

梦幻组合:树莓派+Deepseek
描述

OpenAI,这个只公开宣扬消耗全球所有能源和纳税人5000亿美元一半的机构,最近被震撼到了核心。Deepseek,一家由中国对冲基金运营的新AI初创公司,据称创建了一个名为R1的新型开源权重模型,该模型在所有指标上都超越了OpenAI的最佳模型。
而他们仅用600万美元就做到了这一点,而他们使用的GPU内存带宽只有OpenAI的一半。
除了这家中国初创公司以百分之一的资源击败OpenAI所带来的尴尬(据Deepseek所言),他们的模型还能“提炼”其他模型,使它们在较慢的硬件上运行得更好。
这意味着Raspberry Pi现在可以更好地运行其中一个最好的本地Qwen AI模型。
OpenAI的整个护城河都建立在人们无法获得训练和运行大型AI模型所需的疯狂能源和GPU资源之上。
但如果每个人都能随时购买一个GPU并免费运行一个足够好的模型,那么这个护城河就会消失。
Raspberry Pi AI
但耸人听闻的标题并没有告诉你全部的故事。
从技术上讲,Raspberry Pi可以运行Deepseek R1,但这与Deepseek R1 671b(一个400GB的模型)并不相同。
那个模型(实际击败ChatGPT的模型)仍然需要大量的GPU计算能力。
但巨大的不同在于,假设你有几块3090显卡,你就可以在家里运行它。你不需要为运行OpenAI那些花哨的模型而付费。
你只需安装Ollama,下载Deepseek,就可以尽情玩耍。
而且,即使你没有一堆GPU,你也可以在任何有足够内存的计算机上技术上运行Deepseek。
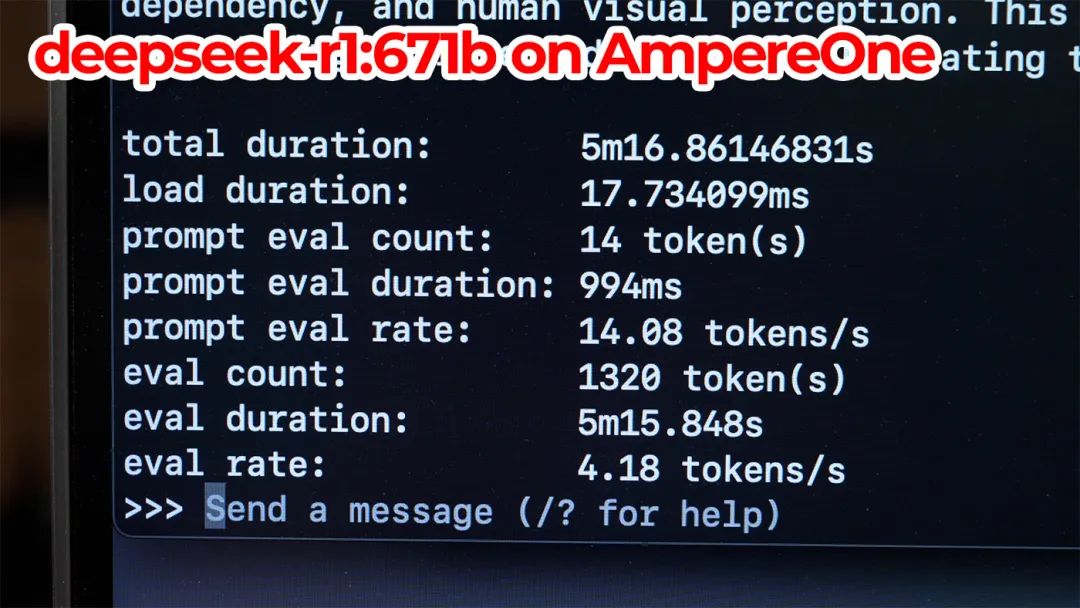
我使用Ollama在拥有512GB内存的AmpereOne 192核服务器上测试了Deepseek R1 671B,它的运行速度仅为每秒4个标记以上。这不算特别快,但AmpereOne也不会让你花费10万美元!
尽管它只使用了数百瓦的功率——这确实非常令人惊讶——但一个嘈杂的机架式服务器并不适合放在每个人的客厅里。
但Raspberry Pi可以。所以让我们看看较小的14b模型在Raspberry Pi上的运行情况:
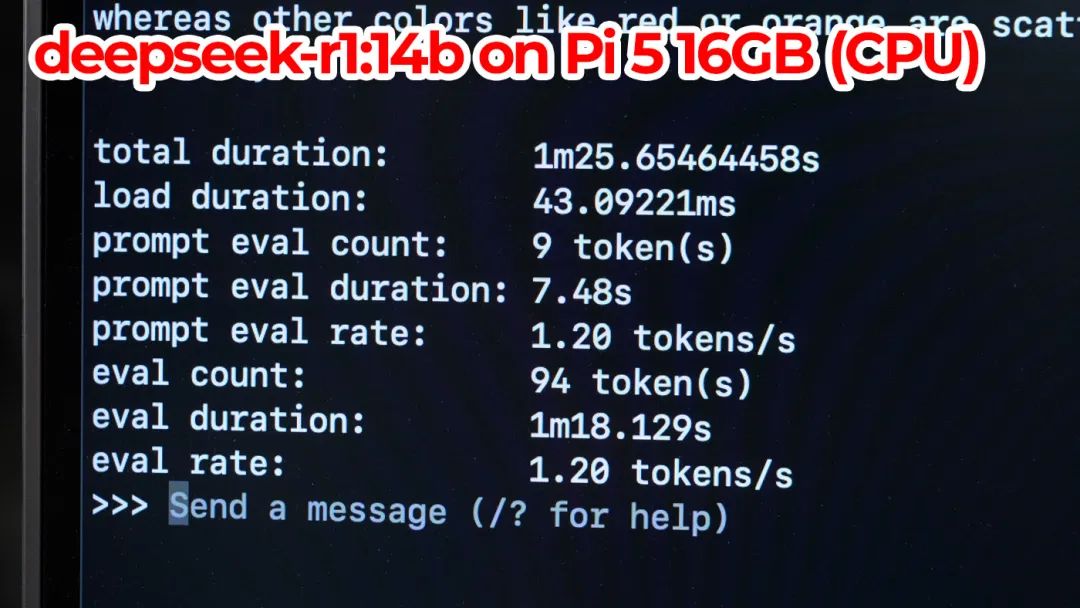
它……肯定不会赢得任何速度纪录。我得到的运行速度大约是每秒1.2个标记。
它能运行,但如果你想要一个用于橡胶鸭调试的聊天机器人,或者给你下一个博客文章标题提供几个想法,这并不有趣。
Raspberry Pi GPU AI
但我们可以加快很多速度。我们只需要一个外置显卡,因为GPU及其上的VRAM比CPU和系统内存更快。

