

谷歌第七代TPU Ironwood深度解读:AI推理时代的硬件革命
描述
谷歌第七代TPU Ironwood深度解读:AI推理时代的硬件革命
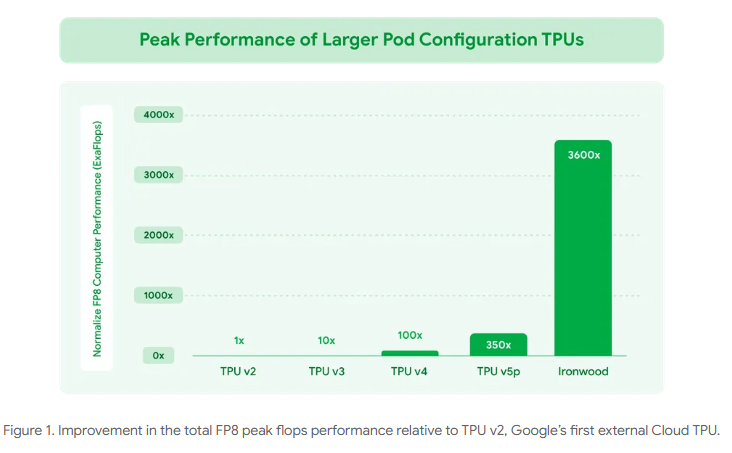
Google 发布了 Ironwood,这是其第七代张量处理单元 (TPU),专为推理而设计。这款功能强大的 AI 加速器旨在处理“思维模型”的大量计算需求,例如大型语言模型和专家混合模型。Ironwood 可扩展至多达 9216 个芯片,提供 42.5 Exaflops 的计算能力,使其比世界上最大的超级计算机更强大。

