示。
故障分析
查看“主机磁盘分区使用率过高”告警详情,通过处理当前告警的节点和对应的磁盘分区能够快速的处理和恢复告警。
告警处理完成后需要进一步排查分区增长的原因,有如下4种情况:
空间分配不足,规划的分区空间不满足现场集群和规模的要求。
出现大量crash和异常debug日志短时间冲击磁盘分区,可能是人为或者进程死循环导致。
日志文件或者定期轮询文件未生效,导致历史文件超限。
后端存储异常或者后端存储复用,导致磁盘使用率过高。
具体分析过程如下:
1. 根据告警详细信息,使用SSH方式登录相应节点。
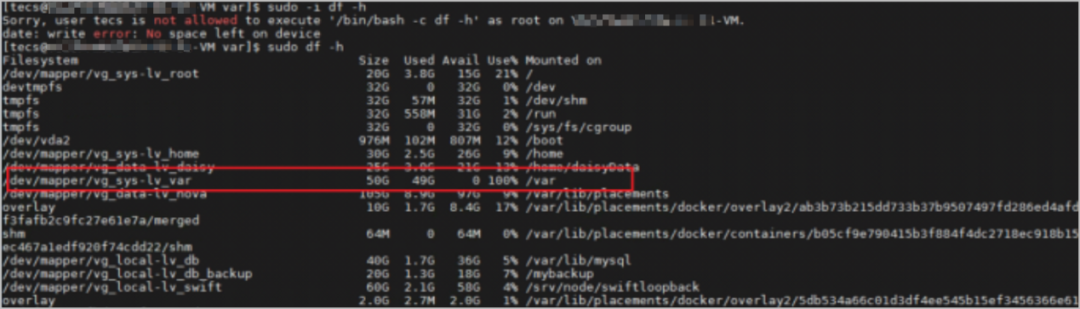
2. 在异常节点中执行df -h命令,检查输出和操作系统运行情况,查看是否有系统只读不可写等系统内核崩溃情况,如下图所示。
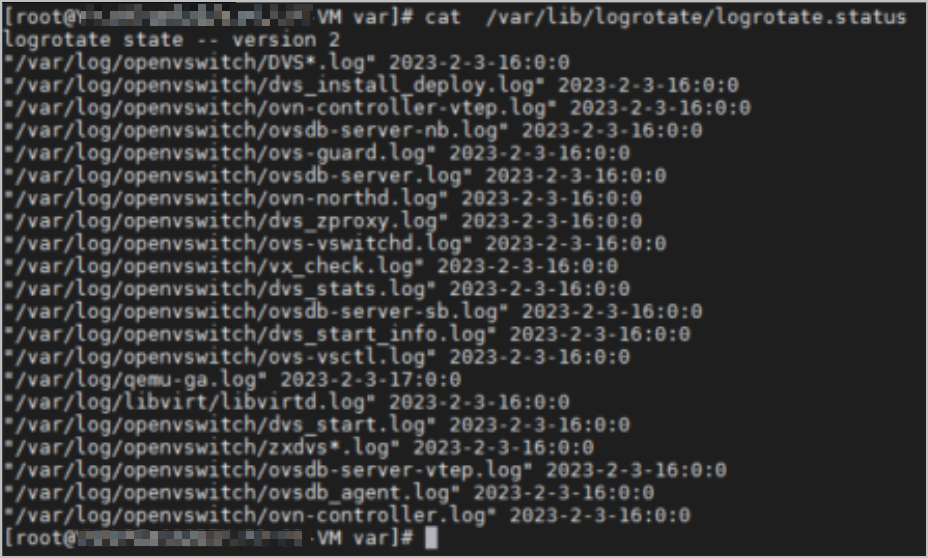
3. 检查/var目录下是否有过大问题。通过在每级目录中执行du -sh * 命令,检查文件大小,从而排查最大异常问题,按照经验var下异常大小文件一般是/var/log下的日志,如下图所示。
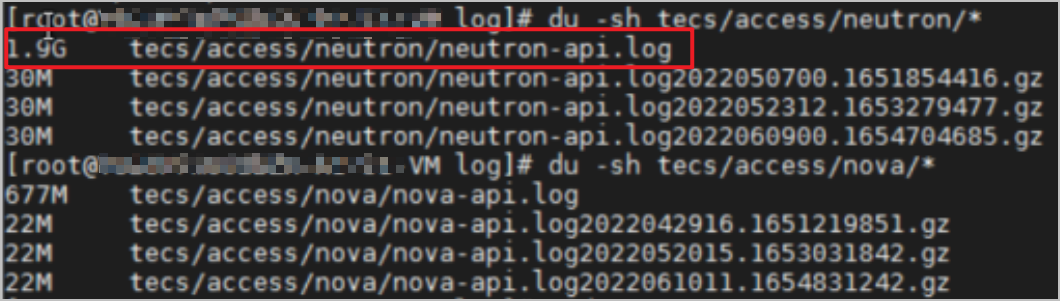
4. 检查日志存储文件大小,如下图所示。
5. 根据检查结果发现,logrotate机制未生效,日志文件未按照设定参数被压缩,转储不成功,导致日志文件过大,占用磁盘空间。
故障处理
1. 执行如下命令,清理磁盘。
a. 执行> /var/lib/logrotate/logrotate.status命令,清空转储记录。
b. 执行logrotate -d /etc/logrotate.conf命令,手动进行日志转储。
c. 执行echo > /var/log/tecs/access/neutron/neutron-api.log命令,写入空,覆盖到日志文件内,如下图所示。

2. 清理完成后重新检查文件大小和磁盘占用情况,问题解决。
3. 总结:对于磁盘分区使用率高问题,如果使用率达到100%就会导致节点不可用,系统自动备份失败,数据库定时备份失败,无法登录root用户,等相关问题,存在很大的隐患,发现问题需要尽快定位对象主机上磁盘占用高的文件,进行处理。
本次是由于logrotate机制未生效,日志文件未按照设定参数被压缩、转储,从而使日志文件不停增大,占用全部磁盘空间导致。
清理文件,触发转储服务后,磁盘占用恢复正常。
建议定期检查系统磁盘空间占用,预防此类事件发生。
-
Linux系统中磁盘分区与挂载详解2025-06-17 2929
-
TECS OpenStack资源池虚拟机网络二层地址无法互通的问题处理2025-06-12 1146
-
TECS OpenStack资源池虚机写磁盘时延高告警的问题处理2025-03-21 1276
-
TECS OpenStack资源池虚机残留导致网元异常的问题处理2025-03-03 1079
-
linux系统如何进行磁盘分区?2023-12-19 2313
-
获取磁盘分区UUID的方法介绍2023-01-31 14658
-
预装Win7系统划分更多的磁盘分区的方法2020-07-08 1342
-
cpu使用率过高怎么解决_cpu使用率过高是什么原因2020-04-29 2156
-
微软Win10搜索磁盘和CPU使用率过高的问题修复2020-03-26 4156
-
微软Windows 10研究新的方法管理现代磁盘分区2020-03-19 2946
-
Windows 10 2004版或解决CPU和磁盘使用率过高的问题2020-01-06 3762
-
linux的三种磁盘分区2019-07-12 1419
-
Linux系统教程之磁盘分区和LVM系统的详细资料概述2018-10-30 1301
-
【雨林木风系统下载教程】利用XP系统磁盘分区来提升读写...2013-07-19 3368
全部0条评论

快来发表一下你的评论吧 !
