

十种典型的数据结构及其特性
电子说
描述
数据结构是软件开发的关键部分,也是开发人员面试经常遇到的问题,它们通常以专用的格式进行数据组织和存储。本文我们将会介绍十种典型的数据结构及其特性。需要注意的是,虽然一些数据结构包含了时间复杂度O,但不完全都有因为时间复杂度很多时候与你的代码书写有关。实际使用时,大多数的数学结构都不需要你自己实现它们,除非像C语言这样的底层语言。虽然大多数高级语言一般都会内置这些数据结构,但如果你知道如何实现这些数据结构将会为你在开发工作中带来巨大优势,说不定当你尝试编写高性能代码时就会派上用场。
1. 链表
链表属于最基本的数据结构。由于许多数据结构既可以用数组也可以用链表来实现,所以通常会与数组进行比较,但它们各有优缺点。
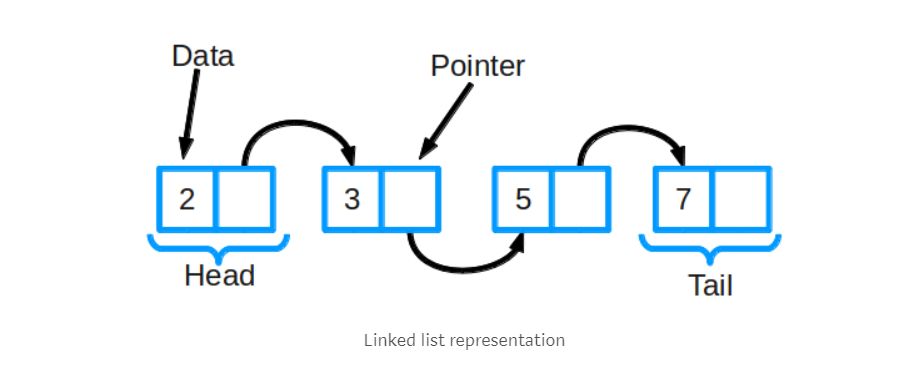
链表通常由一组代表一个序列的节点组成。 每个节点包含存储的任意类型实际数据以及指向序列中下一个节点的指针。特殊的,还有双向链表,其中每个节点都有两个指针,分别起到承前启后的作用。
链表中最基本的操作是插入链表、删除链表以及查询链表。下表为链表的时间复杂度:

2. 堆栈
堆栈属于一种基本的数据结构,你只能在堆栈的顶部插入或删除项目。这有点像一堆书, 如果你想看堆栈中间的一本书,你必须先将它上面上面的所有书移走。
堆栈遵循后进先出,也就是说你最后放入堆栈的项目是第一个出栈的项目。
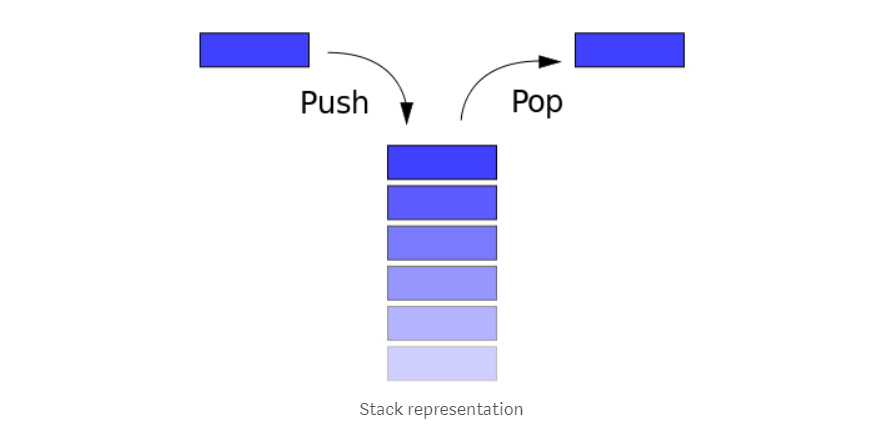
对堆栈主要有三种操作:push,即插入新内容到堆栈;pop,从堆栈中删除一项内容;pip,显示堆栈的内容。
堆栈时间复杂度:

3. 队列
你可以把队列想象成一家杂货店里排队买单的人,队伍中第一个人先被服务。
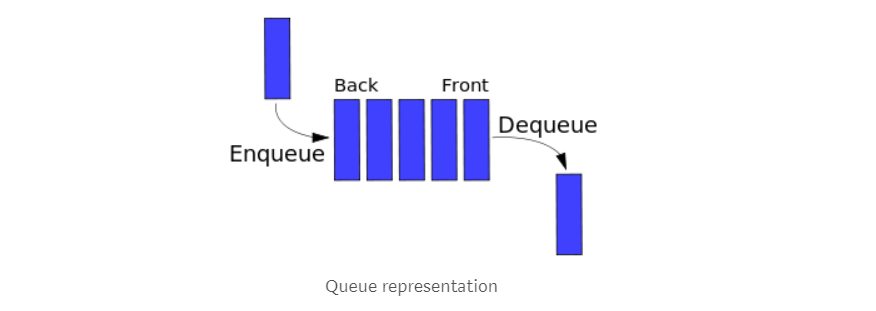
队列遵循先进先出,也就是说一旦你想添加了新元素,你要想删除它,必须先删除它前面的的所有元素。队列只有两个主要操作:入队和出队。 入队,就是将新的内容插入队列后面,而出队就是前面所有的内容。
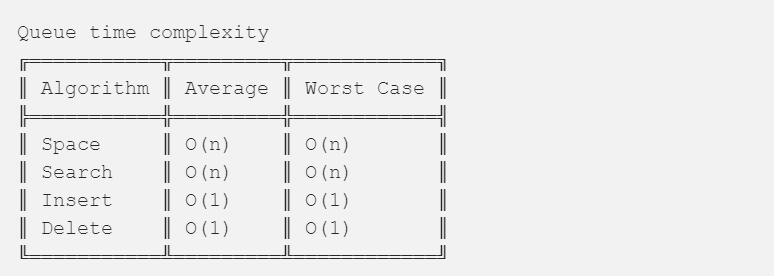
队列时间复杂度:
4. 集合
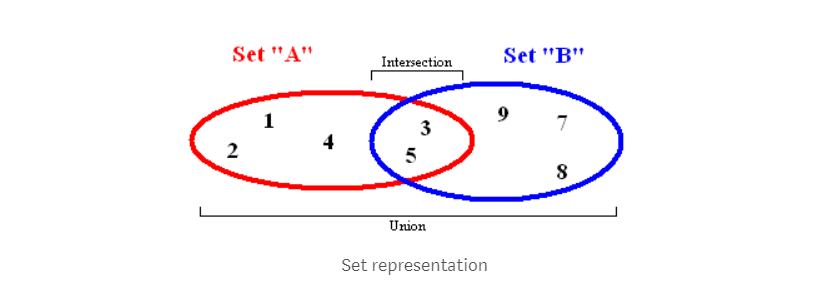
以集合形式存储的数据结构中不存在任何特定的顺序,也不存在重复的值。除了向集合中添加新元素或者删除元素之外,还有一些重要的集合函数可以进行两组集合的处理。
并集,将来自两个不同集合的所有元素结合起来作为新集合返回(不重复).
交集,给定两个集合,此函数返回另一个集合,包含属于两个集合的共同部分。
差集,给定两个集合,此函数返回另一个集合,其中各个元素属于一个集合,但不属于另一个集合。
子集 ,返回一个布尔值,显示一个集合中的所有元素是否包含在不同的集合中。
5. MAP
Map是容器的一种,也属于一种数据结构,它将数据存储在键/值对中,且每个键是唯一的。 map有时也称为关联数组或字典,通常被用于快速查找数据。 Map可以进行以下操作:
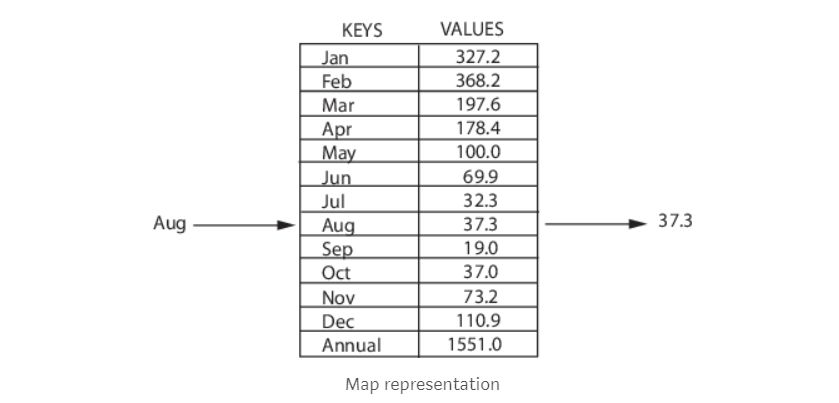
在集合中增加一对
从集合中删除一对
修改现有的一对
查找与特定键相关联的值
6. 哈希表