一、架构设计的颠覆性创新
- 首款推理专用TPU
Ironwood是谷歌TPU系列中首款完全针对AI推理优化的芯片,标志着AI硬件从“训练优先”转向“推理优先”的战略转型。其设计突破传统“训练-推理混合架构”,通过专用电路优化推理流程,例如动态分区技术允许单芯片同时处理视频分析、文本翻译等多模态任务,显著提升实时响应能力。 - FP8浮点格式支持
首次引入FP8计算精度(此前仅支持INT8和BF16),使训练吞吐量翻倍,推理性能较BF16提升10倍。这一改进尤其适用于生成式AI的多模态数据混合精度计算,例如文本转音乐模型Lyria的实时合成效率提升3倍。 - 内存与互连技术革命
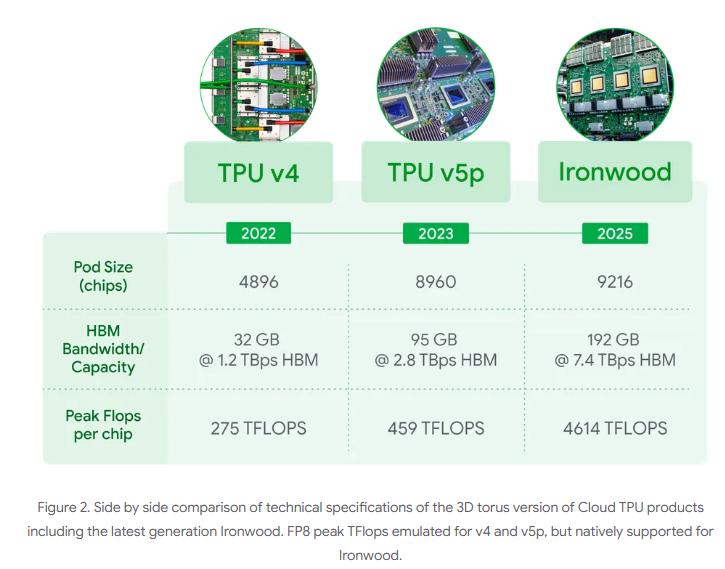
- 192GB HBM内存(Trillium的6倍)可完整缓存1750亿参数模型,避免频繁访问外部存储,延迟降低40%
- 7.2TB/s带宽(Trillium的4.5倍)实现“数据零拥堵”,支持每秒处理20路4K视频流
- 1.2Tbps芯片互连带宽(Trillium的1.5倍),构建9216芯片集群时延迟仅增加12%
二、硬件性能的行业新标杆
- 算力维度突破
- 单芯片峰值算力达4614 TFLOPS(FP8精度),是英伟达H200的1.8倍
- 9216芯片集群算力 42.5 Exaflops ,超全球最快超算El Capitan(1.7 Exaflops)24倍
- 液冷系统支持10兆瓦功率输出,全负载下温度波动小于±2℃
- 能效比改写游戏规则
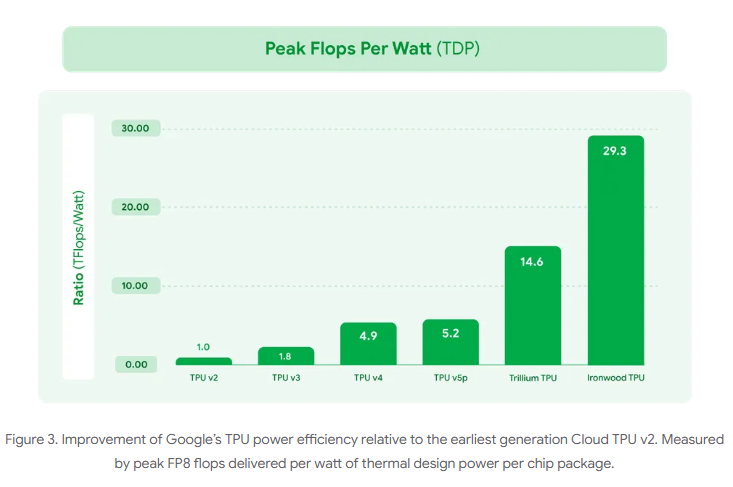
- 每瓦性能较Trillium提升100%,比2018年初代云TPU高30倍
- 运行GPT-4级模型的单位推理成本降低30%,数据中心PUE(电能使用效率)可降至1.1以下
三、行业影响与落地场景
- 医疗健康领域
某药企使用9216芯片集群,将癌症靶点筛选周期从90天压缩至20小时,同时分析1.2万种化合物组合。基因测序数据处理速度提升100倍,全基因组分析成本降至50美元/例。 - 金融科技应用
- 实时风控系统可处理千亿级交易数据,欺诈识别准确率达99.9%
- 某银行采用256芯片配置,信贷审批时间从3小时缩短至2分钟,日均处理量突破200万笔
- 自动驾驶突破
支持L5级全栈算法端到端推理,决策延迟从毫秒级降至 50微秒 ,复杂路况避障成功率提升至99.999%。实测显示,单芯片可同步处理20路激光雷达+8K摄像头数据流。
四、市场竞争与生态战略
- 对抗英伟达的“组合拳”
- 算力密度:Ironwood的29.3 TFLOPS/W能效比超H200(21.5 TFLOPS/W)35%
- 软件生态:配套Pathways系统支持数万芯片统一调度,API调用延迟<1ms
- 价格策略:同等算力租赁成本比AWS Inferentia低40%
- 智能体协作生态构建
推出A2A(Agent-to-Agent)协议,实现跨平台智能体安全通信。例如医疗诊断智能体可自动调用药物研发智能体的分子模拟结果,形成决策闭环。目前已吸引Salesforce、SAP等50+企业加入生态。
五、技术演进路线启示
- 专用化趋势加速
Ironwood验证了“推理芯片需独立进化”的假设,未来可能衍生出医疗推理芯片(如蛋白质折叠专用单元)、金融时序预测芯片等垂直品类。 - 软硬协同新范式
通过TensorFlow-Micro架构实现芯片级指令集优化,使Gemini模型的推理指令集精简60%,功耗降低25%。 - 可持续计算突破
液冷系统配合FP8精度,使单Exaflop算力的碳排放较传统方案降低78%,助力欧盟AI碳税政策下的合规需求。
技术参数对比表
| 指标 | Ironwood | TPU v6e (Trillium) | 英伟达 H200 |
|---|---|---|---|
| 计算精度 | FP8 | BF16/INT8 | FP8 |
| 单芯片峰值算力 | 4614 TFLOPS | 980 TFLOPS | 2560 TFLOPS |
| HBM容量 | 192GB | 32GB | 141GB |
| 能效比(TFLOPS/W) | 29.3 | 14.6 | 21.5 |
| 最大集群规模 | 9216芯片 | 4096芯片 | 4096 GPU |
| 典型推理延迟(ms) | 0.8 | 2.1 | 1.5 |
注:数据综合自各来源
Ironwood的发布不仅重新定义了AI推理硬件的性能边界,更通过“芯片-框架-应用”的全栈优化,推动AI从工具型技术向决策型基础设施进化。其影响将随着生成式AI的普及持续释放,重塑从云计算到边缘计算的整个计算生态。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
-
第七代iPod nano拆解:配备了五款神秘的苹果芯片2012-10-16 13326
-
AMD公布了第七代桌面级APU 采用AM4新接口2016-09-06 2314
-
AMD第七代APU处理器计算速度提升20%2016-09-07 1175
-
第七代高尔夫GTI上手体验评测2018-07-17 14386
-
深度测评大众第七代高尔夫R2018-07-09 17822
-
AMD推出第七代APUA8-7680 热设计功耗只有45W非常节能2018-10-27 7786
-
第七代小冰能做什么?2019-09-01 5610
-
谷歌新一代 TPU 芯片 Ironwood:助力大规模思考与推理的 AI 模型新引擎2025-04-12 4258
-
Google推出第七代TPU芯片Ironwood2025-04-16 2161
-
小马智行第七代Robotaxi车型搭载禾赛AT128激光雷达2025-04-27 1194
-
小马智行第七代自动驾驶车辆广深开跑2025-06-11 1885
-
小马智行第七代自动驾驶Robotaxi开启道路测试2025-07-16 1157
-
小马智行第七代自动驾驶车辆三城开跑2025-07-26 1423
-
小马智行第七代自动驾驶车辆上线运营2025-11-07 1706
-
谷歌云发布最强自研TPU,性能比前代提升4倍2025-11-13 9282
全部0条评论

快来发表一下你的评论吧 !
