

恩智浦eIQ Time Series Studio工具使用教程之模型训练
描述
大家好,eIQ Time SeriesStudio又和大家见面啦!本章为大家带来工具核心部分-模型训练。
Training模块,用于Dataset模块加载数据集后的模型训练。Training功能是核心技术,包括数据预处理、算法超参数自动化搜索、基准测试以及针对有限的Flash和RAM大小进行最佳精度拟合优化。模型性能也可以通过各种基准指标进行评估。
功能布局
下图显示了“Training”模块的布局,分为三个部分:
左侧框架显示了训练的所有记录
中间的框架显示了训练的配置信息和优化过程
右侧框架显示了指定模型的验证集的基准结果
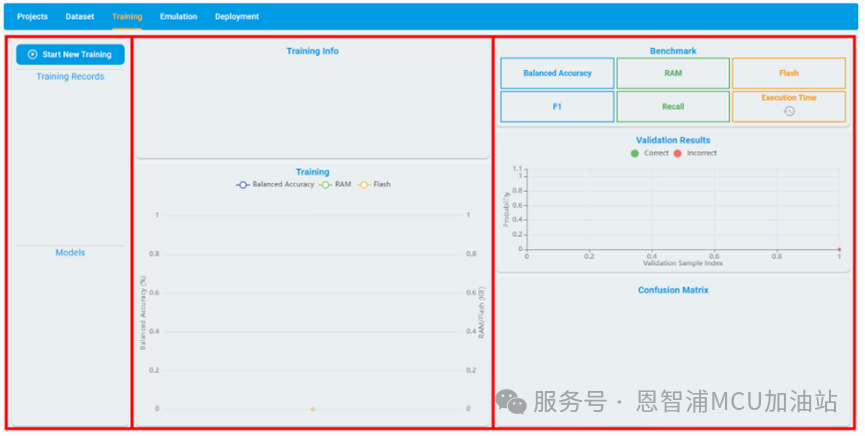
左侧框包含两部分:Training Records和Models。
Training Records:记录了用户创建的所有训练任务。
Models:记录了特定训练任务生成的算法模型;默认情况下,模型按得分降序排列。得分取决于 RAM/Flash 占用大小以及基准测试的一些常见评估指标。
中间框包含两部分:Training Info和Training。
Training Info:记录了训练的时间、进度和配置信息,包括日期、最大 RAM、最大 Flash、是否使用快速搜索、on-Device learn(仅用于异常检测)、训练/验证集比例和训练所用的数据文件。
