

DC中有一个比较常用的方法:set_cost_priority -delay
描述
在综合的时候,可能大家最关心的是如何设置提高timing QoR。在DC中有一个比较常用的方法,使用set_cost_priority -delay。
DC综合过程中默认的优化是有优先级顺序的,即DRC>timing。有的时候会出现某些路径的优化考虑了DRC而忽略timing,导致timing violation的出现。比如以下这种情况:
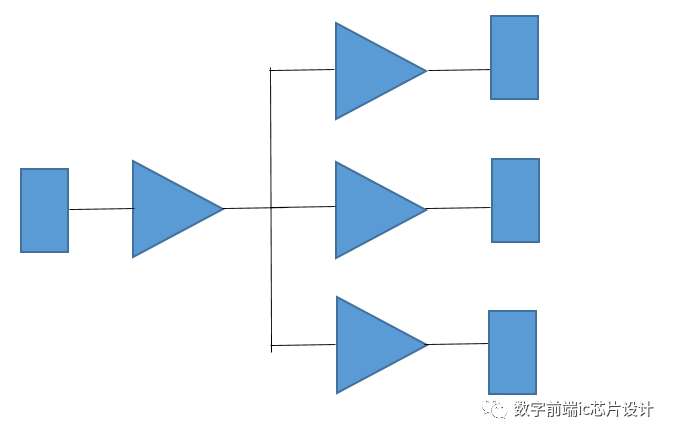
上图所示的电路中第一级buffer驱动了fanout为3的buffer tree(这里只画了fanout=3,一般情况下远远不止),这段net因为fanout较多有可能会有max transition,max capacitance甚至max fanout的DRC违例。但是起点寄存器到终点寄存器之间都只有2级buffer,timing情况还比较乐观,不太容易出现timing violation。在默认情况下,DC为了避免DRC问题,不会将电路优化成这种样子,更有可能是以下的电路:
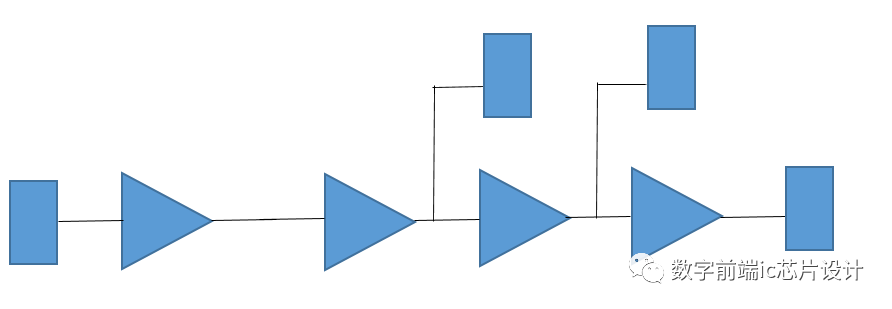
这段电路从功能上与上一图中电路是一致的,在优化过程中为了避免DRC违例,DC将buffer tree拉长,并将连接到终点寄存器的节点分散,这样每个buffer只驱动一个寄存器以及一个buffer,比起图1中一个buffer驱动3个buffer,fanout的数量减小了。乍一看只是从3减小为2,但如果在图1中第一级buffer驱动的是15个fanout,那么这里的将会是15->2的fanout的优化,可以大大避免DRC问题。
DRC的问题避免了,但我们可以明显看到图二中从起点寄存器到终点寄存器中间经过的buffer数量增加了(最多经过4个buffer),而这条path比起图一中的timing path,无疑timing会更差(这里即便考虑到图1中high fanout的net的big transition可能带来的单级较大delay,也不会差过多级buffer相连接,如果buffer数量增加,delay差距更加明显)。
在这种情况下,set_cost_priority -delay这个命令就能使综合工具在优化过程中优先考虑timing,从而综合出图1的网表,即便有一些DRC violation,我们也可以放到后端去修复。因此,我们如果在分析综合网表的时候(在DC中使用report_timing)看到有较长的buffer tree导致的timing violation,并且每级buffer的fanout都较小,可以考虑使用这个命令来实现改善。
-
27个比较常用的电源符号2023-11-24 10447
-
python中的set类型2023-11-21 1976
-
不同创建线程安全Set的方式2023-09-25 1885
-
set_output_delay的本质是什么?浅谈set_ouput_delay时序2023-08-12 3675
-
Vivado中如何做set_input_delay约束2022-02-16 5328
-
STM32上进行Delay延时的方法2021-12-24 956
-
常用的产生负电源的方法2021-11-11 1857
-
set_max_delay被覆盖的解决办法2020-09-07 11193
-
TI-RTOS的PRIORITY如何Set?2020-03-26 1612
-
Low-Cost, Dual SCART Solution2009-09-02 2168
-
延迟线比较-Delay Lines Comparison2009-04-22 1457
-
基于混合SET/MOSFET的比较器2009-04-20 1778
-
MAX15026 Low-Cost, DC-DC Synch2009-02-13 1322
全部0条评论

快来发表一下你的评论吧 !
