

4台树莓派5跑动大模型!DeepSeek R1分布式实战!
描述
导语
“用4台树莓派5组网,轻松运行大模型——这可能是2025年最颠覆认知的开源AI项目!” GitHub明星项目distributed-llama最新实战案例曝光:通过独创的动态模型切片技术,成功在4台树莓派5(8GB内存)上运行DeepSeek R1 Distill 8B模型,推理速度达6.43 tokens/s,功耗仅20W!本文将深入解析: 树莓派集群的核心技术架构 | 零门槛部署全流程 | 社区实测性能报告 文末附树莓派专用配置模板,让旧设备秒变AI算力节点!
项目背景
distributed-llama 是由开发者 Bartłomiej Tadych 发起的一项开源倡议,旨在通过分布式计算技术,将家庭闲置设备(如树莓派、旧笔记本、手机等)转化为高效的 AI 推理集群,从而大幅降低运行百亿参数大模型的门槛。
为何需要分布式LLM?
传统的大语言模型(如Llama、DeepSeek)推理严重依赖高端显卡(如NVIDIA A100/H100),硬件成本高昂且能效比低下。而分布式LLM通过 动态模型切片 和 跨设备协同计算,将单一设备的算力需求分散到多台设备,实现:
低成本:利用闲置设备的算力“边角料”替代昂贵显卡
高扩展性:通过增加节点数量线性提升推理速度
跨平台兼容:支持从树莓派(ARM)到旧x86设备的混合组网
核心突破
项目自2024年发布以来,通过 Tensor并行架构 和 Q80浮点压缩技术,成功将多个开源大模型部署到树莓派5,MAC电脑,PC组成的集群中。
技术解析
1.动态模型切片
自动负载均衡:根据设备数量(需满足2^n)将模型拆分为独立计算单元
树莓派专属优化:针对ARM架构优化算子,CPU利用率提升40%
内存压缩技术:Q80浮点格式使单节点内存占用降低至2.4GB(原模型6.32GB)
2.高效通信协议
低延迟同步:千兆以太网下KV Cache同步延迟<60ms
容错机制:任意节点掉线自动触发计算任务重分配
3.散热方案:
加装Pi5散热风扇(树莓派5满负载温度可降低15℃)

项目展示
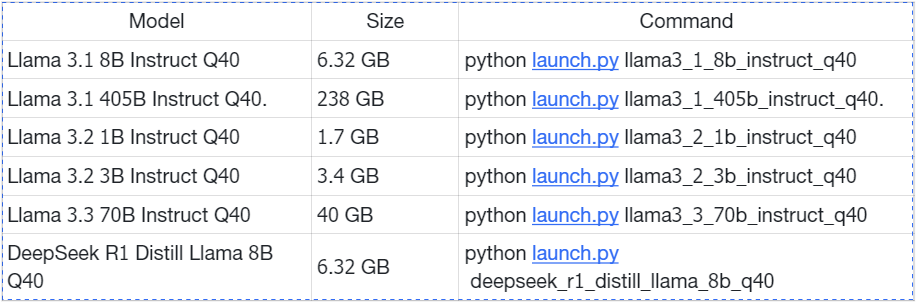
Model: deepseek_r1_distill_llama_8b_q40
Version: 0.12.2
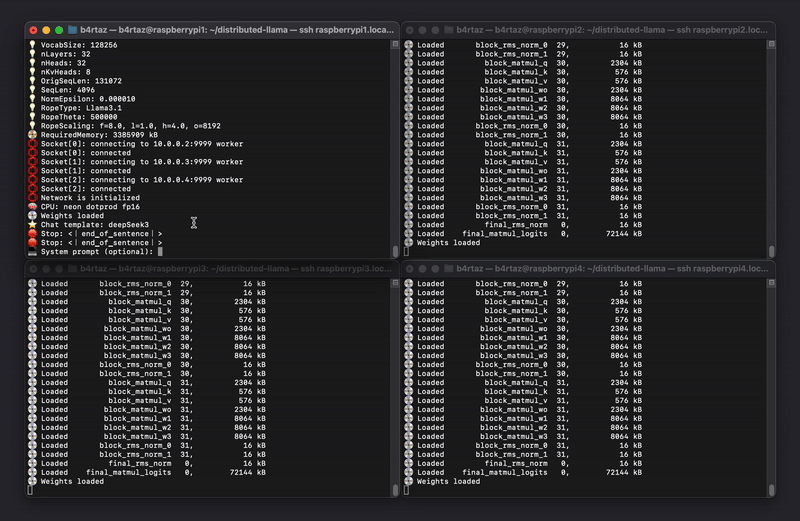
2 x Raspberry Pi 5 8GB
... P 278 ms S 288 kB R 522 kB First P 258 ms S 288 kB R 522 kB , P 323 ms S 288 kB R 522 kB I P 275 ms S 288 kB R 522 kB need P 293 ms S 288 kB R 522 kB to P 269 ms S 288 kB R 522 kB understand P 281 ms S 288 kB R 522 kB whatEvaluation nBatches: 32 nTokens: 19 tokens/s: 7.70 (129.89 ms/tok)Prediction nTokens: 77 tokens/s: 3.54 (282.22 ms/tok) Network is closed
4 x Raspberry Pi 5 8GB
... P 162 ms S 864 kB R 1191 kB The P 160 ms S 864 kB R 1191 kB Multi P 157 ms S 864 kB R 1191 kB - P 176 ms S 864 kB R 1191 kB Device P 130 ms S 864 kB R 1191 kB In P 174 ms S 864 kB R 1191 kB ference P 132 ms S 864 kB R 1191 kB Cluster P 172 ms S 864 kB R 1191 kB ( P 139 ms S 864 kB R 1191 kB MD P 184 ms S 864 kB R 1191 kB IC P 162 ms S 864 kB R 1191 kB ) P 156 ms S 864 kB R 1191 kB isEvaluation nBatches: 32 nTokens: 19 tokens/s: 11.68 (85.63 ms/tok)Prediction nTokens: 77 tokens/s: 6.43 (155.60 ms/tok) Network is closed
结语
“当树莓派集群遇见分布式AI,算力民主化的大门正在打开!”在评论区参与讨论,看看你对分布式计算的想法吧。
-
DeepSeek开源新版R1 媲美OpenAI o32025-05-29 1787
-
瑞萨RZ/V2H平台支持部署离线版DeepSeek -R1大语言模型2025-05-13 2028
-
ORinNano离线部署Deepseek R1大模型教程2025-04-10 1688
-
RK3588开发板上部署DeepSeek-R1大模型的完整指南2025-02-27 2136
-
OpenAI O3与DeepSeek R1:推理模型性能深度分析2025-02-18 1805
-
了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择2025-02-14 4034
-
超星未来惊蛰R1芯片适配DeepSeek-R1模型2025-02-13 1550
-
Deepseek R1大模型离线部署教程2025-02-12 3583
-
扣子平台支持DeepSeek R1与V3模型2025-02-08 2355
-
云天励飞上线DeepSeek R1系列模型2025-02-06 1678
-
树莓派带你掌握嵌入式linux产品实战开发2021-11-05 1343
-
CMD244K5分布式放大器2020-02-13 2012
-
树莓派(Raspberry Pi)实战指南.pdf2018-05-07 3606
-
香蕉派 BPI-M1,R12015-02-11 4662
全部0条评论

快来发表一下你的评论吧 !