哈希表是包含键/值对的地图数据结构,使用散列函数来把关键码值映射到表中一个位置来访问记录,以加快查找的速度。散列函数通常将一个字符串作为输入,并输出一个数值。散列函数对相同的输入提供相同的输出编号。 当两个输入哈希得到相同的数字输出时,称为碰撞。
我们的目标是没有碰撞。所以当你将一个键/值对输入到一个散列表中时,这个键将通过散列函数映射到一个数字,用作值存储的实际键。 当你尝试再次访问相同的密钥时,哈希函数将处理该密钥并返回相同的数字结果,用于查找关联的值。 算法速度非常快,查找的时间复杂度仅为O(1)。
Hash table 时间复杂度:

7. 二叉搜索树
树是由节点组成的数据结构,它具有以下特征:
每棵树都有一个根节点(位于顶部)。
根节点具有零个或多个子节点。
每个子节点都有零个或多个子节点。
二叉搜索树还具有额外的两个特征:
每个节点最多有两个子节点.
对于每个节点,它左边的子节点小于当前节点,而右边的子节点则大于当前节点。
每个节点最多有两个子节点。
二叉搜索树允许快速查找、添加和删除内容。 从它的设计结构来看,每次比较后都会跳过树的大约一半内容,因此每次查找、插入或删除需要的操作时间与存储在树中的内容数量的对数成比例。
二叉树时间复杂度:

8. 前缀树或字典树
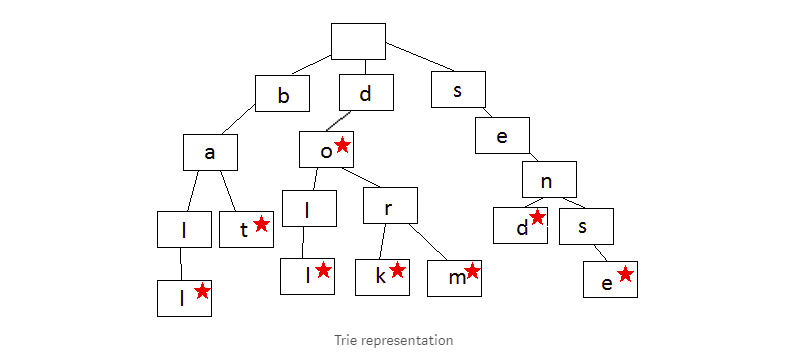
前缀树或字典树,是一种搜索树。 前缀树中存储数据的每个步骤其实就是操作一个节点,它通常被用来存储单词,可以进行快速查找,例如单词自动构成功能。
语言字典树中的每个节点都包含一个单词的一个字母。 你可以按照树状结构的一条分支拼写出一个单词。 当字母的顺序与字典中的其他单词不同或者一个单词完成时,开始分支。每个节点都包含一个字母(数据)和一个布尔值(用于指示该节点是否是单词中的最后一个节点)。
看看上面的图像,你可以构成很多单词。从顶部的根节点开始并往下,这个字典树包含了ball, bat, doll, do, dork, dorm, send, sense这些单词。
9. 二叉堆
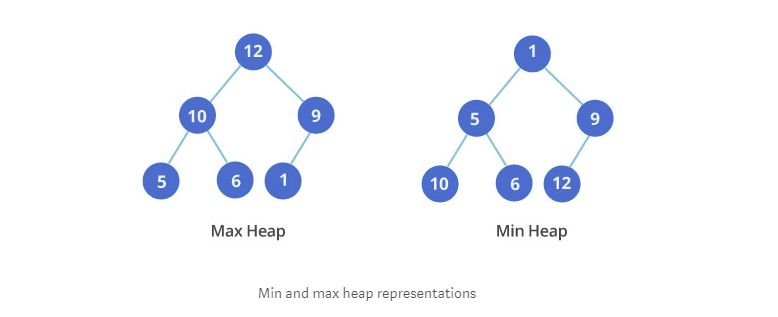
二叉堆是特殊的树数据结构。形式上看,它从顶点开始,每个节点有两个子节点,每个子节点又各自有自己的两个子节点;数值上看,每个节点的两个子节点都比它大或小。
二叉堆有两种:最大堆和最小堆。最大堆:父结点的键值总是大于或等于任何一个子节点的键值;最小堆:父结点的键值总是小于或等于任何一个子节点的键值。
在二叉堆上可以进行插入节点、删除节点、取出值最小的节点、减小节点的值等基本操作。不同层之间的顺序很重要,但同一层上节点的顺序无关紧要。 如图所示,你可以看到最小堆的第三层的值是10,6和12,这些数字并不是按照顺序排列的。
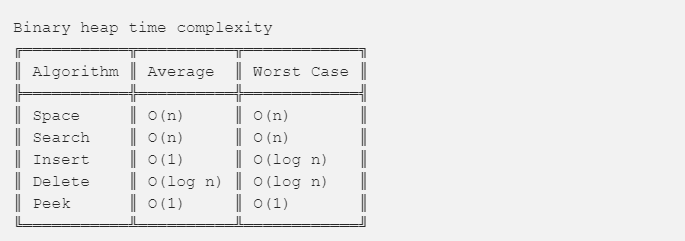
二叉堆时间复杂度:
10. 图
图是由节点(也称为顶点)与它们之间的连接(称为边)构成的集合。图也被称为网络。
社交网络是典型的图的例子,节点是人,边代表他们互相认识的关系。
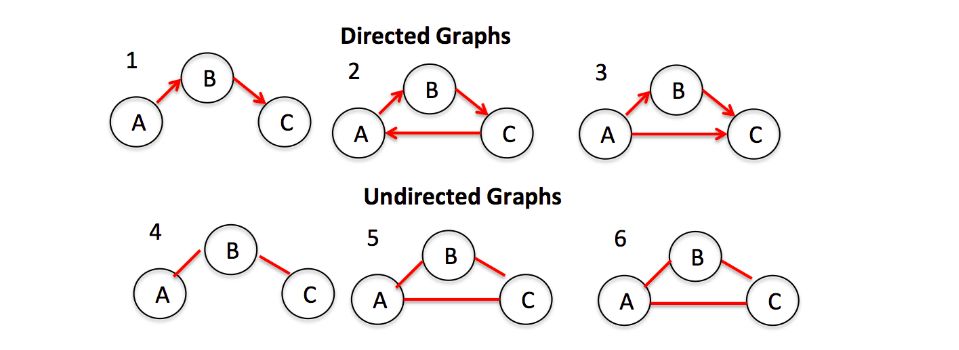
主要有两种类型的图:有向和无向。无向图是指在节点之间的边上没有任何方向的图。相反,有向图表示每条边上都有方向的图。
表示图的两种常用方式是邻接表和邻接矩阵:
邻接列表,表示一个列表的左侧是节点,右侧列出了它所连接的所有其他节点。
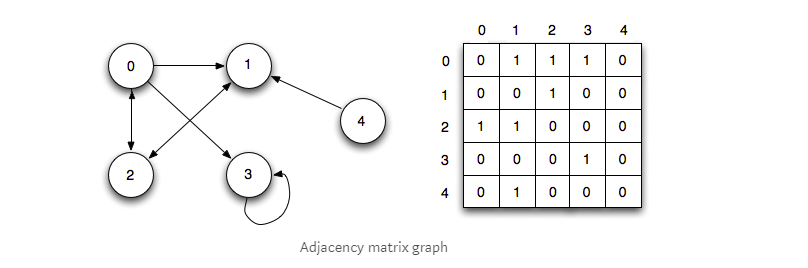
邻接矩阵,则是一个数字网格。其中每个行或列表示图中的不同节点。每一行和一列的交点是一个表示关系的数字。0表示没有边或没有关系,1表示有一种关系,而大于1的数字则可表示不同的权重。
通过遍历算法可以遍历或访问图中的节点。遍历算法的主要类型有广度优先搜索和深度优先搜索,可以被用于确定节点与根节点的接近程度。观看下面的视频你可以学习到如何在JavaScript中实现广度优先搜索。
邻接列表的时间复杂度:

-
十种主流电机拆解全解析:内部结构大揭秘!2025-04-01 286
-
十种精密全波整流电路原图分享2023-11-27 892
-
NetApp的数据结构是如何演变的2023-08-25 462
-
快速介绍8种常用数据结构2023-06-21 1248
-
十种pandas数据编码的方法分享2022-05-10 1827
-
什么是数据结构?为什么要学习数据结构?数据结构的应用实例分析2018-09-26 1477
-
请问怎么做一个跑马灯有十种模式,第十种模式有三种音乐,可加速减速和无线遥控?2018-07-19 2592
-
数据结构是什么_数据结构有什么用2017-11-17 16576
-
数据结构2017-03-04 3296
-
十种方法能保护云数据安全2017-01-14 765
-
几十种典型测控电路图全解2016-10-10 14596
-
GPIB命令的数据结构2010-02-10 847
-
什么是数据结构(Data Structrue)2010-02-09 2997
-
数据结构教程,下载2009-05-14 662
全部0条评论

快来发表一下你的评论吧 !