我一直在用AMD W7700显卡测试这个设置。它有16GB的高速VRAM,只要它能容纳整个AI模型,它就应该快得多:
型号
| 大小
| 参数
| 后台
| ngl
| 测试
| t/s
|
qwen2 14B Q4_K - Medium
| 8.37 GiB
| 14.77 B
| Vulkan
| 99
| pp512
| 193.31 ± 0.35
|
qwen2 14B Q4_K - Medium
| 8.37 GiB
| 14.77 B
| Vulkan
| 99
| pp4096
| 168.01 ± 0.25
|
qwen2 14B Q4_K - Medium
| 8.37 GiB
| 14.77 B
| Vulkan
| 99
| tg128
| 24.41 ± 0.24
|
qwen2 14B Q4_K - Medium
| 8.37 GiB
| 14.77 B
| Vulkan
| 99
| pp4096+tg128
| 54.26 ± 0.92
|
llama-bench报告每秒24到54个标记,而这个GPU甚至不是针对LLM(大型语言模型)设计的——你可以更快。完整的测试结果,请查看我的ollama-benchmark仓库:在配备AMD W7700的Pi 5上测试Deepseek R1 Qwen 14B。
结论
AI仍然处于巨大的泡沫中。Deepseek发布后,英伟达在一天内市值蒸发了超过5000亿美元。
但他们的股价仍然是2023年的8倍,而且现在似乎并没有人们减少对AI的炒作。
-
树莓派分类器:用树莓派识别不同型号的树莓派!2025-06-13 1697
-
家里乱成“垃圾场”,树莓派也能一键搞定家务了?2025-03-25 988
-
如何通过SSH连接到树莓派2023-08-23 2451
-
树莓派控制步进电机2023-03-21 1027
-
如何玩转树莓派2020-05-30 4661
-
树莓派3和树莓派4的原理图免费下载2020-01-07 4585
-
树莓派是什么树莓派的简单介绍2019-05-15 3575
-
浅谈香蕉派与树莓派的不同2018-10-30 28054
-
树莓派有什么用_树莓派能用来做啥_树莓派新手入门教程2018-05-08 35061
-
树莓派用什么语言编程_树莓派python编程详解2018-01-15 39855
-
树莓派3wifi配置_树莓派3开启wifi热点_树莓派3的wifi使用教程2017-12-08 32175
-
树莓派的种类_树莓派安装教程2017-11-27 6041
-
树莓派装机教程2015-11-25 1520
全部0条评论

快来发表一下你的评论吧 !