Training:记录了自动机器学习的平衡准确率、Flash 和 RAM 使用的变化曲线。
右侧框架中的信息因不同的任务类型而异,将在后续内容中详细介绍(基准信息)。
训练过程
介绍如何开始、暂停、停止和管理训练。
点击“Start New Training”按钮,会出现一个弹框供用户配置。在点击“Start”按钮之前,请检查针对不同算法任务可配置的选项。通常,用户可以在不更改配置的情况下进行训练并获得最佳结果。
配置选项
异常检测的配置选项如下。异常检测算法基于半监督机器学习,它支持在设备上进行增量学习。
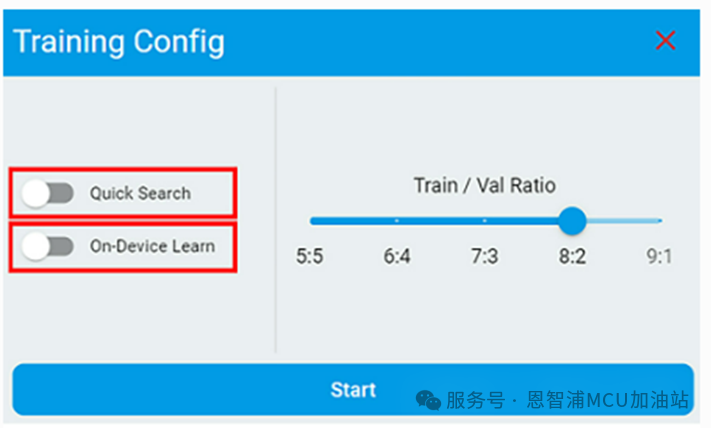
如果算法仅用于预测,请不要使能“On-Device Learn”这将会导致更大的 RAM/Flash占用
如果使用的数据集存在变化,可以启用“On-Device Learn”以允许在设备上进行训练
如果想快速获得训练结果,请启用“Quick Search”。此模式的搜索范围不如默认模式大
以下是分类和回归的配置选项:
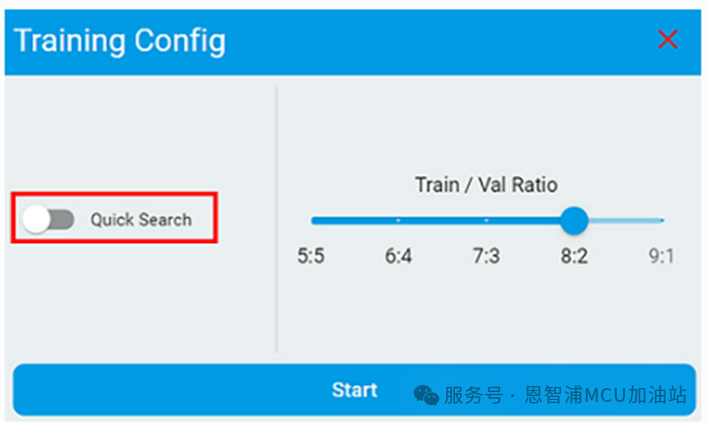
共同的选项:
配置Train/Val Ratio,如果train/emulation准确率不匹配或超出范围,则调整数据文件中训练集和验证集的比例并再次训练和仿真。
训练配置完成或设置为默认值后,单击“Start”按钮开始训练,等待训练完成。
