

利用深层神经网络人工智能(AI)训练技术翻译文本
描述
微软研究人员在3月14日发表博客文章称,在利用深层神经网络人工智能(AI)训练技术翻译文本方面取得了进展。他们发明了第一台机器翻译系统,可以将中文新闻的句子翻译成英文,准确率与人类不相上下。系统在一套常用的新闻报道测试集上实现了达到了人类水平,测试集名为newstest2017。
在前几期的文章里,我们介绍了神经网络和深度学习的相关内容,微软的这套翻译系统就是使用深层神经网络,帮助生成更真实、更准确的翻译。它还采用了多种不同的人工智能训练方法,包括双重学习、商议网络和联合训练,试图模仿人类的学习方式。
机器翻译
机器翻译系统是支持翻译大量文本的应用程序或在线服务,将文本从“源”语言译成另一种"目标"语言的过程。
自从2010年代早期,新的人工智能技术- 深度神经网络(又称深度学习),已经达到较高的精准度,微软翻译团队将语音识别结合其核心文本翻译技术,推出新的语音翻译技术。
虽然机器翻译技术和接口技术的概念相对简单,但它背后的科技集成却是极其复杂的,集成了多项尖端技术,特别是深度学习(人工智能)、 大数据、 语言学、 云计算和 web API。
从历史上看,曾经主流的机器学习技术在行业中应用是统计机器翻译 (SMT)。SMT 使用先进的统计分析,从一句话中上下文的几个词中来估计最佳可能的翻译。SMT自20 世纪中期以来的为所有主要翻译服务提供商所使用,其中包括微软。
基于深度神经网络(NN) 的翻译技术的出现,带动了机器翻译技术的突变,显著提高了翻译质量。这种新的翻译技术在2016年的下半年开始大规模部署使用。
这两种技术共同之处有两个方面︰
两者都需要大量的人工翻译的数据(高达数百万的人工翻译过的句子)用于培训翻译系统。
既不作为双语词典,也不是基于翻译列表,是根据词在句子中使用的上下文来翻译。
Microsoft翻译
微软翻译文本和语音 API,是微软 认知服务集合的一部分,是微软云的机器翻译服务。
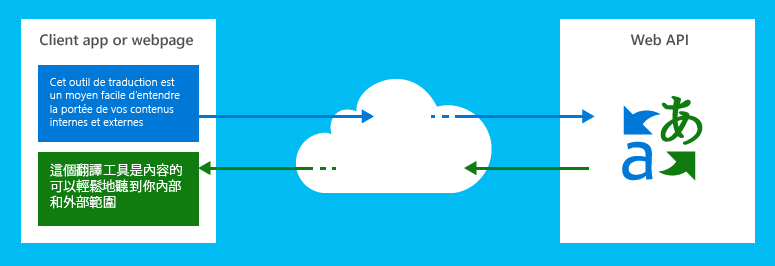
1、微软翻译文本 API
微软翻译文本API 已自2006年以来用于微软多个个业务部门的产品和服务中,并且自2011年向第三方客户提供。微软翻译文本API已经在微软公司内部广泛应用,它被用于产品本地化、客户支持和在线交流(例如, Windows Blog)。还可以从熟悉的微软产品( Bing、 柯塔娜、 Internet Explorer、 Lync、 Cortana、 Office、SharePoint、 Skype 和 Yammer)访问这一服务,且无需额外付费。
Microsoft Translator 可在任何硬件平台上以Web方式或客户端中使用,与任何操作系统结合来进行语言翻译和其他语言相关操作,如文字语言检测,文本到语音转换,以及词典。
利用行业标准的REST技术,开发人员向服务发送源文本以及标识目标语言的参数,该服务经翻译后的文本发送回客户端或 web 应用程序。
