

如何在RAKsmart服务器上部署DeepSeek AI大模型
电子说
描述
RAKsmart作为高性能服务器提供商,其硬件配置和网络环境非常适合运行AI大模型。下面,AI部落小编为您讲解如何在RAKsmart服务器上部署DeepSeek AI大模型的完整流程。
一、部署前的准备工作
1.服务器选型与配置
DeepSeek等AI大模型对计算资源要求较高,建议选择RAKsmart以下配置的服务器:
GPU型号:至少配备NVIDIATeslaV100或A100显卡(显存16GB以上),多卡并行可提升训练/推理速度。
内存:64GB及以上,避免因内存不足导致进程崩溃。
存储:1TBNVMeSSD,确保模型文件(通常数百GB)快速加载。
操作系统:Ubuntu22.04LTS或CentOS8,兼容主流深度学习框架。
2.系统环境初始化
更新系统:

安装基础工具:

二、安装深度学习环境
1.配置NVIDIA驱动与CUDA
安装显卡驱动:
访问NVIDIA驱动下载页,选择对应GPU型号的驱动。
安装CUDAToolkit:
DeepSeek依赖CUDA加速,推荐CUDA11.8:
添加环境变量至~/.bashrc:
2.安装PyTorch与依赖库
使用pip安装适配CUDA11.8的PyTorch:
安装模型运行依赖:
三、下载与配置DeepSeek模型
1.获取模型权重
官方渠道:
若已获得DeepSeek官方授权,可通过提供的链接下载模型文件(通常为.bin或.safetensors格式)。
HuggingFaceHub:
若模型已开源,使用git-lfs克隆仓库:
2.模型配置文件调整
修改config.json以适配硬件:

四、启动模型推理服务
1.编写推理脚本
创建inference.py,使用HuggingFace的pipeline快速调用:
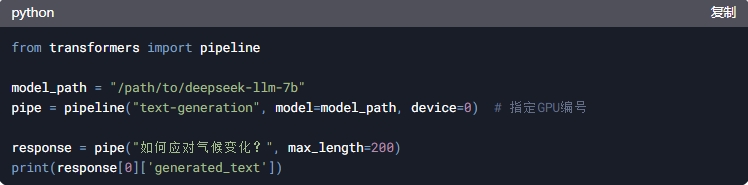
2.运行测试

若输出合理文本,说明模型部署成功。
五、优化与安全加固
1.性能优化技巧
多GPU并行:
使用accelerate库启动多卡推理:

量化压缩:
启用8位量化减少显存占用:

2.安全防护措施
防火墙设置:
仅开放必要端口(如HTTPAPI的5000端口):

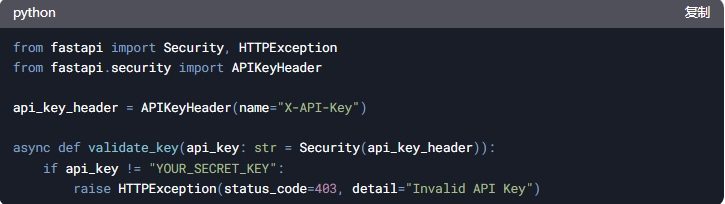
API访问鉴权:
使用FastAPI添加API密钥验证:
六、总结
通过上述步骤,可以在RAKsmart服务器上部署DeepSeek AI大模型,并实现了基础推理与安全防护。对于企业级应用,可进一步结合Kubernetes实现弹性扩缩容,或使用ONNXRuntime提升推理效率。
审核编辑 黄宇
-
添越智创基于 RK3588 开发板部署测试 DeepSeek 模型全攻略2025-02-14 2880
-
DeepSeek企业级部署实战指南:以Raksmart企业服务器为例2025-03-12 1337
-
RAKsmart美国裸机云服务器DeepSeek的高级定制化部署方案2025-03-13 1111
-
如何在RakSmart服务器上用Linux系统部署DeepSeek2025-03-14 953
-
利用RAKsmart服务器托管AI模型训练的优势2025-03-18 898
-
依托raksmart服务器在多种系统上本地部署deepseek注意事项2025-03-19 1155
-
DeepSeek企业级部署服务器资源计算 以raksmart裸机云服务器为例2025-03-21 1410
-
RAKsmart企业服务器上部署DeepSeek编写运行代码2025-03-25 875
-
如何在RAKsmart服务器上实现企业AI模型部署2025-03-27 1097
-
RAKsmart服务器如何重塑AI高并发算力格局2025-04-03 1166
-
RAKsmart高性能服务器集群:驱动AI大语言模型开发的算力引擎2025-04-15 903
-
RAKsmart服务器如何赋能AI开发与部署2025-04-30 1073
-
基于RAKsmart云服务器的AI大模型实时推理方案设计2025-05-13 788
-
DeepSeek模型如何在云服务器上部署?2025-10-13 1325
-
如何快速在云服务器上部署Web环境?2025-10-14 1077
全部0条评论

快来发表一下你的评论吧 !