完成培训的时间取决于:
数据集的大小
选择了什么样的算法任务
不同的训练配置也可能导致不同的时间开销
训练开始时,训练进度条会不断更新,计时器会一直计时,直到100%完成。
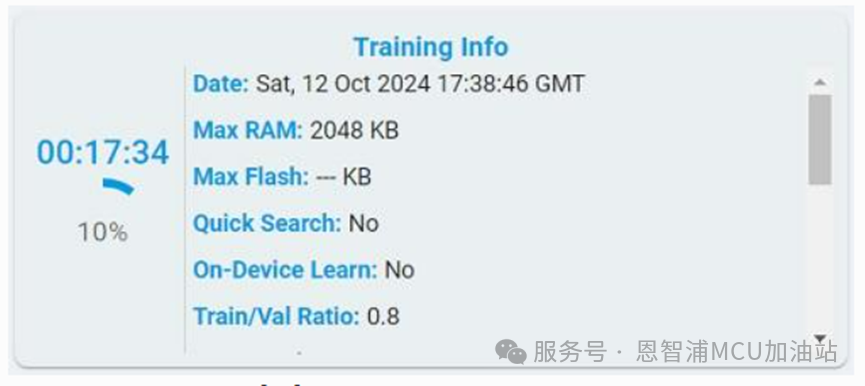
暂停/停止训练 在训练过程中,可以选择点击“Stop”按钮停止训练或点击“Pause”按钮暂停训练,左侧模型列表中存在的算法,可以被使用。
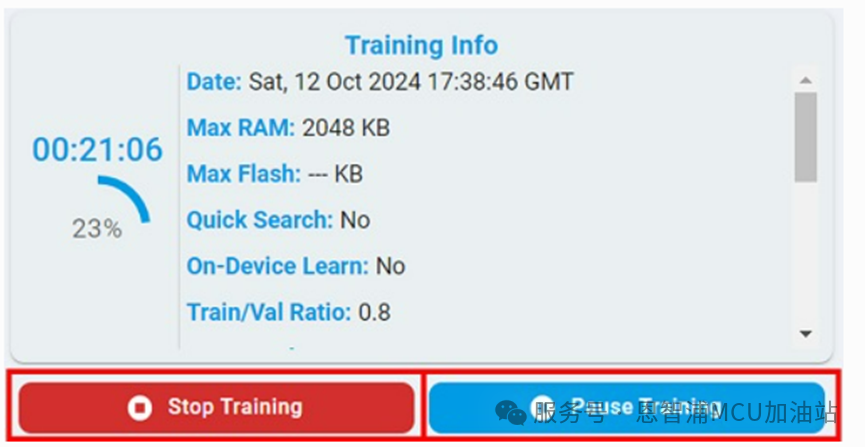
暂停后,可以在左侧模型列表中查看任意模型的训练结果,或者点击“Resume”按钮继续训练。
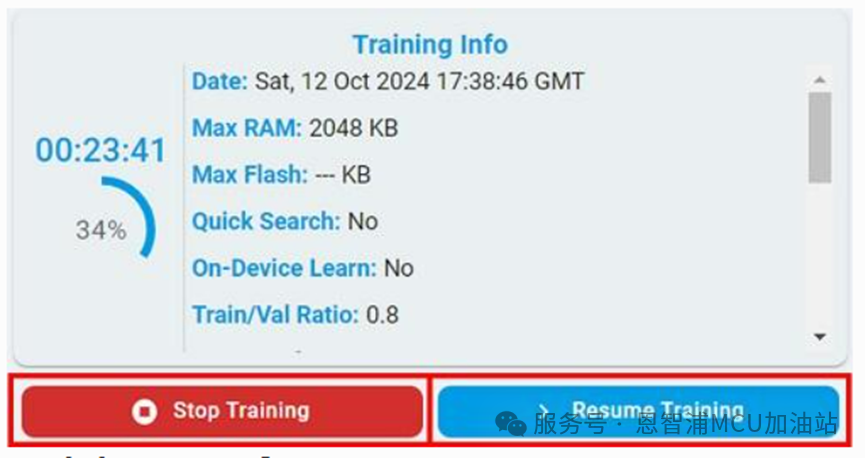
训练记录管理
任务完成后,此次的训练信息将被记录到训练记录中,训练出的算法模型将会按照性能排序出现在模型列表中。
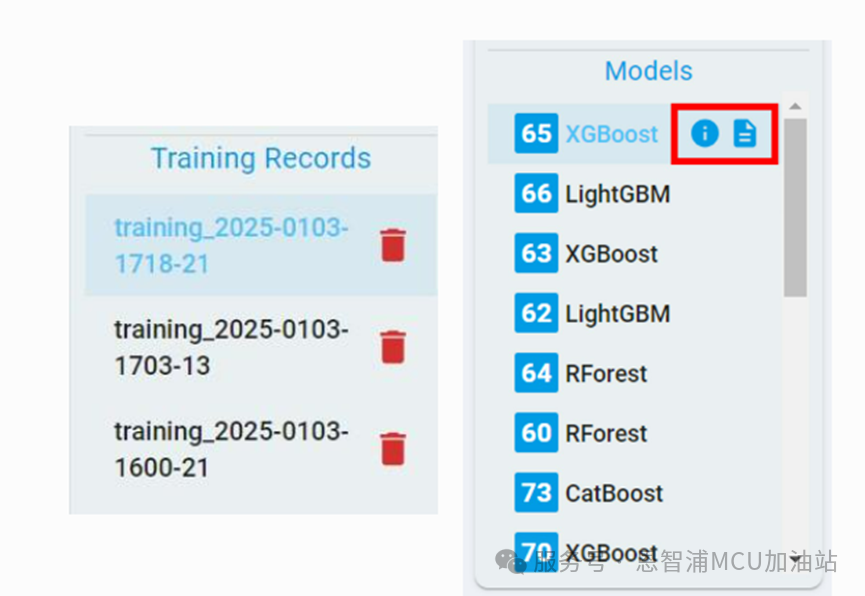
点击“flowchart”和“report”按钮,查看或下载相应模型的流程图和报告,以供进一步参考。
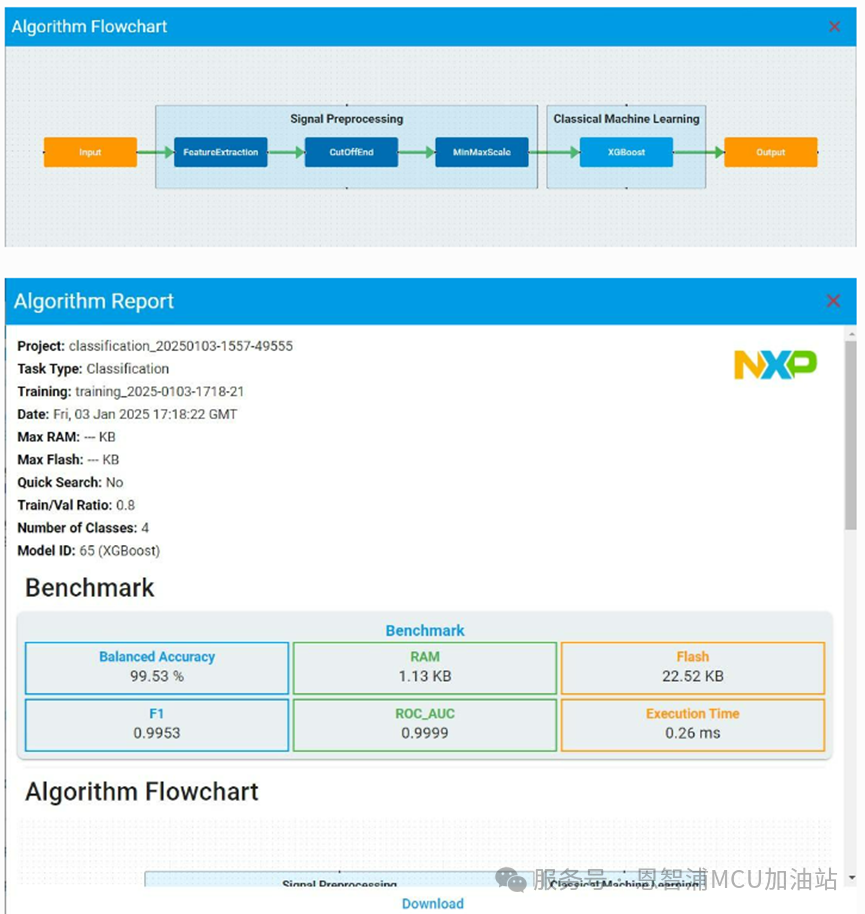
从列表中选择任意算法并点击,可获取如下基准详细信息。在训练图中,紫色箭头坐标指示当前选定的算法模型,用户可以查看自动机器学习训练曲线以及每个模型对应的平衡准确率、Flash和RAM使用情况。