微软翻译服务部署在微软数据中心,从安全性、 可伸缩性、 可靠性和不间断的可用性等方面享受和其他微软云服务同样的好处。
2、微软翻译语音API
微软语音翻译技术首先在2014年底通过Skype Translator集成推出的,并且在2016年初是作为开放的API向客户提供。它集成在Skype,Skype会议广播和微软翻译app中(Android、 iOS 和 Windows版)。
文本翻译的工作原理
有两种主流的机器翻译技术︰ 传统的统计机器翻译(SMT) 和新一代之神经网络 (NN) 翻译。
1、统计机器翻译
微软翻译使用的统计机器翻译(SMT) 是建立在超过十年的微软自然语言处理研究成果上。现代翻译系统不再手动编写规则进行语言转换,而是将翻译当作基于所有语言现有的人工译文及相互转换的学习问题,并利用了应用统计学和机器学习方面的最新成果。
所谓的"平行语料库"在很大程度上充当现代的罗塞塔石,基于语境为许多语言以及专门领域提供单词、短语和习语翻译。统计建模技术和高效算法帮助计算机解决解读(检测训练数据中源语言和目标语言之间的对应关系)以及解码 (为新输入句子找到最好的翻译)等问题。Microsoft Translator 将统计方法的力量与语言信息相结合,产生归纳更理想译文和更易理解的输出。
由于这种方法并不依赖于词典或语法规则,它提供基于上下文的最佳翻译的词汇和短语。
2、神经网络翻译
翻译质量的不断改善是十分重要的。然而,SMT 技术自2010年代中期性能改进有所停滞。通过大规模部署的微软AI 超级计算机,特别是通过微软认知工具包,微软翻译现在提供了基于神经网络 (LSTM) 的翻译,使翻译质量改进步入了新的十年。
这些神经网络模型已经在所有微软语音翻译中部署,可以通过语音翻译API调用, 或者通过文本API 使用“generalnn“的Category ID参数调用。
神经网络翻译从根本上的执行方式相对于传统 SMT翻译不同。
下面的动画描述了神经网络翻译的各个步骤。使用这种方法,翻译将考虑到上下文完整的句子,而SMT技术只能考虑上下文的几个词语。所以,神经网络翻译将会产生更流利和接近人工翻译的结果。
基于神经网络的训练,每个单词被编码沿500 维向量 (a) 表示其独特的特征,针对特定的语言对(例如英语和中文)。将语言对用于训练,神经网络将自定义这些维度应该是什么。他们可以对简单的概念,如性别 (女性,男性,中性),礼貌水平(俚语,休闲,书面的正式的等等),类型的词(动词、 名词等),以及任何其他非明显的特征作为派生的训练数据进行编码。
神经网络翻译运行的步骤如下︰
每个单词或更具体地说 500-维向量表示它,穿过第一层的"神经元",将编码它在一个1000-维向量 (b) 代表这个词在上下文句子中其他词的范围。
一旦所有单词均已进行这些 1000- 维向量都编码,过程被重复几次,每一层都进行更好地微调这1000- 维度表现这个词完整的句子(而SMT翻译只考虑 3 到 5 个单词的窗口)的范围内。
翻译注意层(即软件算法)将使用此最终输出矩阵和以前翻译过的单词来确定来自源句子的哪个词,应该接下来到最终输出矩阵。它还将使用这些计算在目标语言中删除不必要的词语。
解码器(翻译)层,在它最合适的目标语言等效转换选定的词(或更具体地说 1000-维向量代表这个词的完整的句子范围内)。这个输出层(C)然后反馈到注意层计算源句子应该翻译的下一个单词。

在动画的示例中,"the"的上下文感知的 1000- 维度模型将编码的名词 (house)是法语的女性词 (la maison)。这将"the"适当的翻译为"la" 而不是"le" (单数,男性)或"les" (复数),当它达到解码器(翻译)层。
注意算法还将计算基于以前翻译过的(在这个案例"the"),下一步这个词被翻译应该是主题("house") 而不是一个形容词 ("blue")。可以做到这一点因为系统学过英语和法语转换时这些句子中词语的顺序。假如形容词是"大"而不是一种颜色的形容词,那它应该不反转 (“the big house” => “la grande maison”)。
基于这种办法最终的翻译结果在大多数情况下,比基于SMT 的翻译更流畅和更接近于人类的翻译。
语音翻译的工作原理
Microsoft Translator 还能够翻译语音。此功能最初仅通过Skype Translator,以及iOS 和 Android的Microsoft Translator 应用程序提供。现在通过最新版的语音翻译API 提供向开发人员提供。
虽然乍看上去是个简单的过程,但这比仅仅将“传统”人机语音识别引擎插入现有文本翻译引擎的过程复杂得多。
若要正确从一种语言的"源"语音翻译成不同的"目标"语言,系统经过四步过程。
语音识别,将音频转换为文本。
TrueText算法: 微软特有的技术将口语优化成更标准的文本,使之更适合机器翻译。
通过上述的文本翻译引擎进行翻译,利用专为现实生活口语会话开发的翻译模型。
文本到语音转换,必要时输出译文的音频。
1、自动语音识别 (ASR)
使用经过数千小时训练的DNN 系统执行自动语音识别(ASR)。此模型基于人和人交互数据,而非人机指令训练,可产生适合正常对话优化的语音识别效果。为达此目的,DNN需要相比传统人机交互ASR更多大量的生活口语数据训练系统。
2、TrueText
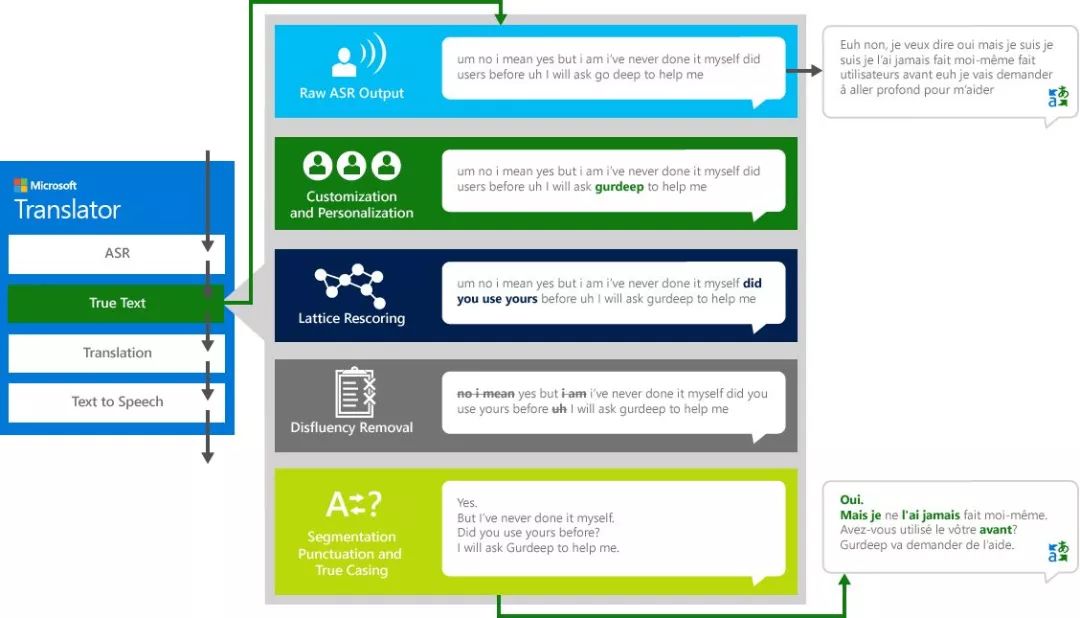
我们日常的说话并不完美,常常不如自己认为的那样清晰和流利。凭借 TrueText技术,可以删除口语中不流利的部分(赘词,如"嗯"、"啊"、"和"、"比如")、口吃和重复,使文本经转换更贴近地反映用户意图。还通过添加断句、正确标点符号和大小写,使文本更易读和更易译。为取得这些成果,我们将数十年的研究成果应用于开发 Translator的语言技术,从而创建出 TrueText。下图通过真实的示例演示 TrueText的执行过程。