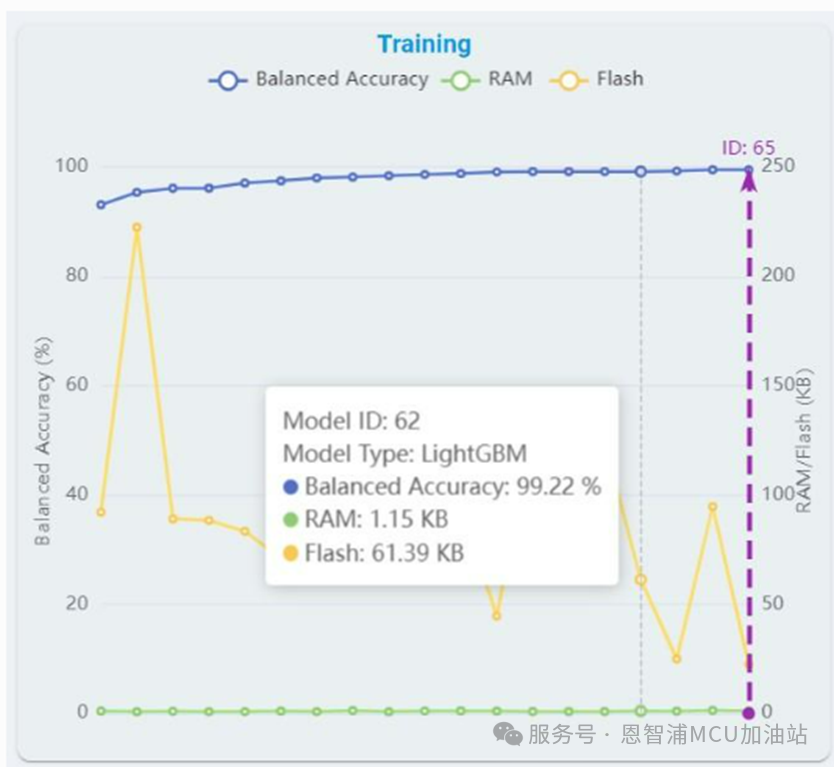
另外,可以点击“Delete”按钮删除相应的训练记录,删除后该训练记录下的所有模型信息也会同时被删除。
模型列表与代码许可
为了满足用户对算法透明度的要求,我们会根据发布版本保持所有支持模型的列表更新:
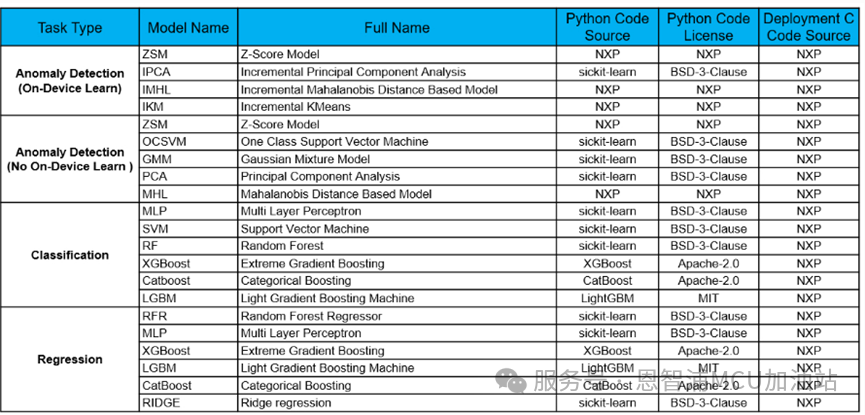
该表格重点展示了以下信息:
每项任务对应的模型
用于训练的Python代码源
Python代码的许可证类型
C代码来源
基准信息
支持时间序列的数据集的算法有三类,分别是异常检测、分类和回归。基准信息因算法类型的不同而不同。
异常检测基准信息

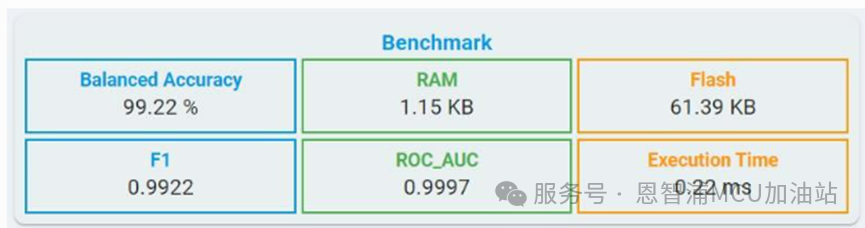
Balanced Accuracy: 从类别中获得平衡准确率。
F1: F1分数是反映分类器全局性能的指标,其值范围为0到1。
Recall:召回率是分类器找出所有正样本的能力,值的范围是0~1。
Flash:所选算法所需的最小Flash。
RAM: 所选算法所需的最小RAM.
Execution Time: 基于LPC55S36(Cortex-M33,150 MHz,启用硬浮点)平台进行一次推理的估计时间,同时您可以通过点击时钟按钮来获取执行时间。
将鼠标悬浮在指标上,可查看它的解释说明和对应的计算公式。
验证集结果分析:
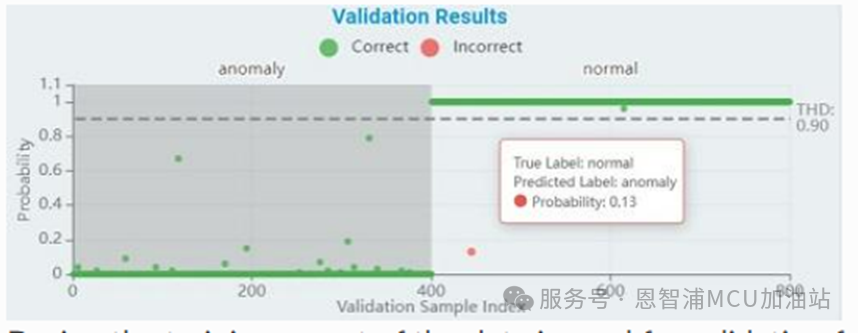
在训练过程中,部分数据会不时用于验证。训练曲线反映了这些结果,并作为准确性指标来衡量模型的性能。
x 轴表示验证样本的索引(对于异常检测,所有样本都用于验证,而分类则根据训练/验证比例来验证)
y 轴表示概率,其值标准化为0到1之间
绿点表示预测正确的样本点,红色表示预测异常的样本点
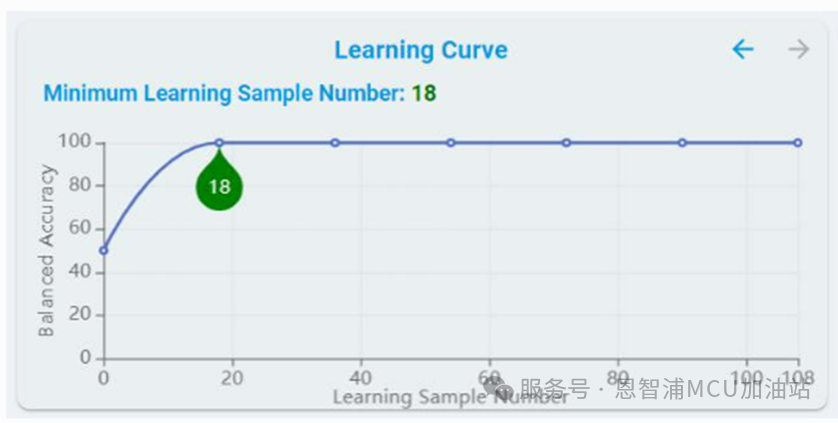
学习曲线:
对于支持“On-DeviceLearn”的模型,提供了学习曲线,展示了在训练过程中添加更多样本的效果。
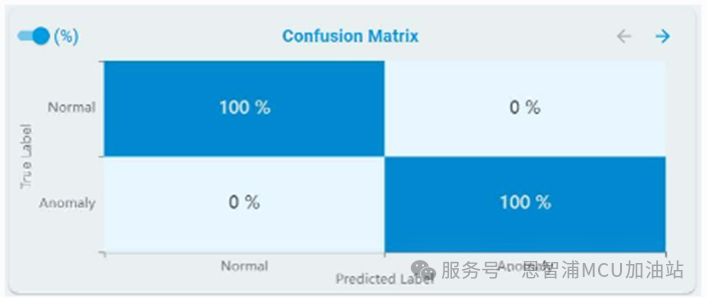
混淆矩阵:
对于异常检测,混淆矩阵表包含正常和异常结果:

同时,您可以通过点击百分比(%)按钮来获取百分比结果:
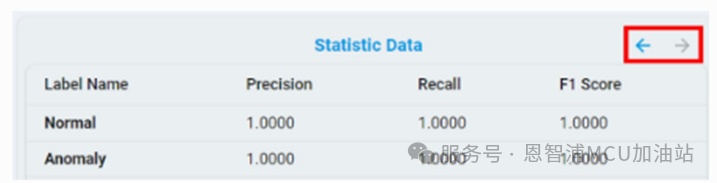
也可以通过点击箭头按钮来查看统计结果:
分类算法基准信息 对于分类任务,一些评估指标与异常检测一致,例如平衡准确率、RAM、Flash和F1。
混淆矩阵:
对于分类,混淆矩阵表重新缩放以适应所有类别,如下图所示:

回归算法基准信息
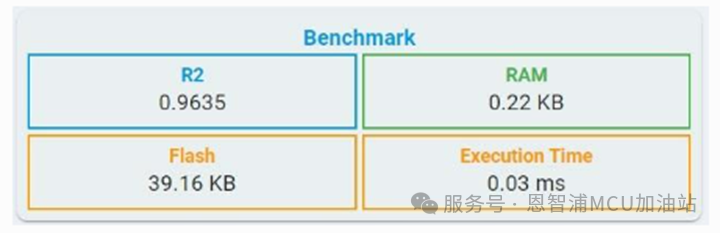
R2: 决定系数:
其公式可在回归仿真指标部分找到。
算法验证结果:
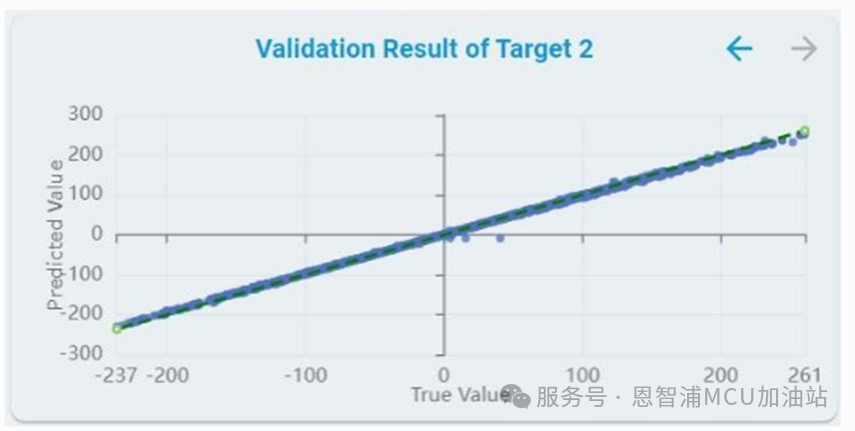
对每个target,都绘制了验证集的预测目标值。
x轴表示验证样本的索引。训练/验证比例决定了用于验证的样本数量
y轴表示预测值
虚线表示真实值
评估指标:
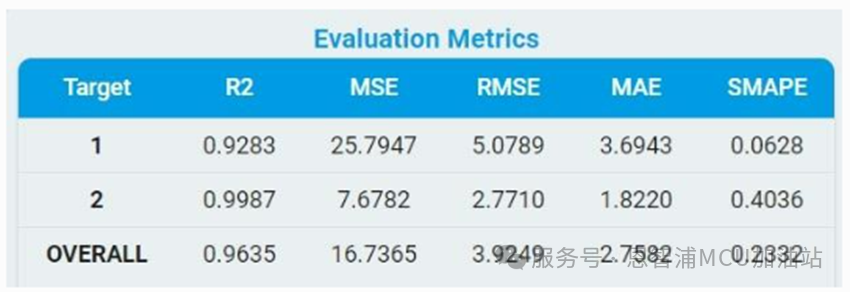
对于回归任务,给出了所有回归目标的MSE、RMSE、MAE、R2和SMAPE值。
MSE: 均方误差
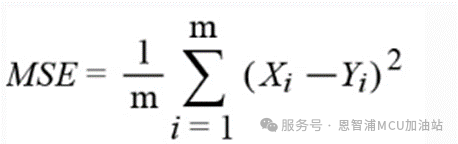
RMSE: 均方根误差
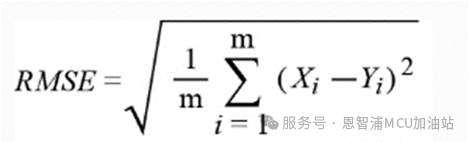
MAE: 平均绝对误差
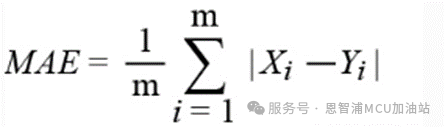
R2: 决定系数
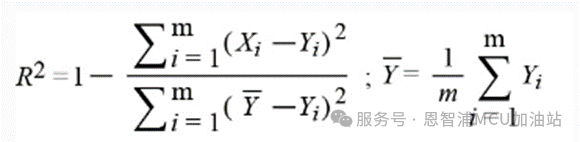
SMAPE: 对称平均绝对百分比误差
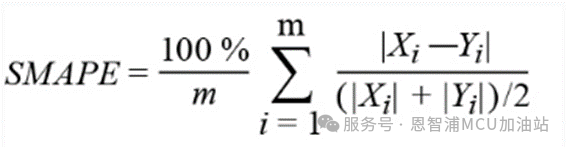
*注:公式中Yi 是第i个样本点的真实值,Xi 为第i个样本点的预测值。
-
恩智浦eIQ Time Series Studio工具使用教程之数据记录2025-05-24 1209
-
如何训练一个有效的eIQ基本分类模型2024-08-01 3746
-
恩智浦eIQ Time Series Studio 工具使用全攻略2024-12-12 2945
-
恩智浦 eIQ Time Series Studio 工具使用攻略(七)-部署2025-04-17 2288
-
NXP eIQ Time Series Studio 工具使用攻略(九)-数据标签2025-05-22 1723
-
恩智浦eIQ Time Series Studio工具使用教程之数据智能2025-06-05 1682
-
恩智浦eIQ Time Series Studio工具使用教程之数据操作2025-06-16 1742
-
恩智浦eIQ® Neutron神经处理单元2023-02-17 993
-
NVIDIA TAO工具套件功能与恩智浦eIQ机器学习开发环境的集成2024-03-22 1909
-
恩智浦eIQ AI和机器学习开发软件增加两款新工具2024-11-01 1904
-
恩智浦eIQ Time Series Studio的工作流程2024-12-09 1619
-
eIQ Time Series Studio工具使用教程2024-12-26 1822
-
恩智浦eIQ Time Series Studio工具使用教程之仿真2025-04-07 1366
-
恩智浦eIQ Time Series Studio简介2025-07-02 1955
-
恩智浦推出全新eIQ Agentic AI框架2026-01-13 1533
全部0条评论

快来发表一下你的评论吧 !