3、翻译
然后,将相关文本翻译成任何微软翻译支持的60 多种语言之一。
面向开发人员提供的语音翻译API或在语音翻译应用程序或服务中使用最新的神经网络翻译,可以使用所有语音输入支持的语言(请参阅这里的完整列表)。当前现有的翻译模型大多是书面语文本训练的,通过增加更多的口语文本语料库,打造更好的为口语会话类型的翻译建立了的模型。这些模型也可通过'Speech'标准类文本翻译 API 提供。
对于任何其他非语音类支持语言,仍然使用传统的SMT 翻译,除非另有说明如这里。
4、文本到语音
目前我们支持18文本到语音转换语言,如果需要音频输出,文本将以语音合成输出。在语音转文本的翻译情景中将省略这一阶段。
newstest2017系统的新技术
微软官方博客中提到,新的翻译系统中用到了四大技术:对偶学习、联合训练、推敲网络和一致性正则化,对应的论文也已经公开。
1、对偶学习台(Dual Learning)
对偶学习利用的是人工智能任务的天然对称性。其发现是由于现实中有意义、有实用价值的人工智能任务往往会成对出现,两个任务可以互相反馈,从而训练出更好的深度学习模型。例如,在翻译领域,我们关心从英文翻译到中文,也同样关心从中文翻译回英文;在语音领域,我们既关心语音识别的问题,也关心语音合成的问题;在图像领域,图像识别与图像生成也是成对出现。此外,在对话引擎、搜索引擎等场景中都有对偶任务。
一方面,由于存在特殊的对偶结构,两个任务可以互相提供反馈信息,而这些反馈信息可以用来训练深度学习模型。也就是说,即便没有人为标注的数据,有了对偶结构也可以做深度学习。另一方面,两个对偶任务可以互相充当对方的环境,这样就不必与真实的环境做交互,两个对偶任务之间的交互就可以产生有效的反馈信号。因此,充分地利用对偶结构,就有望解决深度学习和增强学习的瓶颈,如“训练数据从哪里来、与环境的交互怎么持续进行”等问题。
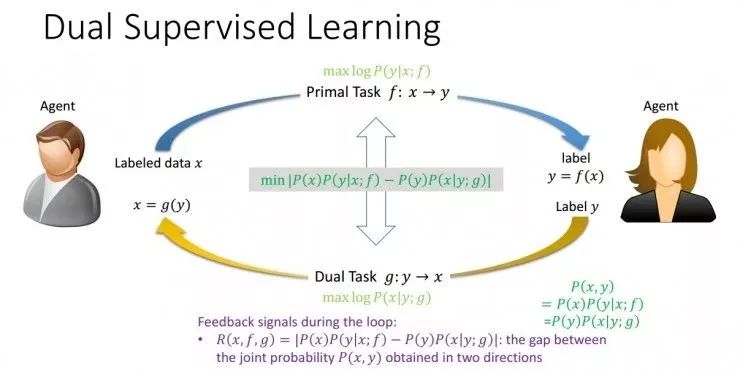
ICML 2017 对偶监督学习论文的范式示意图
2、推敲网络(Deliberation Network)
“推敲”二字可以认为是来源于人类阅读、写文章以及做其他任务时候的一种行为方式,即任务完成之后,并不当即终止,而是会反复推敲。微软亚洲研究院机器学习组将这个过程沿用到了机器学习中。推敲网络具有两段解码器,其中第一阶段解码器用于解码生成原始序列,第二阶段解码器通过推敲的过程打磨和润色原始语句。后者了解全局信息,在机器翻译中看,它可以基于第一阶段生成的语句,产生更好的翻译结果。
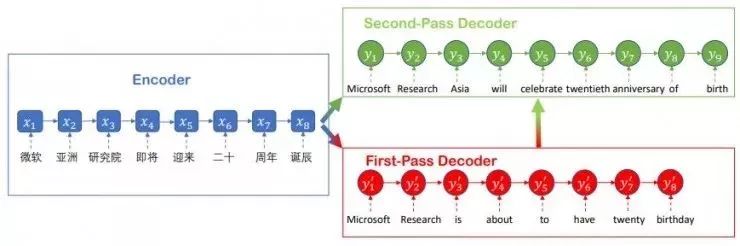
3、脑联合训练(Joint Training)
这个方法可以认为是从源语言到目标语言翻译(Source to Target)的学习与从目标语言到源语言翻译(Target to Source)的学习的结合。中英翻译和英中翻译都使用初始并行数据来训练,在每次训练的迭代过程中,中英翻译系统将中文句子翻译成英文句子,从而获得新的句对,而该句对又可以反过来补充到英中翻译系统的数据集中。同理,这个过程也可以反向进行。这样双向融合不仅使得两个系统的训练数据集大大增加,而且准确率也大幅提高。
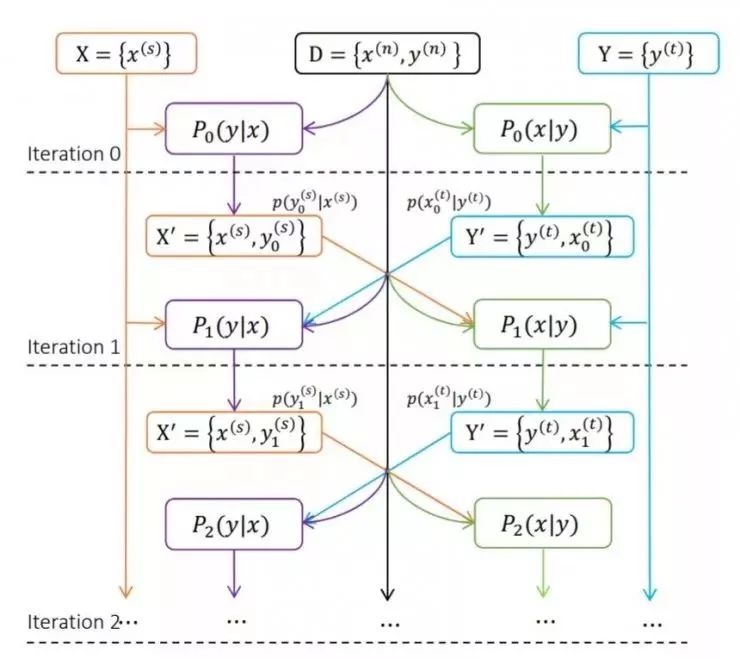
从源语言到目标语言翻译(Source to Target)P(y|x) 与从目标语言到源语言翻译(Target to Source)P(x|y)
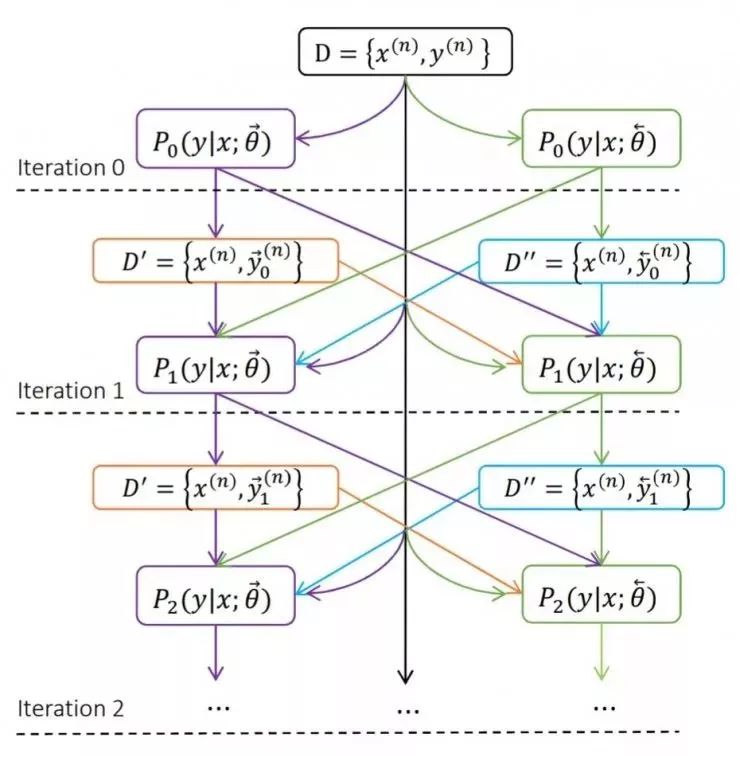
4、一致性规范(Agreement Regularization)
翻译结果可以从左到右按顺序产生,也可以从右到左进行生成。该规范对从左到右和从右到左的翻译结果进行约束。如果这两个过程生成的翻译结果一样,一般而言比结果不一样的翻译更加可信。这个约束,应用于神经机器翻译训练过程中,以鼓励系统基于这两个相反的过程生成一致的翻译结果。
复杂性让机器翻译成为一个极有挑战性的问题,但也是一个极有意义的问题。微软亚洲研究院副院长、机器学习组负责人刘铁岩认为,我们不知道哪一天机器翻译系统才能在翻译任何语言、任何类型的文本时,都能在“信、达、雅”等多个维度上达到专业翻译人员的水准。不过,他对技术的进展表示乐观,因为每年微软的研究团队以及整个学术界都会发明大量的新技术、新模型和新算法,“我们可以预测的是,新技术的应用一定会让机器翻译的结果日臻完善。”
-
嵌入式中的人工神经网络的相关资料分享2021-11-09 0
-
人工神经网络原理及下载2008-06-19 0
-
未来的人工智能技术趋势是什么?2015-12-23 0
-
人工智能:超越炒作2019-05-29 0
-
史上最全AI人工智能入门+进阶学习视频全集(200G)【免费领取】2019-11-27 0
-
【AI学习】第3篇--人工神经网络2020-11-05 0
-
在人工智能神经网络ADC设计方面各位有什么见解呢?2021-06-24 0
-
如何使用stm32cube.ai部署神经网络?2021-10-11 0
-
人工智能对汽车芯片设计的影响是什么2021-12-17 0
-
隐藏技术: 一种基于前沿神经网络理论的新型人工智能处理器2022-03-17 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
-
微软最新的翻译系统是利用深层神经网络人工智能训练技术翻译文本2018-04-08 7916
-
微软发明了第一台AI翻译系统,英汉互译准确率媲美人工2019-03-01 5997
-
深层神经网络模型的训练:过拟合优化2020-12-02 2737
-
神经网络和人工智能的关系是什么2024-07-03 1094
全部0条评论

快来发表一下你的评论吧 !
